
欢迎了解公众号:AI论文解读
背景:探索RankRAG的创新之处
检索增强生成(Retrieval-Augmented Generation, RAG)技术已成为提升大型语言模型(Large Language Models, LLMs)处理知识密集型任务的关键方法。传统的RAG系统通常依赖于独立的检索和排名模型来从大规模文档集中提取相关信息,然后由语言模型生成答案。然而,这种方法存在一定的局限性,如检索器的容量限制和顶层上下文的选择权衡,这些问题可能导致信息的遗漏或引入不相关的内容,从而影响生成的准确性。
为了克服这些挑战,本文提出了一个全新的框架------RankRAG。RankRAG的核心创新在于它通过指令微调(instruction-tuning)单一的LLM,使其同时具备上下文排名和答案生成的双重功能。这种设计不仅简化了传统RAG系统中多模型的复杂性,还通过共享模型参数增强了上下文的相关性判断和信息的利用效率。
具体来说,RankRAG在训练阶段引入了少量的排名数据,并通过特定的任务设计,如问答对的相关性判断,有效地训练模型识别和排列相关上下文。这种方法在实验中显示出惊人的效果,即使是与使用大量排名数据单独微调的模型相比,RankRAG也展现了更优的性能。此外,RankRAG在多个知识密集型基准测试中均显著超越了现有的最先进模型,包括在生物医学领域的RAG基准测试中,无需特定领域数据的指令微调,也能展现出卓越的泛化能力。
通过这些创新,RankRAG不仅提升了信息检索的准确性和生成内容的质量,还为未来的RAG系统研究和应用提供了新的方向。这标志着我们在构建更智能、更高效的语言处理系统方面迈出了重要的一步。
论文基本信息
- 论文标题: RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
- 作者: Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, Bryan Catanzaro
- 机构 : Georgia Tech, NVIDIA论文链接:https://arxiv.org/pdf/2407.02485.pdf

ChatQA-1.5是最强的RAG模型之一,在不同上下文大小k上的性能。我们观察到选择top-k上下文的权衡:较小的k会影响召回,而较大的k可能会引入不相关或嘈杂的上下文,并误导LLM生成。
RankRAG方法介绍
RankRAG是一种新型的指令微调框架,旨在通过单一的大型语言模型(LLM)同时处理上下文排名和答案生成,以增强其在检索增强生成(RAG)任务中的性能。这种方法特别适用于处理知识密集型的自然语言处理任务。
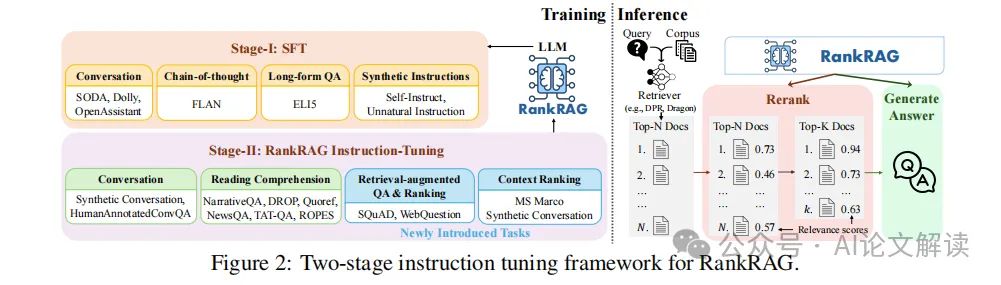
1. 指令微调的双重目的
RankRAG的核心在于它的双重功能:上下文排名和答案生成。这种设计基于这样的假设:上下文的相关性判断和利用相关上下文生成答案的能力是相辅相成的。通过在训练阶段同时对这两种能力进行指令微调,RankRAG能够在实际应用中更有效地筛选和利用相关上下文。
2. 训练阶段的设计
RankRAG的训练包括两个阶段:首先是基于多种高质量指令遵循数据集的监着学习微调(SFT),其次是统一的指令微调,用于同时增强排名和生成能力。这种两阶段训练策略不仅提高了模型对指令的遵循能力,还特别针对RAG任务优化了模型性能。
3. 推理阶段的流程
在推理阶段,RankRAG采用了修改后的检索-重排-生成流程。首先,使用检索器从文档集中检索出顶部N个上下文,然后RankRAG模型重新排序这些上下文,只保留得分最高的k个上下文,最后,这些上下文被用作生成答案的输入。

实验设计与数据集
1. 实验设置
在实验中,我们考虑了三种类型的任务:开放域问答(OpenQA)、事实验证和对话式问答(ConvQA)。这些任务涵盖了从单跳问答到多跳问答的不同复杂性。我们使用了多个公开的数据集,包括NQ、TriviaQA、HotpotQA、FEVER等,以及一些对话式问答数据集如Doc2Dial和TopiOCQA。
2. 基线模型
为了全面评估RankRAG的性能,我们将其与多个基线模型进行了比较,包括没有使用RAG的LLM(如InstructGPT和PaLM 2)以及使用了检索增强的模型(如Atlas和Raven)。此外,我们还考察了使用不同检索器的RankRAG性能,以展示其在不同设置下的鲁棒性。
3. 评估指标
我们使用准确率(Accuracy)、精确匹配(Exact Match)和F1分数作为主要评估指标,这些指标能够全面反映模型在不同任务上的性能。
4. 实施细节
实验中使用的LLM基于Meta-AI的Llama3模型,我们在两个不同的规模**(8B和70B)上进行了实验。模型的训练采用Adam优化器**,具体的学习率和批次大小设置根据模型规模和训练阶段的不同而有所调整。
通过这些细致的实验设计,我们能够深入了解RankRAG在多种知识密集型NLP任务上的表现,并与现有的RAG模型进行了全面的比较。
主要实验结果与分析
1. 实验设置与基线模型
在实验中,我们使用了多种基线模型进行比较,包括不使用检索增强的大型语言模型(如InstructGPT和PaLM 2)以及使用检索增强的模型(如Atlas和Raven)。实验涵盖了开放领域问答(OpenQA)、事实验证和对话式问答(ConvQA)等多种任务。我们使用精确匹配(EM)、准确率和F1分数等评价指标来衡量模型性能。
2. 实验结果
RankRAG在多个知识密集型基准测试中表现出色。在OpenQA任务中,RankRAG的表现通常优于所有基线模型,尤其是在TriviaQA和HotpotQA数据集上,其性能显著优于Llama3-ChatQA-1.5和其他基线模型。此外,RankRAG在没有特定领域微调的情况下,在生物医学领域的RAG基准测试中也显示出良好的性能,几乎可以匹敌GPT-4模型。
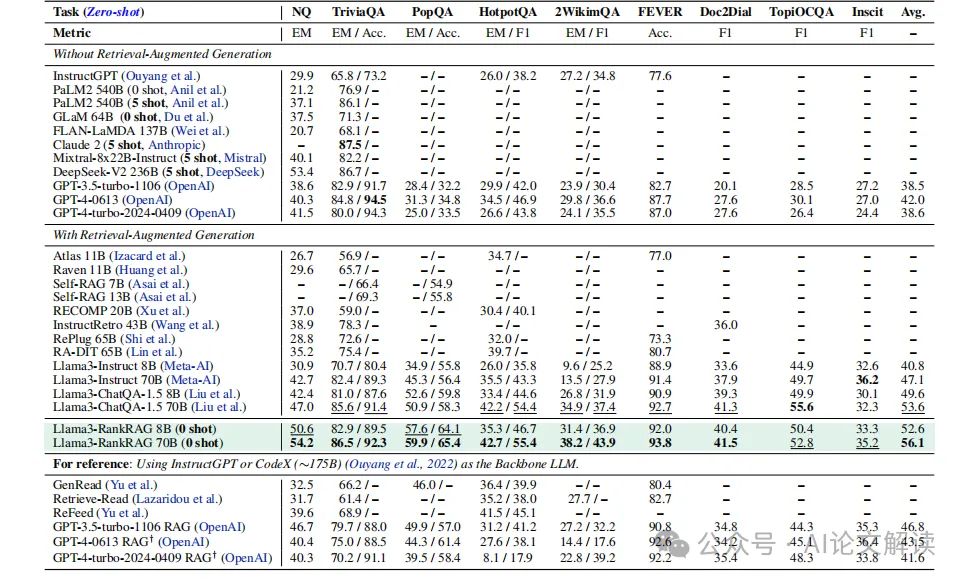
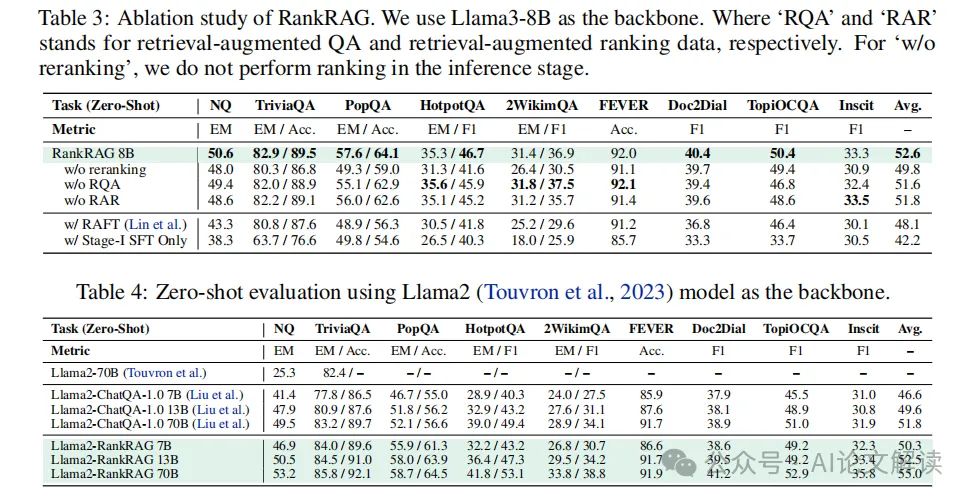
3. 讨论
实验结果表明,RankRAG通过在检索和生成阶段同时进行指令微调,有效提升了信息检索的质量和答案生成的准确性。此外,RankRAG在处理不同类型的问答任务时展现出的灵活性和鲁棒性,进一步验证了其作为一个统一的RAG框架的有效性。
讨论RankRAG的优势
1. 统一的指令微调框架
RankRAG通过一个统一的指令微调框架,同时处理上下文排名和答案生成,这一设计简化了训练流程并提高了模型的通用性。与传统的RAG模型相比,RankRAG无需依赖于独立的排名模型,从而减少了模型复杂性和运行时开销。
2. 数据效率
RankRAG在训练中引入少量的排名数据即可实现显著的性能提升。这种数据效率高的特性使得RankRAG在资源受限的情况下仍能保持良好的性能,同时也降低了训练成本。
3. 高性能
在多个知识密集型任务和领域中,RankRAG均展现出优于现有RAG模型的性能。特别是在需要处理大量不相关信息的开放领域问答任务中,RankRAG通过有效的上下文排名显著提高了答案的准确性和相关性。
4. 跨领域适应能力
RankRAG在未经领域特定训练的情况下,在生物医学领域的表现接近专门为该领域训练的模型。这一点证明了RankRAG极佳的泛化能力和跨领域适应性,为未来在更多专业领域的应用提供了可能。
综上所述,RankRAG通过其创新的统一指令微调框架,在多个方面超越了现有的RAG模型,展现了卓越的性能和广泛的应用潜力。