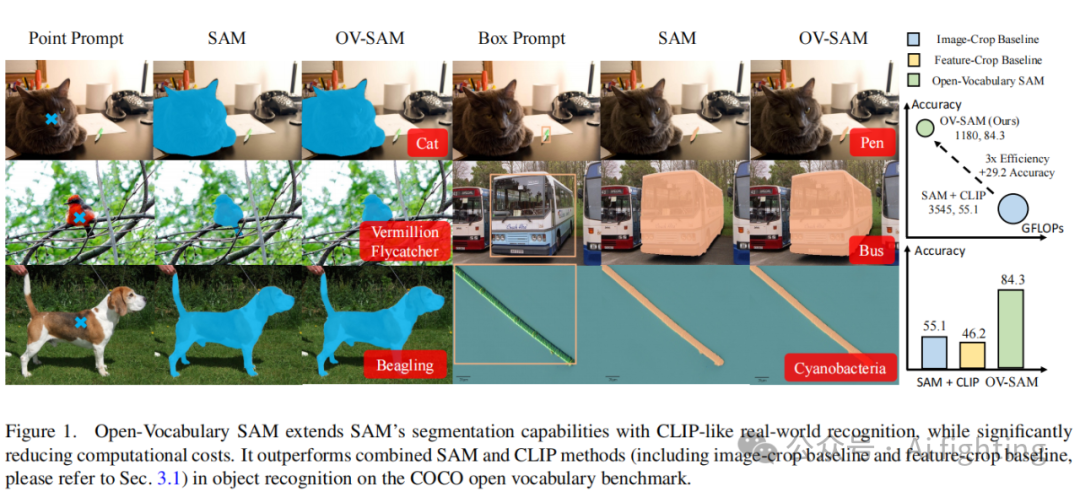
Abstract
CLIP 和 Segment Anything Model(SAM)是卓越的视觉基础模型(VFMs)。SAM 在各种领域的分割任务中表现出色,而 CLIP 以其零样本识别能力而闻名。本文深入探讨了将这两种模型整合到一个统一框架中的方法。具体而言,我们引入了开放词汇表 SAM(Open-Vocabulary SAM),一种受 SAM 启发的模型,旨在同时进行交互式分割和识别,并利用两个独特的知识转移模块:SAM2CLIP 和 CLIP2SAM。前者通过蒸馏和可学习的变压器适配器将 SAM 的知识适配到 CLIP 中,而后者则将 CLIP 的知识转移到 SAM 中,增强其识别能力。在各种数据集和检测器上的广泛实验表明,开放词汇表 SAM 在分割和识别任务中都表现出色,显著优于简单组合 SAM 和 CLIP 的天真基线。此外,在图像分类数据训练的帮助下,我们的方法可以分割和识别大约22,000个类别。
代码地址:
https://github.com/HarborYuan/ovsam
Introduction
Segment Anything Model(SAM)和 CLIP在各种视觉任务中取得了显著进展,分别在分割和识别方面展示了卓越的泛化能力。特别是 SAM,通过大量的掩码标签数据进行训练,使其通过交互式提示能够高度适应各种下游任务。而 CLIP 通过训练数十亿对文本-图像对,拥有了前所未有的零样本视觉识别能力。这引发了许多研究,探索将 CLIP 扩展到开放词汇任务中,如检测和分割。
尽管 SAM 和 CLIP 提供了显著的优势,但它们在原始设计中也存在固有的局限性。例如,SAM 缺乏识别其识别出的分割部分的能力。为了解决这一问题,一些研究通过整合分类头进行尝试,但这些解决方案仅限于特定数据集或封闭集环境。另一方面,CLIP 由于使用图像级对比损失进行训练,在适应密集预测任务时面临挑战。为了解决这一问题,一些研究探讨了对齐 CLIP 表示以进行密集预测的方法。然而,这些方法往往是数据集特定的,并不具有普遍适用性。例如,一些研究专注于在 ADE-20k数据集上的开放词汇分割,并使用 COCO数据集进行预训练。将 SAM 和 CLIP 以天真方式合并,如图 2 (a) 和 (b) 所示,被证明效率低下。这种方法不仅会产生大量计算开销,还会导致次优结果,包括小规模对象的识别,如我们的实验结果所示。
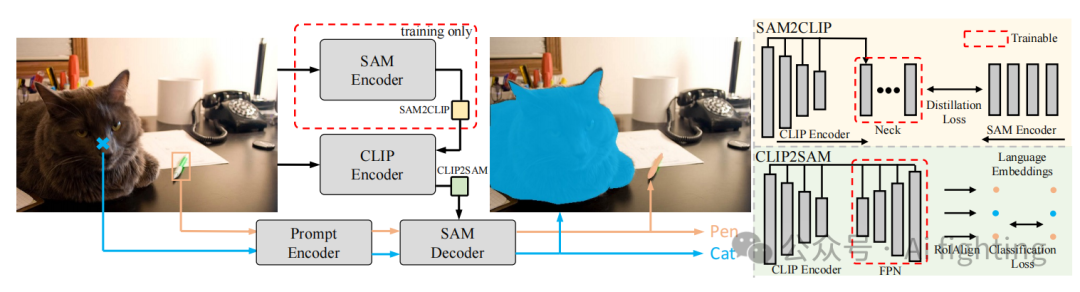
在这项研究中,我们通过统一的编码器-解码器框架解决了这些挑战,该框架集成了 CLIP 编码器和 SAM 解码器,如图 2 © 所示。为了有效地桥接这两个不同的组件,我们引入了两个新模块,SAM2CLIP 和 CLIP2SAM,促进双重知识转移。首先,我们通过 SAM2CLIP 从 SAM 编码器向 CLIP 编码器蒸馏知识。这一蒸馏过程不是直接在 CLIP 编码器上执行,CLIP 编码器保持冻结以保持其现有知识,而是在一个轻量级的类变压器适配器上进行,使用像素级蒸馏损失。适配器以多尺度特征为输入,目的是使 CLIP 特征与 SAM 表示对齐。在解码方面,CLIP2SAM 模块将冻结的 CLIP 编码器的知识转移到 SAM 解码器中。特别是,我们设计了一个具有 RoIAlign 操作的特征金字塔适配器,与 SAM 解码器一起进行联合训练。
Method
3.1 预备知识和基线
SAM

CLIP

组合基线
我们引入了两种不同的组合 CLIP 和 SAM 的基线,如图2(a)和(b)所示。第一种方法称为"裁剪图像基线",它使用 SAM 掩码解码器的输出对原始输入图像进行分割和调整大小。然后,这个处理后的图像作为 CLIP 图像编码器的输入,并结合 CLIP 文本嵌入,使用公式对掩码进行分类。第二种方法称为"裁剪 CLIP 图像特征基线",采用相同的初始 CLIP 特征提取步骤。然而,在这种方法中,由 SAM 解码器预测的掩码用于裁剪 CLIP 图像特征。对这些被掩码的特征进行后续池化产生最终标签,类似于基线(a)。尽管这两种基线可以实现图像的零样本推理,但它们在特定数据集上表现出显著的知识差距。为了解决这个问题,我们借鉴了最近在视觉提示或适配器方面的进展。
3.2 开放词汇 SAM
尽管两种基线模型可以通过视觉提示或适配器进行增强(我们将在第4节讨论),但它们在实际应用中面临一些挑战。首先,组合模型中需要两个独立的骨干网络,这增加了计算成本(问题1)。其次,SAM和CLIP是通过不同的目标进行训练的------SAM通过监督学习,CLIP通过对比学习------关于在这些不同架构之间进行知识转移的研究有限(问题2)。第三,尽管集成了适配器,在识别小物体方面仍存在显著的性能差距(问题3)。第四,缺乏在特征融合和数据扩展的背景下将开放词汇能力集成到SAM和CLIP中的探索(问题4)。我们的工作旨在通过一个统一且有效的框架解决这些问题。
统一架构:
我们设计了一个用于分割和识别的统一架构,以解决问题1。具体来说,我们采用冻结的CLIP视觉编码器作为我们的特征提取器。然后,SAM的掩码解码器和提示编码器被附加在CLIP编码器之后。开放词汇SAM的元架构如图2(c)所示,更详细的版本如图3所示。通过SAM2CLIP和CLIP2SAM使这种统一架构成为可能,其中SAM2CLIP通过蒸馏将SAM的知识转移到CLIP,CLIP2SAM则利用CLIP的知识并结合SAM掩码解码器进行识别。我们选择基于卷积的视觉骨干网络用于冻结的CLIP骨干,符合先前研究强调其在捕捉空间结构方面的优越性28, 70。第4.2节进一步探讨了不同CLIP骨干的有效性。
SAM2CLIP:
为了解决问题2,我们设计了SAM2CLIP模块,通过适应和蒸馏方法弥合SAM和CLIP所学特征表示之间的差距。通过综合实验,我们发现采用蒸馏损失可以有效地进行知识转移。
CLIP2SAM:
该模块旨在利用CLIP的知识增强SAM解码器的识别能力。一个简单的方法是将标签令牌附加到现有的掩码令牌和IoU令牌上。利用标签令牌。我们引入了一个专门的适配器,以促进从冻结的CLIP到SAM解码器的知识转移。随后,增强的标签令牌 与提示编码器的输出和适应的CLIP特征相结合,被输入到双向变压器中。经过交叉注意过程后,改进的标签令牌,通过多层感知机(MLP)进行进一步细化,以确保更好地与CLIP的文本嵌入对齐。最终标签通过计算细化的标签令牌与CLIP文本嵌入之间的距离来得出。
开放词汇:
为了应对问题4的开放词汇挑战,我们利用冻结的CLIP骨干中嵌入的知识,在推理过程中识别新颖和未见过的对象。与先前研究一致,我们通过几何平均融合从冻结的CLIP和CLIP2SAM获得的分类分数,以利用来自CLIP骨干和CLIP2SAM的信息。此外,我们还探讨了通过多数据集联合训练等各种策略来扩展词汇量。
3.3 训练和应用
我们首先使用 SAM-1B(1%)数据集训练 SAM2CLIP 模块,将 SAM 的知识转移到开放词汇 SAM 中,然后,我们使用 COCO 或 LVIS 数据集中的分割掩码和标签注释联合训练 CLIP2SAM 和掩码解码器。此外,我们采用 ImageNet 数据集的联合训练,以便我们的开放词汇 SAM 进行演示(见图5)。

Experiment
4.1 主要结果
与组合基线使用真实标签进行比较:
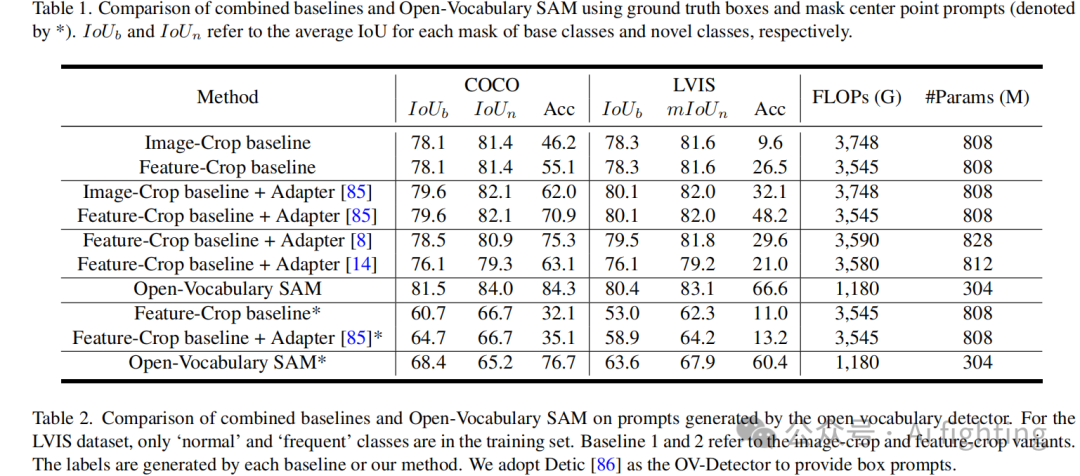
为了避免其他模块的影响,我们首先在表1中展示了我们模型的识别能力。与简单的组合方法相比,添加各种适配器并进行联合训练会得到更好的结果。然而,在COCO和LVIS上的识别能力仍然有限。我们的开放词汇SAM在使用框和点作为视觉提示时都取得了最好的结果。我们观察到在LVIS数据集上的增益更显著。我们认为LVIS包含更多的小物体,比COCO更具挑战性。我们的方法可以解决问题2,并带来超过20%的准确率提升。尽管分割质量相当不错(在COCO和LVIS上的框提示约为80 IoU),我们的方法仍然实现了2%的IoU改进。这表明我们的联合训练在掩码预测和分类上的有效性。相比于使用框作为提示,使用点作为提示更具挑战性,因为点的位置线索比框更弱。然而,我们的方法仍然优于组合基线或带适配器的组合基线。
与开放词汇检测器上的组合基线进行比较
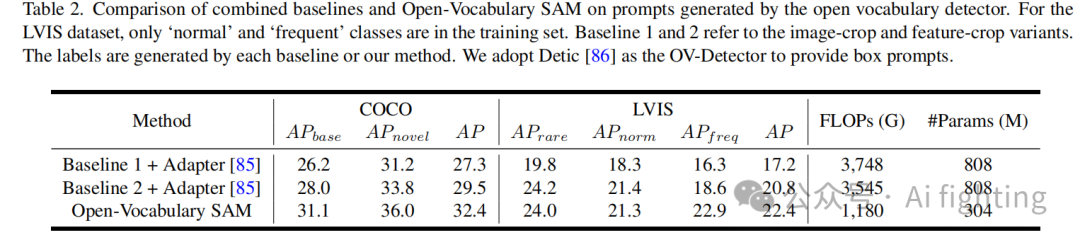
在表2中,我们通过使用现有开放词汇检测器的框预测来模拟具有偏差的交互式分割过程,采用了更具挑战性的设置。我们选择了具有代表性的Detic 86作为开放词汇检测器。同样,我们的方法在COCO和LVIS数据集上也取得了最好的性能。特别是在COCO上,与之前的工作85相比,我们的方法在掩码mAP上提高了3.0,同时参数成本要低得多。更多检测器的结果可以在补充材料中找到。
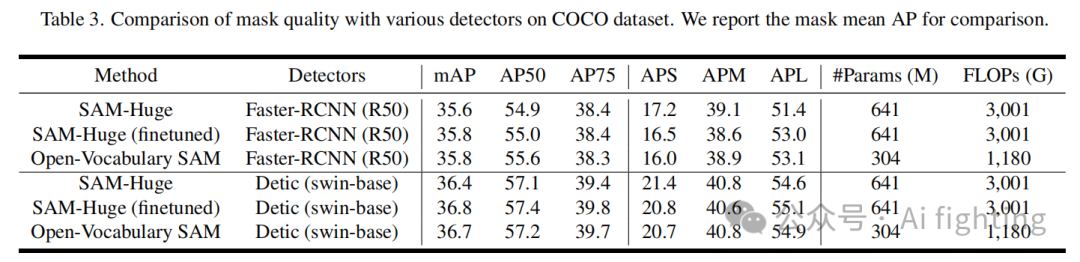
与各种检测器上的SAM进行比较
在表3中,我们还测试了我们的模型和原始SAM在两个不同检测器上的掩码预测质量。我们的方法可以比原始SAM取得更好的性能,并且与在COCO上微调的SAM表现相当。值得注意的是,我们的开放词汇SAM的计算成本和参数比SAM低得多。
可视化比较
在图4中,我们将我们的方法与特征裁剪基线进行比较。我们的模型在分类小物体和稀有物体以及处理遮挡场景方面表现更好。
作为零样本标注工具的模型
除了在COCO和LVIS标准数据集上进行训练之外,秉承SAM的精神,我们还通过更多数据来扩展我们的模型。特别是,我们采用了更多的检测数据(V3Det 57, Object365 53)和分类数据(ImageNet22k 11)。由于成本显著,我们尚未进行与其他基线的比较。相反,我们已将我们的方法调整为一种交互式标注工具,能够分割和识别超过22,000个类别。
4.2 消融研究与分析
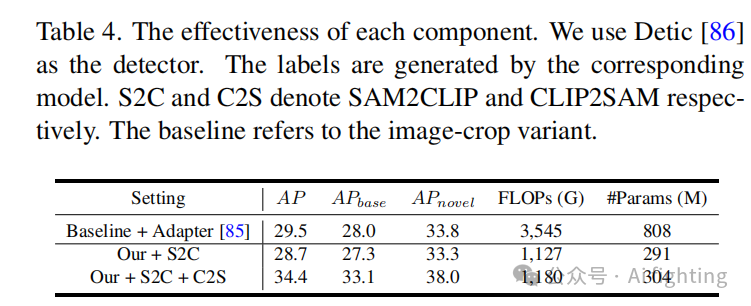
SAM2CLIP和CLIP2SAM的有效性
我们首先验证了我们提出的两个模块的有效性,并验证了计算量的影响。在SAM2CLIP模块的训练过程中,由于SAM数据与COCO数据之间的领域差异,分割性能略有下降。然而,在添加我们的CLIP2SAM模块并与掩码分类和预测进行联合训练后,分割和分类都显著提升,计算成本仅有微小增加。
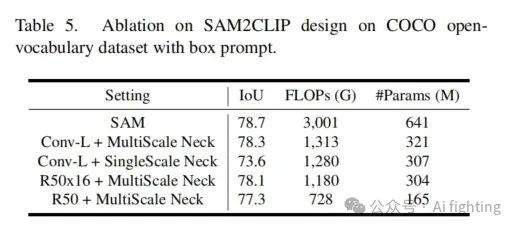
SAM2CLIP的详细设计
在表5中,我们探讨了开放词汇SAM训练的第一阶段中SAM2CLIP的详细设计。结果显示,当采用多尺度特征时,蒸馏的效果最好,这表明高分辨率特征和高级语义在对齐CLIP的特征与SAM的特征时都很重要。
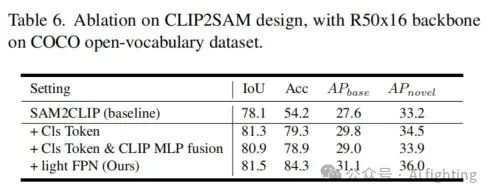
CLIP2SAM的详细设计
在表6中,我们介绍了CLIP2SAM模块的广泛设计。我们比较了两种设计:一种是具有交叉注意力的简单分类令牌(Cls Token),另一种是将该令牌与掩码池化的CLIP特征相结合(CLS Token & CLIP MLP融合)。这些设计比第一行中显示的组合基线效果更好。然而,由于分辨率限制,这些变体无法很好地处理小物体,如图4所示。相比之下,我们包含轻量级FPN的设计显著提高了性能。
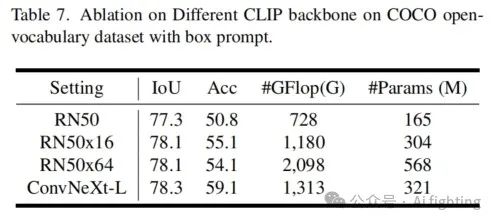
不同CLIP骨干的消融实验
在表7中,我们探讨了冻结的CLIP视觉骨干的影响。我们没有添加CLIP2SAM模块。受到近期工作28, 64, 70, 72的启发,基于CNN的CLIP封装了更多结构信息,这对我们的目标有好处,因为我们有位置敏感的视觉提示作为输入。因此,我们避免了对SAM2CLIP使用简单的ViT设计,而是采用了基于CNN的CLIP。如表中所示,我们发现ConvNext large取得了最佳性能。
总结:
文章的主要贡献如下:
-
创新框架:研究提出了一个集成CLIP编码器和SAM解码器的统一编码器-解码器框架,通过SAM2CLIP和CLIP2SAM两个新模块实现知识转移,增强模型的识别和分割能力。
-
数据集增强:利用COCO、LVIS和ImageNet-22k等现有语义数据集,提升模型的多功能性,使其能够识别和分割各种物体。
-
显著性能提升:在封闭集和开放词汇交互式分割任务中,与基线相比,该方法在COCO数据集上实现了2%以上的IoU提升和3%以上的mAP提升,在LVIS数据集上实现了超过20%的提升,显示出其在不同场景下的优越性能和灵活性。
引用ECCV2024文章:
Open-Vocabulary SAM: Segment and RecognizeTwenty-thousand Classes Interactively
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。