环境
Spark版本:3.0.0
java版本:1.8
scala版本:2.12.19
Maven版本:3.8.1
编译spark
将spark-3.0.0的源码导入到idea中
执行mvn clean package -Phive -Phive-thriftserver -Pyarn -DskipTests
执行sparksql示例类SparkSQLExample
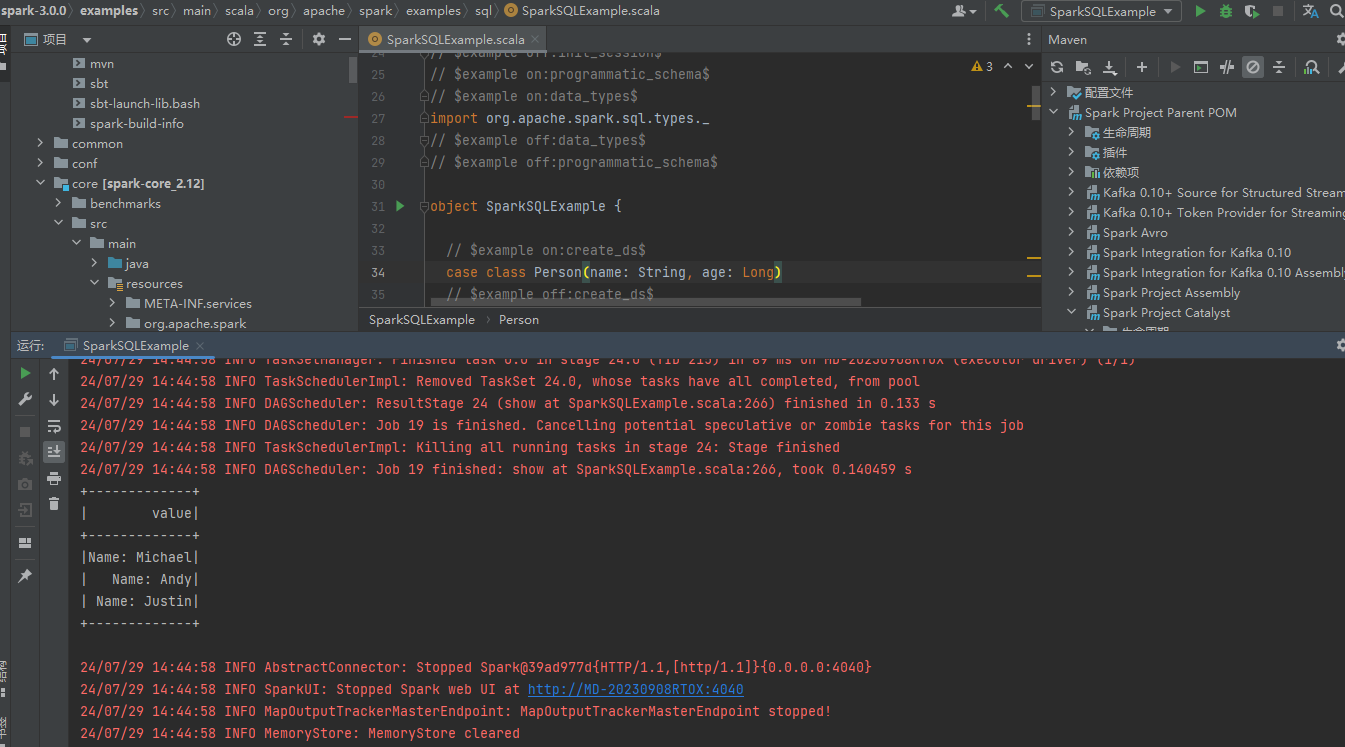
运行成功
遇到的问题
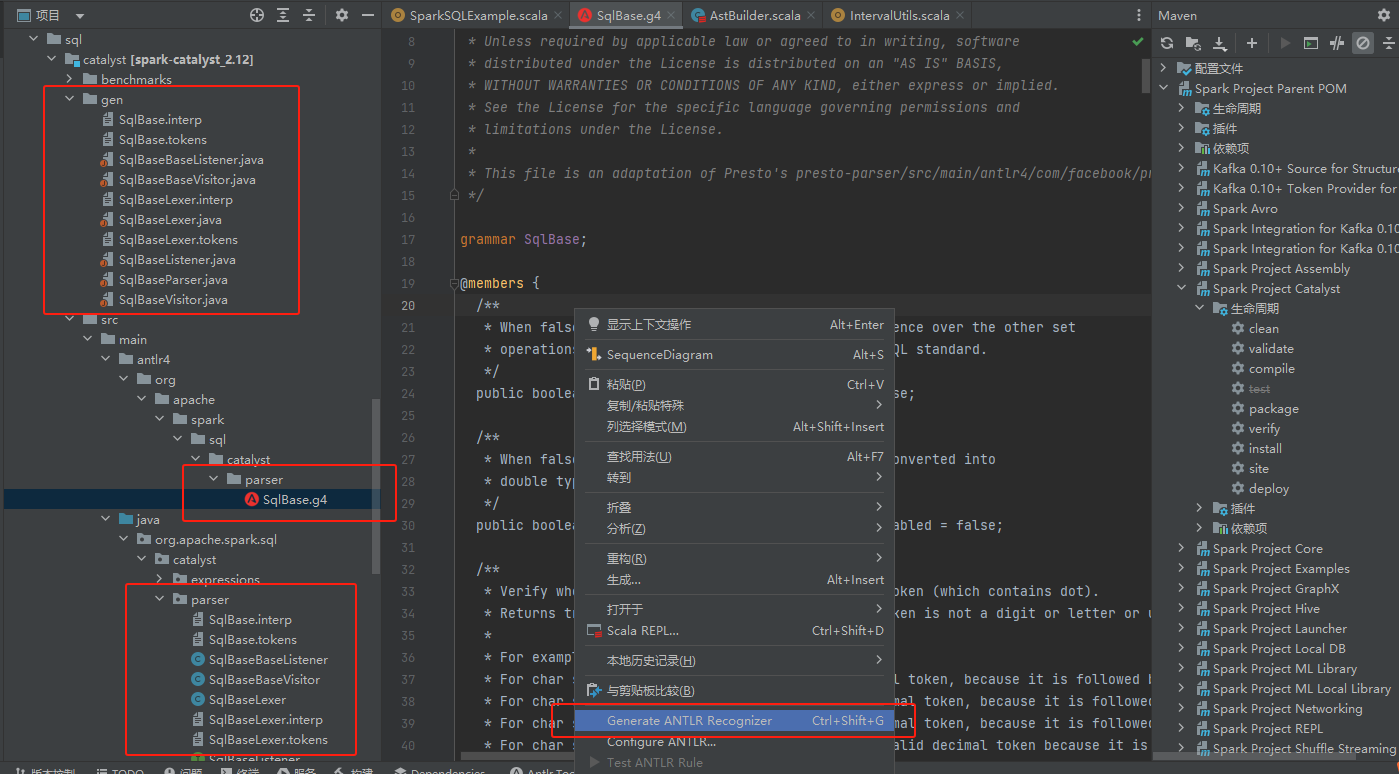
缺少parse包的类
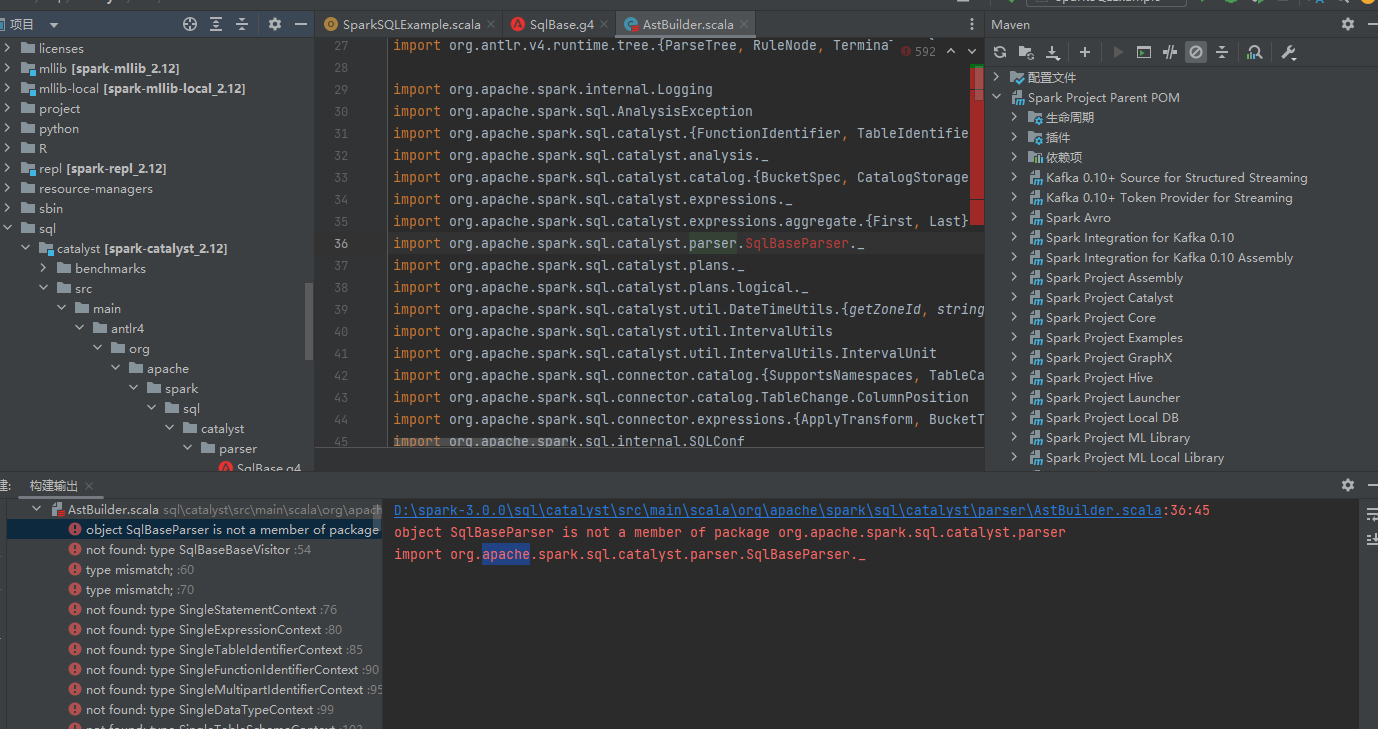
parse包的类是ANTLR工具生成的,确认idea的插件已经安装了。
找到sql包下面的SqlBase.g4文件,右键执行生成文件。最后生成的文件在gen目录下,创建一个新的包org.apache.spark.sql.catalyst.parser,将生成的文件都复制到这个包下面。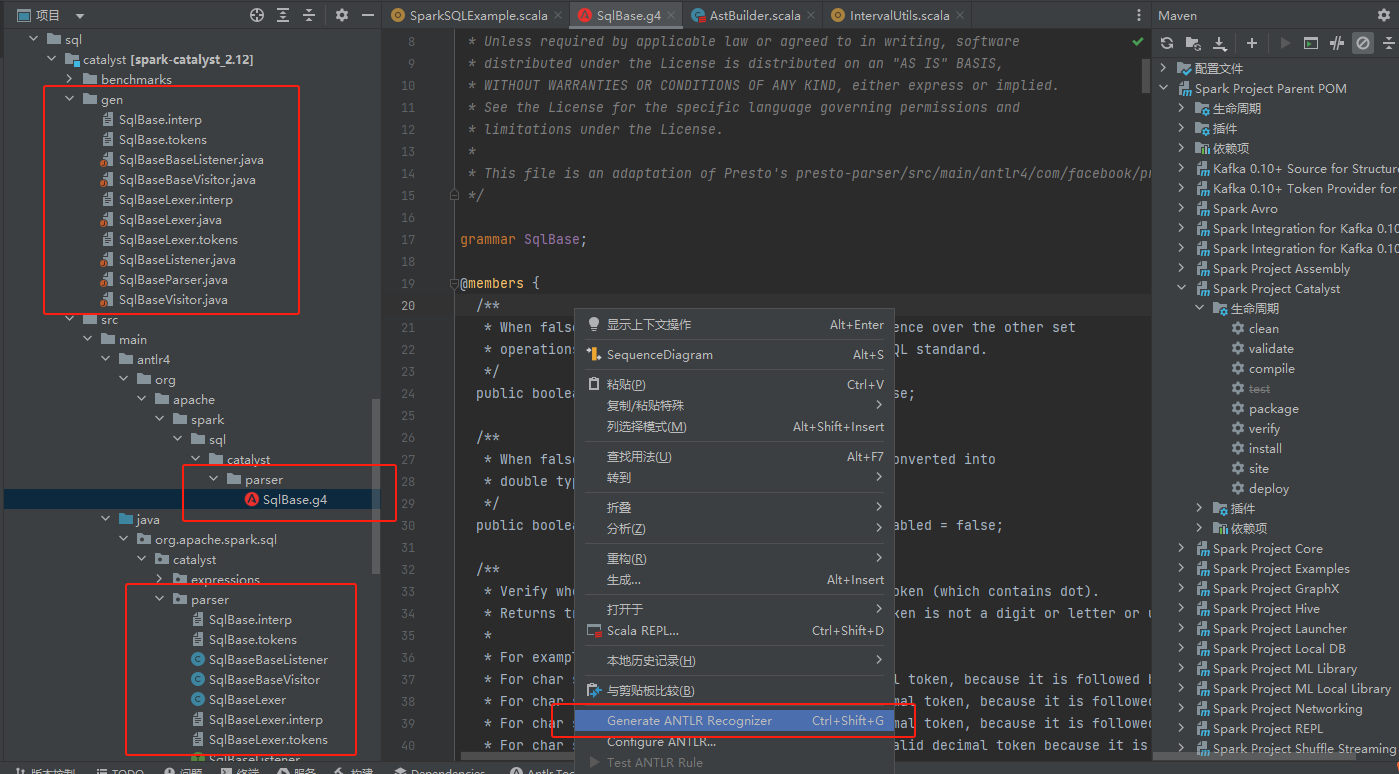
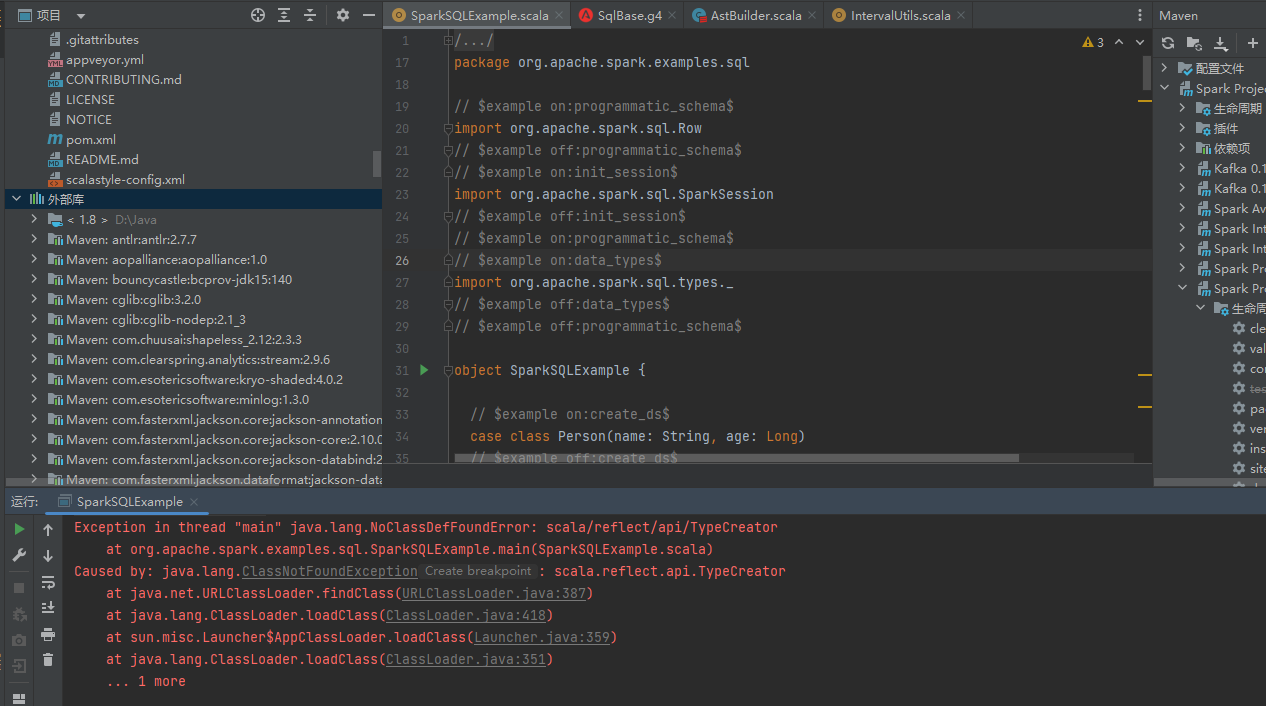
 scala.reflect包的类缺失
scala.reflect包的类缺失
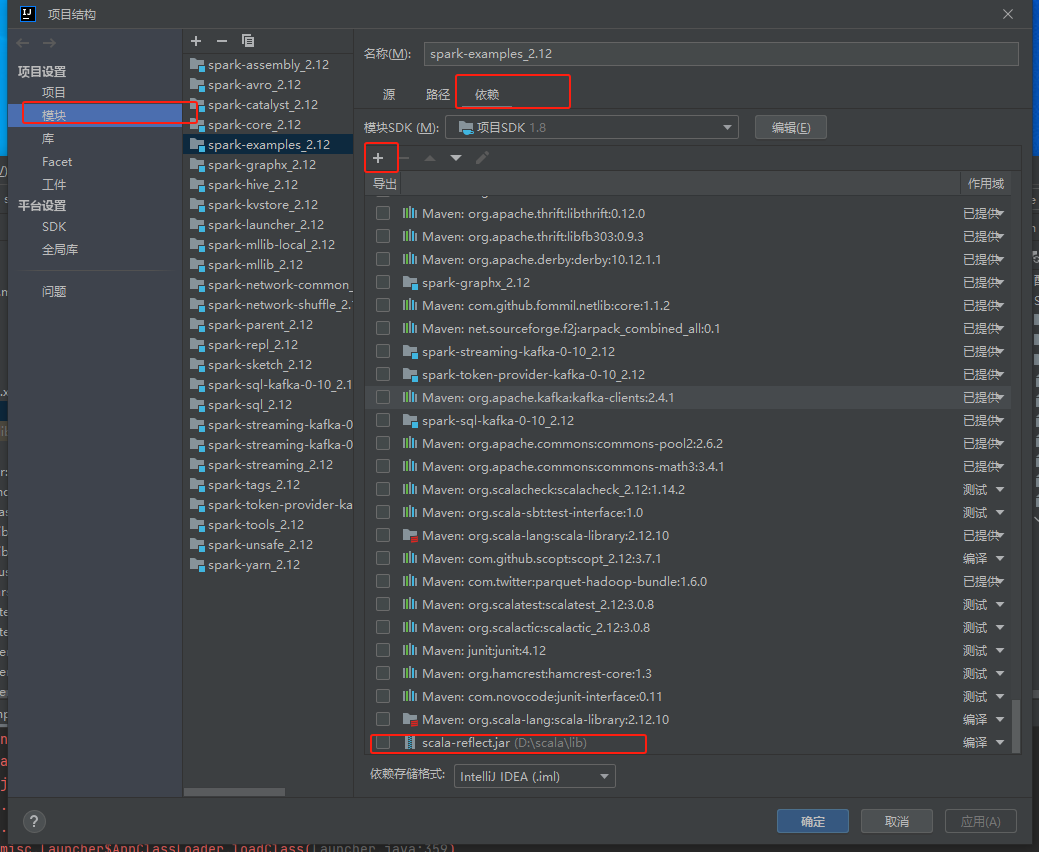
在spark-example模块的依赖加上scala-reflect的jar包
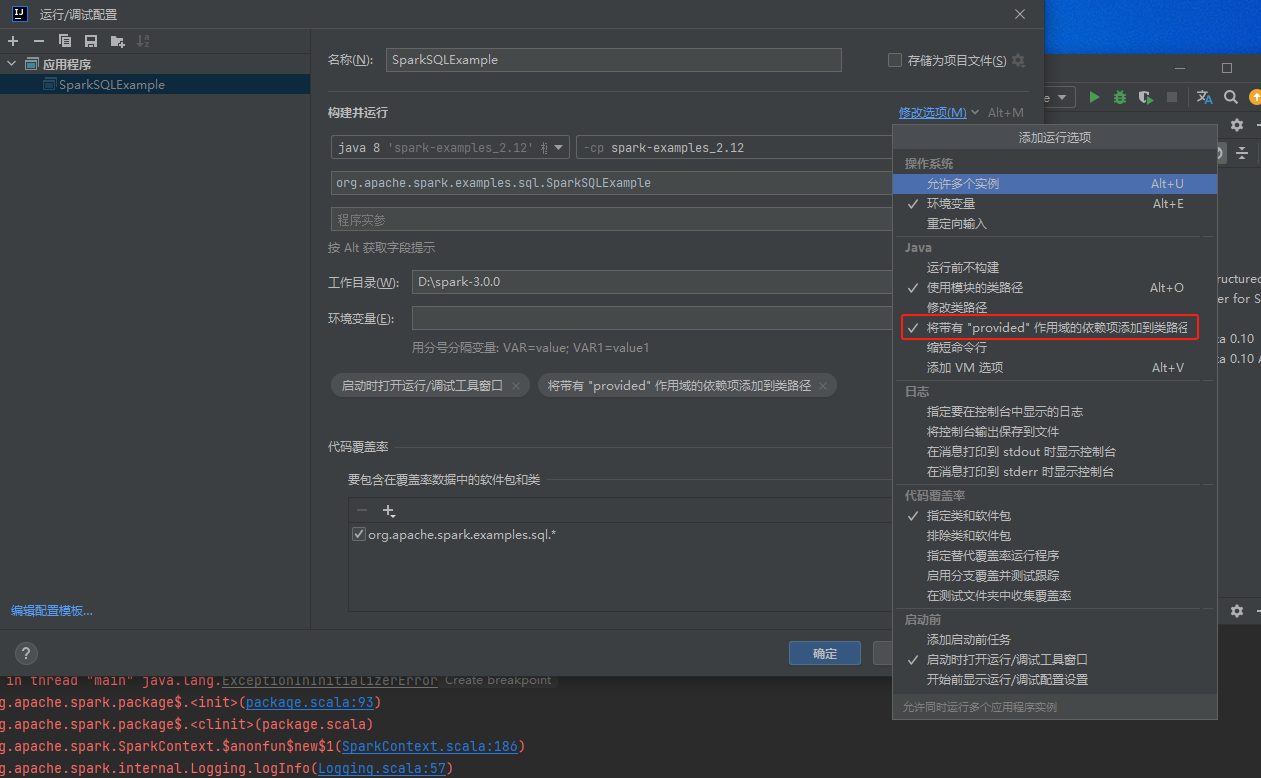
在运行界面上,选中'将带有provided依赖加入路径'
没有spark版本文件
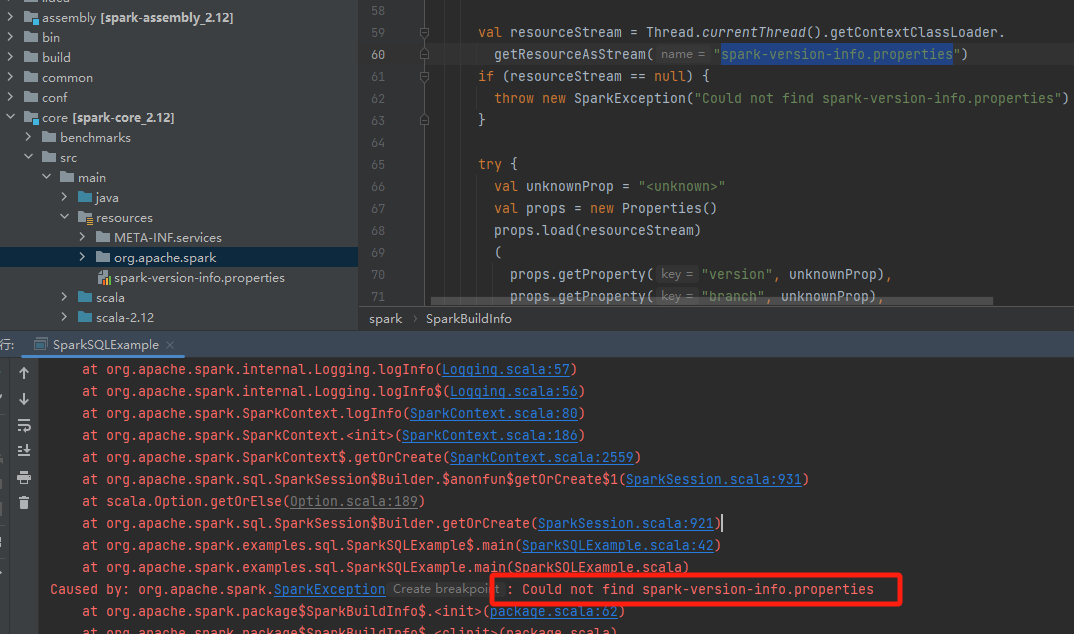
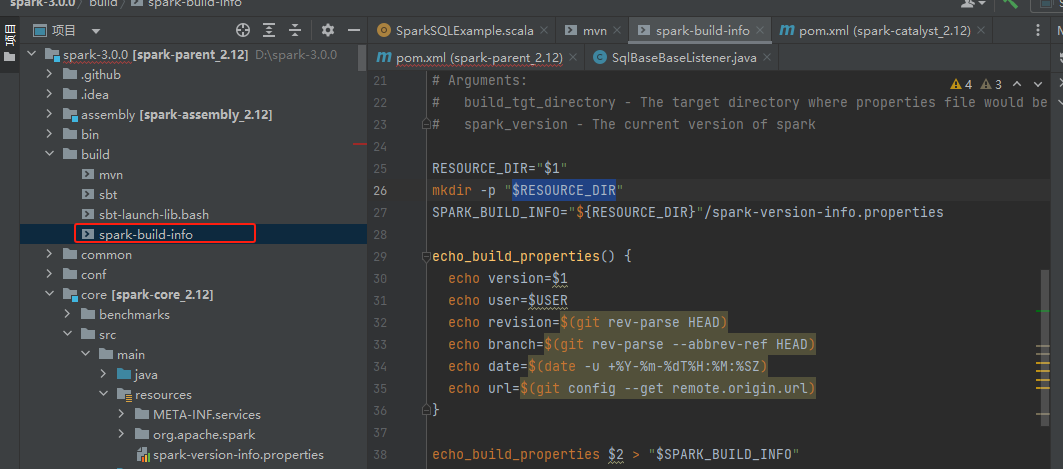
spark版本文件是spark-build-info.sh文件生成的
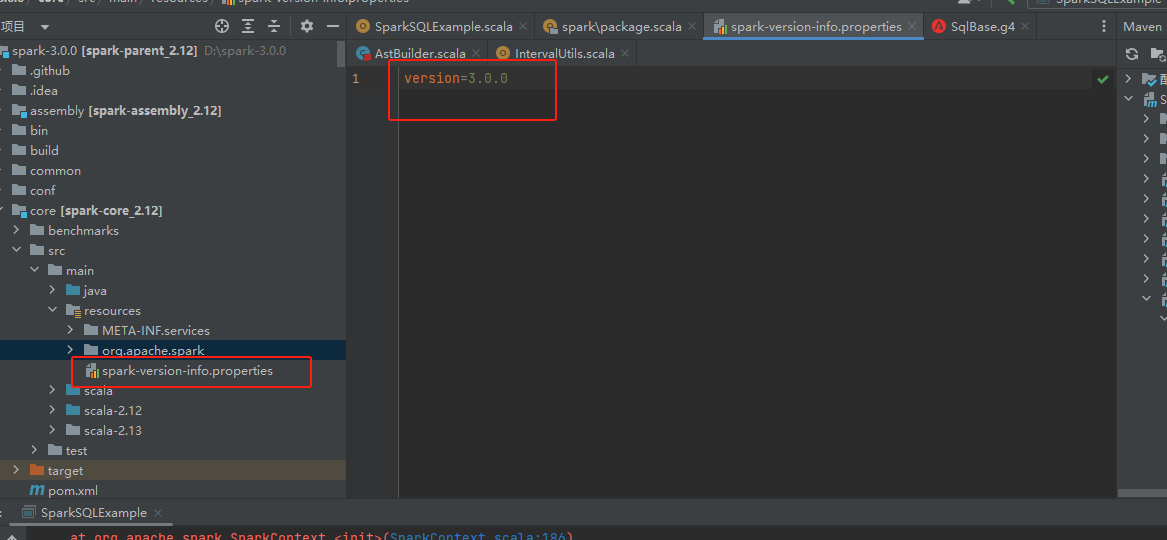
我们可以手动在创建spark-version-info.properties文件,写上版本
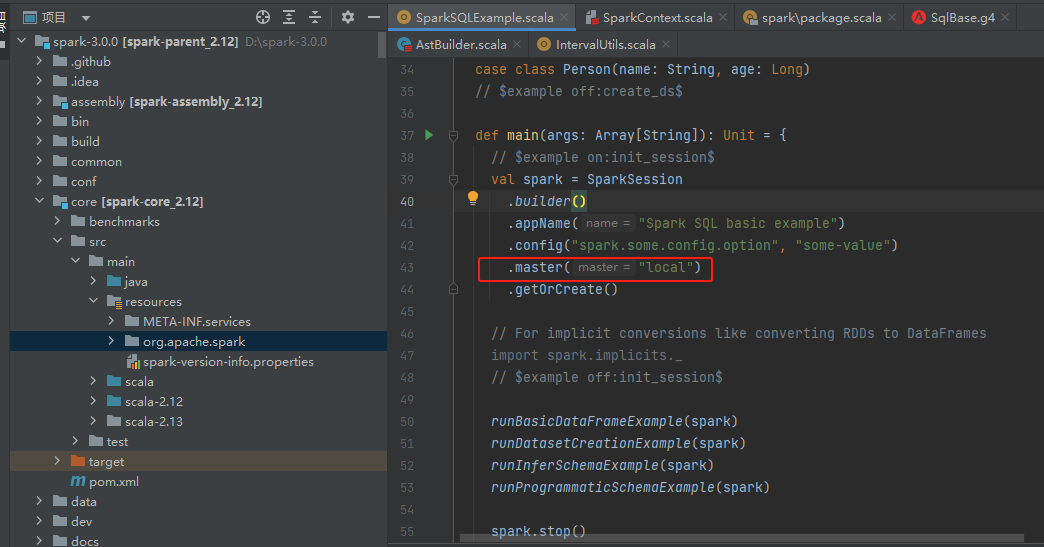
Master URL没有指定
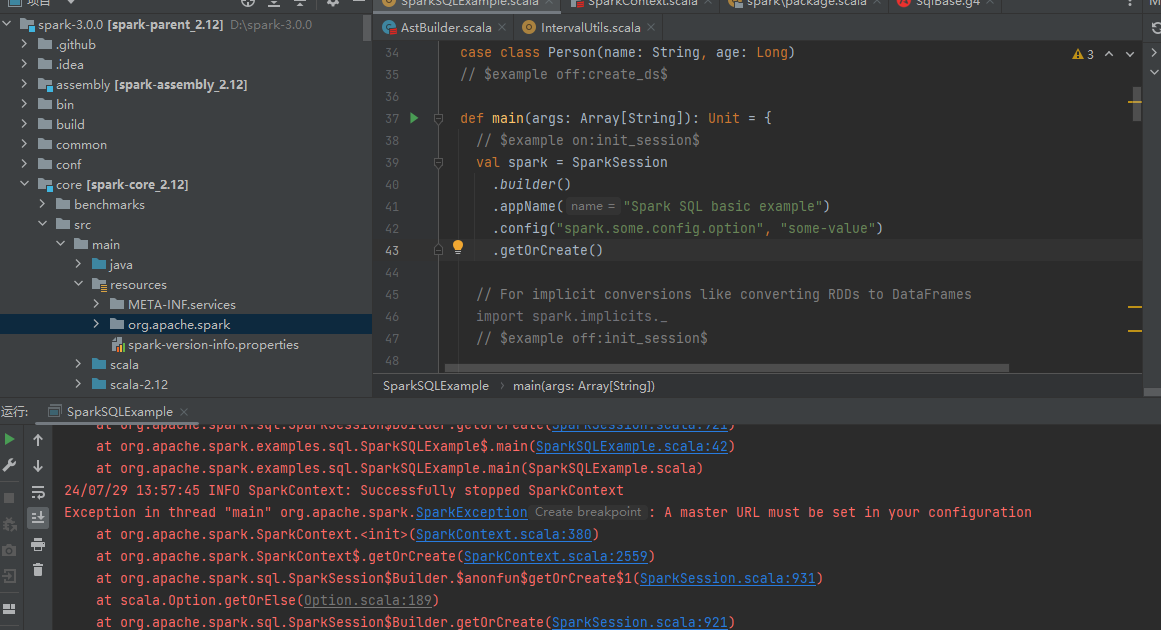
代码中加上master的配置
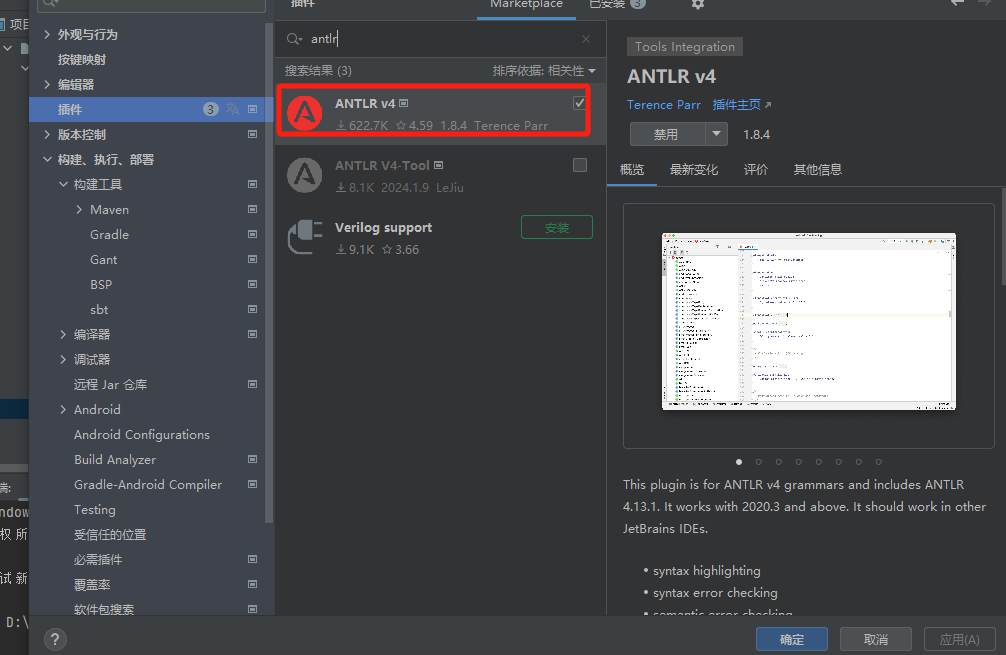
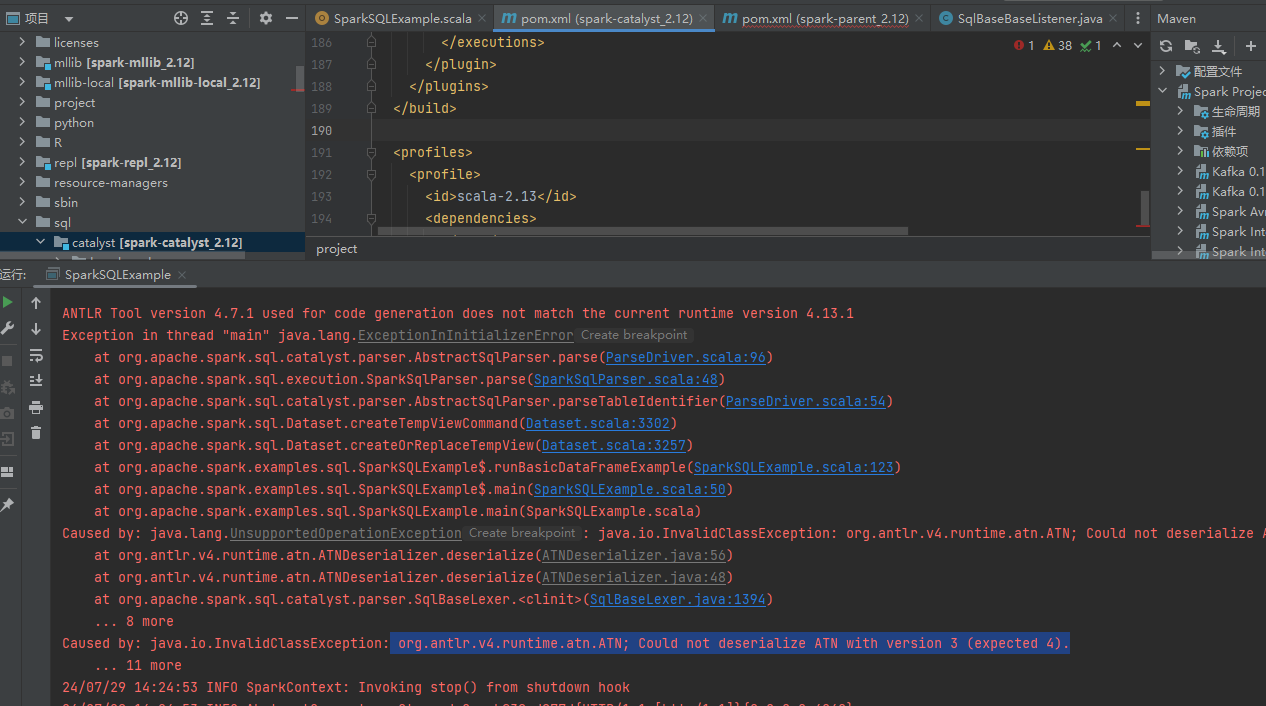
ANTLR版本不对
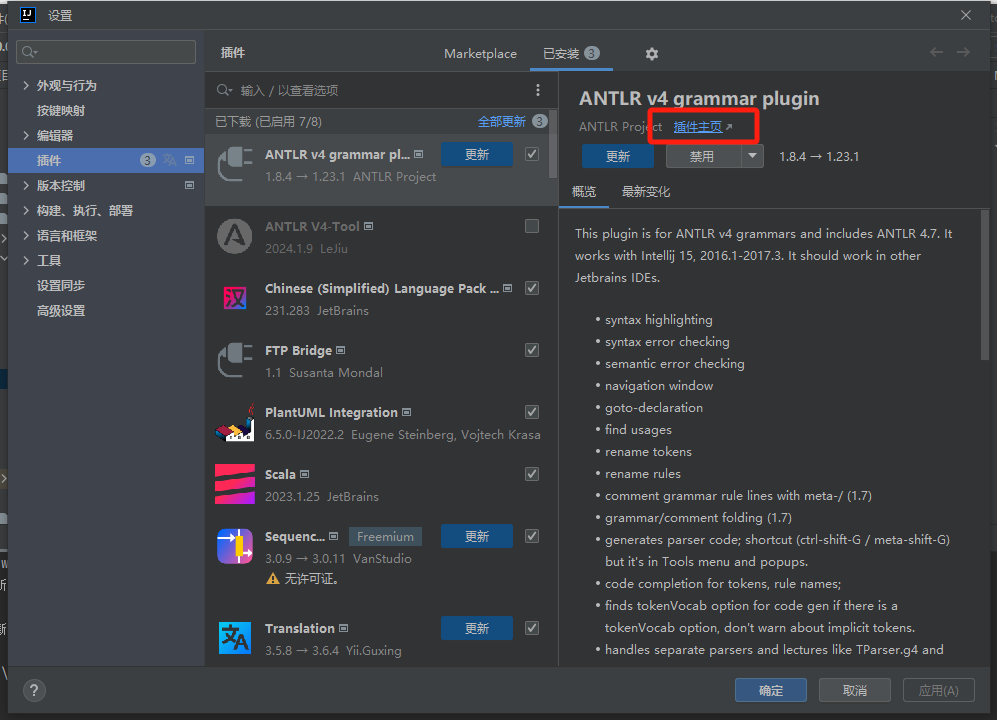
在对应plugin中找到插件主页。
在主页中找到对应版本的插件下载
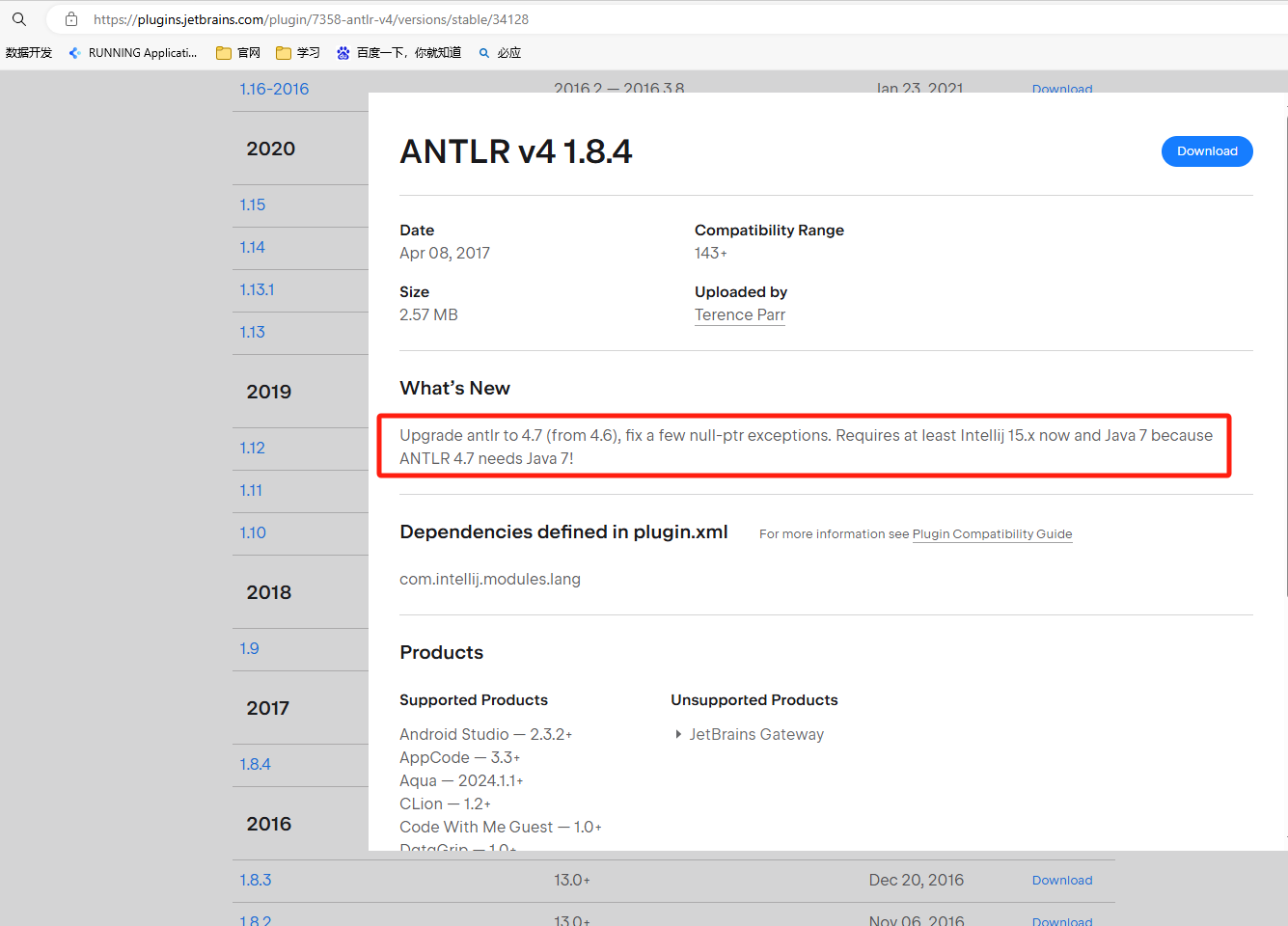
手动安装下载的插件