《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,全书共分10章,第1章主要让读者认识数据资产,了解数据资产相关的基础概念,以及数据资产的发展情况。第2~8章主要介绍大数据时代数据资产管理所涉及的核心技术,内容包括元数据的采集与存储、数据血缘、数据质量、数据监控与告警、数据服务、数据权限与安全、数据资产管理架构等。第9~10章主要从实战的角度介绍数据资产管理技术的应用实践,包括如何对元数据进行管理以发挥出数据资产的更大潜力,以及如何对数据进行建模以挖掘出数据中更大的价值。
图书介绍:数据资产管理核心技术与应用
今天主要是给大家分享一下第二章的内容:
第二章的标题为元数据的采集与存储
主要是介绍了如何从Apache Hive、Delta lake、Apache Hudi、Apache Iceberg、Mysql 等常见的数据仓库、数据胡以及关系型数据库中采集获取元数据。、
1、Hive的元数据采集方式:
1.1、基于Hive Meta DB的元数据采集
由于Hive在部署时,是将数据单独存储在指定的数据库中的,所以从技术实现上来说肯定是可以直接通过从Hive元数据存储的的数据库中获取到需要的元数据信息。Hive通常是将元数据存储在单独的数据库中,可以在部署时由用户自己来指定存储在哪种数据库上,通常可以支持存储在MySQL、SQLServer、Derby 、Postgres、Oracle等数据库中。Hive元数据数据库中常见的关键表之间的关联关系如下图,根据下图的关联关系,我们就可以用SQL语句查询到需要的元数据的数据信息。
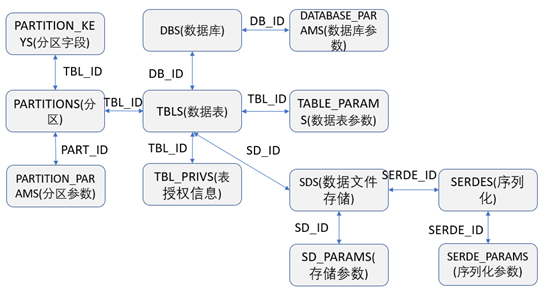
相关表的介绍如下:
DBS:存储着Hive中数据库的相关基础信息
DATABASE_PARAMS:存储着Hive中数据库参数的相关信息
TBLS:存储着Hive中数据库的数据表的相关基础信息
COLUMNS_V2:存储着数据表的字段信息
TABLE_PARAMS:存储着Hive中数据库的数据表参数或者属性的相关基础信息
TBL_PRIVS:存储着表或者视图的授权信息
SERDES:存储着数据序列化的相关配置信息
SERDE_PARAMS:存储着数据序列化的属性或者参数信息
SDS:存储着数据表的数据文件存储的相关信息
SD_PARAMS:存储着数据表的存储相关属性或者参数信息
PARTITIONS:存储着数据表的分区相关信息
PARTITION_KEYS:存储着数据表的分区字段信息
PARTITION_PARAMS:存储分区的属性或者参数信息
1.2、基于Hive Catalog的元数据采集
Hive Catalog 是Hive提供的一个重要的组件,专门用于元数据的管理,管理着所有Hive库表的结构、存储位置、分区等相关信息,同时Hive Catalog提供了RESTful API或者Client 包供用户来查询或者修改元数据信息,其底层核心的Jar包为hive-standalone-metastore.jar。在该Jar包中的org.apache.hadoop.hive.metastore.IMetaStoreClient.java 接口中定义了对Hive元数据的管理的抽象,详细代码实现可以参考纸质书。
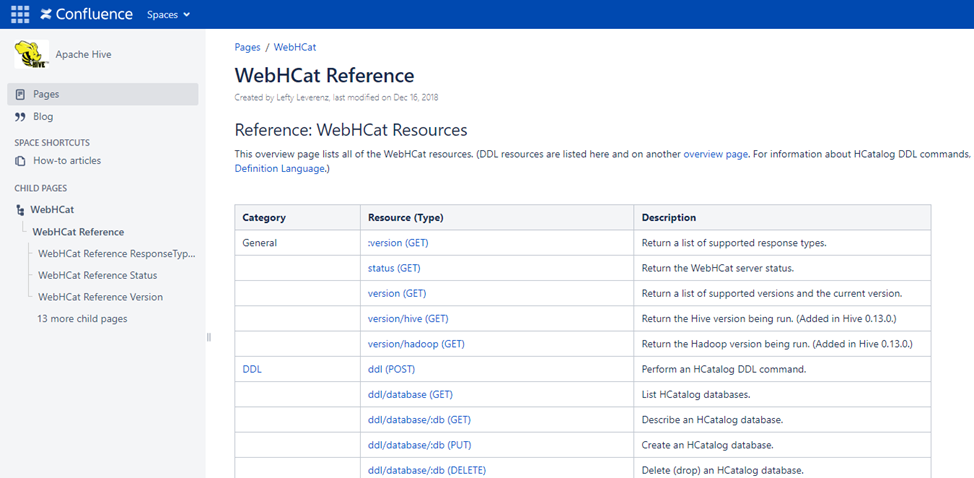
在Hive2.2.0版本之前Hive还提供了以Hcatalog REST API的形式对外可以访问Hive Catalog(Hive2.2.0版本后,已经移除了Hcatalog REST API这个功能),REST API 访问地址的格式为:http://yourserver/templeton/v1/resource,在Hive的Wiki网站:WebHCat Reference - Apache Hive - Apache Software Foundation中有详细列出REST API 支持哪些接口访问,如下图
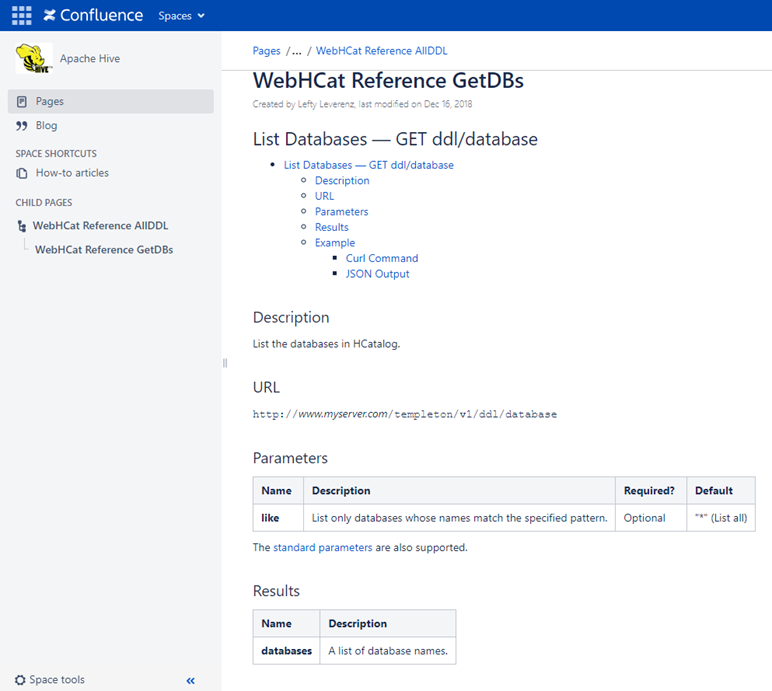
比如通过调用REST API 接口:http://yourserver/templeton/v1/ddl/database 便可以获取到Catalog中所有的数据库的信息,如下图
1.2、基于Spark Catalog的元数据采集
Spark 是一个基于分布式的大数据计算框架。Spark 和Hadoop的最大的不同是,Spark的数据主要是基于内存计算,所以Spark的计算性能远远高于Hadoop,深受大数据开发者的喜欢,Spark提供了 Java、Scala、Python 和 R 等多种开发语言的 API。
Spark Catalog是Spark提供的一个元数据管理组件,专门用于Spark对元数据的读取和存储管理,管理着Spark 支持的所有数据源的元数据,Spark Catalog支持的数据源包括HDFS、Hive、JDBC等,Spark Catalog将外部数据源中的数据表映射为Spark中的表,所以通过Spark Catalog 也可以采集到我们需要的元数据信息。
自Spark3.0版本起,引入了Catalog Plugin,虽然org.apache.spark.sql.catalog.Catalog 提供了一些常见的元数据的查询和操作,但是并不够全面、强大以及灵活,比如无法支持多个Catalog等,所以 Catalog Plugin是Spark为了解决这些问题而应运而生的。
详细代码实现可以参考纸质书。
2、Delta Lake 中的元数据采集
提到Delta Lake 就不得提数据湖这个概念了,Delta Lake 是数据湖的一种。数据湖是相对于数据仓库提出来的一个集中式存储概念,和数据仓库中主要存储结构化的数据不同的是,数据湖中可以存储结构化数据(一般指以行和列来呈现的数据)、半结构化数据(如 日志、XML、JSON等)、非结构化数据(如 Word文档、PDF 等)和 二进制数据(如视频、音频、图片等)。通常来说数据湖中以存储原始数据为主,而数据仓库中以存储原始数据处理后的结构化数据为主。
Delta Lake是一个基于数据湖的开源项目,能够在数据湖之上构建湖仓一体的数据架构,提供支持ACID数据事务、可扩展的元数据处理以及底层支持Spark上的流批数据计算处理。
Delta Lake的主要特征如下:
基于Spark之上的ACID数据事务,可序列化的事务隔离级别确保了数据读写的一致性。
利用Spark的分布式可扩展的处理能力,可以做到PB级以上的数据处理和存储。
数据支持版本管控,包括支持数据回滚以及完整的历史版本审计跟踪。
支持高性能的数据行级的Merge、Insert、Update、Delete 操作,这点是Hive 所不能具备的。
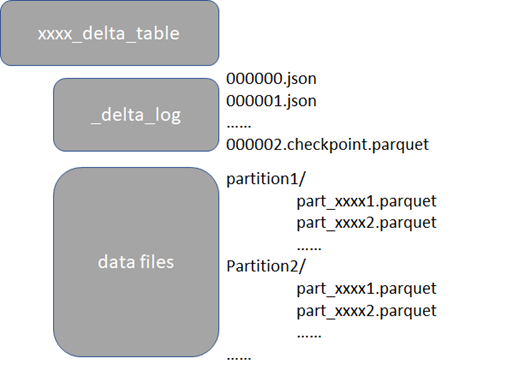
以Parquet文件作为数据存储格式,同时会有 Transaction Log文件记录了数据的变更过程,日志格式为JSON,如下图
2.1 基于Delta Lake自身设计来采集元数据
Delta Lake 的元数据由自己管理,通常不依赖于类似Hive Metastore 这样的第三方外部元数据组件。在Delta Lake中元数据是和数据一起存放在自己的文件系统的目录下,并且所有的元数据操作都被抽象成了相应的 Action 操作,表的元数据是由 Action 子类实现的。如下是Delta Lake中源码的结构(源码Github地址:https://github.com/delta-io/delta),如下图
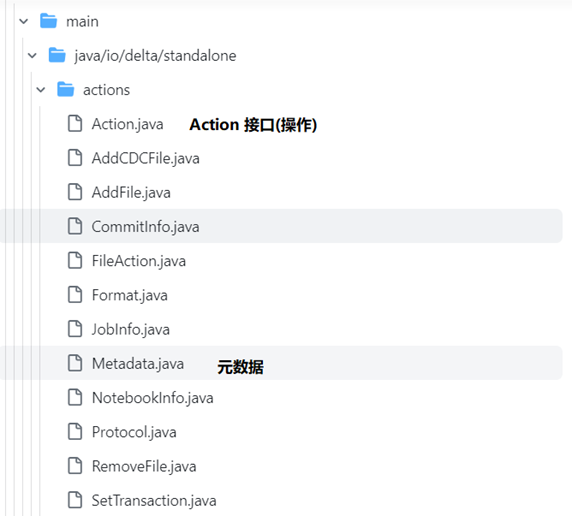
在Metadata.java这个实现类中提供了元数据的方法调用,详细代码实现可以参考纸质书。
2.2 基于Spark Catalog来采集元数据
由于Delta Lake 是支持使用spark 来读取和写入数据,所以在Delta Lake的源码中,也实现了Spark提供的CatalogPlugin接口,由于Delta Lake 也实现了Spark提供的CatalogPlugin接口,所以基于Spark Catalog的方式,也可以直接获取到delta lake的元数据信息,详细代码实现可以参考纸质书。
3、MySQL 中的元数据采集
MySQL是被广泛使用的一款关系型数据库,在MySQL数据库系统中自带了information_schema 这个库来提供MySQL元数据的访问,INFORMATION_SCHEMA是每个MySQL实例中的一个自有数据库,存储着MySQL服务器维护的所有其他数据库的相关信息,INFORMATION_SCHEMA中的表其实都是只读的视图,而不是真正的基表,不能执行INSERT、UPDATE、DELETE操作,因此没有与INFORMATION_SCHEMA相关联的数据文件,也没有具有该名称的数据库目录,并且不能设置触发器。
information_schema 中与元数据相关的重点表如下:
Tables表:提供了数据库中表、视图等信息
Columns表:提供了数据库中表字段的相关信息
Views表:提供了数据库中视图的相关信息
Partitions表:提供了数据库中数据表的分区信息
Files表:提供了有关存储MySQL表空间数据的文件的信息
4、Apache Hudi中的元数据采集
Hudi 和Delta Lake 一样,也是一款基于数据湖的开源项目,同样也能够在数据湖之上构建湖仓一体的数据架构,通过访问网址:Apache Hudi | An Open Source Data Lake Platform即可计入到Hudi的官方首页。
Hudi的主要特征如下:
支持表、事务、快速的Insert、Update、Delete 等操作
支持索引、数据存储压缩比高,并且支持常见的开源文件存储格式
支持基于Spark、Flink的分布式流式数据处理
支持Apache Spark、Flink、Presto、Trino、Hive等SQL查询引擎
4.1 基于Spark Catalog来采集元数据
由于Hudi是支持使用Spark 来读取和写入数据,所以在Hudi的源码中,也实现了Spark提供的CatalogPlugin接口,由于Hudi 和Delta Lake一样, 也实现了spark提供的CatalogPlugin接口,所以采用基于Spark Catalog的方式,也可以直接获取到Hudi的元数据信息,详细代码实现可以参考纸质书。
4.2 Hudi Timeline Meta Server
通常情况下数据湖是通过追踪数据湖中数据文件的方式来管理元数据的,不管是Delta Lake还是Hudi ,底层都是通过跟踪文件操作的方式来提取元数据的。在Hudi中,对元数据的操作和Delta Lake的实现很类似,底层也都是抽象成了相应的Action 操作,只是Action操作的类型略微有些不同。
数据湖之所以不能直接用Hive Meta Store 来管理元数据,是因为Hive Meta Store 的元数据管理是没有办法实现数据湖特有的数据跟踪能力的。因为数据湖管理文件的粒度非常细,需要记录和跟踪哪些文件是新增操作,哪些文件是失效操作,哪些数据的新增的,哪些数据是更新的,而且还需要具备原子的事务性,支持回滚等操作。Hudi为了管理好元数据,记录数据的变更过程,设计了Timeline Meta Server,Timeline 记录了在不同时刻对表执行的所有操作的日志,有助于提供表的即时视图。
在Hudi中抽象出了一个Marker的概念,翻译过来就是标记的意思,数据的写入操作可能在完成之前出现写入失败的情况,从而在存储中留下部分或损坏的数据文件,而标记则用于跟踪和清除失败的写入操作,写入操作开始时,会创建一个标记,表示正在进行文件写入。写入提交成功后,标记将被删除。如果写入操作中途失败,则会留下一个标记,表示这个写入的文件不完整。使用标记主要有如下两个目的。
正在删除重复/部分数据文件:标记有助于有效地识别写入的部分数据文件,与稍后成功写入的数据文件对比,这些文件包含重复的数据,并且在提交完成时会清除这些重复的数据文件。
回滚失败的提交:如果写入操作失败,则下一个写入请求将会在继续进行新的写入之前会先回滚该失败的提交。回滚是在标记的帮助下完成的,标记用于识别整体失败但已经提交的一部分写入的数据文件。
加入没用标记来跟踪每次提交的数据文件,那么Hudi将不得不列出文件系统中的所有文件,将其与Timeline中看到的文件关联起来做对比,然后删除属于部分写入失败的文件,这在一个像Hudi 这样庞大的分布式系统中,性能的开销将会是非常昂贵的。
4.3 基于Hive Meta DB来采集元数据
虽然Hudi 元数据存储是通过Timeline来管理的,但是Hudi 在设计时,就考虑了支持将自身元数据同步到Hive Meta Store中,其实就是将Hudi的Timeline中的元数据异步更新到Hive Meta Store中存储。

在Hudi的源码中,定义了org.apache.hudi.sync.common.HoodieMetaSyncOperations.java这个接口抽象来作为元数据同步给类似Hive Meta DB这样的第三方的外部元数据存储库,详细代码实现可以参考纸质书。
5、Apache Iceberg中的元数据采集
Apache Iceberg同样也是一款开源的数据湖项目,Iceberg的出现进一步推动了数据湖和湖仓一体架构的发展,并且让数据湖技术变得更加丰富,通过访问网址:Apache Iceberg - Apache Iceberg 即可进入其官方首页。
Iceberg的主要特点如下:
同样也支持Apache Spark、Flink、Presto、Trino、Hive、Impala等众多的SQL查询引擎。
支持更加灵活的SQL语句来Merge、Update、Delete数据湖中的数据。
可以很好的支持对数据Schema的变更,比如添加新的列、重命名列等。
支持快速的数据查询,数据查询时可以快速跳过不必要的分区和文件以快速查找到符合指定条件的数据,在Iceberg中,单个表可以支持PB级别数据的快速查询。
数据存储支持按照时间序列的版本控制以及回滚,可以按照时间序列或者版本来查询数据的快照。
数据在存储时,压缩支持开箱即用,可以有效的节省数据存储的成本。
5.1 Iceberg的元数据设计
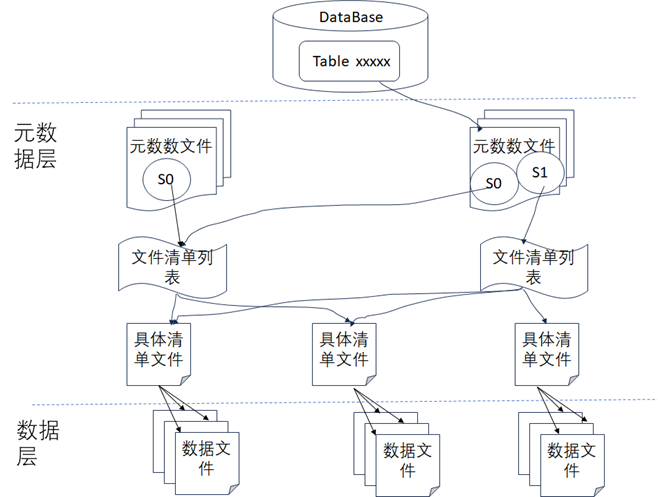
由于Hive数据仓库的表的状态是直接通过列出底层的数据文件来查看的,所以表的数据修改无法做到原子性,所以无法支持事务以及回滚,一旦写入出错可能就会产生不准确的结果。所以Iceberg在底层通过架构设计时增加了元数据层这一设计来规避Hive数据仓库的不足,如下图所示,从图中可以看到Iceberg使用了两层设计来持久化数据,一层是元数据层,一层是数据层,在数据层中存储是Apache Parquet、Avro或ORC等格式的实际数据,在元数据层中可以有效地跟踪数据操作时删除了哪些文件和文件夹,然后扫描数据文件统计数据时,就可以确定特定查询时是否需要读取该文件以便提高查询的速度。元数据层通常包容如下内容:
元数据文件:元数据文件通常存储表的Schema、分区信息和表快照的详细信息等数据信息。
清单列表文件:将所有清单文件信息存储为快照中的清单文件的索引,并且通常会包含一些其他详细信息,如添加、删除了多少数据文件以及分区的边界情况等。
清单文件:存储数据文件列表(比如以Parquet/ORC/AVRO格式存储的数据),以及用于文件被修改后的列级度量和统计数据。
5.2 通过Spark Catalog来采集元数据
同Hudi 和Delta Lake一样,由于Iceberg也是支持使用Spark 来读取和写入数据,所以在Iceberg的底层设计时,也实现了Spark提供的CatalogPlugin接口,所以通过Spark Catalog的方式,也是可以直接获取到Iceberg的元数据信息,详细代码实现可以参考纸质书。
5.3 通过Iceberg Java API来获取元数据
在Iceberg中提供了Java API 来获取表的元数据,通过访问官方网址:Java API - Apache Iceberg 即可获取到Java API的详细介绍,如下图
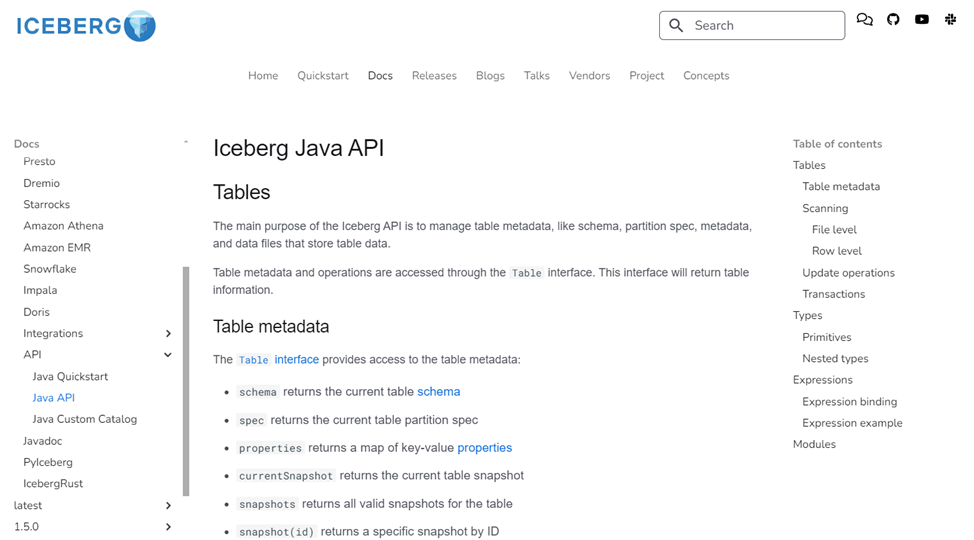
从图中可以看到,通过Java API 可以获取到Iceberg数据表的Schema、属性、存储路径、快照等众多元数据信息。