从科学计算到人工智能,从AI模型开发到AI模型训练,从双精度到半精度,从OPENGL到CUDA,GPU都扮演着关键角色。本文主要从运维的人员的角度出发,来探讨GPU使用过程中遇到的管理问题和创新性解决办法。
GPU的管理和监控
相信每个运维中心都会有各类系统的监控大屏,在针对基础计算平台的监控中,通常会有CPU、内存、网络、存储等资源的使用监控及告警机制,同时还会有各类资源使用情况的TOP排名等。大家可能会发现一个问题:它缺少对GPU的详细数据监控------可能会有一些整卡数量和分配的数据统计,但是APP运行过程中,GPU是否在运算、GPU的算力高峰和低谷分别在什么时候等数据却因为缺乏有效的管理手段来统计,所以通常只能依靠运维人员对业务的理解和经验来判断。
OrionX AI算力池化解决方案,不仅能辅助管理员解决GPU使用过程中遇到的资源不足等问题,还能通过自身强大的智能化统计中心帮助运维人员提升运维管理能力。具体能力如下:
01 GPU资产统计
在OrionX界面中进入统计中心,打开资产管理统计界面,可以自定义信息表单,如GPU设备数量、算力分配和总量、显存分配和总量、虚拟设备使用数等指标。
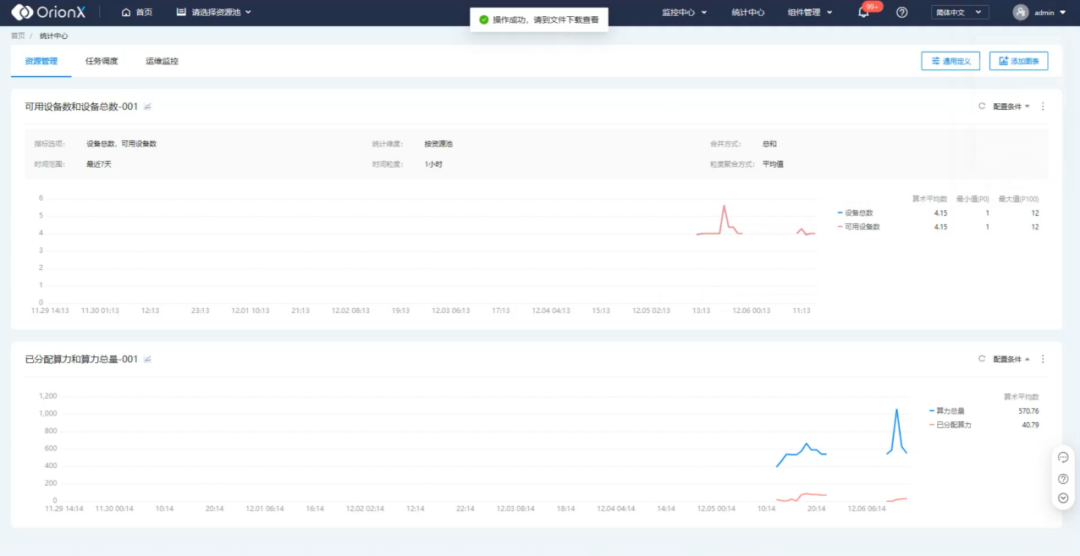
图1. 自定义监控面板
除此之外,用户还可以设置统计项目,并根据需求调整统计图表的位置、显示内容、呈现方式等。当然,导出统计数据也是必不可少的能力。
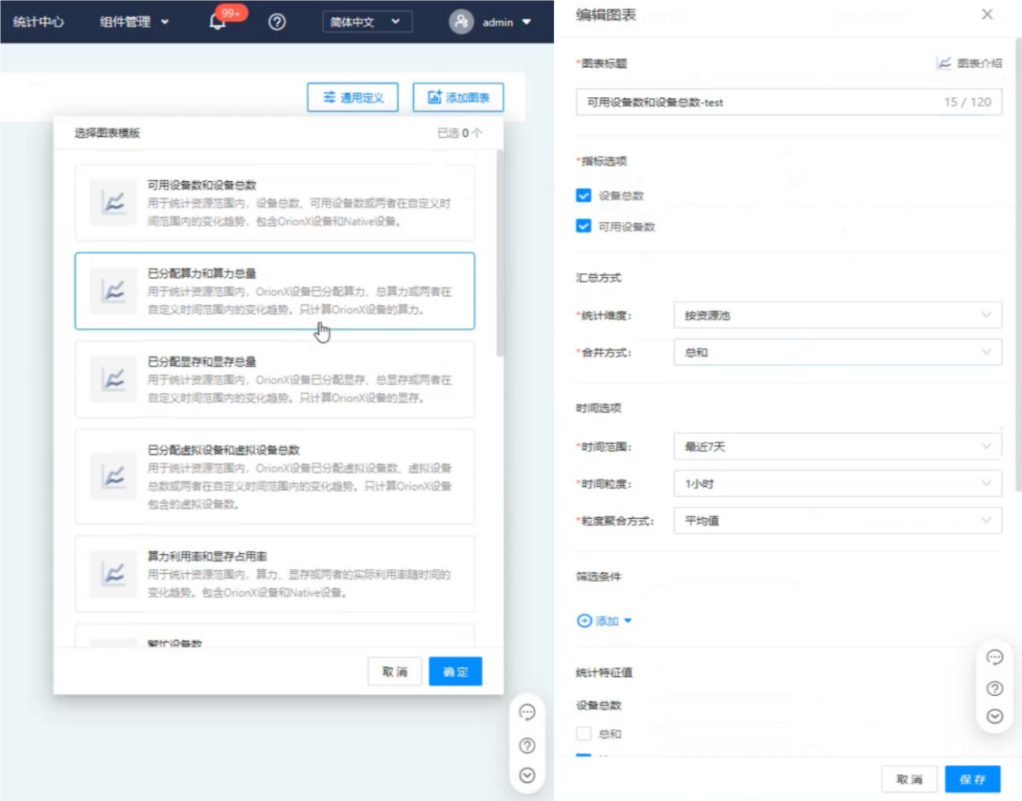
图2. 图表内容均可定制
02 GPU任务调度统计
OrionX支持用户对GPU任务调度情况自定义多种统计维度,如并发任务数、24小时内任务申请的潮汐规律、任务数按资源分布、以及按照各种类型的ID进行分类等。

图3. 任务调度潮汐直观可见
03 运维监控
OrionX的运维监控界面提供了常规的设备运维监控指标,包括设备总数、可用设备数、异常告警、设备功耗等,方便用户评估集群规模、可用状态、运行状态、集群设备功耗变化等,为AI算力集群的建设和维护提供基础数据支撑。
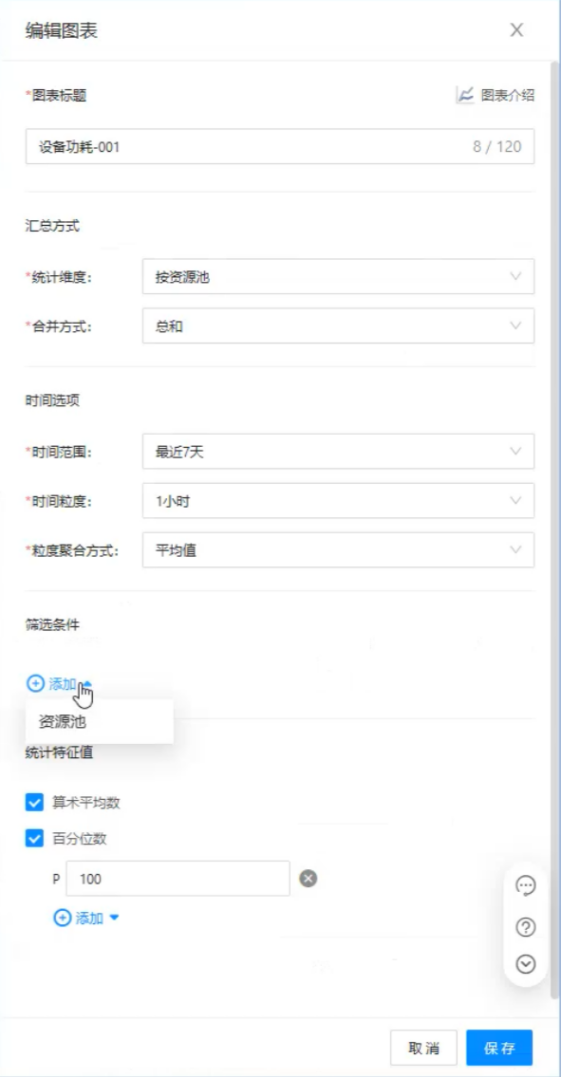
图4. 图表模板已预设,点选即可掌握集群状况
04 用户管理
解决了度量问题之后,用户就可以根据取得的数据采取合理措施来优化GPU的使用。于是新的问题又出现了,统计数据一般是管理员可见,真正的算力使用者一般是看不到的,也就没有办法自发地优化资源使用。
为了减少管理员的工作量,OrionX新增加LDAP的对接功能,支持GPU使用者拥有OrionX的登录权限,方便查询统计资源的使用情况。在OrionX的用户管理界面,就能找到LDAP的对接入口,根据系统提示输入对应的参数信息即可快速登录。
为了保证系统和数据的安全稳定,管理员可通过OrionX的用户管理界面对LDAP的用户权限进行自定义和修改,并且不受后续LDAP信息同步的影响。
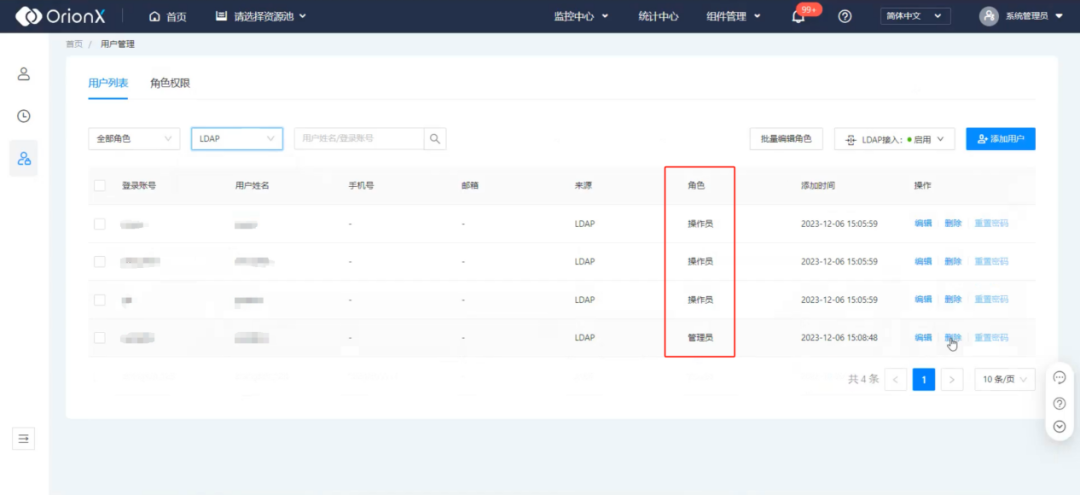
图5. OrionX用户管理界面示意图
GPU的热迁移和任务强制终止
OrionX除了拥有强大的监控统计功能外,还给管理员提供了许多管理手段,例如热迁移、强制任务停止等功能。这些能力又能在哪些场景为用户提供价值呢?
01 热迁移使用场景
OrionX热迁移是指将AI算力硬件上正在运行的计算任务和数据,从一个物理算力设备无缝迁移到另一个物理算力设备的过程,这个过程不需要中断或停止当前正在进行的计算任务。热迁移的主要目的是在不影响服务可用性的情况下,实现对AI算力资源的动态管理和优化。
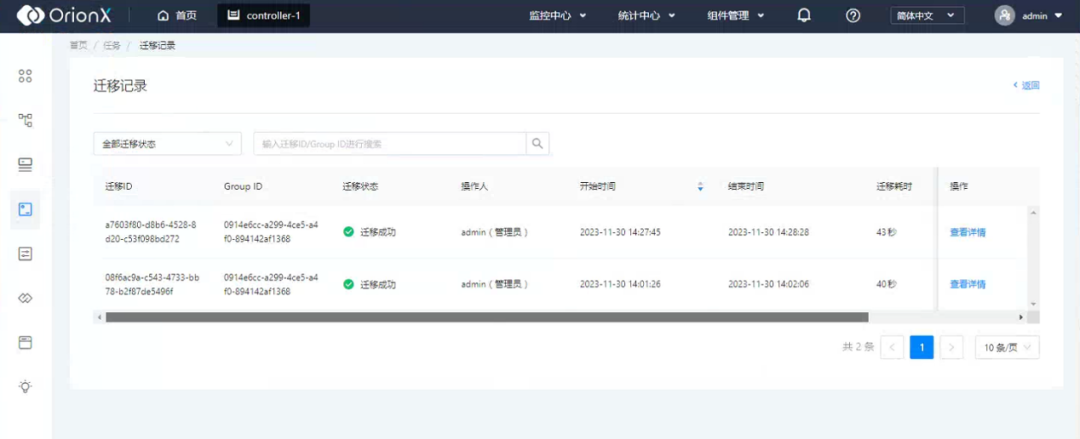
图6. OrionX热迁移示意图
场景一:设备维护
在没有热迁移功能时,维护一台在线的GPU设备需要很多准备工作,如找到合适的时间窗口、联系业务人员停止业务、进行流程审批等,会消耗不少时间和精力。
当拥有OrionX热迁移能力时,运维人员只需要找一个合适的时间窗口,仅需在控制界面将目标GPU设备上的AI任务点选,迁移到其他设备上执行,就可以开始设备的运维工作了,可大大减少运维工作量。
场景二:碎片整理
在长时间运行的AI应用中,显存分配和释放的不规则性,可能会导致显存碎片化,降低显存的利用效率。OrionX热迁移技术可实现对显存的动态整理和优化,将碎片化的显存重新整合,提高显存的利用效率,减少显存碎片对性能的影响,从而提升应用程序的性能和稳定性。
场景三:提升资源利用率
大家可能会产生一个疑问:热迁移是将任务从一个GPU迁移到另外一个GPU上,理论上资源占用并没有变化,是如何提升利用率的呢?这个就要从OrionX的热迁移的高阶用法说起。
OrionX的热迁移能让AI任务在不同设备之间来回迁移,还能够将任务的运行状态保存到硬盘中。当AI任务长时间没有响应、触发了管理员预设的释放资源时长阈值时,OrionX会将AI任务的相关数据和状态保存到硬盘中,将资源动态调配给其他任务;在后续收到该任务请求时,再将之前的状态还原到GPU中,从而在保证业务前后状态连贯性的同时,解决GPU资源被响应频率低业务长时间占用的难题。
02 强制任务停止场景
强制任务停止功能可以提升管理员的资源调配能力,在有紧急任务需要执行但资源不足的时候,管理员可通过手工结束一些重要性低、响应较少的任务,快速聚合相应算力资源进行支持。管理员也可以通过该功能清理一些不在预期内的资源占用,保障整个AI算力集群的健康状态。

图7. 资源占用情况尽在掌握
结 语
借用现代管理学之父彼得·德鲁克的一句话------如果你无法度量,那么就不能有效增长。"增长"几乎是现在所有企业的目标,对于企业的IT部门来讲,能够度量好、使用好当前的IT资源,无疑是企业实现降本增效非常好的途径。
OrionX为企业的运维部门提供了全面又好用的AI算力管理工具,结合OrionX的算力池化功能,帮助用户在面对不断增长的算力需求时从容应对,专注业务增长。