1.TCP/IP 网络分层模型
- 第一层叫"链接层"(link layer),负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次上,使用 MAC 地址来标记网络上的设备。
- 第二层叫"网际层 "(internet layer),IP 协议就处在网际层。用 IP 地址取代 MAC 地址,把许多局域网、广域网连接成一个虚拟的巨大网络,如果要在这个网络里找设备则要把 IP 地址"翻译"成 MAC 地址。
- 第三层叫"传输层 "(transport layer),负责在 IP 地址标记的两点之间"可靠"地传输数据,是 TCP 协议 和 UDP 协议 这两个传输层协议工作的层次。
|----------------|--------------|---------------|
| 特性\传输层协议 | TCP | UDP |
| 是否是有状态的协议? | 是 | 不是 |
| 是否需要事先建立连接 | 需要 | 不需要 |
| 数据的形式 | 连续的字节流,有先后顺序 | 分散的数据包,顺序发乱序收 |
- 第四层叫"应用层"(application layer),负责面向具体的应用传输数据,应用层有面向具体应用的各种协议,HTTP 协议就在这一层,还有一些例如 FTP 协议、SSH 协议 等等。
2.OSI 网络分层模型
- 第一层:物理层,网络的物理形式,例如电缆、光纤、网卡、集线器等等;
- 第二层:数据链路层,它基本相当于 TCP/IP 的链接层,负责在底层网络上发送原始数据包,工作在物理层之上,使用MAC地址标记网络中的设备;
- 第三层:网络层,相当于 TCP/IP 里的网际层,用IP地址取代MAC地址,将许多局域网、广域网连接成一张虚拟的巨大网络;
- 第四层:传输层,相当于 TCP/IP 里的传输层,负责在IP地址标记的两点之间可靠的传输数据;
- 第五层:会话层,维护网络中的连接状态,即保持会话和同步;
- 第六层:表示层,把数据转换为合适、可理解的语法和语义;
- 第七层:应用层,面向具体的应用传输数据。
3.OSI 网络分层模型 到 TCP/IP网络分层模型 的映射关系
- 第一层:物理层,TCP/IP 里无对应;
- 第二层:数据链路层,对应 TCP/IP 的链接层;
- 第三层:网络层,对应 TCP/IP 的网际层;
- 第四层:传输层,对应 TCP/IP 的传输层;
- 第五、六、七层:统一对应到 TCP/IP 的应用层。
"四层"和"七层"到底是什么?"五层""六层"哪去了?
- 四层七层是OSI分层模型里的第四层传输层和第七层应用层。OSI把五六七层分太细,实际上五层会话层和六层表示层通常和具体应用联系非常紧密,不好分开,他们三层映射到TCP/IP 网络分层模型中都是应用层,比如说HTTP 协议就同时包含了连接管理和数据格式定义。
4.TCP/IP 协议栈的工作方式
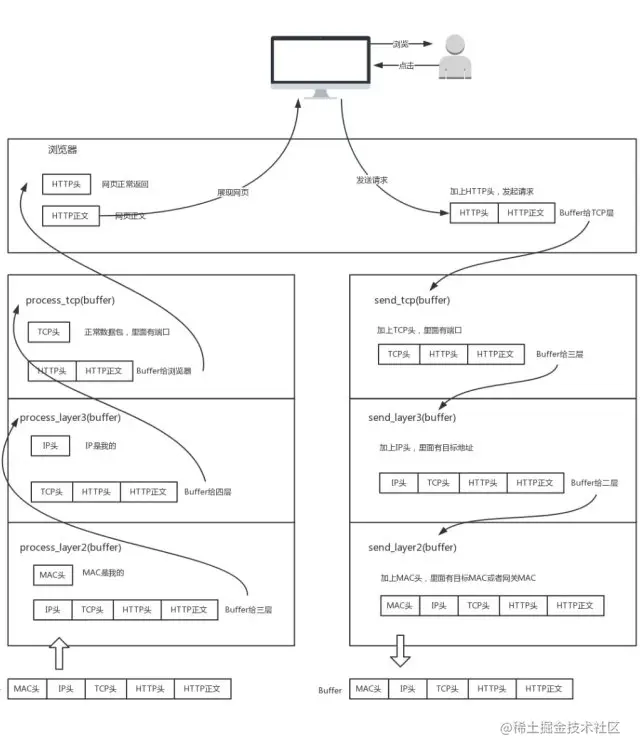
问的也就是HTTP 协议利用 TCP/IP 协议栈传输数据的过程。HTTP协议利用TCP/IP协议栈传输数据分为发送和接受。
- 发送过程:通过协议栈逐层向下,每一层都添加该层的专有头,逐层打包,由下层把数据发送出去。
-
- 浏览器显示了一个页面,你点击了一个链接,浏览器使用应用的端口号发起一个HTTP请求
- 然后加TCP头,记录了源端口号和目的端口号(一般是80)
- 然后加IP头,记录源IP地址和目标IP地址
- 然后加MAC头,记录下源MAC地址和目标MAC地址
- 然后就通过下层的网口发送出去了
- 接受过程:通过协议栈逐层向上,每一层都拆掉该层的专有头,逐层拆包,由上层接收本来的数据。
-
- 一个网口经过了一个网络包,把它拿进来交给网络包处理程序来处理
- 拆掉二层头,看看MAC地址跟自己的是不是相符,如果不相符,那不管它;如果MAC地址相符,继续拆三层头
- 拆掉三层头,看看IP地址跟自己的是不是相符,如果不相符,说明自己只是这个数据包的一个中转站,那我们把MAC地址更改,转发出去;如果IP地址相符,根据IP头里的标示知道四层是TCP地址还是UDP地址,我们假设是TCP的
- 拆掉四层头,看看这是个请求还是应答还是一个正常的数据包,如果是发起或应答那可能接下来要发一个回复包;如果是一个正常的数据包,就要交给上层来处理,网络包处理程序是不能拆七层头的,那么根据TCP头里的端口号交给对应的应用
- 应用拿到数据包想做什么处理就做什么处理,那就是应用的事了,比如说这个应用是浏览器,那浏览器当然是解析数据包(假设里面传送的是HTML),然后把页面显示出来
MAC地址的局限性和IP地址的连接性:因特网把各种网络连接起来,每个网络都使用不同的MAC地址,如果异构网络要互相通信就必须进行复杂的MAC地址转换工作,于是统一的IP地址把这个复杂问题解决了。IP地址本质上是终点地址,而MAC地址则是下一跳的地址,每跳过一次路由器都会改变。
5.DNS 协议
DNS(Domain Name System)域名系统
- 概念 :域名使用字符串来代替 IP 地址,方便用户记忆,本质上一个名字空间系统;最右边是顶级域名,然后是二级域名,最左边是主机名。
域名解析过程
- 像IP地址转换成MAC地址才能访问主机一样,域名也需要转换成IP地址,这就是域名解析。
假设在浏览器输入www.baidu.com会发生的DNS解析过程
- 首先浏览器搜索自己的DNS缓存,若有就直接用,
- 若没有,则搜索操作系统中的DNS缓存和hosts文件 ,若有就直接用,
- 若没有,则操作系统将域名发送至本地域名服务器(本地DNS) (一般是 移动/电信/联通 的某个机房内),本地DNS查询自己的DNS缓存,查找成功则返回结果,
- 若没有,本地DNS 就去询问根DNS ,根DNS 不直接用于域名解析,但会返回对应的顶级DNS 的地址(www.baidu.com就是**".com"顶级DNS**),
- 本地DNS 于是转向去问顶级DNS ,顶级DNS 如果能解析则返回对应的IP地址给本地DNS ,如果没有则会返回对应的权威DNS 给本地DNS (www.baidu.com就是**"baidu.com"权威DNS**)
- 本地DNS 于是转向去问权威DNS ,一般权威DNS 就会返回IP地址 给本地DNS 了,同时自己也将IP地址缓存起来
- 操作系统将 IP 地址返回给浏览器,同时自己也将IP地址缓存起来
- 浏览器得到域名对应的IP地址
HTTPDNS方案:为移动端量身定做的的基于 HTTP协议+域名解析 的流量调度方案(面试装逼用)
国内运营商的本地DNS存在一些问题使得用户造成访问异常,为此有了HTTPDNS作为为移动端量身定做的基于 HTTP协议和域名解析 的流量调度方案:
- 域名缓存问题:当本地DNS的缓存更新速度不及时且该域名已经指向其他IP了这就会导致用户访问异常。还有有的运营商会把静态页面缓存到自己的DNS服务器内加快访问速度,但是如果页面更新那用户只能访问到老页面。(HTTPDNS服务器可以自由掌控缓存更新速度)
- 域名转发问题:小运营商为了节约资源自己不做域名递归解析,转发给其他运营商来做,这就导致用户流量被导向了权威DNS专为其他运营商部署的服务器节点(IDC)上,用户的流量跨域、访问变慢。(HTTPDNS放弃DNS协议而是使用HTTP协议使得用户只需一次http请求即可完成域名解析)
- NAT问题:本地DNS在进行递归时由于网络上存在一些网关会做NAT(网络地址转换),权威DNS收到的域名解析请求源IP被修改,用户流量调度错误、访问变慢。(HTTPDNS服务器由于直接获取了用户的源IP所以可以实现精准的流量调度)
以上问题都可以被HTTPDNS方案解决,HTTPDNS服务器可以自由掌控缓存更新速度,HTTPDNS放弃DNS协议而是使用HTTP协议使得用户只需一次http请求即可完成域名解析,HTTPDNS服务器由于直接获取了用户的源IP所以可以实现精准的流量调度。
6.UDP协议
UDP 包头格式
UDP包头:源端口号、目标端口号、长度、校验和、数据。

UDP 的三大使用场景
- 需要资源少,在网络情况比较好的内网,或者对于丢包不敏感的应用。
- 第二,不需要一对一沟通,建立连接,而是可以广播的应用。
- 第三,需要处理速度快,时延低,可以容忍少数丢包,即便网络拥塞,UDP依然保持发送速度,而TCP的拥塞控制策略会降低发送速度,这使用户更卡。
- 实际使用场景:
-
- **网页或者 APP 的访问(HTTP3)QUIC协议(Quick UDP Internet Connections 快速 UDP 互联网连接)**是 Google 提出的基于 UDP 改进的通信协议,其目的是降低网络通信的延迟,提供更好的用户互动体验。
- 流媒体的协议(直播领域) :TCP 协议在网络不好时会主动降低发送速度,这对本来就卡的看直播来讲是是不能接受的,应该应用层马上重传,而不是主动让步。因而,很多直播应用,都基于 UDP 实现了自己的视频传输协议。
- 实时游戏(游戏领域) :在游戏中如果出现一个数据包丢失,客户端所有事情都需要停下来等待这个数据包重发,然而玩家并不那么关心过期的数据,团战中多卡一秒都可能会死。对实时要求较为严格的游戏,会采用自定义的可靠 UDP 协议,自定义重传策略,把丢包产生的延迟降到最低,尽量减少网络问题对游戏性造成的影响。
7.TCP协议
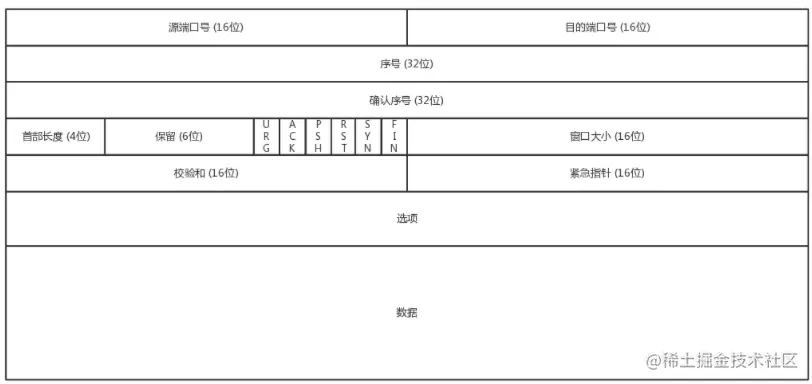
TCP 包头格式
TCP 包头:源端口号、目标端口号、序号seq、确认序号ack、首部长度、状态位、窗口大小rwnd、校验和、紧急指针、选项
- 确认序号ack:我想要收到的下一个序号
- 首部长度:就是TCP头的长度
- 保留:6位,没有意义,说不定以后的时代会将保留位更改为有意义的位置。
- 状态位
-
- 确认标志位ACK:置为1时表明连接状态,0时无效。连接建立后ACK必须置为1
- 同步标志位SYN:置为1表明是连接请求报文段,此时不能携带数据
- 终止标志位FIN:置为1时表明该主机要释放TCP连接
- 复位标志位RST:置为1时表明TCP连接出现异常,需要释放连接重新建立连接
- 推送标志位PSH:置为1时,接收方收到会将接受缓存中报文全部上交应用进程,不再等待接受缓存填满。
- 紧急标志位URG:置为1时紧急指针有效,0时无效。
- 窗口大小rwnd:接收方的接受窗口大小
- 校验和:用来检查TCP报文是否出现误码
- 紧急指针:表示数据中前n位为紧急数据,发送方会将紧急数据插在发送缓存的最前面立刻封装一个报文发送,接收方则会立刻将紧急数据上交应用进程
- 选项:最大40字节,可用来增加TCP功能
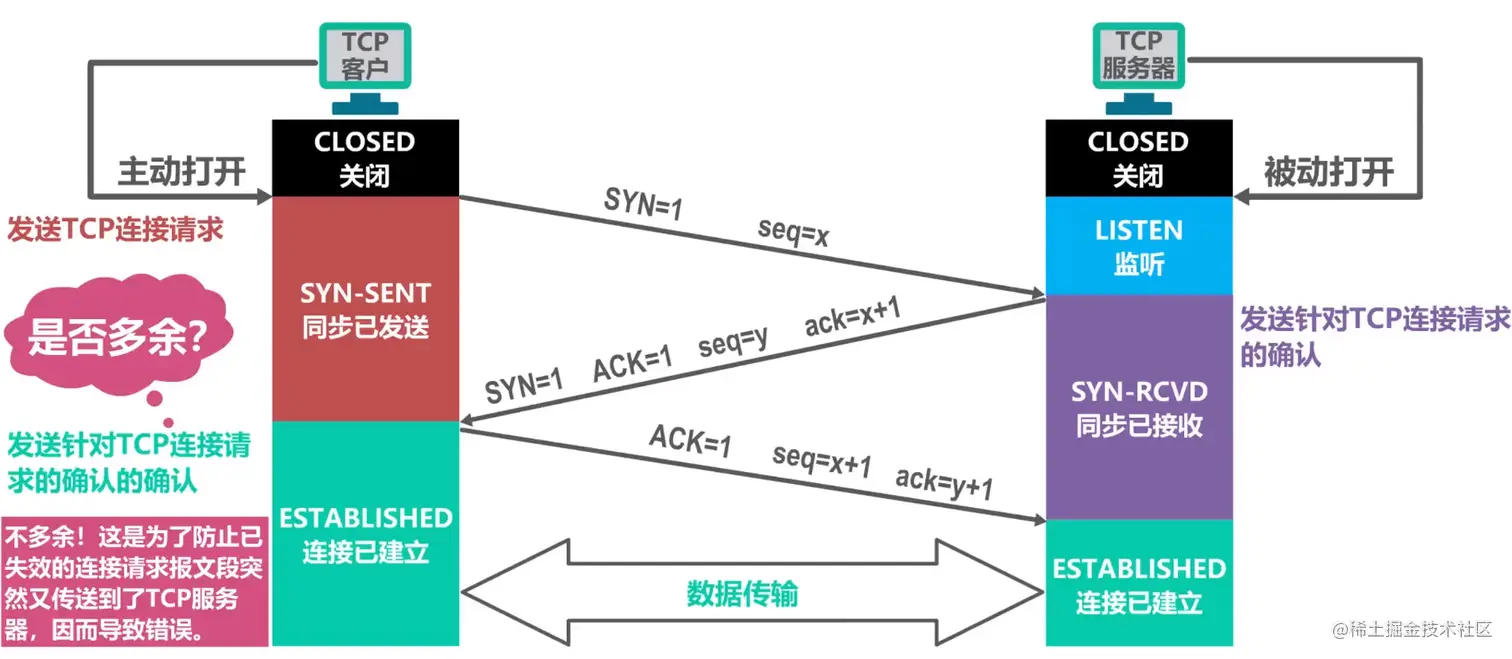
TCP连接建立
- 客户端和服务端一开始都处于 关闭 状态
- 服务端开始 监听 某个端口
- 客户端发送TCP连接请求报文段 ,客户端就进入 同步已发送 状态了(报文首部中 同步状态位SYN=1 序号seq=x)
- 服务器收到TCP连接请求报文段 后,发送TCP连接请求确认报文段 ,服务端就进入 同步已接收 状态了(报文首部中 同步状态位SYN=1 确认状态位ACK=1 序号seq=y 确认序号ack=x+1)
- 客户端收到TCP连接请求确认报文段 后,进入 连接已建立 状态,发送一个普通的TCP确认报文段(报文首部中确认状态位ACK=1 序号seq=x+1 确认序号ack=y+1)
- 客户端收到TCP确认报文段 后也进入连接已建立状态
- 为什么是三次握手?
-
- 正因为是三次握手,对于客户端和服务端来说他们都经历了至少一收一发,就确定对方可以收到自己的消息了,这就保证了两端都可以正常收发消息
- 如果是两次握手,不仅服务端不能确认对方能不能收到自己的消息,而且还可能导致释放连接后服务端又收到了失效的连接请求,就进入 连接已建立 状态无法退出,很耗资源。
- 如果是四次握手,那就造成了浪费,因为三次握手已经可以保证两端都可以正常收发消息了
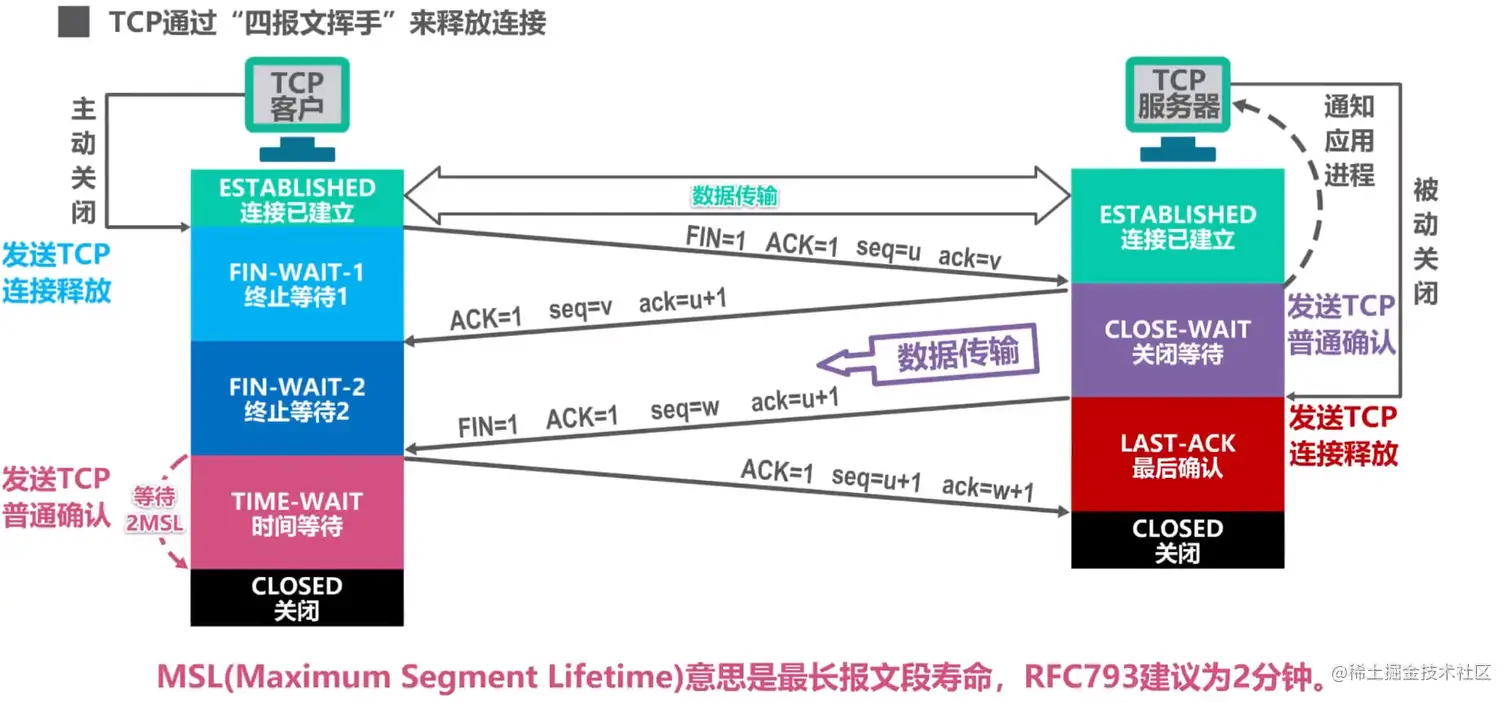
TCP连接释放
- 客户端和服务端都处于 连接已建立 状态
- 客户端发送TCP连接释放报文段 ,客户端进入 终止等待1 状态(报文首部 终止状态位FIN=1 确认状态位ACK=1 序号seq=u 确认序号ack=v)
- 服务端收到TCP连接释放报文段 ,发送一个普通确认报文段 ,服务端进入 关闭等待 状态(报文首部 确认状态位ACK=1 序号seq=v 确认序号ack=u+1,)
- 客户端收到普通确认报文段 后进入 终止等待2 状态,此时 客户端->服务端 这个方向的连接就释放了,但服务端仍然可以向客户端发送数据
- 服务端没有数据发送后,发送TCP连接释放报文段 ,服务端进入 最后确认 状态(报文首部 终止状态位FIN=1 确认状态位ACK=1 序号seq=w 确认序号ack=u+1)
- 客户端收到TCP连接释放报文段 后发送普通确认报文段 ,并进入2MSL时间的等待然后进入 关闭 状态(报文首部 确认状态位ACK=1 序号seq=u+1 确认序号ack=w+1)
- 服务端收到普通确认报文段 后进入关闭状态
- 第四次挥手为什么要等待2MSL?
-
- 保证服务端可以接收到最后一个普通确认报文段 从而关闭 ,否则如果客户端不等2MSL直接关闭 ,那么如果服务端没有收到普通确认报文段 就会一直重传TCP连接释放报文段 ,卡在最终确认 状态没法关闭了
- 2MSL时间可以使本次连接中产生的所有报文段都从网络中消失,这样就可以使下一个TCP连接中不会出现旧连接中的报文段
TCP的可靠性保证
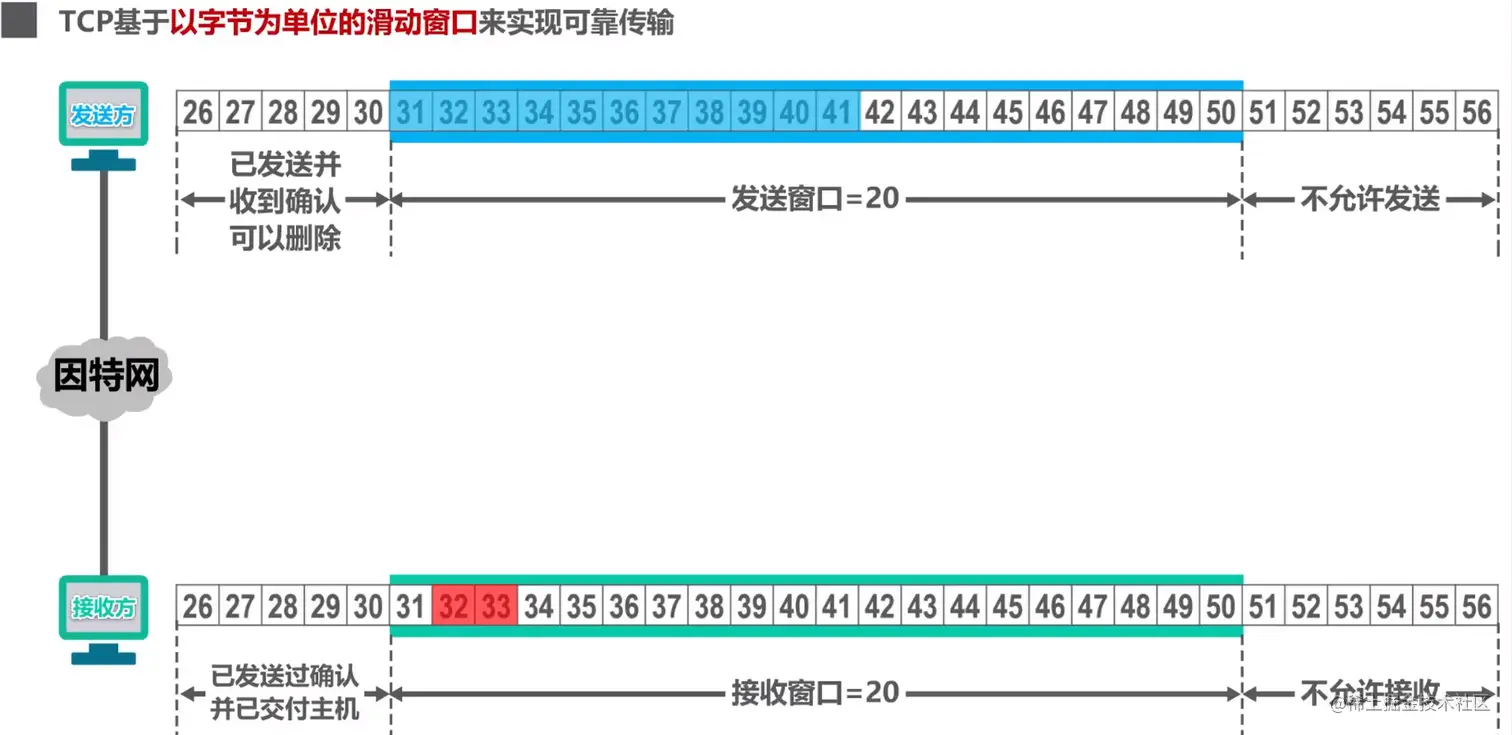
TCP基于以字节为单位的滑动窗口来实现可靠传输
- 待发送字节流分为4个部分:已发送已确认的部分、已发送未确认的部分、未发送可发送的部分、未发送不可发送的部分
发送窗口由第2第3部分组成,且会根据TCP确认报文段中的确认序号ack和窗口大小rwnd沿待发送字节流向后滑动
- 待接收字节流分为4个部分:已交付上层的部分、已接收未交付上层的部分、可接收的部分,不可接收的部分
接收窗口就是可接受部分,当接收方处理不过来的时候接收窗口就会减小,这就是流量控制
- 累计确认就是接收方表示确认序号ack之前的数据都已经接收
- 顺序问题:发生顺序问题时一般做法是在接收窗口中保留不按序到达的数据,等待缺失的字节收到后再按序交付上层
- 丢包问题
-
- 第一种解决方法是超时重传,发送窗口中已发送未确认的数据迟迟未确认就会触发超时重传,并重新启动重传计时器
- 第二种解决方法是快重传,接收方如果发现丢包了,那就发送3个重复的确认报文段,发送方收到后立马重传对应的数据包
- 第三种解决方法是SACK选项,接收方在确认报文段中会报告最近接收的不连续的数据块,那发送方就会重传丢的包
- 流量控制:就是让发送方的发送速度不能太快,让接收方来得及接收,这是利用滑动窗口机制实现的。缓存区域存放的都是基于字节流的数据,当接收方处理不过来的时候就要减小接收窗口的大小,甚至设置为0。接收窗口不为0后,接收方会发一个报文通知发送方,为防止死锁,发送方也会启用一个定时器,每隔一段时间确认一遍接收窗口的大小是否改变。
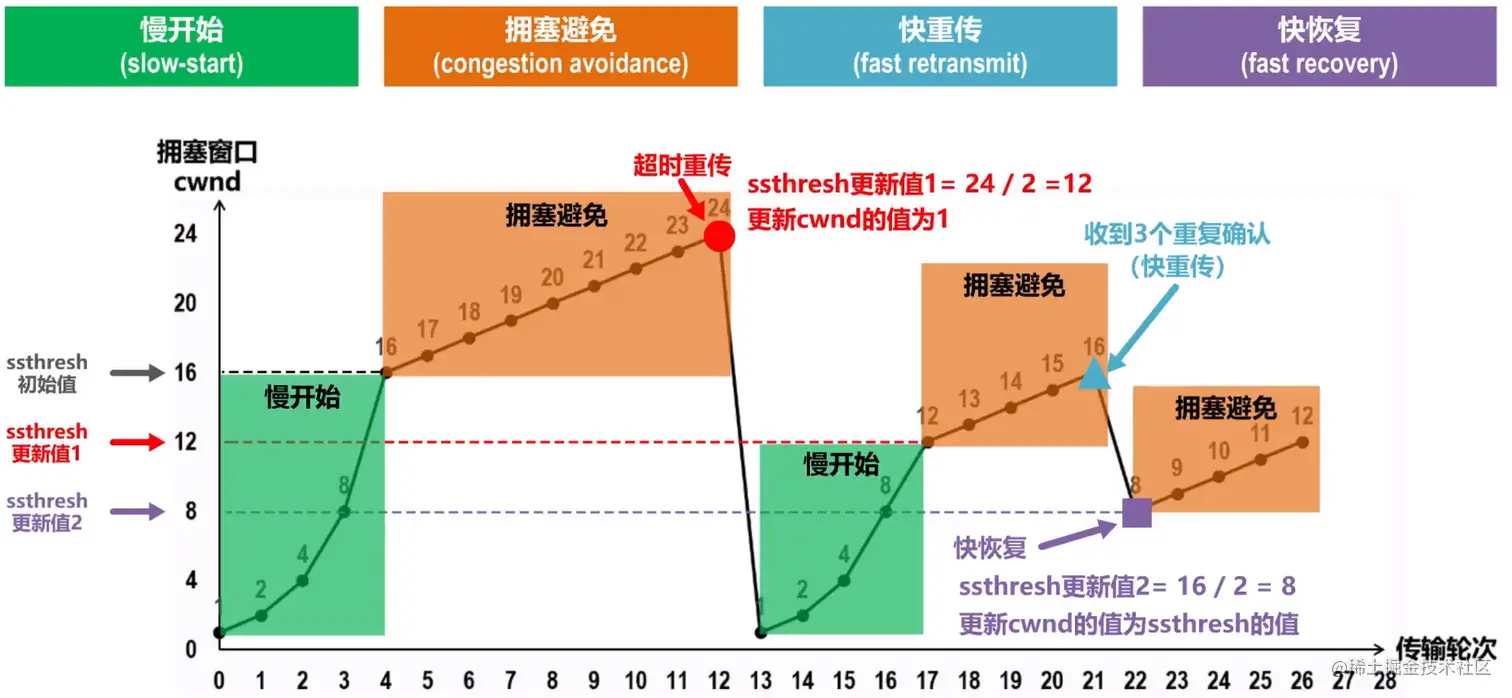
- 拥塞控制 :如果网络非常拥堵,此时再发送的报文段超过了最大生存时间也到达不了接收方,就会产生丢包问题。为此TCP协议引入了慢开始、拥塞避免、快重传、快恢复这四种拥塞控制算法。
-
- 当拥塞窗口cwnd小于慢开始门限ssthresh时,采用慢开始 算法,即发送方每收到一个对新报文段的确认就将拥塞窗口+1,相当于每一传输轮次若没出现拥塞则将拥塞窗口大小扩大为两倍**;当拥塞窗口cwnd大于慢开始门限ssthresh时,采用 拥塞避免算法,每一传输轮次若没出现拥塞则将拥塞窗口+1 ;当发生 拥塞即超时重传**时,将慢开始门限更新为拥塞窗口的一半,并将拥塞窗口减小为1重新开始执行满开始算法。
- 个别报文段的丢失不代表网络发生了拥塞,没必要将拥塞窗口减为1降低传输效率,所以当发生个别报文段的丢失时采用快重传 算法和 快恢复 算法,当接收方收到失序的报文段时不等累计确认立刻发送确认报文段,当发送方收到三个重复的确认报文段时立刻重发该报文段,之后就不会触发该报文段的超时重传,同时发送方将慢开始门限和拥塞窗口更新为拥塞窗口的一半。
8.TCP 和 UDP 有哪些区别?
- TCP 是面向连接的,UDP 是面向无连接的。
- 在互通之前,面向连接的协议会先建立连接。例如,TCP 会三次握手,而 UDP 不会。所谓的建立连接,是为了在客户端和服务端维护连接,而建立一定的数据结构来维护双方交互的状态,用这样的数据结构来保证所谓的面向连接的特性。
- 例如,TCP 提供可靠交付 。通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达。我们都知道 IP 包是没有任何可靠性保证的,一旦发出去,就像西天取经,走丢了、被妖怪吃了,都只能随它去。但是 TCP 号称能做到那个连接维护的程序做的事情,这个下两节我会详细描述。而UDP 继承了 IP 包的特性,不保证不丢失,不保证按顺序到达。
- 再如,TCP 是面向字节流的 。发送的时候发的是一个流,没头没尾。IP 包可不是一个流,而是一个个的 IP 包。之所以变成了流,这也是 TCP 自己的状态维护做的事情。而UDP 继承了 IP 的特性,基于数据报的,一个一个地发,一个一个地收。
- 还有TCP 是可以有拥塞控制的 。它意识到包丢弃了或者网络的环境不好了,就会根据情况调整自己的行为,看看是不是发快了,要不要发慢点。UDP 就不会,应用让我发,我就发,管它洪水滔天。
- 因而TCP 其实是一个有状态服务 ,错一点儿都不行。而 UDP 则是无状态服务,发出去就发出去了。
9.HTTP协议基础
HTTP协议简述
- 概念 :HTTP 就是超文本传输协议 ,也就是H yperT ext T ransfer P rotocol,可以把它拆成三部分理解"超文本 ""传输 "和"协议"。
-
- 超文本:是文字、图片、音频和视频的混合体,并拥有"超链接",能够从一个"超文本"跳跃到另一个"超文本",形成网状的结构关系。
- 传输 :意思是两点之间传输数据。
- 协议 :意思是对行为的约定和规范。
- 综合来看HTTP 是一个对两点之间传输超文本数据的约定和规范。
HTTP报文
- "起始行 + 头部 + 空行 + 实体"
- 起始行(start line):请求行或是状态行
-
- 请求行格式:"请求方法 目标URI 协议版本号"
- 状态行格式:"协议版本号 状态码 原因"
- 头部(header):使用 key-value 详细说明报文;
- 消息体(entity):实际传输的数据
- HTTP 报文必须有 起始行和头部,在 header 之后必须要有一个 空行,可以没有 消息体
请求方法与幂等性
-
GET 方法的含义是请求从服务器获取指定的URI 资源,可以搭配其他 头部 字段 实现对资源更精细的操作。
vbnet
复制代码GET /10-1 HTTP/1.1
Host: www.chrono.com -
POST方法的含义是向指定的URI 资源提交数据,数据就放在报文的 body 里。
makefile
复制代码POST /10-2 HTTP/1.1
Host: www.chrono.com
Content-Length: 17POST DATA IS HERE
-
幂等意思是多次执行相同的操作后结果是相同的,GET和HEAD这种只读显然幂等,DELETE多次删除同个资源结果都是资源不存在,PUT多次修改同一个资源显然也幂等,但POST每次都提交新数据就不幂等了。联系到SQL中,POST就像insert,PUT就像update。
安全是指请求方法不会对服务器上的资源造成修改。
POST和GET的区别:
- POST和GET的本质都是 TCP 链接,并无区别。但是由于 HTTP 的规定以及浏览器/服务器的限制,导致它们在应用过程中可能会有所不同。具体的有
-
- GET 用于获取资源,无副作用、安全且幂等,会被浏览器主动缓存;
POST 用于修改服务器上的资源,有副作用、不安全不幂等,除非手动设置否则不会被浏览器主动缓存
-
- GET的参数直接暴露在URL上,POST的参数放在消息体里不会暴露,但HTTP本身在网络上是明文传输的,所以GET和POST都不安全,除非用HTTPS。
- GET的参数数据类型必须是ASCII码字符,POST没有限制。
- 一个很有意思的事情是国外一篇博客说Ruby的net::HTTP库在使用POST方法时会 先将请求头和消息体分两个TCP数据包发送,我自己测试了我主机上的各个浏览器包括postman都没有看到这个现象,所以这应该是很少见的现象(这很好验证,我们写一个服务端,封装简单的HTTP处理方法,然后我们用浏览器或postman发一个post请求,然后抓包看一下就可以)。
- 虽然HTTP本身不限制URL的长度,但因为长url处理起来很耗资源所以浏览器和服务器为了性能和安全考虑(避免长url攻击)对 url 的长度有限制,所以 GET请求在URL中传送的参数是有长度限制的,而POST请求没有(一样可以验证一下HTTP不限制URL的长度,我们写个服务端让它在接收到请求时打印报文,然后用postman发送超过2k个字符的get请求,可以看到打印出来的url长度多少都没问题)。
URI和响应状态码
- 1xx:指示信息--表示请求已接收,继续处理
100 ------客户端必须继续发出请求;101------客户端要求服务器转换 HTTP 协议版本。
- 2xx:成功--表示请求已被成功接收、理解、接受
200------OK 204--请求收到,但返回信息为空;206------服务器已经完成了部分用户的 GET 请求
- 3xx:重定向--信息不完整需要进一步补充
300------请求资源在多处可得到。301------永久重定向,隐式重定向。302 临时重定向,显示重定向。304------请求的资源没有改变,可以使用缓存。
- 4xx:客户端错误--请求有语法错误或请求无法实现
401------未授权;403------禁止访问。 404------找不到;409------对当前资源状态,请求不能完成
- 5xx:服务器端错误--服务器未能实现合法的请求
500 内部服务器错误,501 未实现, 502 网关错误,503 服务不可用,504 网关超时。
cookie和session
由于HTTP协议是无状态的协议,需要用某种机制来识具体的用户身份,用来跟踪用户的整个会话。常用的会话跟踪技术是cookie与session。
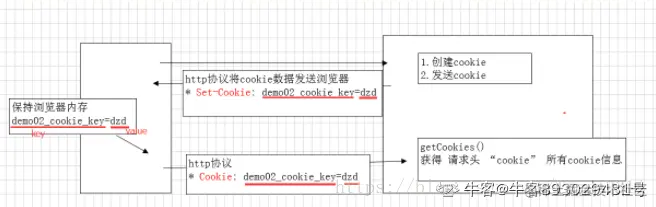
- Cookie是一种通过在客户端记录信息确定用户身份的会话追踪技术
cookie的工作流程是
-
- 当浏览器访问一个支持cookie的网站时,浏览器会把个人信息提交至服务端;
- 然后服务端创建并保存对应的cookie并在响应请求时发回set-cookie,set-cookie放在响应报文的header中
- 浏览器收到响应之后将set-cookie保存
- 下次访问时浏览器将自动携带cookie发送至服务端,服务端通过cookie就能够知道用户的信息,从而动态生成相对应的内容。
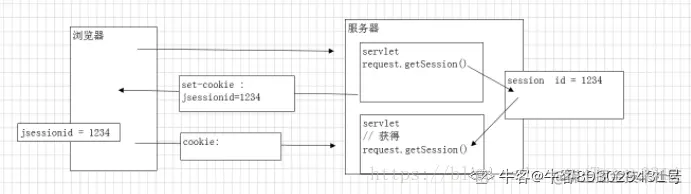
- session是一种通过在服务器端记录信息确定用户身份的会话追踪技术。
session的工作流程是
-
- 当客户端请求服务端时,服务端首先检查请求报文是否包含sessionid,如果包含则说明服务端已经为这个客户端创建过session,服务端就将对应的session检索出来使用
- 如果请求报文不包含sessionid,服务端就为这个客户端创建一个session,并且生成一个对应的sessionid存放到set-cookie中在本次响应中返回到客户端保存。
- 之后客户端每次请求都会带着sessionid,服务器根据sessionid就可以找到对应的session,从而知道用户的信息,动态生成相对应的内容。
cookie和session的区别?
- 存储位置不同,cookie数据存储在客户端,session数据存储在服务端;
- 隐私策略不同 ,cookie数据存储在客户端,所以对客户端可见,有信息泄露的风险,敏感信息最好不存放在cookie中,cookie也可以像google、baidu那样做一个加密,在服务端解密;而session数据存放在服务端,对客户端不可见,但是sessionid通过cookie存储,所以客户端仅能 看见sessionid
- 存取类型不同,Cookie中只能保管ASCII码字符串,若要存储略微复杂的信息非常麻烦;而Session能够存储任何类型的数据,String、Integer、List、Map,也能够直接保管任何Java类和对象,使用起来十分方便。
- 有效期不同,cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,session 一般失效时间较短,客户端关闭或者 session 超时都会失效。
- 浏览器支持的不同,Cookie是需要客户端浏览器支持的,如果客户端禁用了Cookie或者不支持Cookie,cookie就不能用了;但sessoin不会,虽然session更常见的实现是通过cookie传递sessionid的,但也可以在配置过后通过url传递sessionid
HTTP中请求应答过程(请求响应模型)
- 浏览器:浏览器本质上是一个 HTTP 协议中的请求方
- 服务器(Web server)
-
- 硬件含义就是物理形式或"云"形式的机器,在大多数情况下它可能不是一台服务器,而是利用反向代理、负载均衡等技术组成的庞大集群
- 软件含义的 Web 服务器就是提供 Web 服务的应用程序,通常会运行在硬件含义的服务器上。它利用强大的硬件能力响应海量的客户端 HTTP 请求,处理磁盘上的网页、图片等静态文件,或者把请求转发给后面的 Tomcat、Node.js 等业务应用,返回动态的信息。如Nignx,Tomcat,Jetty等
- 所谓的后端开发也是服务端开发
10.HTTPS
- HTTPS概念 :英文名是HTTP over SSL/TLS ,HTTPS 的语法、语义仍然是 HTTP,但在 HTTP 下层的五层会话层换成了 SSL/TLS,默认端口从80 调整为443。
SSL/TLS:SSL 即Secure Sockets Layer(安全套接层),由网景公司1994年开发的安全协议,处于OSI五层(会话层),TLS·即Transport Layer Security(传输层安全),它是SSL的3.1版本。
- 通信安全需要的四个必要特性
-
- **机密性(混合加密(对称+非对称)解决)**是指对数据的"保密",只能由可信的人访问,对其他人是不可见的秘密,HTTP没有机密性所以wireshark抓包之后能清楚的看到传输的数据。
-
-
- 对称加密 是指加密解密使用同一把密钥,是"对称"的,只要保证了密钥的安全,那整个通信过程就可以说具有了机密性 ,常用的对称加密算法有AES和CHACHA20。
- 非对称加密 是指使用"公钥 "加密、"私钥 "解密的加密方式,公钥的信任需要通过CA颁发的证书进行认证 ,接收方拥有自己的私有密钥,不需要通过传输获得。比较著名的非对称加密算法是基于"整数分解"问题的RSA 算法,使用两个超大素数的乘积作为生成密钥的材料,想要从公钥推算出私钥非常困难 ;还有基于"椭圆曲线离散对数"问题的ECC 算法,使用特定的曲线方程和基点生成密钥,其子 算法ECDHE用于密钥交换,ECDSA用于数字签名。
- 混合加密是指混合使用对称加密和非对称加密的加密方式,之所以需要混合加密是因为非对称加密虽然安全但太慢了,在交换对称加密密钥阶段使用非对称加密,交换报文阶段使用对称加密。
-
-
- **完整性(摘要算法解决)**是指数据在传输过程中没有被修改。
**摘要算法**是指通过哈希函数将数据转换为固定长度的字符串,所以数据要配合摘要一起发送,为了防止数据和摘要一起被黑客修改,要保证机密性,使用密钥加密数据和摘要。
-
- **身份认证(数字签名解决)**是指保证消息只能发送给可信的人。
- **不可否认(数字签名解决)**是指不能否认已经发生过的行为。
数字签名使用非对称加密,但是是使用私钥加密,公钥解密,考虑非对称加密效率低,我们仅加密摘要,拿到数字签名后对比原文验证即可知道对方身份是否可信。
11.HTTP2
- 二进制格式:HTTP1的解析是基于文本格式的,HTTP2的解析是基于二进制格式的,效率更高。
- 帧与双向数据流 :同时HTTP2引入帧和流 的概念;帧就是HTTP2通信的最小消息单位,报文被分割为多个帧;**"流概念"**是存在于连接中的双向的虚拟通道,帧可以在拥有整数标识的流上进行双向传输,一个连接可以承载任意数量的流,所以多个帧之间可以乱序发送,根据帧首部的流标识重新组装。
- 多路复用 :HTTP1想要并发多个请求只能起多个TCP连接,而且浏览器对单个域名还有TCP连接数量的限制,HTTP2拥有流和帧后单个连接上就可以并发进行多个请求和响应,避免了HTTP1中的队头阻塞问题,极大地提升了性能。
- 头部压缩 :HTTP1的头字段太长了,而且每次都重复发送,非常浪费带宽,HTTP2使用特别的算法在客户端和服务端建立字典记录之前发送的键值对,这样就能用索引号代替重复字符串,压缩效率极高。
- 服务端推送:HTTP1中服务端需要等待客户端请求才能被动响应,而HTTP2.0是允许服务端向客户端主动推送的。
12.HTTP3
- 相比HTTP2的优化 :HTTP2使用流和帧 的概念实现了多路复用 ,但这只是在应用层的优化,并未完全解决队头阻塞问题,在TCP连接中一旦发生丢包就会阻塞住后续所有请求。因此,HTTP3将传输层的TCP协议换为了UDP协议,并引入QUIC协议使UDP实现了类似TCP的可靠传输,如果某个流丢包只会阻塞这个流而不会阻塞其他流。
- QUIC 内含了 TLS1.3,只能加密通信,支持 0-RTT 快速建连;
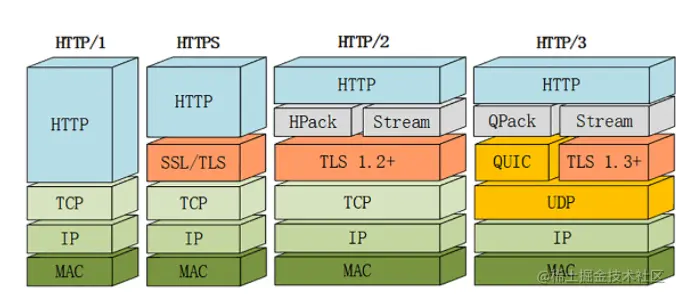
13.Nginx
- 概念 :Nginx 是一款高性能的轻量级 Web服务器,它消耗的 CPU、内存很少。主要提供反向代理、负载均衡、动静分离(静态资源服务)等服务。
- Nginx采用"进程池 + 单线程"的工作方式,消除了进程、线程切换的成本。
- Nginx 基于 Linux内核的IO多路复用接口--epoll 实现了"I/O 多路复用" ,不会阻塞,性能很高;
- Nginx 使用了"职责链"模式,多个模块分工合作,自由组合,流水线处理 HTTP 请求。
14.CDN(Content Delivery Network内容分发网络)
IDC是基础,纯物理硬件服务器服务;云平台是IDC基础上进行升级,服务器功能上再附加更多的综合服务;而CDN是基于IDC或者云平台的一种组网模式,通过分布于各地的缓存服务器,达到最快访问资源的目的。
- 概念:由于客观地理距离的存在,直连网站访问速度会很慢,所以 CDN 构建了全国乃至全球级别的专网,网站使用了CDN服务后,用户再访问对应的域名则可以通过CDN将流量智能调度到就近的边缘节点,访问速度加快。
- CDN的两个关键组成:全局负载均衡(GSLB) 和 缓存系统
-
- 全局负载均衡:在没加入CDN服务时,权威DNS返回网站自己的IP地址,加入之后,权威DNS就会返回CDN的GSLB,本地DNS再去访问GSLB就会得到GSLB智能调度的最佳边缘节点。用户因此得以访问就近的CDN缓存代理。
- 缓存系统:缓存系统存储了网站具体的内容,一般是静态资源,缓存命中则返回给用户,未命中则要回源,通过CDN的路径优化速度即使回源的速度也很快。
15.HTTP长连接和短连接
HTTP1.0默认使用的是短连接:浏览器和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。
HTTP/1.1起,默认使用长连接 :要使用长连接,客户端和服务器的HTTP首部的Connection都要设置为keep-alive,才能支持长连接。
HTTP长连接,指的是复用TCP连接。多个HTTP请求可以复用同一个TCP连接,这就节省了TCP连接建立和断开的消耗。