文章目录
- 前言
- [Clickhouse 表设计](#Clickhouse 表设计)
-
- [adlp_log_local 本地表](#adlp_log_local 本地表)
- [adlp_log 分布式表](#adlp_log 分布式表)
- [Flink SQL 说明](#Flink SQL 说明)
-
- [创建 Source Table (Kafka) 连接器表](#创建 Source Table (Kafka) 连接器表)
- [创建 Sink Table (Clickhouse) 连接器](#创建 Sink Table (Clickhouse) 连接器)
- [解析 Message 写入 Sink](#解析 Message 写入 Sink)
- 日志查询演示
- 总结
前言
在之前的文章中,我们总结了如何在 Django 项目中进行日志配置,以及如何在 k8s 上部署 Filebeat 采集 PVC 中的日志发送至 Kafka:
- Django 日志控制台输出、文件写入按天拆分文件,自定义 Filter 增加 trace_id 以及过滤------日志处理(一)
- Filebeat k8s 部署(Deployment)采集 PVC 日志发送至 Kafka------日志处理(二)
本文将总结如何使用 Flink SQL 实时将 kafka 中的日志消息发送至 Clickhouse 表中。
说明
限于文章主题和篇幅,本文不会将如何部署和使用 Flink SQL, 关于这些内容过多而且网上资料也很多,就不再赘述。
本文的核心是说明如何设计 Clickhouse 表结构,以及对应的 Flink SQL 说明。
Clickhouse 表设计
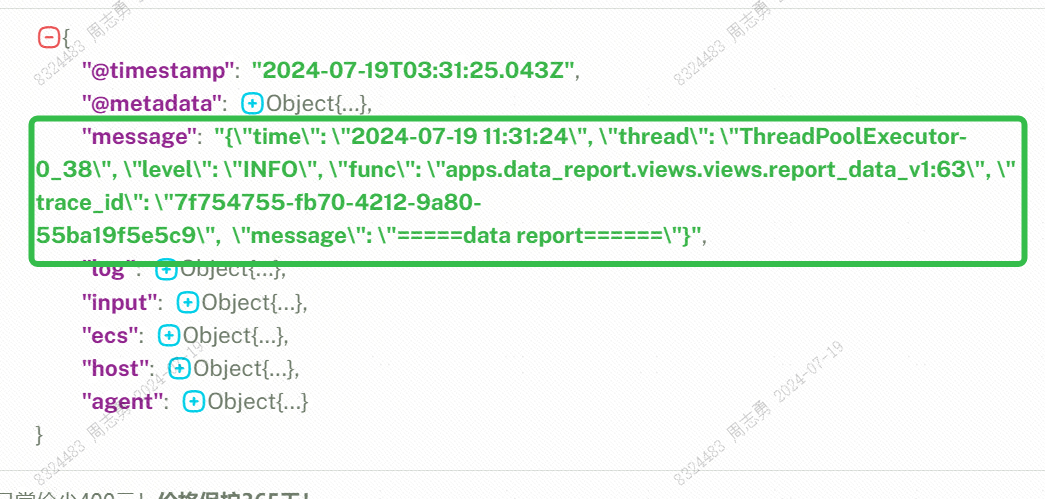
上图中的JSON 内容是kafka 中的日志消息,我们需要读取该消息中的 message 字段(我们的日志信息),然后将该字段中的 time, level, func, trace_id, message 保存至 clickhouse 中。
这里我使用两张表保存日志:
adlp_log_local本地表adlp_log分布式表,FlinkSQL 实时写入分布式表
adlp_log_local 本地表
python
create table if not exists cloud_data.adlp_log_local on cluster perftest_5shards_2replicas
(
`dt` DateTime64(3),
`level` LowCardinality(String),
`trace_id` String,
`func` String,
`message` String,
-- 建立索引加速低命中率内容的查询
INDEX idx_trace_id `trace_id` TYPE tokenbf_v1(4096, 2, 0) GRANULARITY 2,
INDEX idx_message `message` TYPE tokenbf_v1(30720, 2, 0) GRANULARITY 1
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/cloud_data/adlp_log_local', '{replica}')
PARTITION BY toYYYYMMDD(dt)
PRIMARY KEY (dt, trace_id)
ORDER BY (dt, trace_id)
TTL toDateTime(dt) + toIntervalDay(30);字段说明
dt(DateTime64(3)): 存储日志时间戳,精确到毫秒。level(LowCardinality(String)) : 存储日志级别,如INFO、ERROR等,使用LowCardinality优化存储和查询。trace_id(String): 存储追踪 ID,通常用于关联一系列相关的日志记录。func(String): 存储函数或方法名称,表示日志产生的位置。message(String): 存储日志消息的具体内容。
索引
idx_trace_id: 使用tokenbf_v1类型的布隆过滤器索引(tokenbf_v1(4096, 2, 0)),在trace_id字段上创建,粒度为 2。布隆过滤器索引适合低命中率的查询,能够快速过滤出大多数不匹配的记录。idx_message: 使用tokenbf_v1类型的布隆过滤器索引(tokenbf_v1(30720, 2, 0)),在message字段上创建,粒度为 1。同样用于加速低命中率的查询。
存储引擎
ReplicatedMergeTree: 使用分布式和复制的存储引擎,路径模板为/clickhouse/tables/{layer}-{shard}/cloud_data/adlp_log_local,副本名称为{replica},保证数据的高可用性和一致性。
分区和排序
- 分区 (PARTITION BY): 按
dt字段的年月日(toYYYYMMDD(dt))进行分区,有助于管理和查询按天划分的数据。 - 主键 (PRIMARY KEY): 主键由
dt和trace_id组成,有助于高效查询。 - 排序 (ORDER BY): 按
dt和trace_id字段排序,优化基于时间和 trace ID 的查询。
数据生命周期 (TTL)
- TTL (Time To Live) : 配置数据的生存时间,数据在
dt字段的时间加上 30 天后自动过期删除,保持数据表的清洁和高效。
adlp_log 分布式表
python
create table if not exists cloud_data.adlp_log on cluster perftest_5shards_2replicas
(
`dt` DateTime64(3),
`level` LowCardinality(String),
`trace_id` String,
`func` String,
`message` String
)
ENGINE = Distributed('perftest_5shards_2replicas', 'cloud_data', 'adlp_log_local', rand());字段说明
与本地表 adlp_log_local 相同,包含以下字段:
dt(DateTime64(3))level(LowCardinality(String))trace_id(String)func(String)message(String)
存储引擎
Distributed: 分布式引擎,允许将数据分布到多个分片和副本中。参数解释如下:
- 集群名称 (
perftest_5shards_2replicas): 指定集群的名称。 - 数据库 (
cloud_data): 数据库名称。 - 表 (
adlp_log_local): 本地表的名称。 - 分片键 (
rand()) : 使用随机函数进行数据分片,保证数据均匀分布。
Flink SQL 说明
创建 Source Table (Kafka) 连接器表
python
CREATE TEMPORARY TABLE source_table (
message STRING
) WITH (
'connector' = 'kafka',
'topic' = 'filebeat_logs',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'properties.group.id' = 'prod-logs-k2c',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.ignore-parse-errors' = 'false',
'json.fail-on-missing-field' = 'false',
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.sasl.mechanism' = 'PLAIN',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin";'
);创建 Sink Table (Clickhouse) 连接器
python
CREATE TEMPORARY TABLE sink_table (
`dt` TIMESTAMP(3),
`level` STRING ,
`trace_id` STRING ,
`func` STRING ,
`message` STRING
) WITH (
'connector' = 'clickhouse',
'url' = 'clickhouse://127.0.0.1:8123',
'username' = 'admin',
'password' = 'admin',
'database-name' = 'cloud_data',
'table-name' = 'adlp_log',
'use-local' = 'true',
'sink.batch-size' = '1000',
'sink.flush-interval' = '1000',
'sink.max-retries' = '10',
'sink.update-strategy' = 'insert',
'sink.sharding.use-table-definition' = 'true',
'sink.parallelism' = '1'
);解析 Message 写入 Sink
python
INSERT INTO sink_table
SELECT
TO_TIMESTAMP(JSON_VALUE(message, '$.time'), 'yyyy-MM-dd HH:mm:ss') AS dt,
JSON_VALUE(message, '$.level') AS level,
JSON_VALUE(message, '$.trace_id') AS trace_id,
JSON_VALUE(message, '$.func') AS func,
JSON_VALUE(message, '$.message') AS message
FROM source_table;注意:
这里在写入的时候默认我们的日志格式是 JSON 的,如果我们的日志发送到 kafka 不是 JSON 格式的,上边的 JSON_VALUE 可能会报错。当然,我们也可以在条件中加上是否为 JSON 判断,但是我觉得没必要。
日志查询演示
我们的日志导入成功后,可以通过第三方查询工具查询 clickhouse 数据源,我这里使用的是 superset 去查询 clickhouse 数据源。
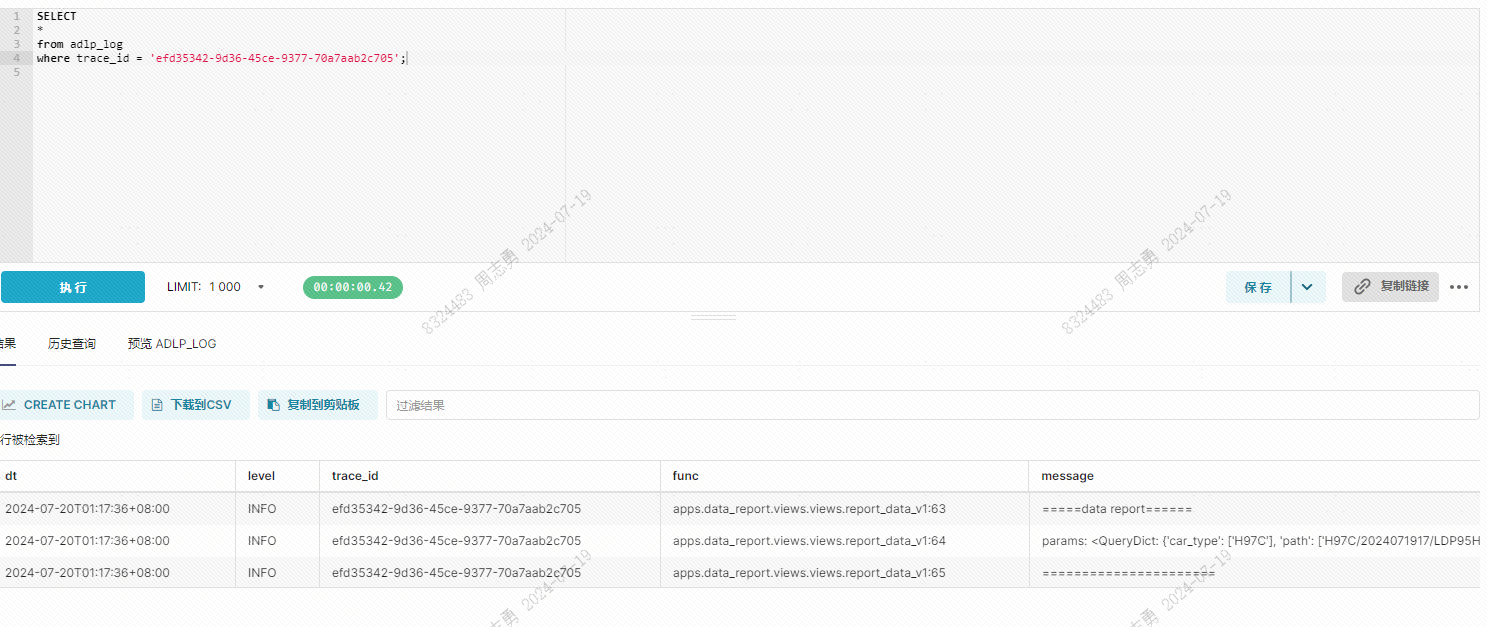
通过 trace_id 查询整个执行链路的日志
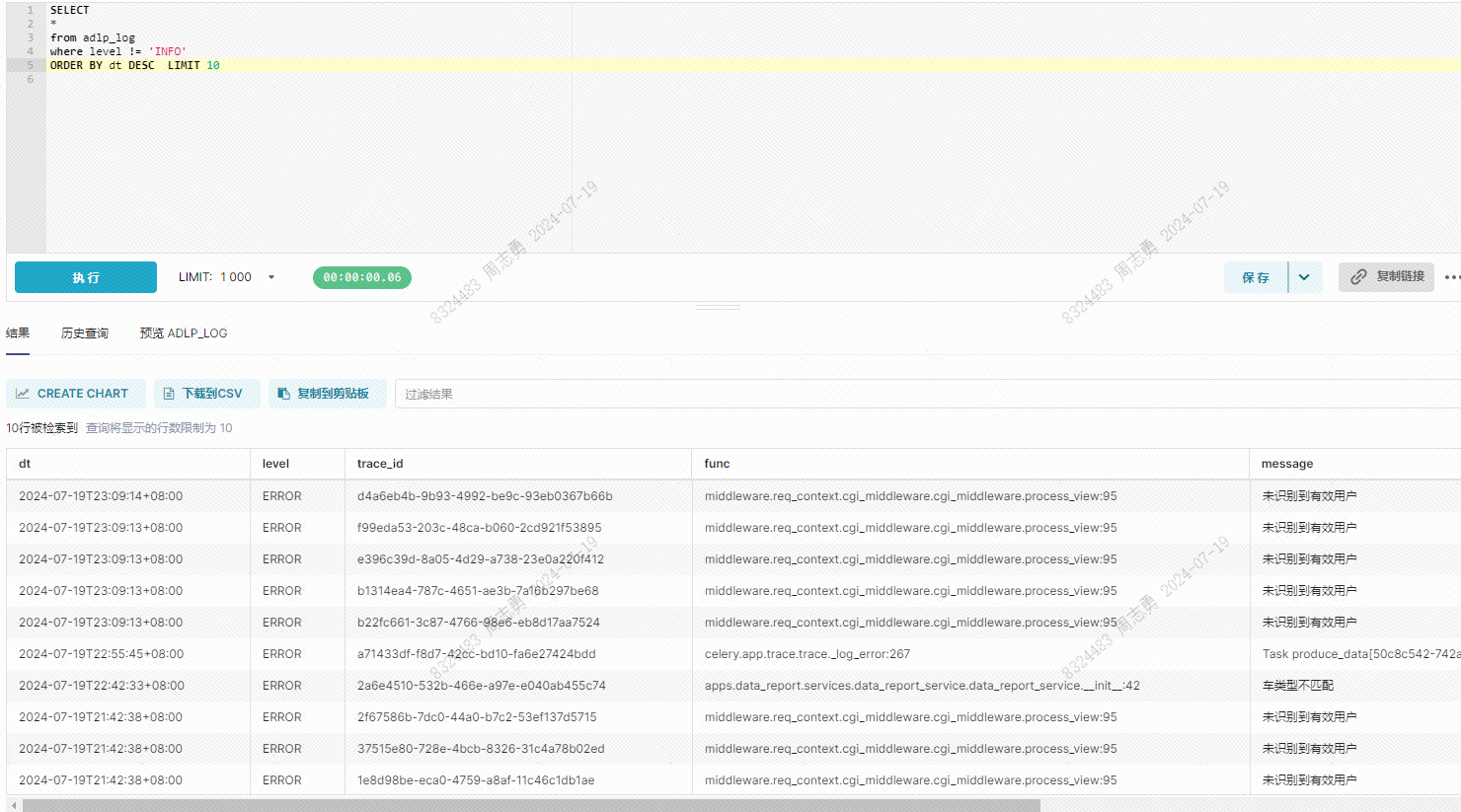
查询错误日志信息
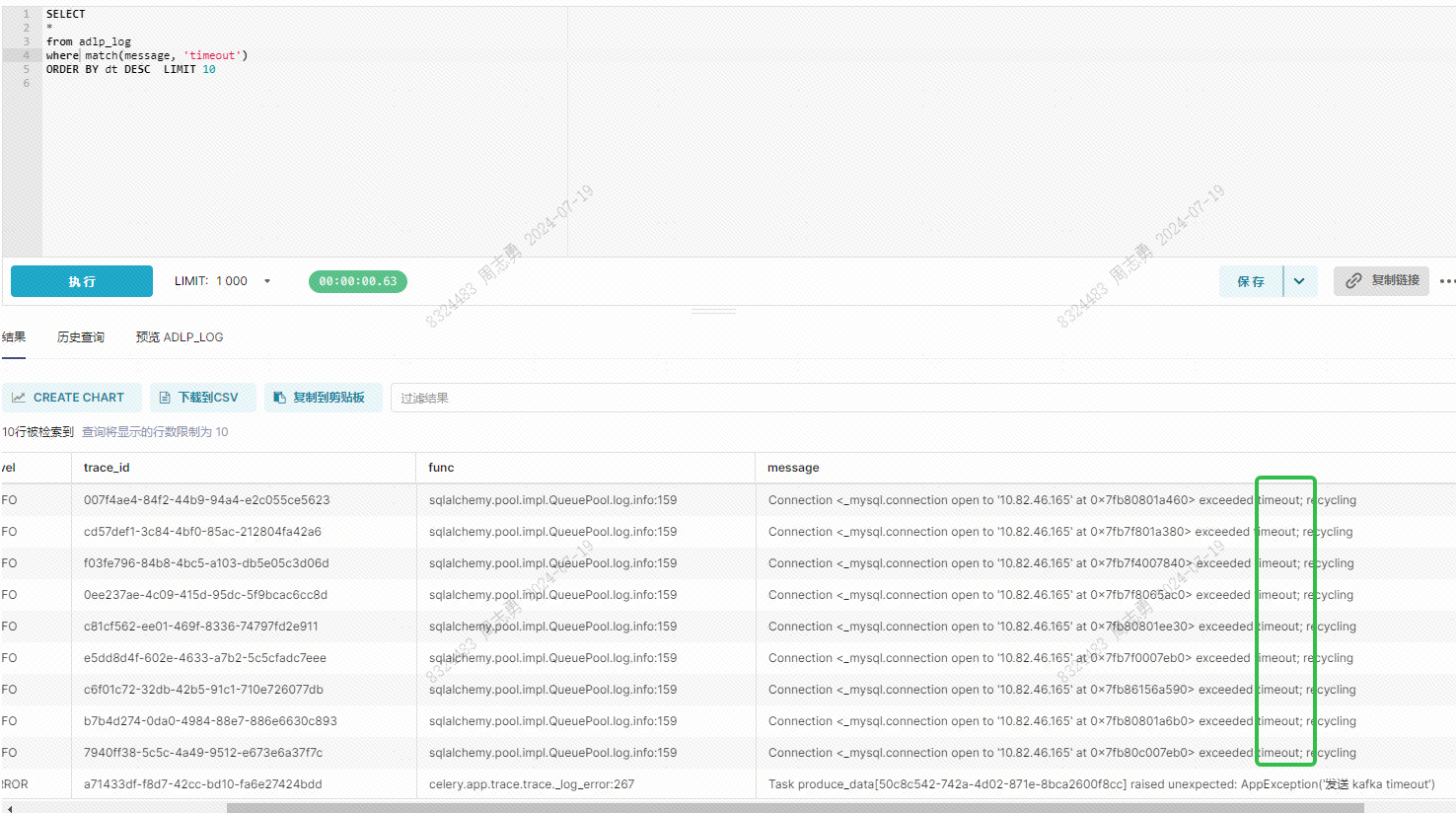
全文检索 message 日志信息
更多扩展
- superset 是一个强大的 BI 工具,可以将我们的日志中的一些指标做成看板,比如说关键错误日志数量,然后设置告警,发送通知。
- 通过 Flink SQL 实时将我们的日志从 kafka 中写入 clickhouse ,结合 clickhouse 强大的查询功能,以及 superset 强大的 BI 功能,可以充分挖掘业务日志中的潜在价值。
总结
本文总结了如何使用使用 Clickhouse 保存日志数据,以及如何通过 Flink SQL 将我们的日志实时从 kafka 同步至 clickhouse,然后在结合强大的第三方查询 BI 工具 superset,玩转业务日志,挖掘业务日志的潜在价值。
本文设计到的技能知识点比较多,需要熟悉 Clickhouse, Kafka, FlinkSQL, Superset 等,我之前的文章中总结了一些关于 Clickhouse 和 Kafka 相关的内容,感兴趣的读者可以看看:
clickhouse
kafka
superset