关联比赛: 第三届 Apache Flink 极客挑战赛暨AAIG CUP------电商推荐"抱大腿"攻击识别
第三届Apache Flink 极客挑战赛暨AAIG CUP比赛攻略_大浪813团队
第三届Apache Flink 极客挑战赛暨AAIG CUP 自2021年8月17日上线以来已有 4537 个参赛队伍报名。11月09号,大赛复赛结束,我们团队(队伍名称:大浪813)最终取得了初赛第7名,复赛第8名的成绩。下面就将我们团队的比赛心得和攻略分享一下,与各位参赛小伙伴共勉。
1.1 赛题说明
1.1.1 赛题背景
随着互联网的发展,网购成为越来越多人的选择,据阿里巴巴财报显示,2020财年阿里巴巴网站成交总额突破一万亿美元,全球年度活跃消费者达9.60亿。
为了满足不同用户的个性化需求,电商平台会根据用户的兴趣爱好推荐合适的商品,从而实现商品排序的千人千面需求。推荐系统常见的召回路径有U2I(User-Item)、I2I(Item-Item)等。其中,user-to-item是指通过用户的 profile信息为用户进行商品的推荐,而item-to-item推荐策略则根据用户的商品点击列表为用户推荐关联的商品。
推荐系统的目的是基于不同用户的偏好进行千人千面的推荐。传统的离线推荐系统基于用户历史的行为数据进行加工处理,形成特征样本,然后离线训练模型,并且在线部署进行服务。然而用户的偏好是多元的、用户的行为分布会随着时间而变化,离线的模型无法刻画这种动态的用户偏好,因此需要进行实时的特征更新与模型参数更新,从而能够更好的捕获用户的行为偏好。在推荐场景中,为了更好的提升推荐的时效性与准确性,平台会基于全网的用户行为信息进行实时的 U2I 及 I2I 的更新,并且基于用户最近的行为信息进行相关性的推荐。
为了获取更多的平台流量曝光,将自己的商品展现在更多的消费者面前,部分商家通过HACK平台的推荐机制从而增加商品的曝光机会。其中一种典型的手法为"抱大腿"攻击,该方法通过雇佣一批恶意用户协同点击目标商品和爆款商品,从而建立目标商品与爆款商品之间的关联关系,提升目标商品与爆款商品之间的I2I关联分。商家通过这种方式诱导用户以爆款的心理预期购买名不符实的商品,不仅损害了消费者的利益,降低其购物体验,还影响了平台和其他商家的信誉,严重扰乱了平台的公平性。因此,我们需要用一个风控系统来过滤掉这些可能的恶意流量,避免它们对推荐系统的模型造成干扰。
由于所有用户行为在输入推荐系统之前,都会首先经过风控系统的过滤,所以如果想要做到推荐系统的实时性,风控系统就必须同样做到实时性。实时拦截此类行为,有助于在保证推荐的时效性的同时,保护实时推荐系统不受恶意攻击影响。
实时风控系统对数据安全的要求较高,如果系统的拦截算法意外泄漏,HACK平台将得以针对性地加强恶意流量的伪装能力,增大平台监控恶意流量的难度,因此,此类系统有必要部署在加密的可信环境中。
综上所述,为了保障实时推荐系统的准确性,比赛要求选手实现一个保证了数据安全的实时风控系统。本次大赛要求选手基于Flink,Analytics Zoo/BigDL 等组件,在Occlum环境中搭建保护数据安全的PPML(Privacy Preserving Machine Learning)应用,实现对恶意流量的实时识别。
1.1.2 技术介绍
Apache Flink 是一个在无界和有界数据流上进行状态计算的框架和分布式处理引擎。Flink 已经可以在所有常见的集群环境中运行,并以 in-memory 的速度和任意的规模进行计算。
在Flink的基础上,Flink AI Flow作为兼顾流计算的大数据 + AI 顶层工作流抽象和配套服务,提供了机器学习的端到端解决方案。
Analytics Zoo及BigDL是英特尔®开源的统一大数据分析和AI平台,支持分布式TensorFlow及PyTorch的训练和推理,通过OpenVINO工具套件和DL Boost指令集等,提升深度学习工作负载的性能。Cluster Serving是Analytics Zoo/BigDL的分布式推理解决方案,可以部署在Apache Flink集群上进行分布式运算。
Occlum是蚂蚁集团基于Intel SGX的开源LibOS,使得 Linux 应用程序在只修改少量代码或者完全不修改代码的情况下运行于 Enclave 安全环境中,保证数据处于加密和强隔离状态,确保数据安全与用户隐私。
1.1.3 数据说明
给定恶意点击、正常点击及对应的"商品"、"用户"相关的属性信息(用户本地调试可以从网上下载),选手实现实时的恶意点击识别分类算法,包括模型训练和模型预测。在大赛评测系统中,系统使用100万条数据用于模型训练、10万条数据用于模型预测。另外,比赛提供给选手50万条数据的数据集用于算法的本地调试。
比赛提供如下格式的数据用于训练与预测。所有数据均采用csv格式保存在文件中,即以下数据格式的各列之间以逗号分隔。每条数据代表一次用户点击商品的行为,它的特征主要来源于其所关联的用户与商品。
· uuid:每条数据的id。该id在数据集内具有唯一性。
· visit_time:该条行为数据的发生时间。实时预测过程中提供的数据的该值基本是单调递增的。
· user_id:该条数据对应的用户的id。
· item_id:该条数据对应的商品的id。
· features:该数据的特征,包含N个用空格分隔的浮点数。其中,第1 ~ M个数字代表商品的特征,第M+1 ~ N个数字代表用户的特征。
· label:值为0或1,代表该数据是否为正常行为数据。
训练数据包括上述所有列的数据,预测数据包括除了label之外的所有列。
1.1.4 评分指标
选手提交结果的分数由两方面评分的乘积来决定,两方面分别代表选手提交结果的算法与工程方面的表现。用一个公式表示即如下所示:
score=F1 ∗valid_latency
在算法方面,比赛根据推理结果的F1参数来评分,即推理结果的准确率与召回率的调和平均数。
在工程方面,由于比赛模拟实时风控场景,所以比赛对实时推理过程中的延迟做出限制。选手的程序需要为kafka中出现的实时数据流提供推理服务,并在数据流的流量不超过给定阈值的情况下,单条数据的延迟不超过500ms。
选手部署的推理服务需要从kafka中读取待推理数据,并将推理结果写入kafka。数据的延迟的定义即为待推理数据及其推理结果在kafka中的时间戳的差值。上述公式中的valid_latency,即为延迟符合要求的数据占所有数据的比例。延迟超过500ms的数据不仅会影响到valid_latency的值,进而影响到分数,而且也不会参与F1参数的计算过程。
1.1.5 赛题解析
本次赛题注重算法和工程的结合,解答赛题大概要经过以下几个阶段:模型训练、模型评估并选取最优阈值、在线预测。
· 模型训练:大赛给的训练数据都是结构化的,可以直接使用其中的Feature字段进行训练。在 大赛demo 里,构建了一个前向反馈网络进行模型的训练,直接拟合样本的标签;但是如果想取得更好成绩,则必须需要根据User和Item的时序关系,构造更加有效的动态和组合特征;同时业界有很多成熟的DNN模型,选手可以考虑使用更复杂的模型进行训练,或者考虑基于集成学习的方式混合多个模型/策略进行预测;另外,由于实时性500ms的要求,过于复杂的模型将引入更大的延迟,因此如何权衡模型的性能与实时性将是模型设计的重要考量点。
· 模型评估并选取最优阈值:由于在线预测使用的是直接判定类别,而不是输出一个概率(这个是非常符合实际业务场景的),因此必须选取一个合理的概率阈值来判定最终类别。由于预测阈值的选取对于模型的线上效果影响特别大,因此一般需要对模型进行评估并确定最优阈值。
· 在线预测并判定类别:为了将训练与预测阶段做到更好的分离,在在线预测阶段,使用的是 cluster serving 的形式,因此预测只需要直接加载训练好的模型,便可以进行预测;在最终输出的时候通过比较当前预测概率与最优阈值的大小,从而确定当前样本的预测类别(是否作弊)
1.2 赛题理解:难点与挑战
由于大赛的评分标准包含了算法的部分(F1)和工程的部分(valid_latency),同时由于大赛最终是以Docker镜像方式提交,需要在线完成批量特征构造,模型训练,最优阈值确定,实时特征构造,实时预测等全部流程,因此实际比赛中,工程部分的挑战与算法方面的挑战同样艰巨。因此,我们总结的赛题难点与挑战也包括了算法与工程两大部分。
1.2.1 算法部分:
1 数据分析与特征工程:
也就是如何分析、构造更有效的批量和基于流的动态和组合特征?因为赛题中的Feature和Id字段都是偏向于静态的特征,同时赛题中没有明显给出User和Item的动态特征,因此选手需要通过User和Item的点击时序关系自己建立有效的动态和组合特征。
2 数据处理
数据处理中的难点和挑战包括:
1) 如何有效利用Unlabel数据提高模型性能?复赛中train0.csv给出的100万条数据中,只有10万条有Label,其他数据需要选手自己决断。
2) 如何处理不均衡数据?复赛train0.csv中Label1的数据与Label0的数据比例大致为2:8。
3 网络结构与训练策略
网络结构与训练策略中的难点与挑战包括:
1) 如何构造更有效的满足实时性要求的网络结构?由于大赛中规定单个数据从kafka接收到预测完毕输出到kafka之间的耗时必须在500毫秒以内,这其中包括了kafka输入输出,在线特征构造和预测的全部时间,因此预测的网络结构不能过于复杂,那么如何构造满足实时性要求的网络结构就是一个挑战。
2) 如何选择训练策略?复赛中要求两次预测,因此,到底是训练1轮还是训练2轮,是全量训练还是增量训练,是否加入预训练就是一个需要权衡和实验的点,因此这也是一个挑战。
4 模型稳定性与预测阈值的选择
1) 神经网络模型的一个挑战就是模型稳定性,那么如何增加模型的稳定性也是本赛的一个挑战。
2) 另外,由于预测阈值的选取对于模型的线上效果影响特别大,因此如何确定预测阶段的概率阈值也是一个挑战。
1.2.2 工程部分:
1 Occlum中各组件内存分配
如何解决Occlum中各组件和各训练阶段的内存不足问题?本次大赛要求从训练到预测的全部流程都需要在Occlum中执行,而Occlum中的总内存是固定的,按照主办方给出的默认内存配置和大内存配置运行,几乎肯定的是会到处碰到OutOfMemory或资源不足的问题,因此如何解决Occlum中各组件的内存分配是工程部分遇到的第一个挑战。
2 预测阶段长尾现象:Warmup
如何解决预测初始阶段长尾现象?预测初始阶段的长尾现象指的是预测阶段的初始样本的预测会发生高延迟现象,同时初始样本的高延迟也导致后续样本的预测连带延迟。这是工程部分的第二个挑战。
3 Flink中实时动态特征的构造
如何在实时性要求下构造基于流的有效的动态特征?如何构造有效的动态特征是算法部分的一个挑战,但是当算法部分解决了这个问题后,就需要在Flink实时流中构造动态特征,并且必须满足500ms的实时性要求,这也是一个工程挑战。
4 Occlum内外各组件关键流程可见性
另外,在实际调试中,我们发现Occlum内外各组件日志彼此独立,内部运行情况和关键流程的耗时很难分析,同时Occlum内的代码很难调试,比如一个Flink AI Flow的bug就是第一轮训练的日志会被第二轮训练的日志覆盖掉,因此第一轮训练的情况很难通过日志搞清楚,甚至经常遇到第一轮训练成功,第二轮训练OutOfMemory导致训练日志中只有errno 12,而没有其他有用的训练信息。第二个问题就是预测任务只有被真正杀掉或异常退出后,才能看到内部日志,本地调试时很难随时看到预测任务的内部信息。因此怎么能方便调试,方便掌握和分析内部运行情况和关键流程耗时也是工程中的一大挑战。
1.3 方案与实验
针对以上大赛中的难点与挑战,我们做了各种实验,并最终给出了有效的解决方案。
1.3.1 总体架构
下面是我们方案的总体架构。
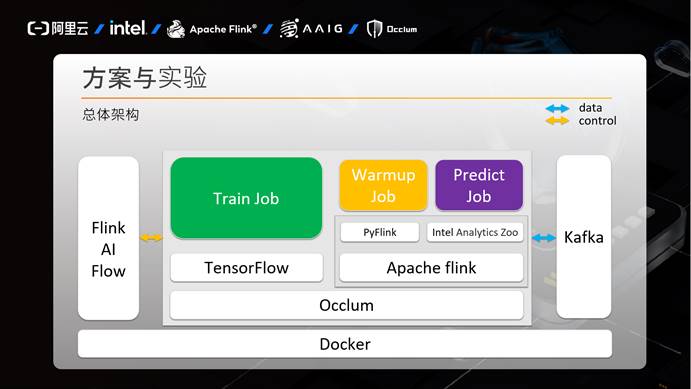
本次大赛的全部代码都是运行于Docker镜像内。Docker镜像内的组件又分为Occlum内的组件和Occlum外的组件。Occlum外的组件包括Flink AI Flow和Kafka,Occlum内的组件包括训练任务依赖的TensorFlow等组件,和预测任务依赖的Apache Flink和Intel Analytics Zoo等组件。
图中白色背景组件是标准的第三方组件,而绿色的训练任务,橙色的预热任务和紫色的预测任务是我们方案需要编写的组件。我们团队的方案是在Baseline基础上加入了橙色的预热任务,预热任务的引入主要是为了解决预测阶段的长尾问题。
Flink AI Flow负责调度训练任务,预热任务和预测任务的运行,Kafka负责与预热和预测任务进行数据交互。
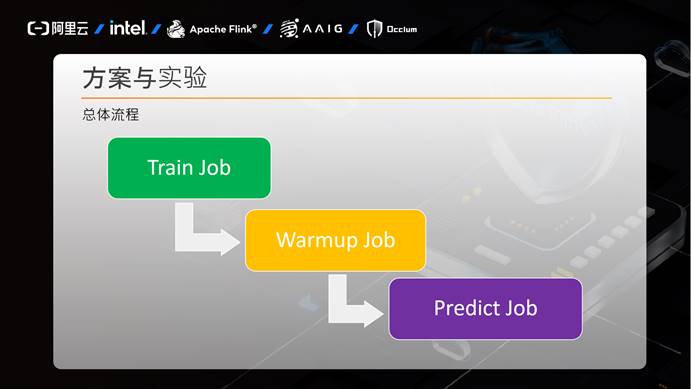
下图是我们方案的总体流程,首先是训练任务,训练任务结束后拉起预热任务,预热任务结束后拉起预测任务。
下面是我们方案的具体流程:
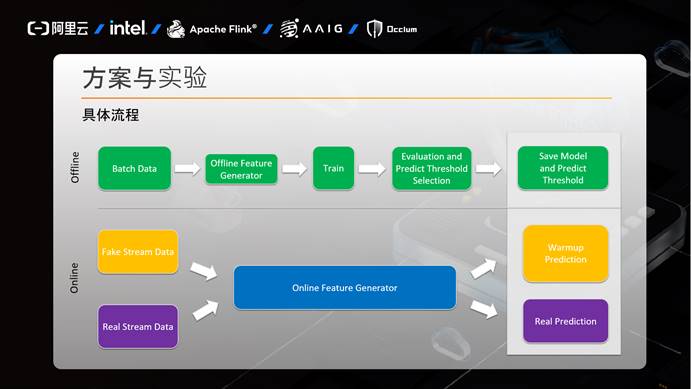
1) 训练任务:训练任务首先读取批量数据,通过批量数据构造特征,然后进行训练,训练完毕,对模型进行评估并选择最优预测阈值,最后保存模型和预测阈值。
2) 预热任务:预热任务首先通过Kafka读取假的实时流数据,然后在线构造特征,然后通过训练任务保存的模型和预测阈值进行预测,并发送结果数据给Kafka输出Topic。
3) 预测任务:预测任务类似预热任务,首先通过Kafka读取真实的实时流数据,然后在线构造特征,然后通过训练任务保存的模型和预测阈值进行预测,并发送最终结果数据给Kafka输出Topic。
预热任务和预测任务只有输入和输出Kafka数据部分不同,其他都共用代码。通过预热任务我们最终取得了评分指标中valid_latency为1的完美结果。
1.3.2 特征工程
下面是我们的特征工程:
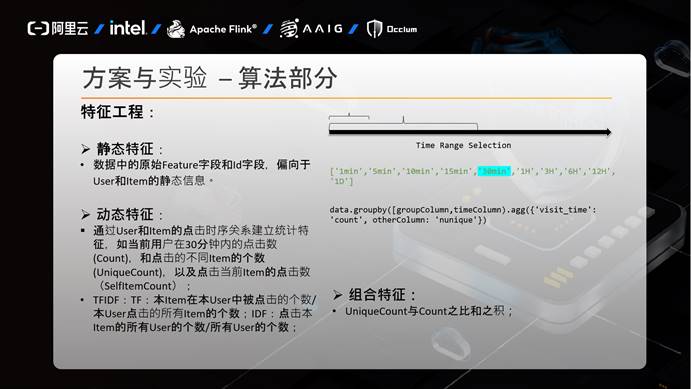
特征工程主要包括三个部分:
1) 静态特征:
赛题中的Feature和Id字段都是偏静态的特征,我们没有过多处理。
2) 动态特征:
赛题中没有给出明显的动态特征,因此各参赛选手需要自行决定自己方案的动态特征。我们方案中的动态特征主要是根据User和Item的点击时序关系建立的统计特征,比如,对于当前User而言,当前User在30分钟内的点击数(count),点击不同Item的个数(UniqueCount),以及点击当前Item的点击数。同时对于当前Item而言,反之亦然。
另一各动态特征就是TFIDF特征,比如TF:最近30分钟内,当前Item在当前User中的点击数/当前User的所有Item的点击数;IDF:点击当前Item的所有User的个数/所有User的个数等。
3) 组合特征:
对于组合特征,我们只是简单的引入了UniqueCount和Count之比,之积,没有更多的精力继续实验。
对于特征工程而言,另一个重要的方面就是时间粒度的选择。我们的做法是从1分钟到1天中的多种粒度全部实验选取,我们的实验表面,如果使用全部时间粒度的全部动态特征,那么模型的最终效果是最好的。但在在线实时流基础上构造特征时,如果构造全部时间粒度的特征,那么将非常耗时,无法满足实时性500ms的要求,因此必须对时间粒度和动态特征进行取舍。
查看更多内容,欢迎访问天池技术圈官方地址: 第三届Apache Flink 极客挑战赛暨AAIG CUP比赛攻略_大浪813团队_天池技术圈-阿里云天池