概叙
很多时候,一套代码要适配多种数据库,主流的三种库:MySQL、Oracle、PostGresql,刚好mybatis支持这种扩展,如下图所示,在一个"namespace",判断唯一的标志是id+databaseId,刚好写了三个同样的方法,一个不带databaseId,两个带databaseId,此时当前库如果连接的是oracle则执行databaseId='oracle'的方法,如果连接的是MySQL则执行databaseId='mysql'的方法。不带databaseId的方法,只有在不写databaseId的方法且唯一只有一个不带databaseId方式时才会被执行。
不足:本文中mybatis虽然可以适配多种类型的数据库,但是启动后,只支持一种库;即要么连接oracle,要么连接MySQL,不能同时连接和操作两种库。
思考:如何改进不足,同时支持操作多种库?如果用原生的jdbc很好解决,但是我们用的是mybatis框架,如何让mybatis支持同时操作多种数据库?(动态数据源,其实和jdbc一样,系统启动时,就要初始化好多种库的连接,然后动态切换;具体实现,大家可以自行试试)

详细的我们接着往后看
一、启用数据库识别DatabaseIdProvider
1. 调查数据库产品名
要想做兼容多种数据库,那毫无疑问,我们首先得明确我们要兼容哪些数据库,他们的数据库产品名称是什么。得益于SPI设计,java语言制定了一个java.sql.DatabaseMetaData接口(jdbc接口),要求各个数据库的驱动都必须提供自己的产品名。因此我们如果想要兼容某数据库,只要在对应的驱动包中找到其对DatabaseMetaData的实现即可。

比如Mysql的驱动包 mysql-connector-java 下的 DatabaseMetaData

Oracle 的驱动包 com.oracle.ojdbc6 下的 OracleDatabaseMetaData

DatabaseMetaData接口是由JDBC驱动程序实现的,用于提供底层数据源相关的信息。该接口主要用于为应用程序或工具确定如何与底层数据源交互。应用程序也可以使用DatabaseMetaData接口提供的方法获取数据源信息。
DatabaseMetaData接口中包含超过150个方法,根据这些方法的类型可以分为以下几类:
(1)获取数据源信息。
(2)确定数据源是否支持某一特性或功能。
(3)获取数据源的限制。
(4)确定数据源包含哪些SQL对象以及这些对象的属性。
(5)获取数据源对事务的支持。
创建DatabaseMetaData对象
DatabaseMetaData对象的创建比较简单,需要依赖Connection对象。Connection对象中提供了一个getMetadata()方法,用于创建DatabaseMetaData对象。
一旦创建了DatabaseMetaData对象,我们就可以通过该对象动态地获取数据源相关的信息了。下面是创建DatabaseMetaData对象并使用该对象获取数据库表名允许的最大字符数的案例,代码如下:
Connection connection = DriverManager.getConnection("jdbc:mysql://XXXX/demo",
"XXXX",
"XXXX");
DatabaseMetaData dmd = connection.getMetaData();获取数据源的基本信息
//获取数据源的基本信息
System.out.println("数据库URL:" + dmd.getURL());
System.out.println("数据库用户名:" + dmd.getUserName());
System.out.println("数据库产品名:" + dmd.getDatabaseProductName());
System.out.println("数据库产品版本:" + dmd.getDatabaseProductVersion());
System.out.println("驱动主版本:" + dmd.getDriverMajorVersion());
System.out.println("驱动副版本:" + dmd.getDriverMinorVersion());
System.out.println("数据库供应商用于schema的首选术语:" + dmd.getSchemaTerm());
System.out.println("数据库供应商用于catalog的首选术语:" + dmd.getCatalogTerm());
System.out.println("数据库供应商用于procedure的首选术语:" + dmd.getProcedureTerm());
System.out.println("null值是否高排序:" + dmd.nullsAreSortedHigh());
System.out.println("null值是否低排序:" + dmd.nullsAreSortedLow());
System.out.println("数据库是否将表存储在本地文件中:" + dmd.usesLocalFiles());
System.out.println("数据库是否为每个表使用一个文件:" + dmd.usesLocalFilePerTable());
System.out.println("数据库SQL关键字:" + dmd.getSQLKeywords());**注意:**由于HSQLDB驱动对DatabaseMetaData接口的getSQLKeywords()方法没有任何实现逻辑,只返回一个空字符串,因此上面的代码获取数据库SQL关键字内容为空。
获取数据源支持特性
DatabaseMetaData接口中提供了大量的方法用于确定数据源是否支持某个或一组特定的特性。除此之外,有些方法用于描述数据源对某一特性的支持级别。
获取数据源限制
获取SQL对象及属性
获取SQL对象及属性
2. 启用databaseId
既然各个驱动都提供了产品名,那么接下来就是让项目在启动中能够识别这些数据库,并赋予以不同数据库不同的id。MyBatis 其实有这项功能,但是这个功能默认没有被启用,若要启用我们首先得建立一个配置,即databaseIdProvider,可以在配置类里面加上这个Bean来实现
java
@Bean
public DatabaseIdProvider databaseIdProvider() throws SQLException {
DatabaseIdProvider databaseIdProvider = new VendorDatabaseIdProvider();
Properties properties = new Properties();
// Key值(即产品名)来源于数据库,需要提前查清楚 ,
// value值(即databaseId)可以随便填,你填"1" "2" "3"也行,但建议有明确意义,像下面这样
properties.setProperty("0racle", "oracle");
properties.setProperty("MySQL", "mysql");
properties.setProperty("DB2", "db2");
properties.setProperty("Derby", "derby");
properties.setProperty("H2", "h2");
properties.setProperty("HSQL", "hsql");
properties.setProperty("Informix", "informix");
properties.setProperty("MS-SQL", "ms-sql");
properties.setProperty("PostgresqL", "racle");
properties.setProperty("sybase", "sybase");
properties.setProperty("Hana", "hana");
databaseIdProvider.setProperties(properties);
return databaseIdProvider;
}
@Bean
public SqlSessionFactory testdbSqlSessionFactory(@Qualifier("testdbDataSource") DataSource testdbDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(testdbDataSource);
//set 注入databaseIdProvider 到当前SqlSessionFactoryBean
sessionFactory.setDatabaseIdProvider(databaseIdProvider());
sessionFactory.setMapperLocations(
new PathMatchingResourcePatternResolver().getResources(TestDbDataSourceConfig.MAPPER_LOCATION));
return sessionFactory.getObject();
}完成了上述配置后,我们的项目就能主动去识别数据库类型了。
二、SQL语法鉴别
对于大部分SQL,因为有SQL规范的限制,它们通常是通用的,一段SQL可以在不同的数据库上跑。但是对于部分复杂SQL,就得针对不同数据库,来写不同的SQL了,我们以Mysql 、 Oracle 为例,看一些常见功能的语法差异
1. 分页查询
MySQL中使用LIMIT关键字来实现分页查询,例如:
|---|-----------------------------------------------------------|
| 1 | SELECT * ``FROM table_name LIMIT offset, ``count``; |
而Oracle中使用ROWNUM关键字来实现分页查询,例如:
|-----------|--------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 | SELECT * FROM (``SELECT t.*, ROWNUM ``AS rn ``FROM table_name t ``WHERE ROWNUM <= offset + ``count``) WHERE rn > offset; |
2. 获取当前时间
MySQL中可以使用NOW()函数来获取当前时间,例如:
|---|-------------------|
| 1 | SELECT NOW(); |
而Oracle中可以使用SYSDATE关键字来获取当前时间,例如:
|---|-----------------------------------|
| 1 | SELECT SYSDATE ``FROM DUAL; |
3. 获取自增主键的值
MySQL中可以使用LAST_INSERT_ID()函数来获取最后插入行的自动生成的主键值,例如:
|-----|----------------------------------------------------------------------------------------------------------|
| 1 2 | INSERT INTO table_name (column1, column2) ``VALUES``(value1, value2); SELECT LAST_INSERT_ID(); |
而Oracle中可以使用SEQUENCE和CURRVAL来获取自增主键的值,例如:
|-----|------------------------------------------------------------------------------------------------------------------------|
| 1 2 | INSERT INTO table_name (column1, column2) ``VALUES``(seq.nextval, value2); SELECT seq.currval ``from dual; |
4. 转换数据类型
MySQL 使用 CAST() 或 CONVERT() 函数转换数据类型,例如:
|-------|--------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 | SELECT CAST``(``'123' AS SIGNED) ``AS converted_value; -- 或者 SELECT CONVERT``(``'123'``, SIGNED) ``AS converted_value; |
而Oracle使用 TO_NUMBER(), TO_CHAR(), TO_DATE() 等函数进行数据类型转换,例如:
|-----|------------------------------------------------------------------------------------------------------------------------|
| 1 2 | INSERT INTO table_name (column1, column2) ``VALUES``(seq.nextval, value2); SELECT seq.currval ``from dual; |
5. 字符串拼接
MySQL中可以使用CONCAT()函数来进行字符串拼接,例如:
|---|----------------------------------------------------------|
| 1 | SELECT CONCAT(column1, column2) ``FROM table_name; |
而Oracle中可以使用||运算符来进行字符串拼接,例如:
|---|----------------------------------------------------|
| 1 | SELECT column1 || column2 ``FROM table_name; |
6. 字符串截取
MySQL 使用 SUBSTRING() 函数,例如:
|---|--------------------------------------------------------------------------|
| 1 | SELECT SUBSTRING``(``'Hello World'``, 1, 5) ``AS substring_result; |
而Oracle 使用 SUBSTR() 函数,例如:
|---|-----------------------------------------------------------------------------------|
| 1 | SELECT SUBSTR(``'Hello World'``, 1, 5) ``AS substring_result ``FROM DUAL; |
7. 判空函数
MySQL中可以使用IFNULL()函数来进行字符串拼接,例如:
|---|----------------------------------------------------------|
| 1 | SELECT IFNULL(column1, ``"1"``) ``FROM table_name; |
而Oracle中可以使用NVL()来进行字符串拼接,例如:
|---|-------------------------------------------------------|
| 1 | SELECT NVL(column1, ``"1"``) ``FROM table_name; |
8. 正则表达式
MySQL 使用 REGEXP 或 RLIKE 进行正则表达式匹配,例如:
|---|-----------------------------------------------------------------|
| 1 | SELECT 'Hello World' REGEXP ``'^Hello' AS is_matched; |
而Oracle 使用 REGEXP_LIKE, REGEXP_INSTR, REGEXP_SUBSTR, 和 REGEXP_REPLACE 等函数,例如:
|---|--------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | SELECT CASE WHEN REGEXP_LIKE(``'Hello World'``, ``'^Hello'``) ``THEN 'Matched' ELSE 'Not Matched' END AS is_matched ``FROM DUAL; |
9. 窗口函数
MySQL 低版本不支持窗口函数,可以使用自连接模拟窗口函数,例如:
|-----------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 | SELECT t1.* FROM table_name t1 LEFT JOIN table_name t2 ON t1.column_name = t2.column_name ``AND t1.order_column > t2.order_column WHERE t2.column_name ``IS NULL``; |
而Oracle 或 MySQL高版本则可以 使用 窗口函数,例如:
|---------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 | SELECT * FROM (``SELECT *, ROW_NUMBER() OVER (PARTITION ``BY column_name ``ORDER BY order_column) ``as rn ``FROM table_name) ``as t WHERE rn = 1; |
三、SQL兼容处理
如果我们的项目有SQL语法不兼容的情况,如上面那些场景,那么我们就需要对这些SQL做特殊处理了,比如一个常用的功能,获取当前数据库时间。我们需要在同一个XML文件中写两份,注意两份SQL的 databaseId 是不同的,而不同数据库的 databaseId 是什么,则依赖我们最开始维护的databaseIdProvider 里的value值了
|----------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 | <``select id = ``"getSysDateTime" databaseId=``"oracle"``> ``select ``TO_CHAR (sysdate, ``'yyyyMMdd'``) sys_date, ``TO_CHAR (sysdate, ``'HH24miss'``) sys_time ``from dual </``select``> <``select id = ``"getSysDateTime" databaseId=``"mysql"``> ``select ``date_format (now(), ``'%Y%m%d'``) sys_date, ``date_format (now(), ``'%H%i%s'``) sys_time ``from dual </``select``> |
而一些可以跑在所有平台的SQL,则不需要改造,即databaseId不要填,如
|---------|------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 | <``select id = ``"getUserInfo" resultType = ``"UserInfo"``> ``select user_name, user_age ``from USERINFO </``select``> |
四、运行原理
做完上述步骤后,我们的项目就能在多种数据库环境运行了,而其内部原理,其实也非常简答
1. 配置载入
在项目启动的时候,MyBatis 需要创建会话工厂,其中就有如下代码,他的意义很明确,就是找到当前连接的数据库,对应的是什么databaseId。并且将这个值保存进配置中。
|----------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 | // SqlSessionFactoryBean protected SqlSessionFactory buildSqlSessionFactory() ``throws Exception { ``// 省略无关代码 ``if (``this``.databaseIdProvider != ``null``) { ``try { ``targetConfiguration.setDatabaseId(``this``.databaseIdProvider.getDatabaseId(``this``.dataSource)); ``} ``catch (SQLException e) { ``throw new NestedIOException(``"Failed getting a databaseId"``, e); ``} ``} ``// 省略无关代码 } |
2. SQL选择
我们在 Mybatis之动态SQL使用小结(全网最新)中介绍过MyBatis的启动流程,其中就有对xml文件的解析,而我们现在在一个xml中写了多个id相同的SQL,MyBatis会怎么做呢?
|-------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | // XMLMapperBuilder ``private void buildStatementFromContext(List<``XNode``> list) { ``// 如果当前环境有DatabaseId,则以这个DatabaseId去加载对应的SQL ``if (configuration.getDatabaseId() != null) { ``buildStatementFromContext(list, configuration.getDatabaseId()); ``} ``// 兜底,把某些没有指明DatabaseId的SQL加载进来 ``buildStatementFromContext(list, null); ``} ``private void buildStatementFromContext(List<``XNode``> list, String requiredDatabaseId) { ``for (XNode context : list) { ``final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId); ``try { ``statementParser.parseStatementNode(); ``} catch (IncompleteElementException e) { ``configuration.addIncompleteStatement(statementParser); ``} ``} ``} |
可以看到对于一个XML文件的解析,会先后以指定databaseId 和无指定databaseId 两种情况去解析
|----------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | // XMLStatementBuilder ``public void parseStatementNode() { ``String id = context.getStringAttribute(``"id"``); ``String databaseId = context.getStringAttribute(``"databaseId"``); ``if (!databaseIdMatchesCurrent(id, databaseId, ``this``.requiredDatabaseId)) { ``return``; ``} ``// 省略无关代码 } ``private boolean databaseIdMatchesCurrent(String id, String databaseId, String requiredDatabaseId) { ``if (requiredDatabaseId != ``null``) { ``return requiredDatabaseId.equals(databaseId); ``} ``if (databaseId != ``null``) { ``return false``; ``} ``id = builderAssistant.applyCurrentNamespace(id, ``false``); ``if (!``this``.configuration.hasStatement(id, ``false``)) { ``return true``; ``} ``// skip this statement if there is a previous one with a not null databaseId ``MappedStatement previous = ``this``.configuration.getMappedStatement(id, ``false``); ``// issue #2 ``return previous.getDatabaseId() == ``null``; ``} |
可以看到,在读取每一段SQL块的时候,会判断SQL上标注的databaseId是否符合当前数据库环境,只有符合的才会被解析。
五、坑点
1. 避免歧义
不难发现,因为兜底逻辑的存在,有时可能会存在歧义,假设我们在mysql环境,我们写下这样的代码,是不是会把两段都解析掉?
|----------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 | <select id = "getSysDateTime" databaseId="mysql"> ``select ``date_format (now(), '%Y%m%d') sys_date, ``date_format (now(), '%H%i%s') sys_time ``from dual </select> <select id = "getSysDateTime"> ``select ``TO_CHAR (sysdate, 'yyyyMMdd') sys_date, ``TO_CHAR (sysdate, 'HH24miss') sys_time ``from dual </select> |
其实是不会的,因为在解析完后我们会把解析的结果存入一个map中,它的key值就是每一块的id,因为这个map是个内部定义的StrictMap,如下

|-------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | @Override @SuppressWarnings``(``"unchecked"``) public V put(String key, V value) { ``if (containsKey(key)) { ``throw new IllegalArgumentException(name + ``" already contains value for " + key ``+ (conflictMessageProducer == ``null ? ``"" : conflictMessageProducer.apply(``super``.get(key), value))); ``} ``if (key.contains(``"."``)) { ``final String shortKey = getShortName(key); ``if (``super``.get(shortKey) == ``null``) { ``super``.put(shortKey, value); ``} ``else { ``super``.put(shortKey, (V) ``new Ambiguity(shortKey)); ``} ``} ``return super``.put(key, value); } |
不难发现,一旦有两个id冲突(同一个命名空间下)直接就会报错,所以我们要知道,每一个id实际上只会被存储一次,我们应尽量避免出现歧义的写法
2. 复杂数据库场景
对于大部分场景,按照上面的做法就能解决,但是仍有部分场景是需要特殊处理的,比如同一个数据库的不同版本。
比如说都属于 MySQL 族,但是 MySQL 下又分 5.7 或 8.0,有些语法在低版本上不支持,又或者与Percona 和 Maria-db 等不兼容
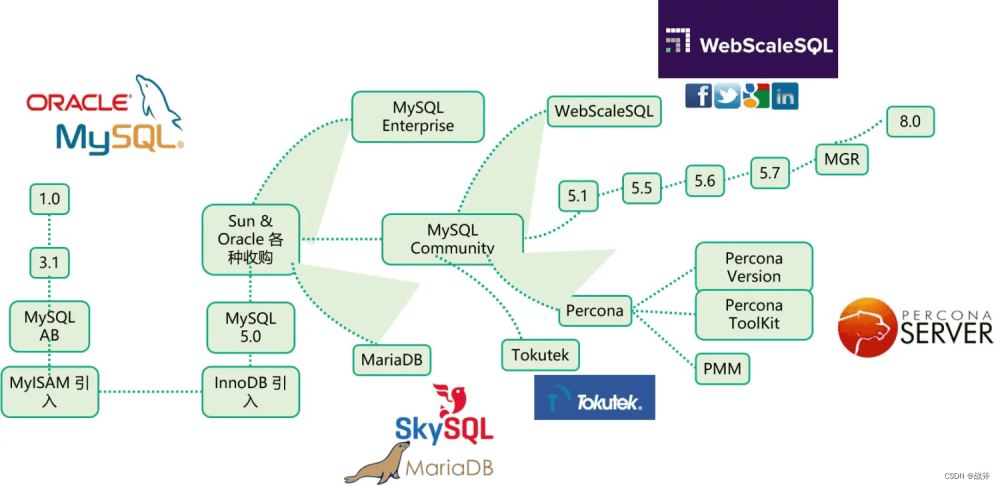
此时就需要使用通用性SQL来写了,一般都是顺着低版本来写,但往往也是性能最差的写法。
Mybatis 类型映射
Mybatis 类型处理器映射关系图
这里列出一些默认的类型处理器处理JAVA与JDBC数据类型的映射关系图:


mybatis jdbcType与PostGreSQL数据类型对应表

mybatis jdbcType与Oracle mysql数据类型对应表
| Mybatis | JdbcType | Oracle | MySql |
|---|---|---|---|
| JdbcType | ARRAY | ||
| JdbcType | BIGINT | BIGINT | |
| JdbcType | BINARY | ||
| JdbcType | BIT | BIT | |
| JdbcType | BLOB | BLOB | BLOB |
| JdbcType | BOOLEAN | ||
| JdbcType | CHAR | CHAR | CHAR |
| JdbcType | CLOB | CLOB | CLOB |
| JdbcType | CURSOR | ||
| JdbcType | DATE | DATE | DATE |
| JdbcType | DECIMAL | DECIMAL | DECIMAL |
| JdbcType | DOUBLE | NUMBER | DOUBLE |
| JdbcType | FLOAT | FLOAT | FLOAT |
| JdbcType | INTEGER | INTEGER | INTEGER |
| JdbcType | LONGVARBINARY | ||
| JdbcType | LONGVARCHAR | LONG VARCHAR | |
| JdbcType | NCHAR | NCHAR | |
| JdbcType | NCLOB | NCLOB | |
| JdbcType | NULL | ||
| JdbcType | NUMERIC | NUMERIC/NUMBER | NUMERIC/ |
| JdbcType | NVARCHAR | ||
| JdbcType | OTHER | ||
| JdbcType | REAL | REAL | REAL |
| JdbcType | SMALLINT | SMALLINT | SMALLINT |
| JdbcType | STRUCT | ||
| JdbcType | TIME | TIME | |
| JdbcType | TIMESTAMP | TIMESTAMP | TIMESTAMP |
| JdbcType | TINYINT | TINYINT | |
| JdbcType | UNDEFINED | ||
| JdbcType | VARBINARY | ||
| JdbcType | VARCHAR | VARCHAR | VARCHAR |
mybatis的jdbcType中部分没有对应的oracle和mysql的数据类型中,后续碰到再具体分析。
更新日志
Mysql中没有CLOB类型
