在日常MySQL开发中,count()函数是统计数据行数的常用工具,但很多开发者对count(*)、count(字段)、count(1)的区别一知半解,也常困惑于不同存储引擎下count(*)的性能差异。本文将结合实际测试案例,从原理到实践,带你彻底搞懂count(*),并分享3种高效优化count()性能的方案。
一、测试环境搭建
为了让所有结论有数据支撑,我们先搭建统一的测试环境------创建3张不同配置的表(InnoDB带索引、MyISAM、InnoDB无二级索引),并插入测试数据。
1.1 建表语句与存储过程
sql
-- 切换数据库(需提前创建martin库:create database martin;)
use martin;
-- 1. 创建InnoDB引擎表t1(含主键+二级索引)
drop table if exists t1;
CREATE TABLE `t1` (
`id` int NOT NULL AUTO_INCREMENT,
`a` int DEFAULT NULL, -- 允许为null,用于测试count(字段)
`b` int NOT NULL,
`c` int DEFAULT NULL,
`d` int DEFAULT NULL,
PRIMARY KEY (`id`), -- 聚簇索引
KEY `idx_a` (`a`), -- 二级索引
KEY `idx_b` (`b`) -- 二级索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 2. 创建批量插入10000条数据的存储过程
drop procedure if exists insert_t1;
delimiter ;; -- 临时修改语句结束符,避免与存储过程中的;冲突
create procedure insert_t1()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t1(a,b,c,d) values(i,i,i,i); -- 初始数据a无null
set i=i+1;
end while;
end;;
delimiter ; -- 恢复语句结束符
-- 3. 执行存储过程+补充1条a为null的数据
call insert_t1();
insert into t1(a,b,c,d) values (null,10001,10001,10001),(10002,10002,10002,10002);
-- 此时t1共10002行数据,其中1行a为null
-- 4. 创建MyISAM引擎表t2(结构与t1一致,用于对比引擎差异)
drop table if exists t2;
create table t2 like t1;
alter table t2 engine = MyISAM; -- 修改引擎
insert into t2 select * from t1; -- 同步t1数据
-- 5. 创建无二级索引的InnoDB表t3(用于测试索引对count(*)的影响)
drop table if exists t3;
CREATE TABLE `t3` (
`id` int NOT NULL AUTO_INCREMENT,
`a` int DEFAULT NULL,
`b` int NOT NULL,
`c` int DEFAULT NULL,
`d` int DEFAULT NULL,
PRIMARY KEY (`id`) -- 仅聚簇索引
) ENGINE=InnoDB CHARSET=utf8mb4;
insert into t3 select * from t1;二、重新认识count(*):4个核心疑问解答
2.1 count(a)与count(*)的区别:是否统计null?
很多人误以为count(字段)和count(*)功能一致,实则关键差异在是否统计字段为null的行:
count(a):仅统计a字段不为null的行(若字段有null值,会过滤掉);count(*):统计表中所有行(无论字段是否为null,包括全null的行)。
测试验证(基于t1表,10002行,1行a为null):
sql
-- 结果为10001(排除a为null的1行)
select count(a) from t1;
-- 结果为10002(统计所有行)
select count(*) from t1;
2.2 MyISAM与InnoDB:count(*)性能天差地别?
两种主流引擎对count(*)的处理逻辑完全不同,导致性能差异显著:
- MyISAM :会将表的总行数存储在磁盘(仅针对无where子句、无其他列检索的场景),查询时直接读取该值,速度极快;
- InnoDB :需临时扫描表/索引计算行数(因InnoDB支持事务,行数据可能被锁定或版本不同,无法缓存固定行数),速度较慢。
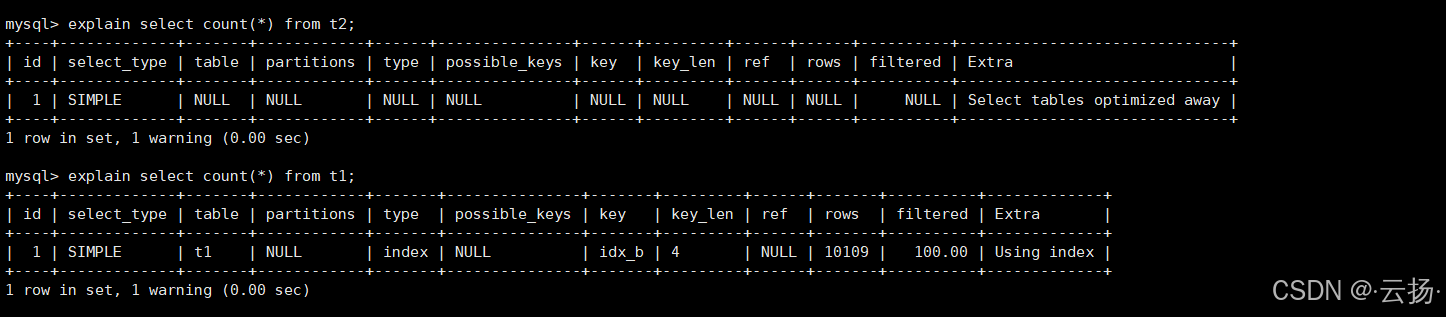
执行计划对比:
sql
-- 1. MyISAM表t2的count(*):Extra为Select tables optimized away,核心含义是:MySQL 通过优化逻辑,直接从索引中获取了所需的全部数据,完全无需访问实际的表,因此 "跳过了表的访问步骤"
explain select count(*) from t2;
-- 2. InnoDB表t1的count(*):type为index,表示 "全索引扫描",而非 "全表扫描",Extra为Using index,表示查询所需的所有信息都能从索引中直接获取,完全不需要回表读取行数据
explain select count(*) from t1;从执行计划可见,MyISAM直接复用预存的行数,而InnoDB需扫描索引计算。
2.3 MySQL 5.7.18+:count(*)为何优先选二级索引?
在MySQL 5.7.18之前,InnoDB的count(*)默认扫描聚簇索引 (主键索引);而5.7.18之后,优化器会优先选择最小的二级索引,原因是:
- 聚簇索引的叶子节点存储整行数据,体积较大;
- 二级索引的叶子节点仅存储主键值,体积远小于聚簇索引,扫描成本更低。
若表无二级索引(如t3表),则仍会扫描聚簇索引。

2.4 count(1)比count(*)快?谣言!
很多开发者认为count(1)性能优于count(*),实则两者结果一致、性能无差异:
count(1):将"1"视为恒真表达式,统计所有行(与count(*)逻辑一致);count(*):MySQL对其有专门优化,不会展开为所有字段,而是直接统计行数。
执行计划验证:
sql
-- 两条语句的执行计划完全一致(均扫描二级索引,rows=10002)
explain select count(1) from t1;
explain select count(*) from t1;结论:无需纠结count(1)和count(*),优先用count(*)更符合语义。

三、3种方法加快count():从"慢统计"到"快查询"
当表数据量达百万/千万级时,InnoDB的count(*)会明显变慢,以下3种方案可根据场景选择:
3.1 场景1:仅需"大概数据量"→ show table status
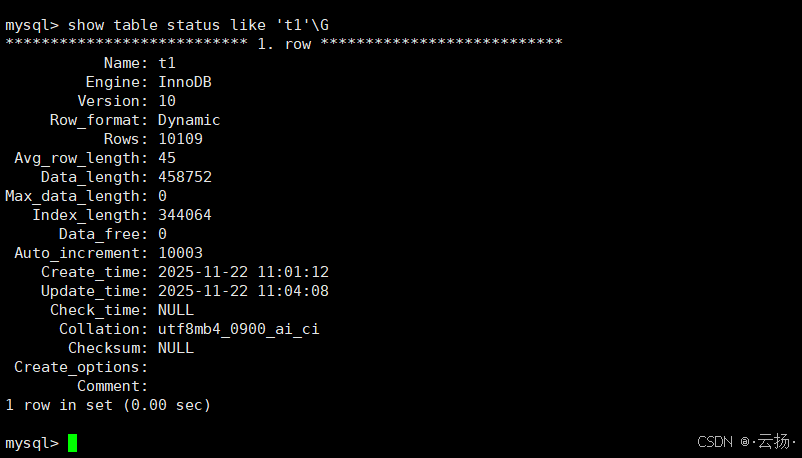
若业务无需精确行数(如后台数据概览),可使用show table status,它直接读取MySQL的表元数据,无需扫描表:
sql
-- 结果中Rows字段即为表的大概行数(t1表约10002行)
show table status like 't1';优缺点 :速度极快,但数据可能有误差(误差通常在10%以内)。
3.2 场景2:需高性能+可接受少量延迟→ Redis计数器
利用Redis的原子操作(INCR/DECR)维护表行数,查询时直接读Redis,避免扫描MySQL表:
步骤1:初始化计数器
sql
-- 1. 先查询MySQL表的初始行数
select count(*) from t1; -- 结果10002
-- 2. 将初始值写入Redis(key为t1_count,值为10002)
set t1_count 10002;步骤2:增删数据时同步更新计数器
sql
-- 插入数据时,Redis计数器+1
insert into t1(a,b,c,d) values (10003,10003,10003,10003);
INCR t1_count; -- Redis命令
-- 删除数据时,Redis计数器-1
delete from t1 where id=10003;
DECR t1_count; -- Redis命令步骤3:查询行数时读Redis
sql
-- 直接获取Redis中的值,耗时微秒级
get t1_count;优缺点:性能极高,但存在"Redis与MySQL数据不一致"风险(如插入MySQL成功但Redis更新失败),适合对一致性要求不严格的场景。
3.3 场景3:需强一致性→ 计数表(InnoDB)
用一张InnoDB表专门存储行数,通过事务保证"数据操作"与"计数更新"的原子性,彻底解决一致性问题:
步骤1:创建计数表
sql
-- 创建count_t1表,仅存储t1的行数
create table count_t1 (
table_name varchar(50) not null primary key, -- 表名(可扩展到多表)
count int not null default 0 -- 行数
);
-- 初始化t1的计数
insert into count_t1(table_name, count) values ('t1', (select count(*) from t1));步骤2:事务中同步增删与计数
sql
-- 插入数据时,在同一事务中更新计数
begin; -- 开启事务
insert into t1(a,b,c,d) values (10003,10003,10003,10003);
update count_t1 set count=count+1 where table_name='t1';
commit; -- 提交事务(要么都成功,要么都失败)
-- 删除数据时同理
begin;
delete from t1 where id=10003;
update count_t1 set count=count-1 where table_name='t1';
commit;步骤3:查询行数时读计数表
sql
-- 直接查询计数表,仅扫描1行,速度极快
select count from count_t1 where table_name='t1';优缺点:强一致性、性能好,但需额外维护计数表,适合对数据一致性要求高的核心业务(如订单数统计)。
四、总结:count(*)使用与优化指南
- 基础选择 :统计所有行用
count(*),统计非null字段用count(字段),无需用count(1); - 引擎差异 :MyISAM适合静态表(行数不变),InnoDB需通过索引优化
count(*); - 优化方案 :
- 概览数据:
show table status; - 高性能低一致性:Redis计数器;
- 强一致性:InnoDB计数表。
- 概览数据:
掌握以上知识,可避免在MySQL计数场景中踩坑,让统计逻辑既高效又可靠。