近几年,随着企业数据资产规模的指数级增长,传统的ETL和数据集成方式已经难以应对多源、异构、实时和高频变化的数据场景。
Gartner 在其最新的《Data Integration Strategies》和《Market Guide to DataOps》报告中提出了一个重要趋势:"未来的数据管理将以元数据为中心,从静态记录走向主动驱动(Metadata Activation)。"
这标志着一个新的方向------基于元数据(metadata-driven)的 DataOps 与 ETL 架构------正在成为数据集成与治理的核心演进方向。
一、从静态元数据到"主动元数据"
传统的数据集成体系中,元数据往往只是"描述性"的:记录字段定义、表结构、血缘关系或作业日志。但在 Gartner 的框架中,元数据的角色正从"文档"走向"智能中枢"。
主动元数据(Active Metadata) 指的是系统能够持续采集、分析和利用元数据来自动驱动运行决策的能力。
它不再是"看得见",而是"能行动":
-
当检测到上游表结构变化时,自动触发下游任务调整;
-
当某个任务延迟或异常时,系统能自动回溯依赖并执行补偿;
-
当某条数据质量规则连续异常时,能智能识别原因并给出修复建议。
Gartner 将这种能力称为数据管理最高成熟度阶段的标志性特征之一:
"元数据激活(Metadata Activation)是第五级数据集成成熟度的支柱,使自动化管道编排与机器决策成为可能。"
二、DataOps 的演进:以元数据为核心的自动化闭环
Gartner 对 DataOps 的定义是:
"一种以协作、自动化和持续改进为核心的数据交付方法论,旨在提升数据集成与交付的速度、质量与可观测性。"
而当 DataOps 与元数据结合后,它从 DevOps 式的"数据发布流水线"进一步演变为"元数据驱动的智能闭环体系":
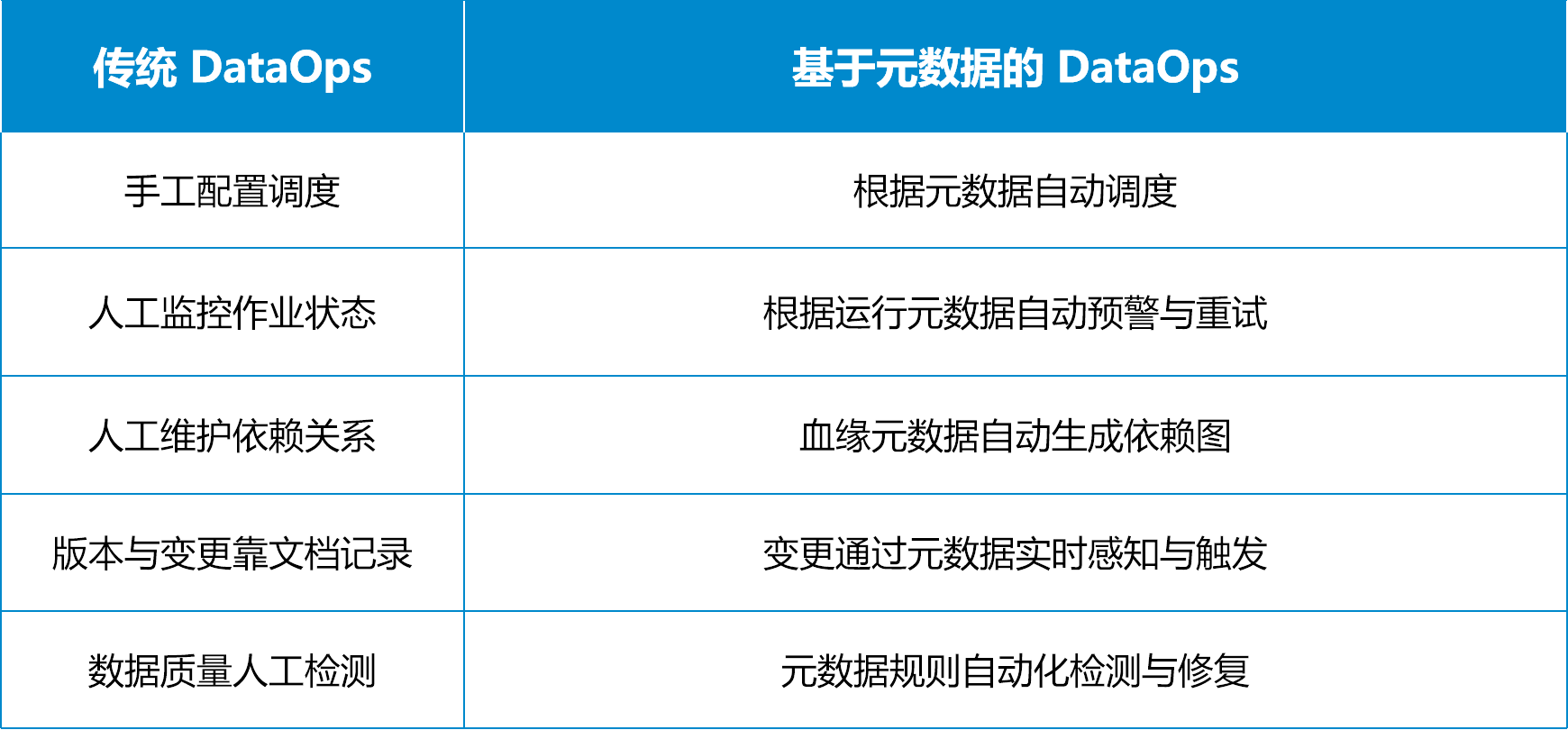
这意味着,数据管道不再是一组固定脚本,而是一个可以自感知、自调优、自修复的系统。
三、ETL 的再造:元数据驱动的"自适应集成"
在 ETL(Extract-Transform-Load)层面,基于元数据的架构也带来了显著变化。
传统ETL痛点:
-
每次源表结构变化都需人工改脚本;
-
无法精确识别哪些任务受影响;
-
作业优化完全依赖人工经验;
-
数据质量检测与管道调度分离。
而在元数据驱动的ETL中:
-
元数据统一建模:包括字段定义、血缘关系、运行时性能、数据质量规则等;
-
动态任务生成:ETL流程根据元数据动态构建和调整逻辑,无需手动改脚本;
-
自适应调度:当检测到依赖变化或运行异常时,系统自动决定重跑、跳过或延迟执行;
-
自动化数据质量控制:基于元数据规则持续监测、触发警报或补偿任务;
-
可观测性增强:通过元数据可追踪到任意任务的来源、依赖、耗时与性能。
这类机制已经在部分领先的数据平台中实践,比如 Atlan、Collibra、Informatica Intelligent Data Management Cloud,以及国内的 ETLCloud、阿里DataWorks 等,都在不同程度上探索元数据驱动的 ETL 自动化能力。
四、关键能力构成:让元数据"活起来"
一个真正"基于元数据"的 DataOps / ETL 平台,至少需要具备以下八类核心能力:
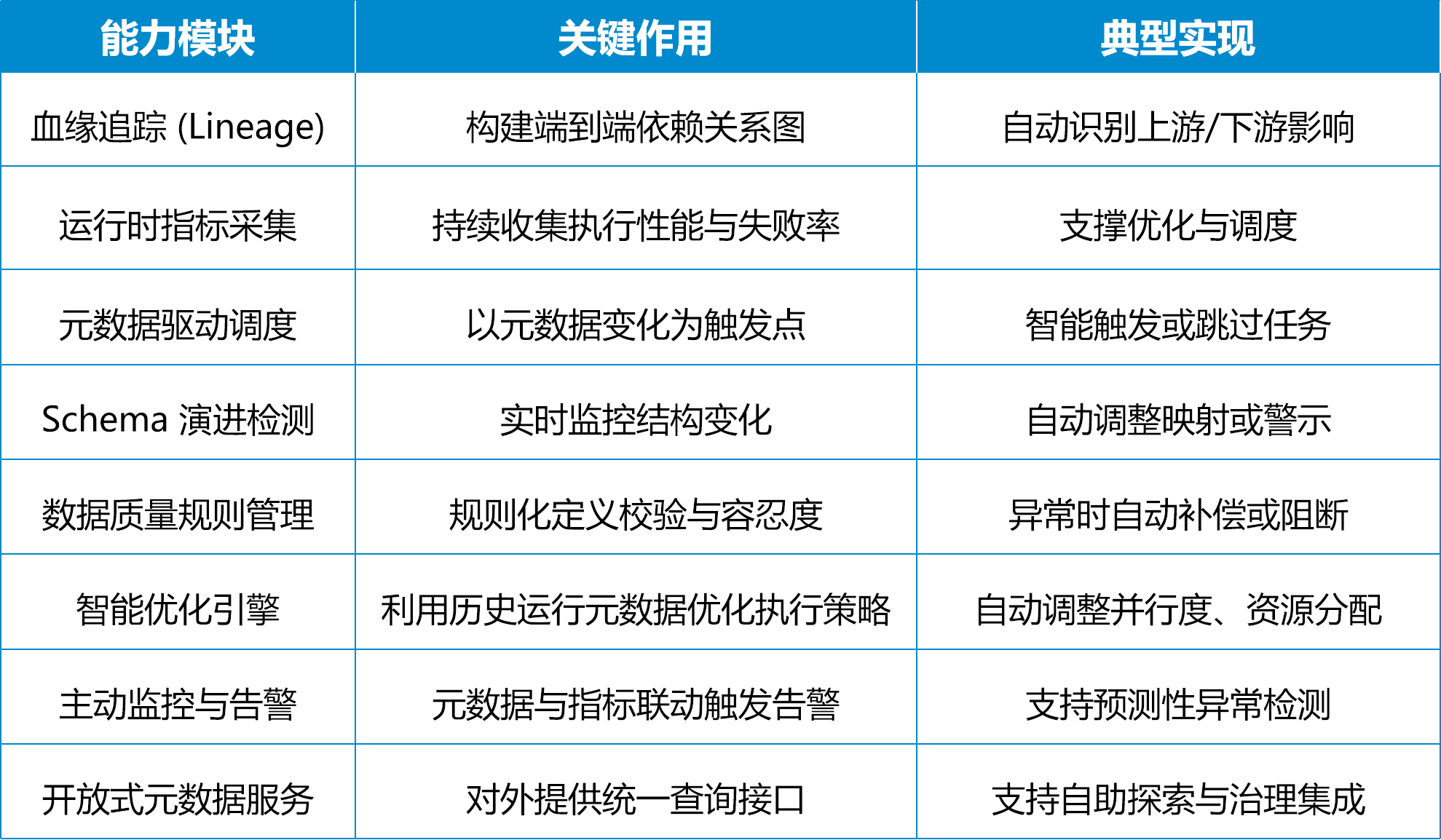
可以看到,这实际上已经超越了传统"ETL工具"的定义,逐步向智能化"数据编排与治理平台"演进。
五、落地挑战:从理念到实践的距离
Gartner 同时指出,主动元数据目前仍处于"幻灭期"------技术成熟度曲线的中段阶段。
这意味着它的理念先进,但落地难度依旧不小。
主要挑战包括:
-
元数据整合难度大:不同系统的元数据格式、标准、接口差异大,统一抽取与融合复杂;
-
元数据质量治理:当元数据不完整或不一致,自动化决策可能失准;
-
技术与组织协同成本:自动化系统需要匹配 DataOps 的流程文化,否则"工具孤岛"仍旧存在;
-
安全与合规问题:元数据往往含敏感信息,涉及权限、合规与安全边界;
-
ROI 不易量化:主动元数据带来的收益多体现在长期自动化与质量提升上,短期内投入较高。
因此,大多数企业的实践路径是渐进式激活元数据:先从血缘、质量、调度监控入手,逐步延伸到自动优化与智能决策。
六、元数据将成为下一代ETL的"操作系统"
如果说传统 ETL 的核心是"流程",
那么新一代 ETL 的核心就是"元数据"。
当元数据真正"活"起来------
它不仅描述数据的形状,还能决定数据的行为;
它不仅记录历史,还能指导未来。
Gartner 的趋势预示着:未来的 DataOps 和 ETL 平台,不再是基于规则的脚本集合,而是基于元数据的智能体系统。在这个趋势下,谁能先让元数据"动起来",谁就能真正掌握数据自动化与治理智能化的主动权。