全球AI领导者英伟达(Nvidia)和著名开源大模型平台Mistral.ai联合开源了,企业级大模型Mistral NeMo 12B。(以下简称"MN 12B")
据悉,MN 12B一共有基础和指令微调两种模型,支持128K上下文长度,能生成文本、代码、摘要等,其性能比最新开源的Gemma 2更好。
基础模型开源地址:https://huggingface.co/mistralai/Mistral-Nemo-Base-2407
指令微调模型:https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407


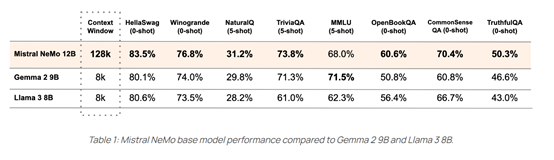
MN 12B在多轮对话、数学、常识推理、世界知识以及编码方面表现出色,比谷歌开源的Gemma 2 9B、Meta开源的Llama 3 8B 性能更好。支持128K的上下文长度,能够更连贯、更准确地处理大量复杂信息。
MN 12B以Apache 2.0许可证发布,允许企业、个人开发者进行商业化基础训练和微调。此外,模型采用FP8数据格式进行模型推理,极大减少了内存大小并加快了部署速度,同时没有任何准确性的降低。这意味着模型可以更好地学习任务,更有效地处理多样化的场景,使其非常适合企业级业务用例。
MN 12B作为NVIDIA NIM推理微服务的一部分,使用了NVIDIA TensorRT-LLM引擎的优化推理性能。这种容器化格式允许在任何地方轻松部署,为各种应用提供了增强的灵活性,模型可以在几分钟内部署在任何地方,无需耗费几天的时间。
在多语言方面,MN 12B支持英语、中文、法语、德语、西班牙语、意大利语、葡萄牙语、日语、韩语、阿拉伯语等主流语言,在MMLU等多语言基准测试中超过了同类开源模型。

此外,MN 12B使用了一种基于Tiktoken的更高效分词器Tekken。该分词器经过100多种语言的训练,比之前Mistral模型中使用的 SentencePiece 分词器更有效地压缩自然语言文本和源代码。
尤其是在压缩源代码、中文、意大利语、法语、德语、西班牙语和俄语时,效率提升了大约30%。在压缩韩语和阿拉伯语时效率相比之前,分别提升了2倍和3倍。
Mistral AI的创始人兼首席科学家Guillaume Lample表示,Mistral NeMo结合了Mistral AI在训练数据方面的专长与NVIDIA优化的硬件和软件生态系统为各种应用场景提供了高性能。
本次与NVIDIA团队的合作,借助其顶级的硬件和软件,共同开发出了具有前所未有的准确度、灵活性、高效性的企业级大模型。
本文素材来源英伟达官网,如有侵权请联系删除
END