⚖️ MySQL索引:数量越多越好吗?
🎯 一句话答案
绝对不是!索引就像 调料**------** 放对了美味,放多了毁菜**。**
📊 索引的代价(为什么不能多)
1. 写入性能急剧下降
-- 假设表有5个索引,插入一条数据:
INSERT INTO users (name, age, city, phone, email)
VALUES ('张三', 25, '北京', '13800138000', 'zhangsan@example.com');
-- 实际发生:
主数据写入 1 次
索引1写入 1 次
索引2写入 1 次
索引3写入 1 次
索引4写入 1 次
索引5写入 1 次总共:6次写入!每加一个索引,写入就多一次。
2. 更新/删除变慢
UPDATE users SET city = '上海' WHERE id = 100;
-- 如果city列有索引,需要:1.删除旧索引 2.插入新索引
-- 多个索引时,每个涉及到的索引都要更新💰 索引的"成本"分析
空间成本
-- 查看索引占用空间
SELECT
table_name,
index_name,
ROUND(index_length/1024/1024, 2) AS '索引大小(MB)',
ROUND(data_length/1024/1024, 2) AS '数据大小(MB)',
ROUND(index_length/data_length, 2) AS '索引/数据比'
FROM information_schema.TABLES
WHERE table_schema = 'your_db';
-- 典型情况:
-- 数据:100MB
-- 1个索引:20MB
-- 5个索引:100MB(和原始数据一样大!)时间成本对比
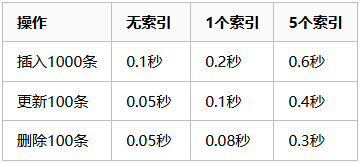
🚨 索引过多的危害
1. 优化器选择困难
-- 假设表有10个索引,查询:
SELECT * FROM users WHERE age > 20 AND city = '北京';
-- 优化器可能面临选择:
-- idx_age (age)
-- idx_city (city)
-- idx_age_city (age, city)
-- idx_city_age (city, age)
-- ...等等
-- 选择过程消耗CPU,还可能选错索引!2. 重复/冗余索引
-- 常见重复索引:
CREATE INDEX idx_a ON users(a);
CREATE INDEX idx_a_b ON users(a, b); -- idx_a是冗余的!
-- 冗余索引:
CREATE INDEX idx_b_a ON users(b, a); -- 和idx_a_b顺序不同,可能都需要
CREATE INDEX idx_a_b_c ON users(a, b, c); -- 包含idx_a_b的功能3. 内存浪费
MySQL缓冲池大小有限(比如4GB)
理想情况:
数据缓存:3GB
索引缓存:1GB
查询:快速
索引过多时:
数据缓存:2GB
索引缓存:2GB(大量不常用的索引占内存)
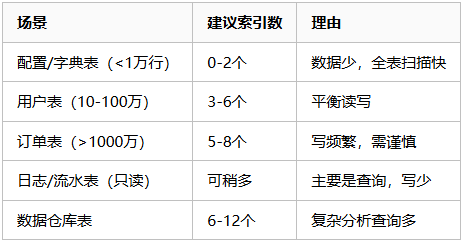
查询:经常需要从磁盘读数据,变慢!🔍 如何判断索引是否过多?
健康指标检查
-- 1. 索引与数据比例
-- 健康:索引大小 < 数据大小
-- 危险:索引大小 > 数据大小
-- 2. 索引数量
-- 小型表(<10万行):3-5个索引
-- 中型表(10万-1000万):5-8个索引
-- 大型表(>1000万):8-12个索引(需严格评估)
-- 3. 索引使用率
SELECT
object_schema,
object_name,
index_name,
rows_read,
rows_inserted,
rows_updated,
rows_deleted
FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE index_name IS NOT NULL
ORDER BY rows_read DESC;
-- 如果rows_read很低,说明索引很少被用找出无用索引
-- MySQL 8.0+ 查看未使用索引
SELECT * FROM sys.schema_unused_indexes;
-- 手动分析(所有版本适用)
SELECT
s.index_name,
s.table_name,
s.rows_selected,
s.rows_inserted,
s.rows_updated,
s.rows_deleted,
CASE
WHEN s.rows_selected < 1000 THEN '考虑删除'
WHEN s.rows_selected < 10000 THEN '观察'
ELSE '保留'
END AS recommendation
FROM (
SELECT
OBJECT_NAME AS table_name,
INDEX_NAME AS index_name,
COUNT_READ AS rows_selected,
COUNT_INSERT AS rows_inserted,
COUNT_UPDATE AS rows_updated,
COUNT_DELETE AS rows_deleted
FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE OBJECT_SCHEMA = DATABASE()
) s
WHERE rows_selected = 0
OR (rows_selected < 100 AND rows_updated > 1000);🎯 最佳索引数量策略
根据业务类型决定
OLTP系统(在线交易,频繁写):
✅ 索引要少而精(3-8个)
✅ 只给高频查询建索引
✅ 定期清理无用索引
OLAP系统(分析报表,频繁读):
✅ 索引可以稍多(8-15个)
✅ 覆盖多种查询模式
✅ 但要注意维护成本索引优先级排序
-- 按重要性创建索引:
1. 主键索引(必须有) -- ⭐⭐⭐⭐⭐
2. 唯一约束索引 -- ⭐⭐⭐⭐⭐
3. 高频查询的WHERE条件列 -- ⭐⭐⭐⭐
4. 高频查询的JOIN条件列 -- ⭐⭐⭐⭐
5. 高频的ORDER BY/GROUP BY列 -- ⭐⭐⭐
6. 覆盖索引(避免回表) -- ⭐⭐⭐
7. 全文索引(文本搜索) -- ⭐⭐
8. 低选择性列索引(如性别) -- ⭐(通常不需要)📝 实战案例:电商系统索引优化
商品表优化前
-- 有15个索引!
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(200),
category_id INT,
price DECIMAL(10,2),
stock INT,
status TINYINT,
created_time DATETIME,
updated_time DATETIME,
-- 各种单列索引
INDEX idx_name (name),
INDEX idx_category (category_id),
INDEX idx_price (price),
INDEX idx_stock (stock),
INDEX idx_status (status),
INDEX idx_created (created_time),
INDEX idx_updated (updated_time),
-- 各种组合索引
INDEX idx_cat_price (category_id, price),
INDEX idx_cat_status (category_id, status),
INDEX idx_price_status (price, status),
-- 还有重复冗余的...
INDEX idx_name_part (name(20)), -- 和idx_name重复
INDEX idx_cat_price_stock (category_id, price, stock)
);问题:写入慢,维护成本高,内存占用大。
优化后
-- 精简到6个核心索引
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(200),
category_id INT,
price DECIMAL(10,2),
stock INT,
status TINYINT,
created_time DATETIME,
updated_time DATETIME,
-- 1. 高频查询:按分类+价格排序
INDEX idx_cat_price_status (category_id, price, status),
-- 2. 高频查询:按状态+创建时间
INDEX idx_status_created (status, created_time),
-- 3. 名称搜索(前缀索引)
INDEX idx_name (name(50)),
-- 4. 库存预警
INDEX idx_stock_status (stock, status),
-- 5. 时间范围查询
INDEX idx_created (created_time),
-- 6. 管理后台复合查询
INDEX idx_cat_created (category_id, created_time)
);效果:写入速度提升40%,内存占用减少60%,查询性能基本不变。
🛠️ 索引管理最佳实践
1. 定期审计
-- 每月执行一次
-- 检查索引使用情况
SELECT * FROM sys.schema_unused_indexes;
-- 检查重复索引
SELECT
a.table_name,
a.index_name AS idx1,
b.index_name AS idx2,
a.column_name
FROM information_schema.statistics a
JOIN information_schema.statistics b
ON a.table_schema = b.table_schema
AND a.table_name = b.table_name
AND a.column_name = b.column_name
AND a.seq_in_index = b.seq_in_index
AND a.index_name != b.index_name
WHERE a.table_schema = DATABASE();2. 使用不可见索引测试
-- MySQL 8.0+ 功能
-- 先让索引不可见,观察影响
ALTER TABLE users ALTER INDEX idx_test INVISIBLE;
-- 运行一段时间业务
-- 如果没影响,再删除
DROP INDEX idx_test ON users;3. 监控写入性能
-- 监控索引对写入的影响
SHOW GLOBAL STATUS LIKE 'Innodb_rows_inserted';
SHOW GLOBAL STATUS LIKE 'Innodb_rows_updated';
SHOW GLOBAL STATUS LIKE 'Innodb_rows_deleted';
-- 计算索引维护成本
-- 如果发现写入性能下降,考虑减少索引💡 黄金法则
索引创建检查清单
✅ 这个查询每天执行多少次?(>100次考虑索引)✅ 这个索引能覆盖多个查询吗?✅ 表的主要操作是读还是写?✅ 索引列的选择性高吗?(>10%)✅ 已有类似索引吗?(避免重复)✅ 索引会占用多少空间?✅ 维护成本能接受吗?
简单决策流程
新查询需要索引吗?
↓
每天执行超过100次? → 否 → 不需要
↓是
有类似索引吗? → 是 → 复用现有索引
↓否
选择性 > 10%? → 否 → 可能不需要
↓是
表写入频繁吗? → 是 → 谨慎评估
↓否
创建索引,监控效果📈 总结:索引数量的平衡点
记住 :🔹 每个索引都是负债 (维护成本)🔹 只有高频查询才值得建索引 🔹 定期清理就像定期大扫除 🔹 质量 > 数量(一个设计良好的复合索引顶三个单列索引)
最终建议:从核心查询开始,按需创建,定期评估,保持精简!
文章转载自: ++佛祖让我来巡山++