Abstract
灵感来自ViT的长距离建模能力,大核卷积最近被广泛研究和采用,以扩大感受野并提高模型性能,例如显著的工作ConvNeXt采用7×7深度卷积。虽然这种深度算子只消耗少量的FLOPs,但由于高内存访问成本,它在强大计算设备上大大损害了模型效率。例如,ConvNeXt-T在A100 GPU上全精度训练时,与ResNet-50的FLOPs相似,但吞吐量仅为约60%。虽然减少ConvNeXt的核大小可以提高速度,但会导致显著的性能下降,这就提出了一个挑战性的问题:如何在保持性能的同时加速基于大核的CNN模型。为了解决这个问题,受Inceptions的启发,我们提出将大核深度卷积沿通道维度分解为四个并行分支,即小方核、两个正交带状核和一个恒等映射。通过这种新的Inception深度卷积,我们构建了一系列网络,即InceptionNeXt,它们不仅具有高吞吐量,还保持了竞争力的性能。例如,InceptionNeXt-T的训练吞吐量比ConvNeX-T高1.6倍,并在ImageNet-1K上获得了0.2%的top-1准确率提升。我们预计InceptionNeXt可以作为未来架构设计的经济基线,以减少碳足迹。
代码地址:
https://github.com/sail-sg/inceptionnext
欢迎加入自动驾驶实战群
Introduction
受语言生成预训练的启发,Image GPT (iGPT)将像素视为标记,并采用纯Transformer进行视觉自监督学习。然而,iGPT在处理高分辨率图像方面由于计算成本面临限制。突破来自Vision Transformer (ViT),它将图像块视为标记,利用纯Transformer作为骨干,并在大规模监督图像预训练后在图像分类中表现出显著性能。
显然,ViT 的成功进一步激发了人们对Transformer在计算机视觉领域应用的热情。许多ViT变体,如DeiT和Swin,被提出并在各种视觉任务中取得了显著的性能。ViT类模型优于传统CNN(例如,Swin-T在ImageNet上的81.2% vs ResNet-50的76.1%)的卓越性能使许多研究人员相信Transformer最终会取代CNN并主导计算机视觉领域。
是时候让CNN反击了。随着DeiT 和Swin中先进的训练技术,"ResNet strikes back" 的工作表明,ResNet-50的性能可以提升2.3%,达到78.4%。此外,ConvNeXt 表明,使用类似于注意力窗口大小的GELU 激活和大内核大小等现代模块,CNN模型在各种设置和任务中可以始终优于Swin Transformer。ConvNeXt并不是孤军奋战:越来越多的工作显示出类似的观察结果,如RepLKNet 和SLaK。在这些现代CNN模型中,共同的关键特征是通常通过具有大内核大小的深度卷积 实现的大感受野.
Formulation and Method
公式与方法
3.1. MetaNeXt
MetaNeXt模块的公式
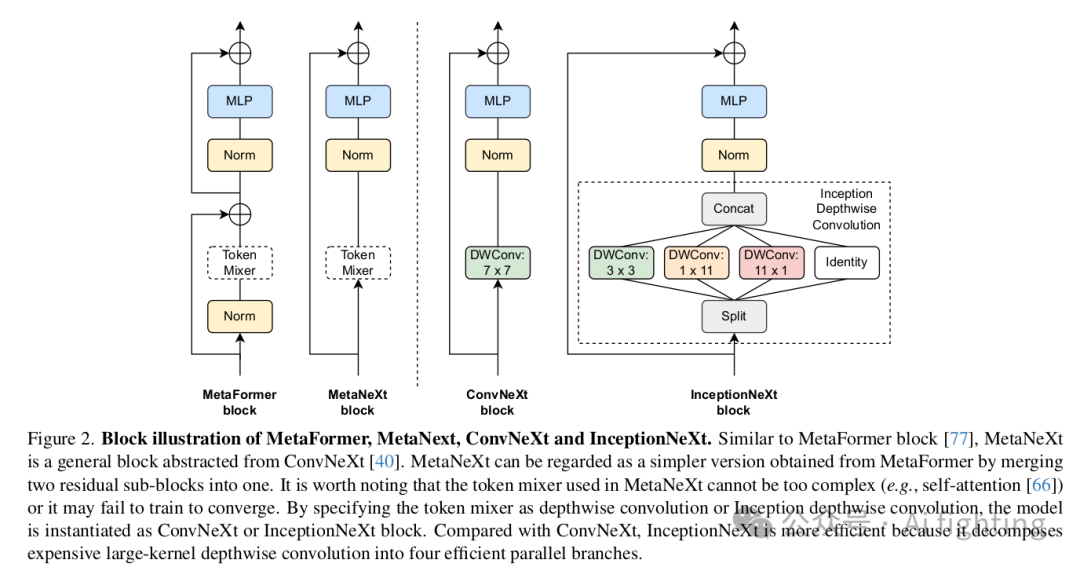
在ConvNeXt 中,对于其每个ConvNeXt模块,输入X首先通过一个深度卷积来沿空间维度传播信息。我们遵循MetaFormer 的做法,将深度卷积抽象为一个负责空间信息交互的token mixer。因此,如图2的第二个子图所示,ConvNeXt被抽象为MetaNeXt模块。正式地,在一个MetaNeXt模块中,其输入X首先被处理为

归一化 1, 29之后,特征被馈送到一个MLP模块中,该模块由两个全连接层组成,在它们之间有一个激活函数,类似于Transformer中的前馈网络。这两个全连接层也可以通过1×1卷积实现。同时,采用了shortcut connection。

与MetaFormer模块的比较
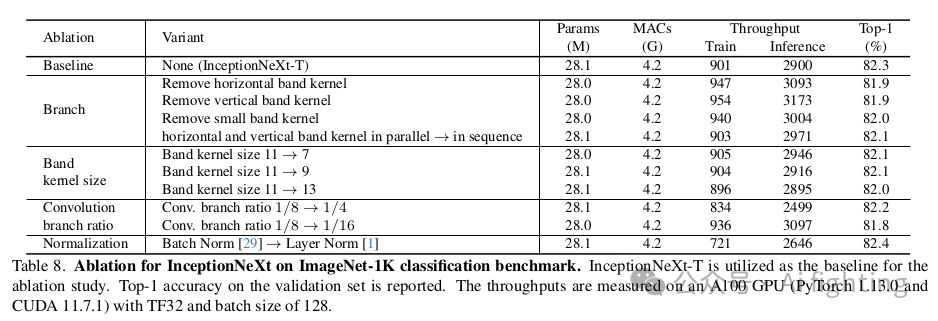
如图2所示,可以发现MetaNeXt模块与MetaFormer模块共享类似的模块,例如token mixer和MLP。然而,这两种模型之间的一个关键区别在于shortcut connections的数量。MetaNeXt模块实现了一个shortcut connection,而MetaFormer模块包含两个,一个用于token mixer,一个用于MLP。从这个角度来看,MetaNeXt模块可以被认为是将MetaFormer的两个残差子模块合并的结果,从而简化了整体架构。因此,MetaNeXt架构比MetaFormer具有更高的速度。然而,这种更简单的设计有一个限制:如我们的实验(表5)所示,MetaNeXt中的token mixer组件不能太复杂(例如Attention)。
实例化到ConvNeXt
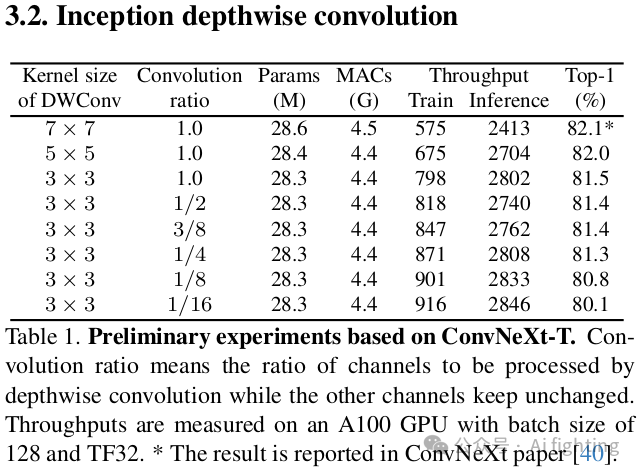
如图2所示,在ConvNeXt中,token mixer简单地通过一个深度卷积实现。我们首先基于ConvNeXt-T进行了初步实验,并在表1中报告了结果。首先,深度卷积的核大小从7×7减少到3×3。与核大小为7×7的模型相比,核大小为3×3的模型训练吞吐量提高了1.4倍,但性能显著下降,从82.1%下降到81.5%。接下来,受ShuffleNet V2启发,我们仅将部分输入通道馈送到深度卷积中,而其余的保持不变。处理的输入通道数由一个比例控制。结果发现,当比例从1减少到1/4时,训练吞吐量可以进一步提高,而性能几乎保持不变。总之,这些初步实验传达了两个关于ConvNeXt的发现。发现1:大核深度卷积是速度瓶颈。发现2:在单个深度卷积层中处理部分通道已足够。
公式
基于上述发现,我们提出了一种新型卷积来保持准确性和效率。根据发现2,我们将部分通道保持不变,并将其视为一个恒等映射分支。受发现1的启发,对于处理的通道,我们提出以Inception风格分解深度操作。Inception 利用了几条小核(例如3×3)和大核(例如5×5)分支。同样,我们采用3×3作为我们的一个分支,但由于其实际速度较慢,放弃了使用大方核。相反,大核k_h × k_w
复杂性
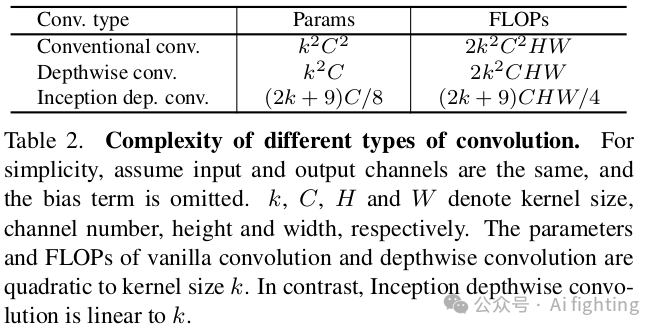
三种类型卷积的复杂性,即传统卷积、深度卷积和Inception深度卷积如表2所示。可以看出,Inception深度卷积在参数数量和FLOPs方面比其他两种卷积更高效。Inception深度卷积消耗的参数和FLOPs与通道和核大小成线性关系。深度卷积和Inception深度卷积在FLOPs方面的比较也清晰地显示在图3中。
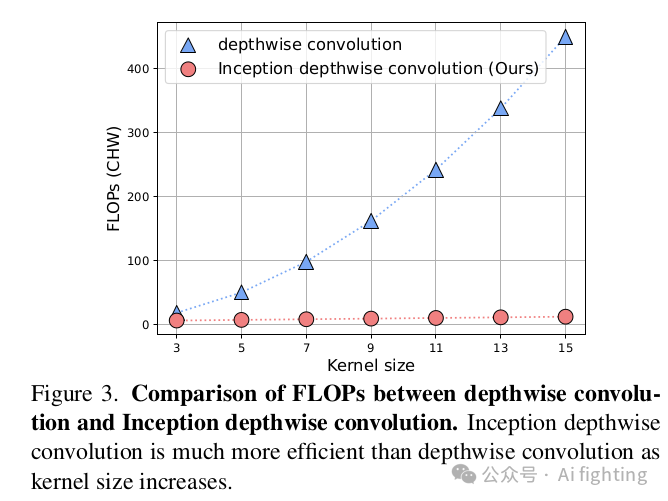
3.3. InceptionNeXt
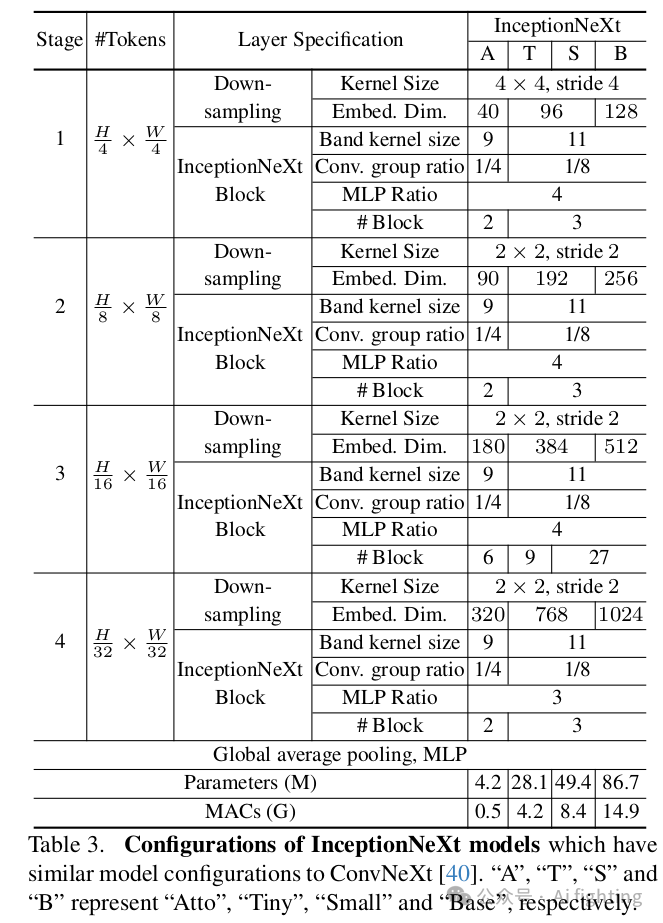
基于InceptionNeXt模块,我们可以构建一系列名为InceptionNeXt的模型。由于ConvNeXt是我们的主要比较基线,我们主要遵循其构建多个尺寸的模型。具体而言,类似于ResNet和ConvNeXt,InceptionNeXt也采用4-stage框架。与ConvNeXt相同,4个阶段的数量分别为2, 2, 6, 2(atto尺寸),3, 3, 9, 3(小尺寸)和3, 3, 27, 3(基尺寸)。我们采用Batch Normalization,因为本文强调速度。与ConvNeXt的另一个区别在于InceptionNeXt在stage 4中使用MLP比例为3,并将节省的参数移至分类器,这有助于减少一些FLOPs(例如,基尺寸减少3%)。详细的模型配置见表。
Experiment
结果
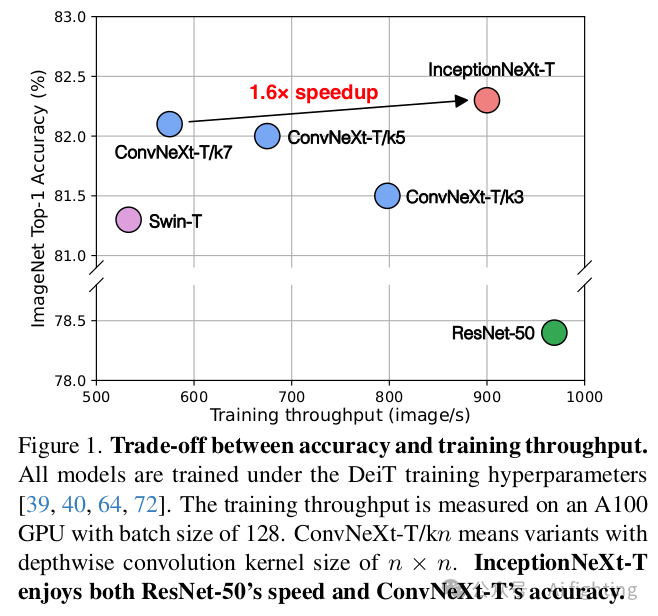
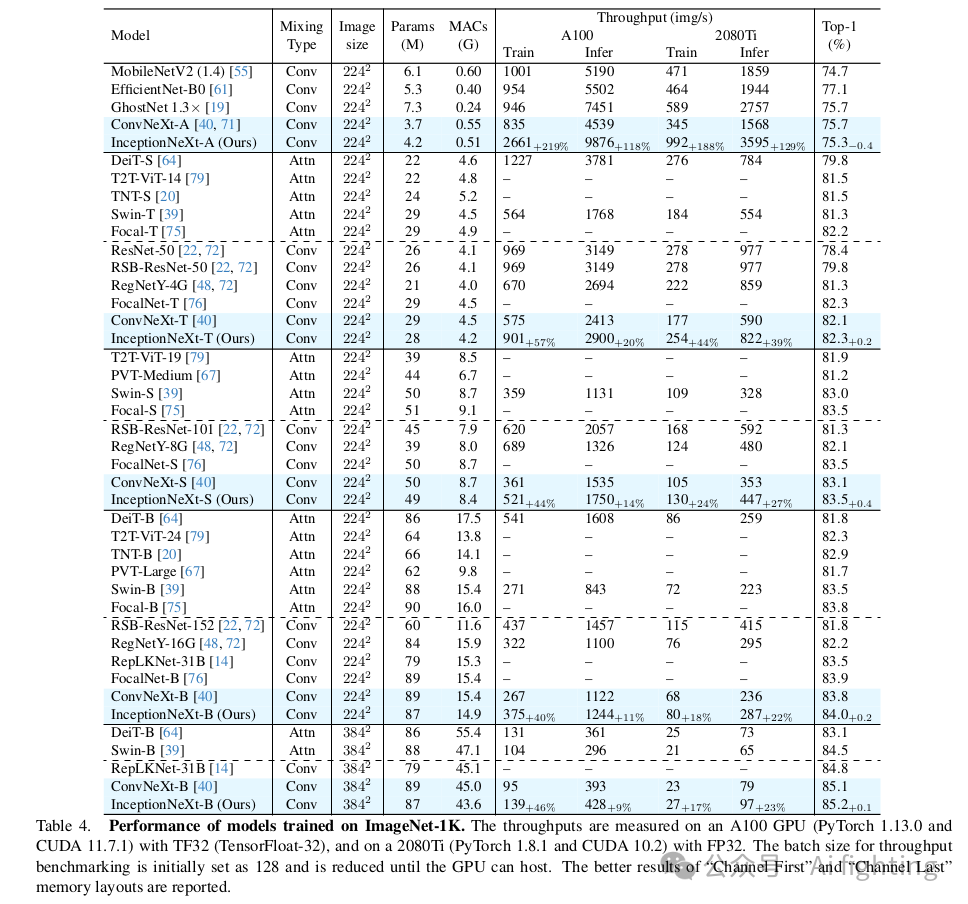
我们将InceptionNeXt与各种最先进的模型进行了比较,包括基于注意力机制和基于卷积的模型。如表4所示,InceptionNeXt在性能上具有高度竞争力,同时具有更高的速度。InceptionNeXt在准确率-速度的权衡方面始终优于ConvNeXt 。例如,InceptionNeXt-T不仅比ConvNeXt-T高出0.2%,而且在A100上的训练/推理吞吐量分别是ConvNeXt的1.6倍/1.2倍,类似于ResNet-50。也就是说,InceptionNeXt-T兼具ResNet-50的速度和ConvNeXt-T的准确率。此外,遵循Swin和ConvNeXt的做法,我们还对在224 × 224分辨率下训练的InceptionNeXt-B进行了微调,调整至384 × 384分辨率并训练30个epoch。我们可以看到,InceptionNeXt-B在保持竞争性准确率的同时,获得了比ConvNeXt-B更高的训练和推理吞吐量。
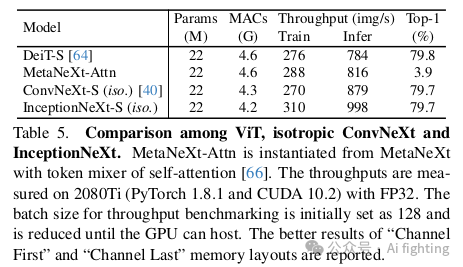
除了4-stage框架,另一个显著的是ViT风格的等异性架构,其只有一个stage。为了匹配DeiT-S的参数和MACs,我们构建了InceptionNeXt-S(iso.),其设计参考了ConvNeXt-S(iso.。具体来说,我们将嵌入维度设为384,块数设为18。此外,我们还构建了一个名为MetaNeXt-Attn的模型,该模型是通过将MetaNeXt模块中的token mixer指定为自注意力机制而实例化的。此模型的目的是调查是否可以将Transformer块的两个残差子块合并为一个。实验结果如表5所示。可以看出,InceptionNeXt在等异性架构下也表现良好,证明了InceptionNeXt在不同框架下具有良好的泛化能力。值得注意的是,MetaNeXt-Attn无法收敛训练,准确率仅为3.9%。这一结果表明,与MetaFormer中的token mixer不同,MetaNeXt中的token mixer不能过于复杂,否则模型可能无法训练。
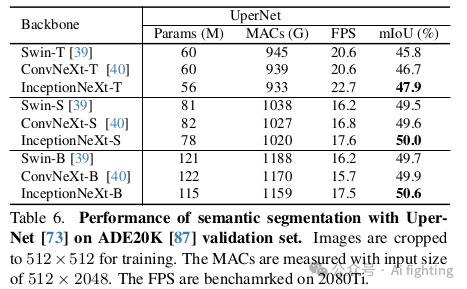
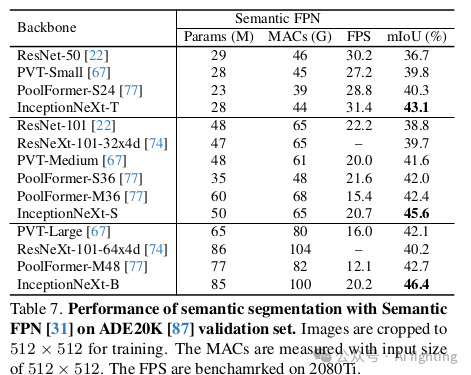
在使用UpNet进行分割时,结果如表6所示。可以看到,InceptionNeXt在不同模型尺寸下始终优于Swin 39和ConvNeXt 。在Semantic FPN方法中,如表7所示,InceptionNeXt显著超越了其他主干网络,如PVT和PoolFormer。这些结果表明,InceptionNeXt在密集预测任务中也具有很高的潜力。
总结:
文章的贡献主要体现在两个方面:
-
速度瓶颈识别:通过图1展示了ConvNeXt的速度瓶颈,并提出了解决方案。
-
Inception深度卷积:提出了一种新的深度卷积方法,将大核卷积分解为多个小核卷积,提高效率。
此外,通过在图像分类和语义分割任务上的实验验证,InceptionNeXt在速度和准确性的权衡上优于ConvNeXt,有望成为新的CNN基线,推动神经网络架构设计的进一步研究。
引用CVPR2024文章:
InceptionNeXt: When Inception Meets ConvNeXt
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。