哎呀,Meta声称将于今晚发布的Llama 3.1,数小时前就在Hugging Face上泄露出来了?泄露的人很有可能是Meta员工?

还是先来看泄露出来的llama3.1吧。新的Llama 3.1模型包括8B、70B、405B三个版本。
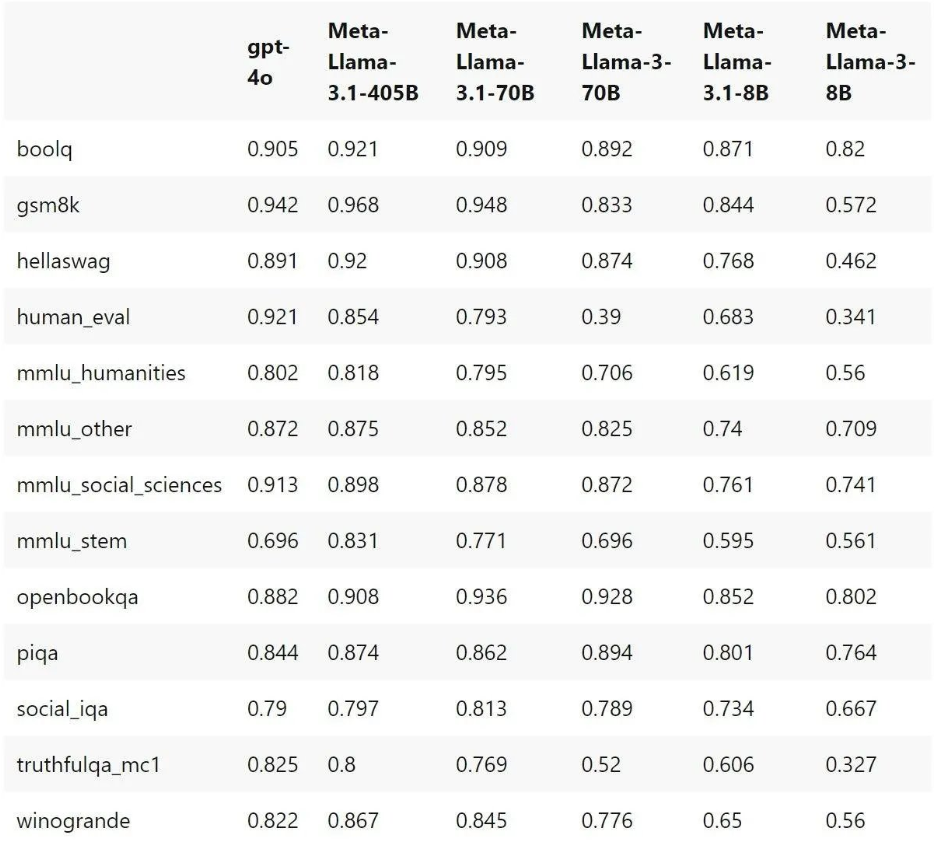
而经过网友测试,该base版模型在AI的基准测试中有显著进步,其性能可以超越当前大模型天花板GPT-4o。而模型的instruct版本通常会更强,也许值得期待一手。
这一模型的问世,可能会成为AI历史性的节点。它意味着开源模型首次在性能上,战胜当下最顶尖的闭源AI大模型(GPT-4o)。
不过GPT-4o好像也发布了很久了,我们一直没能等来GPT5,甚至等来的只是个更便宜的缩水版GPT-4o mini。那就是OpenAI不够努力咯。

128k上下文,15T+tokens训练最强开源模型
Llama 3.1系列不仅是405b模型成绩显著,70b的模型也在一定程度上超越了GPT-4o。不过在human eval和social sciences方面略逊一筹。
而8B和70B模型在基准测试中有了非常显著的进步,下图为Meta根据内部的评估库评估后的结果。
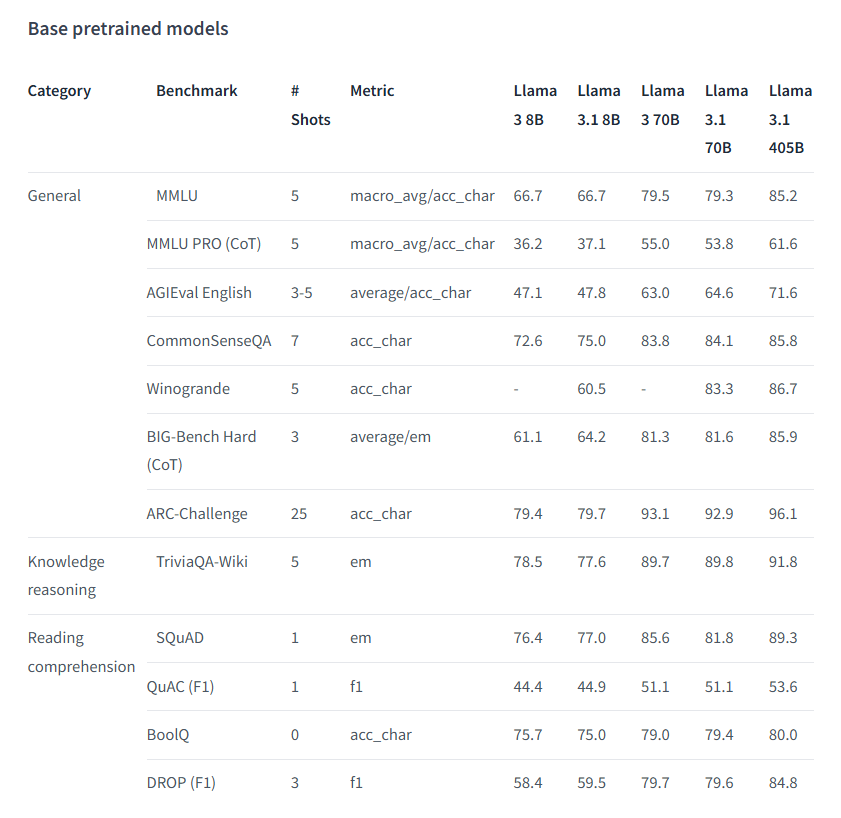
基础预训练模型:
指令微调模型:
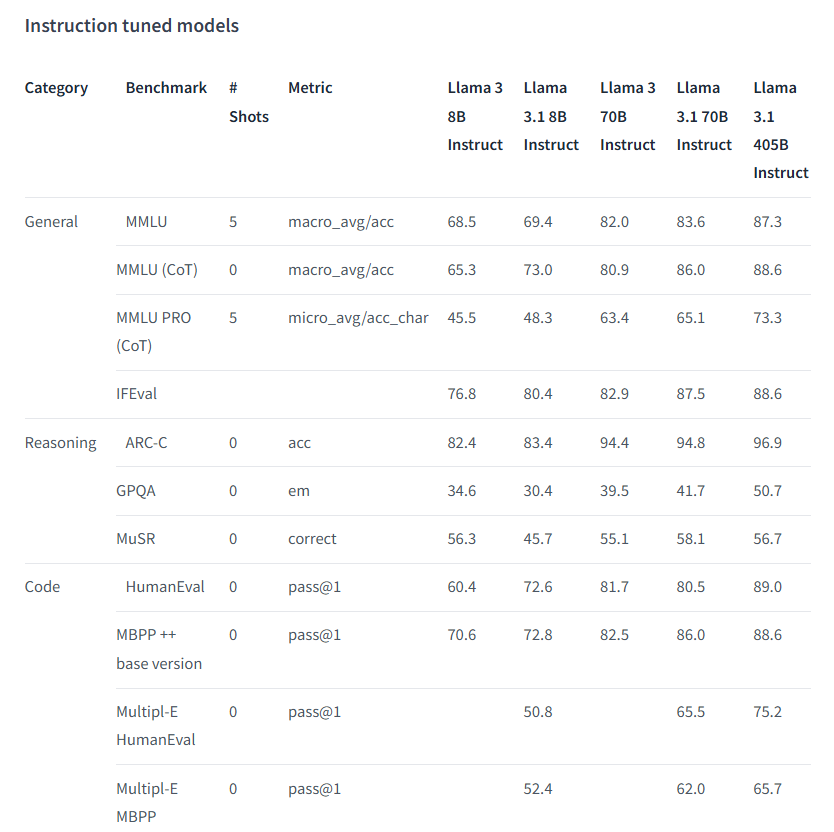
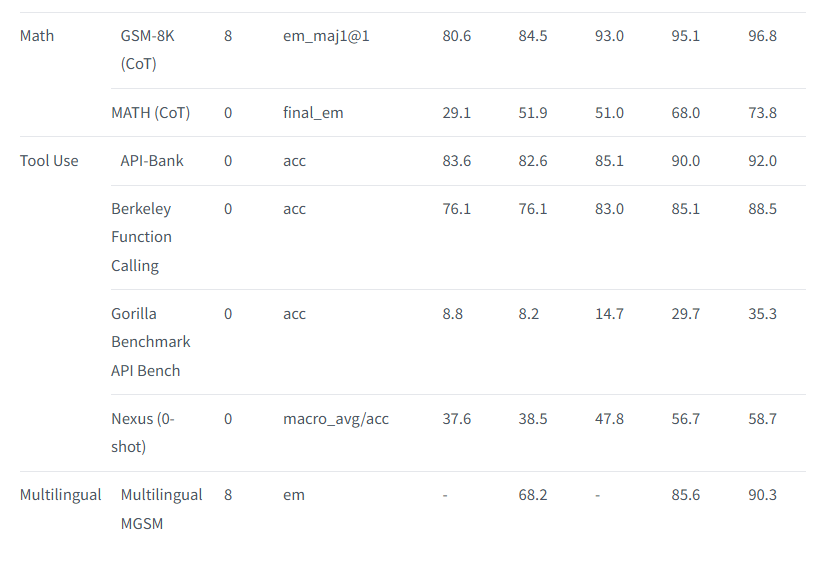
而看到llama 3.1 70b和8b的数据后,我们不妨猜测这两个模型就是405b的蒸馏。
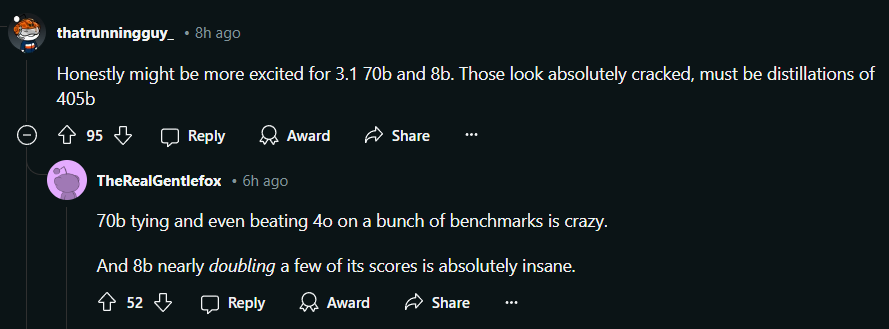
同时,作为纯文本模型,Llama 3.1专门针对多语言对话场景优化了文本指令。 包括英语,法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语等等。
Llama 3.1使用了15T+个tokens的公开数据源来进行预训练,还使用了超过2500万个人工合成的示例进行微调。预训练数据的时间截止到2023年的12月。这三个版本的模型的上下文长度都达到了128K。相比于原本Llama的8k上下文,这可以说是一次质的飞跃了。
不过嘛,泄露的文章中并没有透露使用了哪些私人的数据源,也许要等到Meta正式发布后才能知晓。
原文件地址已删除,疑似员工泄露
一经泄露,Llama 3.1在reddit上迅速引发热议,不过很快这个页面就变成404了。
还是有好心人给出了下载链接。不过Meta官方声明,正式公布时间也就在今晚,大家先按捺一下好奇心,不用急于这一时
也有网友对泄露的原文进行了补档,对Llama3.1具体数据有兴趣的小伙伴可以去看一看:
https://web.archive.org/web/20240722214257/https://huggingface.co/huggingface-test1/test-model-1
而另一边,根据网友猜测,泄露这个模型的人的身份可能是Meta员工。
以下是上传文件的作者的主页:https://huggingface.co/samuelselvan
虽然这种偷跑的行为令人不齿,但看完Llama的表现后,个人认为开源模型能取得如此成绩,是对闭源模型的一种鞭策。长久以来,闭源模型在人力和钞能力的支持下,始终压开源模型一头。而"蚂蚁虽小可溃千里长堤",开源模型的资源交汇织成的蛛网,终究会产生无比强大的力量。
现在我只想对OpenAI说一句:OpenAI你说句话呀!开源的模型都打赢你了,快把GPT5端上来!

