目录
[MappedByteBuffer 的工作机制](#MappedByteBuffer 的工作机制)
前言
在深入学习 RocketMQ 这款高性能消息队列框架的源码时,发现 ByteBuffer 和 MappedByteBuffer在 RocketMQ 这样的高性能消息队列框架中扮演了关键角色,其核心部分广泛使用了这两种缓冲区,以实现高效的数据存储和异步刷盘操作。 接下来就深入学习ByteBuffer 和 MappedByteBuffer 的工作原理、优势特点,以便能运用到实际业务中。
ByteBuffer是什么
ByteBuffer 是 Java NIO(New Input/Output)库中的一个类,用于高效地进行字节数据的读写操作。ByteBuffer 提供了一个直接操作字节数组的接口,使得开发者可以更加灵活和高效地处理数据,特别是在处理大文件、网络通信以及其他需要高性能 I/O 操作的场景下。
重要特点
使用 ByteBuffer 进行数据读取时,内部的 position 指针会在每次读取操作后自动向前移动。这是 ByteBuffer 的基本操作原理之一,用于追踪缓冲区当前的读取或写入位置 。
分配缓冲区
ByteBuffer 类提供了两种主要的方法来分配缓冲区:allocate 和 allocateDirect
java
ByteBuffer buffer = ByteBuffer.allocate(1024);
ByteBuffer directBuffer = ByteBuffer.allocateDirect(1024);- allocate:分配JVM堆内存中的缓冲区,所以它受 JVM 垃圾回收的管理, 在执行 I/O 操作时,可能需要将数据从堆内存复制到操作系统的 I/O 缓冲区中,相对于直接缓冲区,堆缓冲区的性能通常稍逊色,适合对性能要求不高的场景。
allocateDirect:分配的缓冲区是在 JVM 堆外的直接内存中,从而减少了内存复制的开销,适合需要高性能 I/O 操作的场景,由于直接缓冲区不受 JVM 垃圾回收的管理,它可能会造成内存泄漏,需要额外注意管理。
读写模式切换
ByteBuffer 提供了 flip() 方法,可以方便地从写模式切换到读模式;clear() 方法可以重置缓冲区,使其再次可用于写入数据。
java
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.flip();
buffer.clear();操作文本数据
java
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
public class ByteBufferExample {
public static void main(String[] args) {
String text = "Hello, ByteBuffer!";
// 创建一个 ByteBuffer
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// 将字符串转换为字节数组并逐个字节写入
byteBuffer.put(text.getBytes(StandardCharsets.UTF_8));
// 准备读取
byteBuffer.flip();
// 读取并输出 ByteBuffer 中的字节
byte[] outputArray = new byte[byteBuffer.remaining()];
byteBuffer.get(outputArray);
String outputText = new String(outputArray, StandardCharsets.UTF_8);
System.out.println("Stored and retrieved text: " + outputText);
}
}- 其中
ByteBuffer.remaining()方法就是确定在当前缓冲区的position和limit之间还有多少字节可以读取。它间接告诉你"从当前位置到缓冲区结束,可以读取的字节数"。
上面案例只是对单条数据进行操作,所以获取时直接调用remaining()方法获取所有可以读取的字节数并输出。
那么我们需要存储多条数据,并且逐条输出呢?
- 对于固定大小的数据,可以直接逐条写入数据,并在读取时使用
get方法按固定字节数读取。(对于实际业务中很难保证操作的文本数据大小一样)- 对于可变大小的数据,先存储每条数据的长度,然后存储数据内容;读取时先读取长度,再读取对应大小的数据内容。(显然这种维护成本很高)
操作基本数据类型
java
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.putInt(1);
buffer.putLong(1L);
buffer.putFloat(1.0f);
buffer.putDouble(1.0);
...我们知道一个基本数据类型的大小是固定的,所以ByteBuffer提供了相关方法
int类型占用 4 个字节long类型占用 8 个字节float类型占用 4 个字节double类型占用 8 个字节
案例解析-循环输出数据
如果我们一条数据由20个字节组成,并且这20个字节是三个关键数据组合(基于RocketMq源码ConsumeQueue场景简化)
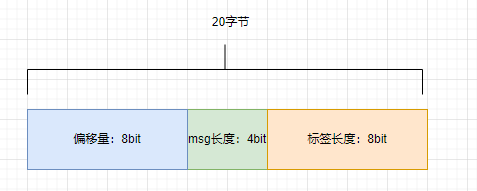
我们对2条数据进行存储并获取操作。
注意:获取顺序必须与写入顺序一致!!!
java
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
//第一条数据
buffer.putLong(637823L);
buffer.putInt(233);
buffer.putLong(232342L);
//第二条数据
buffer.putLong(34234L);
buffer.putInt(33);
buffer.putLong(34322L);
//切换读模式
buffer.flip();
while (buffer.hasRemaining()){
//偏移量
long offset = buffer.getLong();
//msg大小
int msgSize = buffer.getInt();
//标签大小
long tagsSize = buffer.getLong();
//拼接一条完整的数据
String msgIndex = offset + "" + msgSize + "" + tagsSize;
System.out.println("msgIndex:" + msgIndex);
}
}输出:

MappedByteBuffer是什么
MappedByteBuffer 是 ByteBuffer 的一个子类,所以具有ByteBuffer 的所有特性,它核心是用于内存映射文件(mmap机制的一种实现)。它通过将文件映射到内存,使得应用程序可以直接在内存中对文件内容进行读写操作,而操作系统负责在适当的时候将这些修改同步到磁盘上。这种机制极大地提高了文件 I/O 的效率。
MappedByteBuffer 的工作机制
- 内存映射 :文件的内容被映射到内存后,操作系统会在后台维护内存和磁盘之间的同步。应用程序对
MappedByteBuffer的读写操作实际上是对内存的读写,操作系统会在适当的时候将这些修改写入到磁盘中。 - 异步刷盘 :操作系统通过页面缓存机制来管理内存和磁盘之间的数据同步。修改后的页面不会立即写回磁盘,而是被标记为"脏页"(dirty page)。当页面缓存需要释放内存或达到一定条件时,操作系统会将脏页刷盘。
- 手动刷盘 :
MappedByteBuffer提供了 force() 方法,允许应用程序立即将内存中的修改同步到磁盘。这个方法会触发操作系统将映射的内存区域中的脏页写回到文件中,确保数据的持久性。
java
import java.io.RandomAccessFile;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class MappedByteBufferExample {
public static void main(String[] args) throws Exception {
RandomAccessFile file = new RandomAccessFile("example.txt", "rw");
FileChannel channel = file.getChannel();
// 将文件的前 1024 字节映射到内存
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
// 在内存中修改数据
buffer.put(0, (byte) 97); // 写入 ASCII 码 'a'
// 手动将内存中数据刷新到磁盘
buffer.force();
channel.close();
file.close();
}
}刷盘时机
- 在使用
MappedByteBuffer进行内存映射文件操作时,除了显式调用force()方法触发刷盘外,其他刷盘操作由操作系统根据内存管理和 I/O 子系统的机制自行决定。应用程序通常无法确切知道刷盘的具体时间。 - 可以通过日志、监控工具和文件系统统计信息了解系统的刷盘行为。为了确保关键数据的及时刷盘,可以显式调用刷盘方法并采用事务机制管理数据写入等。
总结
ByteBuffer 和 MappedByteBuffer 是 Java NIO 中重要的组件,通过提供高效的内存和文件操作机制,极大地提高了 I/O 操作的性能和灵活性。理解并掌握它们的使用,可以帮助我们在处理大数据量、高性能应用时游刃有余。通过学习它们的底层实现和应用场景,我们可以更好地优化应用程序的 I/O 操作,提高整体系统性能。