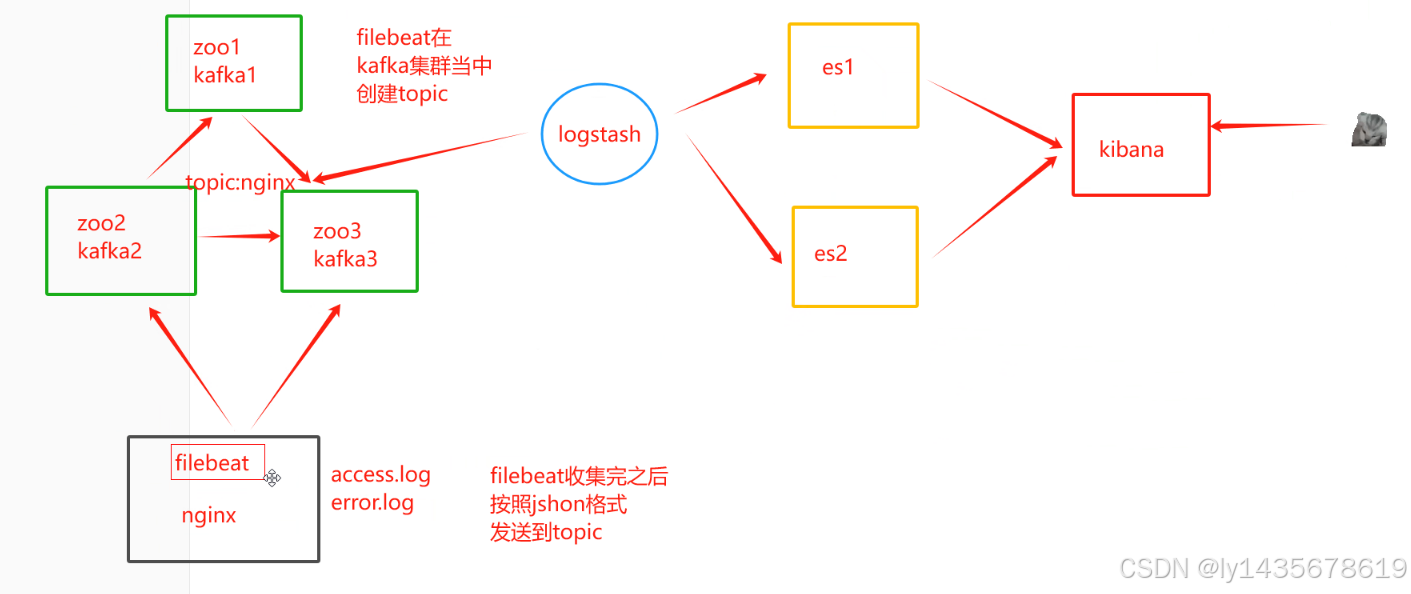
一、elk + filebeat + kafka
kafka
组件
工作流程
主题
filebeat----生产者
logstash----消费者
elk + (filebeat+服务) + (zookeeper+kafka)
1.1、部署filebeat+nginx服务
[root@nginx1 ~]# systemctl stop firewalld
[root@nginx1 ~]# setenforce 0
[root@nginx1 ~]# systemctl restart nginx.service
[root@nginx1 ~]# cd /opt/
[root@nginx1 opt]# tar -xf filebeat-6.7.2-linux-x86_64.tar.gz
[root@nginx1 opt]# mv filebeat-6.7.2-linux-x86_64 filebeat
[root@nginx1 opt]# cd filebeat/
[root@nginx1 filebeat]# ls
fields.yml filebeat.yml module README.md
filebeat kibana modules.d
filebeat.reference.yml LICENSE.txt NOTICE.txt
[root@nginx1 filebeat]# vim filebeat.yml
- type: log
enabled: true
paths: - /usr/local/nginx/logs/access.log
tags: ["access"]
- type: log
enabled: true
paths: - /usr/local/nginx/logs/error.log
tags: ["error"]
150 #output.elasticsearch:
151 # Array of hosts to connect to.
152 # hosts: ["localhost:9200"]
#添加输出到 Kafka 的配置
163 output.kafka:
164 enabled: true
165 # The Logstash hosts
166 hosts: ["192.168.168.11:9092","192.168.168.12:9092","192. 168.168.13:9092"] ##发送到kafka集群上
topic: "nginx1" #指定 Kafka 的 topic
./filebeat -e -c filebeat.yml ##启动filebeat--------------------以上是filebeat+nginx的配置文件------------
启动完成结果如下:
------------------------以上nginx+filebeat生产者的配置----------------------------
1.2、部署 ELK,在 Logstash 组件所在节点上新建一个 Logstash 配置文件
-----------------------------------以下是logstash的配置-----------------------------
[root@elk3 ~]# cd /etc/logstash/conf.d/
[root@elk3 conf.d]# ls
http.conf nginx_31.conf nmh_11.conf system.conf
vim kafka.conf
input {
kafka {
bootstrap_servers => "192.168.168.11:9092,192.168.168.12:9092,192.168.168.13:9092"
#kafka集群地址
topics => "nginx1"
#拉取的kafka的指定topic
type => "nginx_kafka"
#指定 type 字段
codec => "json"
#解析json格式的日志数据
auto_offset_reset => "latest"
#拉取最近数据,earliest为从头开始拉取
decorate_events => true
#传递给elasticsearch的数据额外增加kafka的属性数据
}
}
output {
if "access" in [tags] {
elasticsearch {
hosts => ["192.168.168.61:9200","192.168.168.62:9200"]
##数据存储到 elasticsearch----61、62数据库上
index => "nginx_access-%{+YYYY.MM.dd}"
##索引的名称格式
}
}
if "error" in [tags] {
elasticsearch {
hosts => ["192.168.168.61:9200","192.168.168.62:9200"]
index => "nginx_error-%{+YYYY.MM.dd}"
}
}
}
logstash -f kafka.conf --path.data /opt/test12 & ##在filebeat启动后再启动
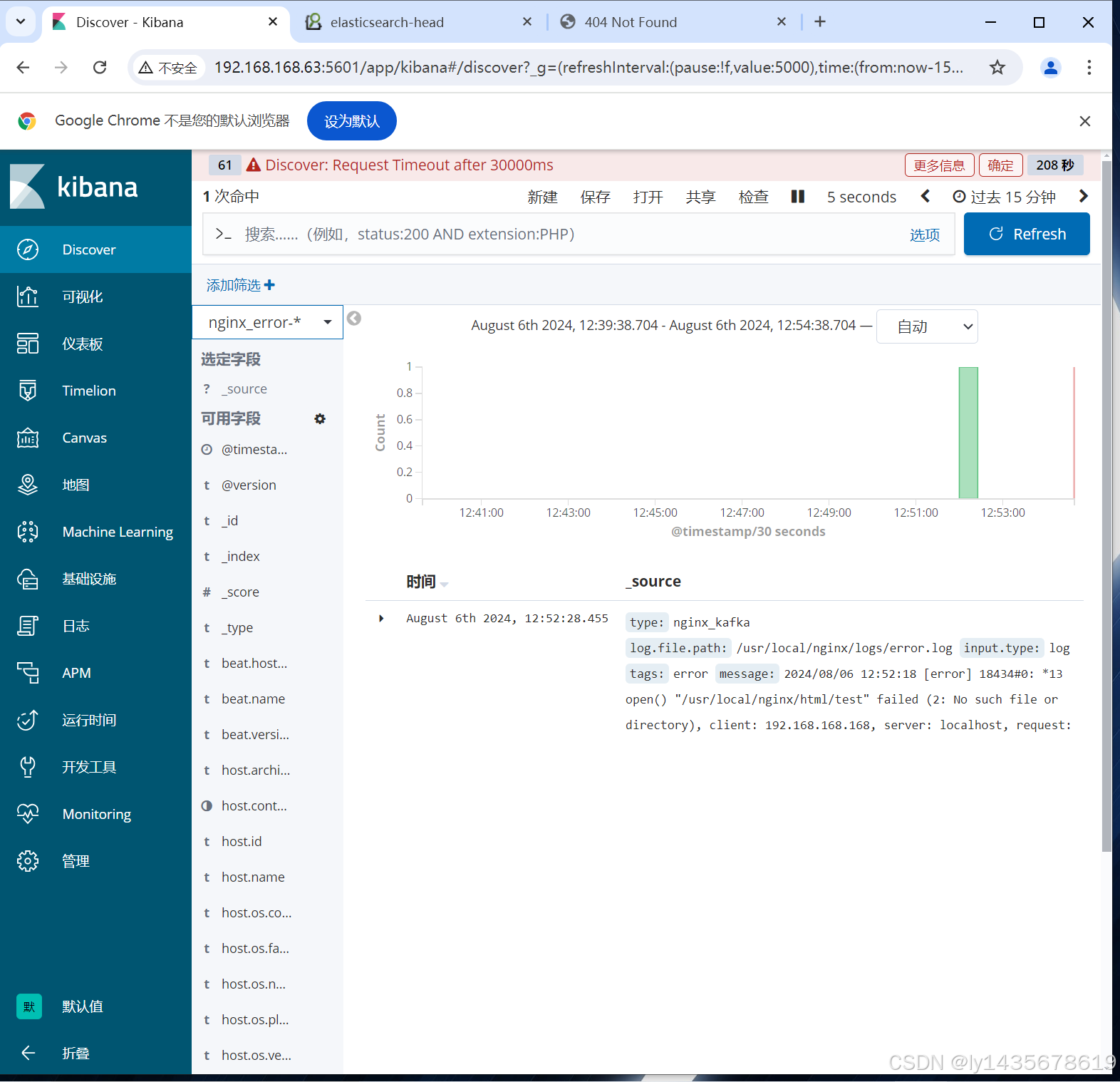
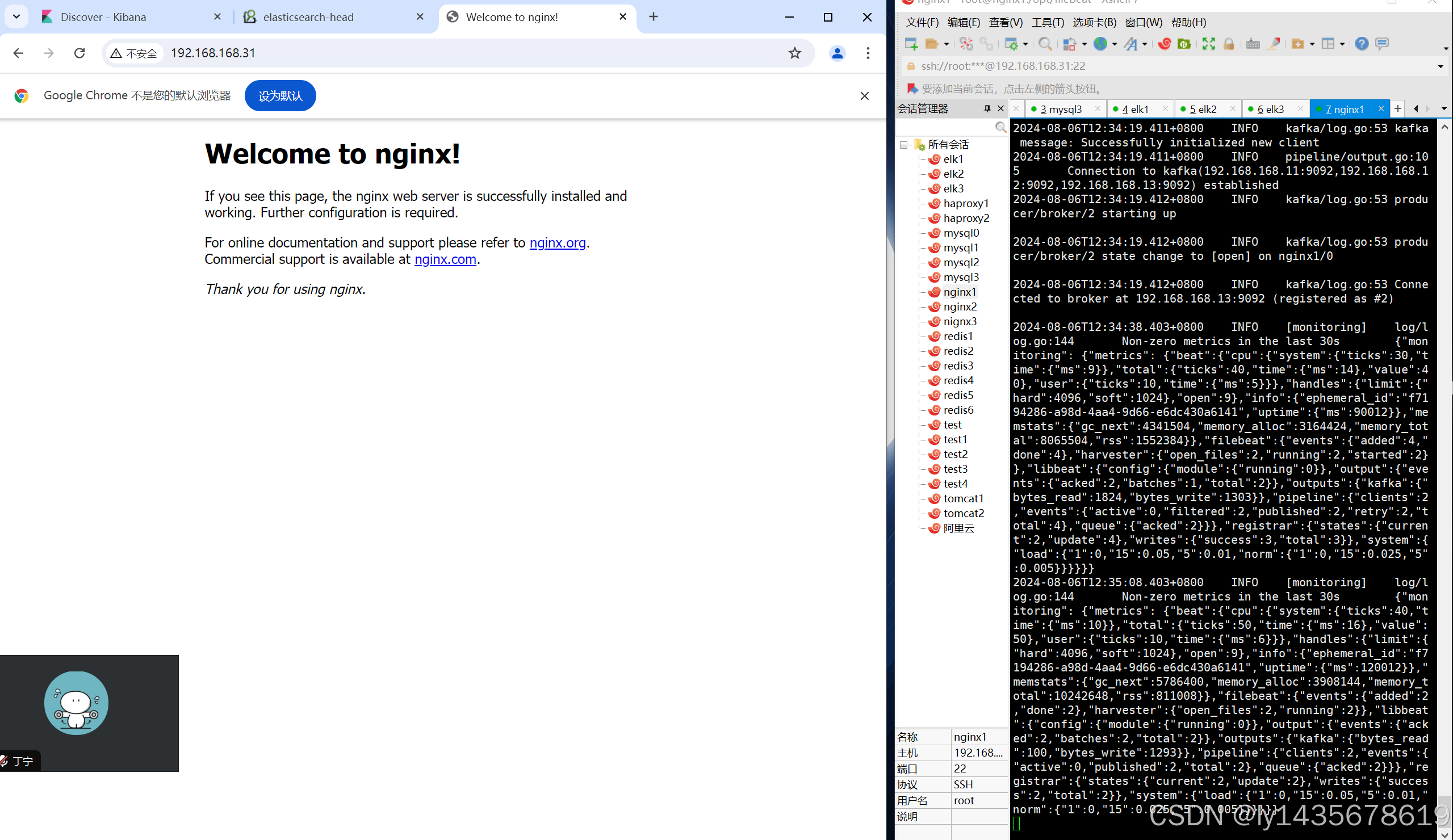
谷歌浏览器访问 http://192.168.168.63:5601 登录 Kibana,
单击"Create Index Pattern"按钮添加索引"filebeat_test-*",单击 "create" 按钮创建,
单击 "Discover" 按钮可查看图表信息及日志信息。启动完成结果如下:
访问192.168.168.31
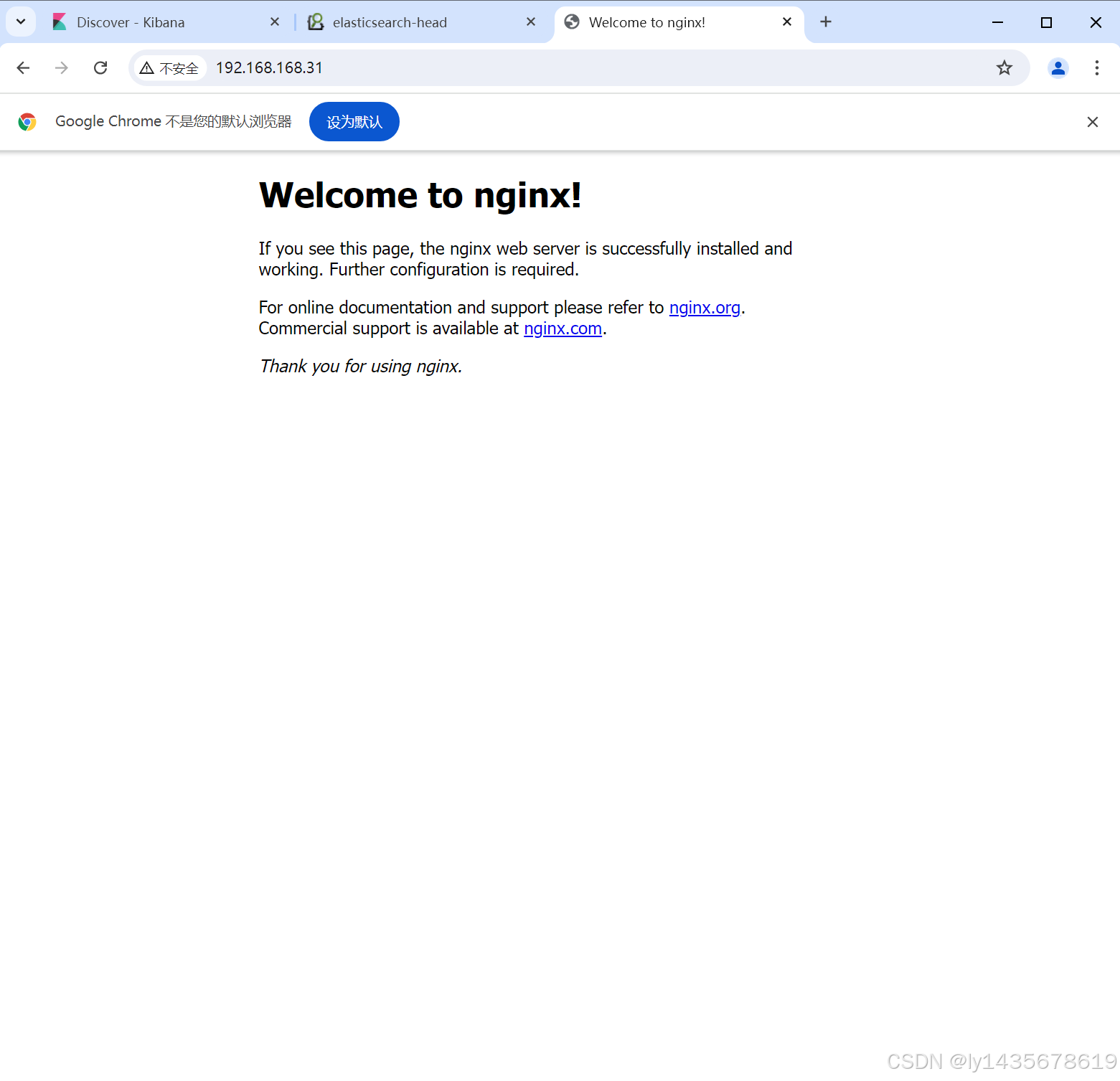
访问192.168.168.31/test
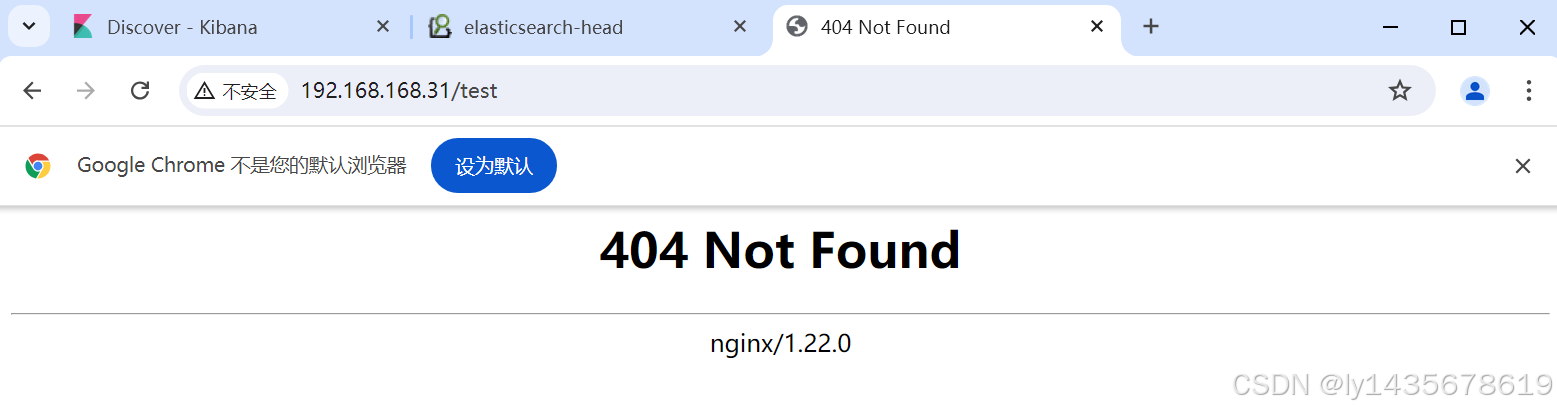
访问192.168.168.61:9100
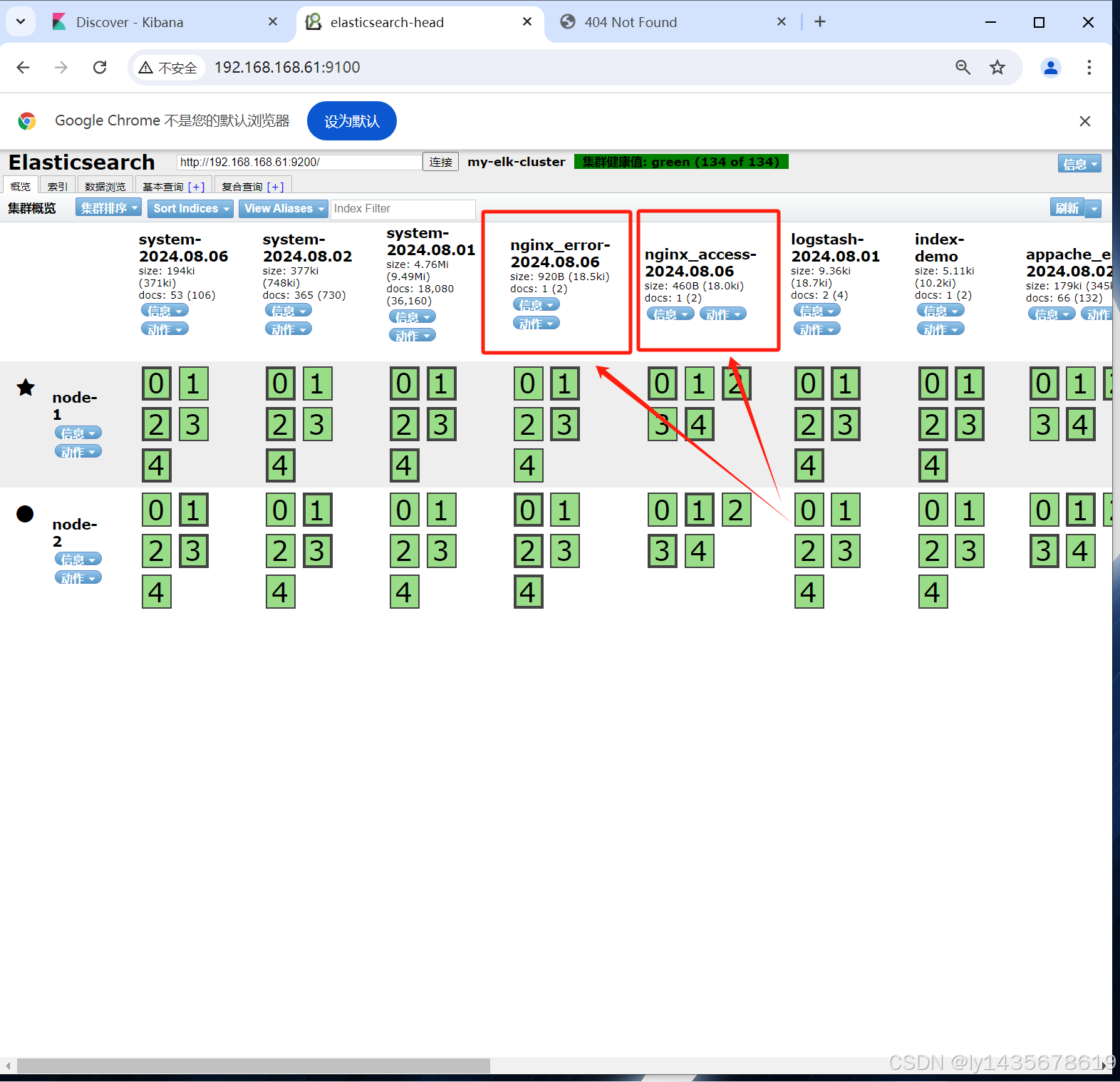
访问192.168.168.63:5601kibana可视化工具查看nginx的访问日志
[root@mysql1 ~]# kafka-topics.sh --list --bootstrap-server 192.168.168.11:9092,192.168.168.12:9092,192.168.168.13:9092
__consumer_offsets
nginx1
test1
test2
[root@mysql3 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.168.11:9092,192.168.168.12:9092,192.168.168.13:9092 --topic nginx1 --from-beginning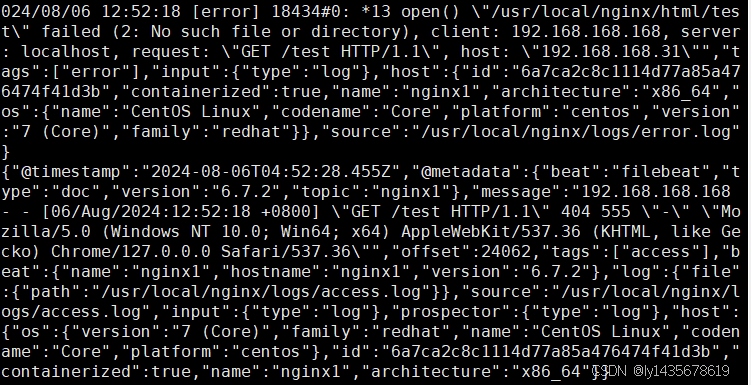
---------------- Filebeat+Kafka+ELK ----------------
1.部署 Zookeeper+Kafka 集群
2.部署 Filebeat
cd /usr/local/filebeat
vim filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access_log
tags: ["access"]
- type: log
enabled: true
paths:
- /var/log/nginx/error_log
tags: ["error"]
150 #output.elasticsearch:
151 # Array of hosts to connect to.
152 # hosts: ["localhost:9200"]##注释其中150行和152行
#添加输出到 Kafka 的配置
output.kafka:
enabled: true
hosts: "192.168.168.11:9092,192.168.168.12:9092,192.168.168.13:9092" #指定 Kafka 集群配置
topic: "nginx1" #指定 Kafka 的 topic
#启动 filebeat
./filebeat -e -c filebeat.yml
3.部署 ELK,在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.d/
vim kafka.conf
input {
kafka {
bootstrap_servers => "192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092"
#kafka集群地址
topics => "nginx1"
#拉取的kafka的指定topic
type => "nginx_kafka"
#指定 type 字段
codec => "json"
#解析json格式的日志数据
auto_offset_reset => "latest"
#拉取最近数据,earliest为从头开始拉取
decorate_events => true
#传递给elasticsearch的数据额外增加kafka的属性数据
}
}
output {
if "access" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index => "nginx_access-%{+YYYY.MM.dd}"
}
}
if "error" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index => "nginx_error-%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}
#启动 logstash
logstash -f kafka.conf4.浏览器访问 http://192.168.168.63:5601 登录 Kibana,
单击"Create Index Pattern"按钮添加索引"filebeat_test-*",单击 "create" 按钮创建,
单击 "Discover" 按钮可查看图表信息及日志信息。
[root@mysql1 ~]# kafka-topics.sh --list --bootstrap-server 192.168.168.11:9092,192.168.168.12:9092,192.168.168.13:9092
__consumer_offsets ##查看主题列表
nginx1
test1
test2
[root@mysql3 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.168.11:9092,192.168.168.12:9092,192.168.168.13:9092 --topic nginx1 --from-beginning ##查看nginx主题生产情况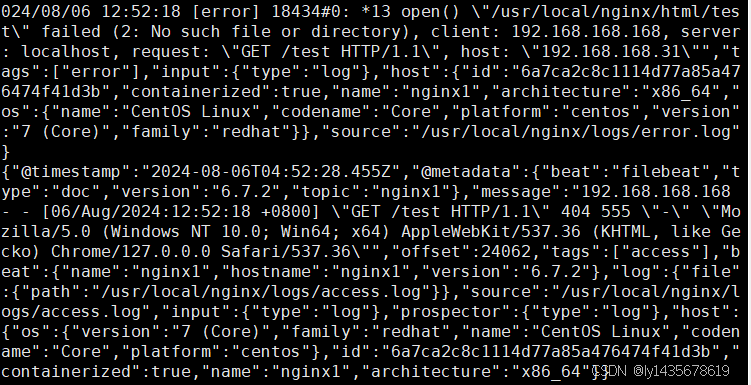
二、rsync远程同步
-
上行 客户端同步到服务端
-
rsync 远程同步可以实现 上行 客户端同步到服务端
-
下行 服务端同步到客户端
-
发起端(客户端)配置 rsync+inotify 远程上传实现下行 服务端同步到客户端
-
开源快速备份工具,一般是系统自带的。
-
开源在不同主机之间同步整个目录树(目录)
-
在远程同步的任务中,负责发起rsync的叫做发起端,也就是服务端,负责响应的同步请求的,就是客户端。
2.1、rsync的特点:
1、支持拷贝文件,链接文件等等。
2、可以同步整个目录
3、可以支持保留源文件或者目录的权限等等。
4、可以实现增量同步。
2.1.1、同步方式:
1、完整备份。
2、增量备份。
2.1.2、常用的选项:
1、-a 归档模式,保留权限
2、-v 显示同步的详细过程
3、-z 压缩,在传输过程中对文件进行压缩。
4、-H 同步硬链接
5、-delete 同步删除文件
6、-l 同步链接文件
7、-r 递归,所有
inotify-tools
inotify-tools实现监控
inotify watch 监控文件系统变化
inotify wait 监控修改,修改,创建,删除,属性修改(权限修改,所有者,所在组)如果发送变动,立即输出结果。
rsync 远程同步
1、Rsync 简介====
rsync(Remote Sync,远程同步) 是一个开源的快速备份工具,可以在不同主机之间镜像同步整个目录树,
在远程同步任务中,负责发起rsync同步操作的客户机称为发起端,而负责响应来自客户机的rsync
同步操作的服务器称为同步源。在同步过程中,同步源负责提供文件的原始位置,发起端应对该位置具有读取权限。
Rsync 是 Linux 系统下的数据镜像备份工具,使用快速增量备份工具 Remote Sync 可以远程同步,
可以在不同主机之间进行同步,可实现全量备份与增量备份,保持链接和权限,且采用优化的同步算法,
传输前执行压缩,因此非常适合用于架构集中式备份或异地备份等应用。同时Rsync支持本地复制,
或者与其他 SSH、rsync 主机同步
rsync简介
rsync(Remote Sync,远程同步)是一个开源的快速备份工具,可以在不同主机之间镜像同步整个目录树,
支持增量备份,并保持链接和权限,且采用优化的同步算法,传输前执行压缩,因此非常适用于异地备份、
镜像服务器等应用。
rsync 的官方站点的网址是 rsync.samba.org/,目前最新版本是 3.1.3,由 Wayne Davison 进行维护。
作为一种最常用的文件备份工具,rsync 往往是 Linux 和 UNIX 系统默 认安装的基本组件之一。
rsync特点
支持拷贝特殊文件,如连接文件、设备等。
可以有排除指定文件或目录同步的功能,相当于打包命令tar的排除功能。
可以做到保持原文件或目录的权限、时间、软硬链接、属主、组等所有属性均不改变 --p。
可以实现增量同步,既只同步发生变化的数据,因此数据传输效率很高(tar-N)。
可以使用rcp、rsh、ssh等方式来配合传输文件(rsync本身不对数据加密)。
可以通过socket(进程方式)传输文件和数据(服务端和客户端)。
支持匿名的活认证(无需系统用户)的进程模式传输,可以实现方便安全的进行数据备份和镜像。
rsync同步源服务器
在远程同步任务中,负责发起 rsync 同步操作的客户机称为发起端,
而负责响应来自客户机的 rsync 同步操作的服务器称为同步源。
在下行同步(下载)中,同步源负责提供文档的原始位置,发起端应对该位置有读取权限。
在上行同步(上传)中,同步源负责提供文档的目标位置,发起端应对该位置具有写入权限。
scp与rsync的区别
(1)功能差距
rsync远程拷贝可以附带软链接/硬链接。(参数-l 保留软链接,-H 保留硬链接)
scp不支持链接的拷贝。
(2)效率差异
简单的解析scp和rsync,前是复制,后是同步。
rsync和scp在目录均不存在时,执行时间相差不大,但是目录存在的情况下差异很大。
原因是scp是复制:若目的地文件不存在则新建,若存在则覆盖。而rsync是同步,
比较两边文件是否相同,相同的话,就什么都不做,若存在差异就直接更新。
起到同步的作用时用rsync会快一些,起到复制作用时两者均可(目的地无文件)。视情况来选择rsync或scp。
=2、同步方式===
(1)完整备份:每次备份都是从备份源将所有的文件或目录备份到目的地。
(2)差量备份:备份上次完全备份以后有变化的数据(他针对的上次的完全备份,他备份过程中不清除存档属性)。
(3)增量备份:备份上次备份以后有变化的数据(他才不管是那种类型的备份,有变化的数据就备份,他会清除存档属性)
==3、常用Rsync命令=
基本格式:rsync 选项 原始位置 目标位置
常用选项:
-r:递归模式,包含目录及子目录中的所有文件。
-l:对于符号链接文件仍然复制为符号链接文件。
-v:显示同步过程的详细(verbose)信息。
-z:在传输文件时进行压缩(compress)。
-a:归档模式,保留文件的权限、属性等信息,等同于组合选项"-rlptgoD"。
-p:保留文件的权限标记。
-t:保留文件的时间标记。
-g:保留文件的属组标记(仅超级用户使用)。
-o:保留文件的属主标记(仅超级用户使用)。
-H:保留硬连接文件。
-A:保留 ACL 属性信息。
-D:保留设备文件及其他特殊文件。
--delete:删除目标位置有而原始位置没有的文件。
--checksum:根据校验和(而不是文件大小、修改时间)来决定是否跳过文件。
=======4、配置源的两种表达方法
格式一:
用户名@主机地址::共享模块名
rsync -avz backuper@192.168.80.10::wwwroot /opt/
格式二:
rsync://用户名@主机地址/共享模块名
rsync -avz rsync://backuper@192.168.80.10/wwwroot /opt/
2.2、rsync远程同步下行配置
4、配置服务端与客户端的实验==
前提首先关闭防火墙和增强功能
systemctl stop firewalld
setenforce 0
实验
192.168.168.23 服务端 14
192.168.168.24 客户端 15
① 配置rsync源服务器(192.168.168.23)
rpm -q rsync #一般系统已默认安装rsync
#建立/etc/rsyncd.conf 配置文件
vim /etc/rsyncd.conf #添加以下配置项
uid = root
gid = root
use chroot = yes #禁锢在源目录
address = 192.168.168.23 #监听地址
port 873 #监听端口 tcp/udp 873,可通过cat /etc/services | grep rsync查看
log file = /var/log/rsyncd.log #日志文件位置
pid file = /var/run/rsyncd.pid #存放进程 ID 的文件位置
hosts allow = 192.168.168.0/24 #允许访问的客户机地址
dont compress = *.gz *.bz2 *.tgz *.zip *.rar *.z #同步时不再压缩的文件类型
[wwwroot] #共享模块名称
path = /var/www/html #源目录的实际路径
comment = Document Root of www.kgc.com
read only = yes #是否为只读
auth users = backuper #授权账户,多个账号以空格分隔
secrets file = /etc/rsyncd_users.db #存放账户信息的数据文件
uid = root
gid = root
use chroot = yes
address = 192.168.233.10
port 873
log file = /var/log/rsyncd.log
pid file = /var/run/rsyncd.pid
hosts allow = 192.168.233.0/24
dont compress = *.gz *.bz2 *.tgz *.zip *.rar *.z
[test]
path = /opt/test
comment = test
read only = no
auth users = backuper
secrets file = /etc/rsyncd_users.db
#如采用匿名的方式,只要将其中的"auth users"和"secrets file"配置项去掉即可。
#为备份账户创建数据文件
vim /etc/rsyncd_users.db
backuper:123456 #无须建立同名系统用户
chmod 600 /etc/rsyncd_users.db #这个文件的权限只能是600!
#保证所有用户对源目录/opt/test 都有读取权限
chmod 777 /opt/test
ls -ld /opt/test
#启动 rsync 服务程序
rsync --daemon #启动 rsync 服务,以独立监听服务的方式(守护进程)运行
netstat -anpt | grep rsync
[root@test3 opt]# netstat -anpt | grep rsync
[root@test3 opt]# systemctl restart rsyncd
[root@test3 opt]# netstat -anpt | grep rsync
tcp 0 0 192.168.168.23:873 0.0.0.0:* LISTEN 11909/rsync
#关闭 rsync 服务
kill $(cat /var/run/rsyncd.pid)
rm -rf /var/run/rsyncd.pid
② 发起端(192.168.168.24)
#将指定的资源下载到本地/opt 目录下进行备份。
格式一:
rsync -avz backuper@192.168.168.23::test /opt/ #密码123456
格式二:
rsync -avz rsync://backuper@192.168.168.23/test /opt/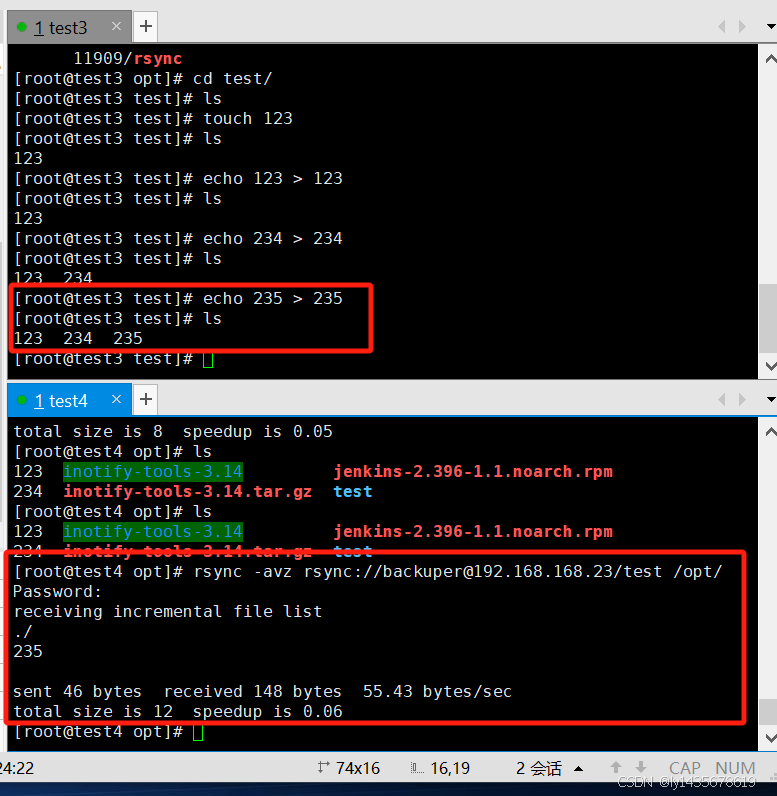
#免交互格式配置:
echo "123456" > /etc/server.pass ##设置在客户端,输入密码的一方
chmod 600 /etc/server.pass #密码文件权限必须为600,即除了属主,其他人都没有查看权限。
rsync -avz --password-file=/etc/server.pass backuper@192.168.168.23::test /opt/
#免密同步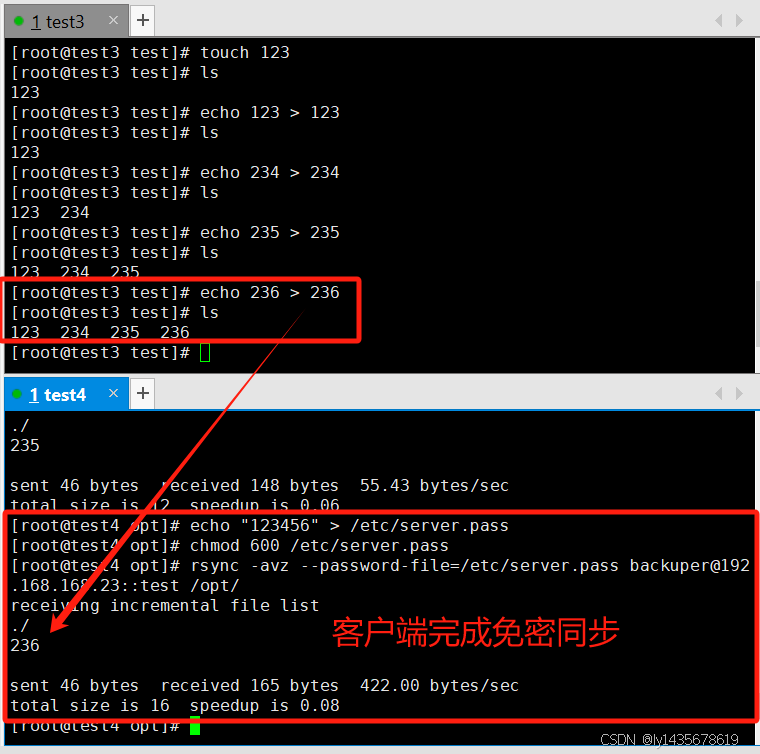
[root@test4 opt]# whereis rsync
rsync: /usr/bin/rsync /usr/share/man/man1/rsync.1.gz
设置定时任务
定时备份
crontab -e
30 22 * * * /usr/bin/rsync -az --delete --password-file=/etc/server.pass backuper@192.168.168.23::test /opt/
#为了在同步过程中不用输入密码,需要创建一个密码文件,保存 backuper 用户的密码,如 /etc/server.pass。在执行 rsync 同步时使用选项 "--password-file=/etc/server.pass" 指定即可。
systemctl restart crond
systemctl enable crond三、inotify上行同步
-
inotify-tools
-
inotify-tools实现监控
-
inotify watch 监控文件系统变化
-
inotify wait 监控修改,修改,创建,删除,属性修改(权限修改,所有者,所在组)如果发送变动,立即输出结果。
---------------------------5、发起端(客户端)配置 rsync+inotify-------------------------------
使用inotify通知接口,可以用来监控文件系统的各种变化情况,如文件存取、删除、移动、修改等。利用这一机制,
可以非常方便地实现文件异动告警、增量备份,并针对目录或文件的变化及时作出响应。
将inotify机制与rsync工具相结合,可以实现触发式备份(实时同步),即只要原始位置的文档发生变化,
则立即启动增量备份操作;否则处于静默等待状态。这样,就避免了按固定周期备份时存在的延迟性、周期过密等问题。
因为 inotify 通知机制由 Linux 内核提供,因此主要做本机监控,在触发式备份中应用时更适合上行同步。
1.修改rsync源服务器配置文件
vim /etc/rsyncd.conf
......
read only = no #关闭只读,上行同步需要可以写
kill $(cat /var/run/rsyncd.pid) ##杀死服务
rm -rf /var/run/rsyncd.pid ##删除服务
rsync --daemon ##重启服务
netstat -anpt | grep rsync
chmod 777 /opt/test2.调整 inotify 内核参数
在Linux内核中,默认的inotify机制提供了三个调控参数:
max_queue_events(监控事件队列,默认值为16384)、
max_user_instances(最多监控实例数,默认值为128)、
max_user_watches(每个实例最多监控文件数,默认值为8192)。当要监控的目录、文件数量较多或者变化较频繁时,
建议加大这三个参数的值。
cat /proc/sys/fs/inotify/max_queued_events
cat /proc/sys/fs/inotify/max_user_instances
cat /proc/sys/fs/inotify/max_user_watches
vim /etc/sysctl.conf
fs.inotify.max_queued_events = 16384
fs.inotify.max_user_instances = 1024
fs.inotify.max_user_watches = 1048576
sysctl -p3.1.安装 inotify-tools 192.168.168.24安装
用 inotify 机制还需要安装 inotify-tools,以便提供 inotifywait、inotifywatch 辅助工具程序,
用来监控、汇总改动情况。
inotifywait:可监控modify(修改)、create(创建)、move(移动)、delete(删除)、attrib(属性更改)等各种事件,
一有变动立即输出结果。
inotifywatch:可用来收集文件系统变动情况,并在运行结束后输出汇总的变化情况。
##tar zxvf inotify-tools-3.14.tar.gz -C /opt/
[root@test4 opt]# rz -E
rz waiting to receive.
[root@test4 opt]# ls
inotify-tools-3.14.tar.gz jenkins-2.396-1.1.noarch.rpm test
[root@test4 opt]# tar -xf inotify-tools-3.14.tar.gz
[root@test4 opt]# yum -y install make
[root@test4 opt]# cd inotify-tools-3.14/
[root@test4 inotify-tools-3.14]# ./config
config.guess config.sub configure
[root@test4 inotify-tools-3.14]# ./configure
[root@test4 inotify-tools-3.14]# make -j 2
[root@test4 opt]# mkdir xy102
[root@test4 opt]# chmod 777 xy102
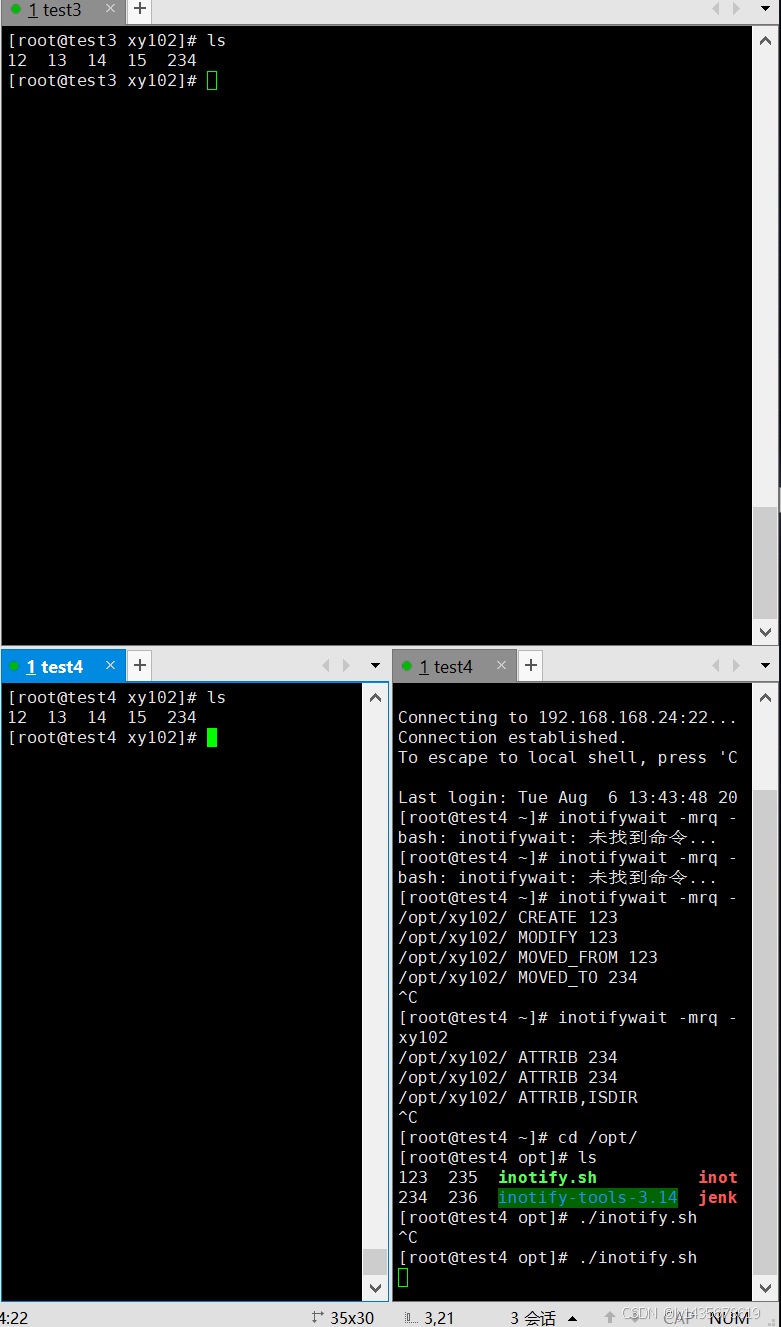
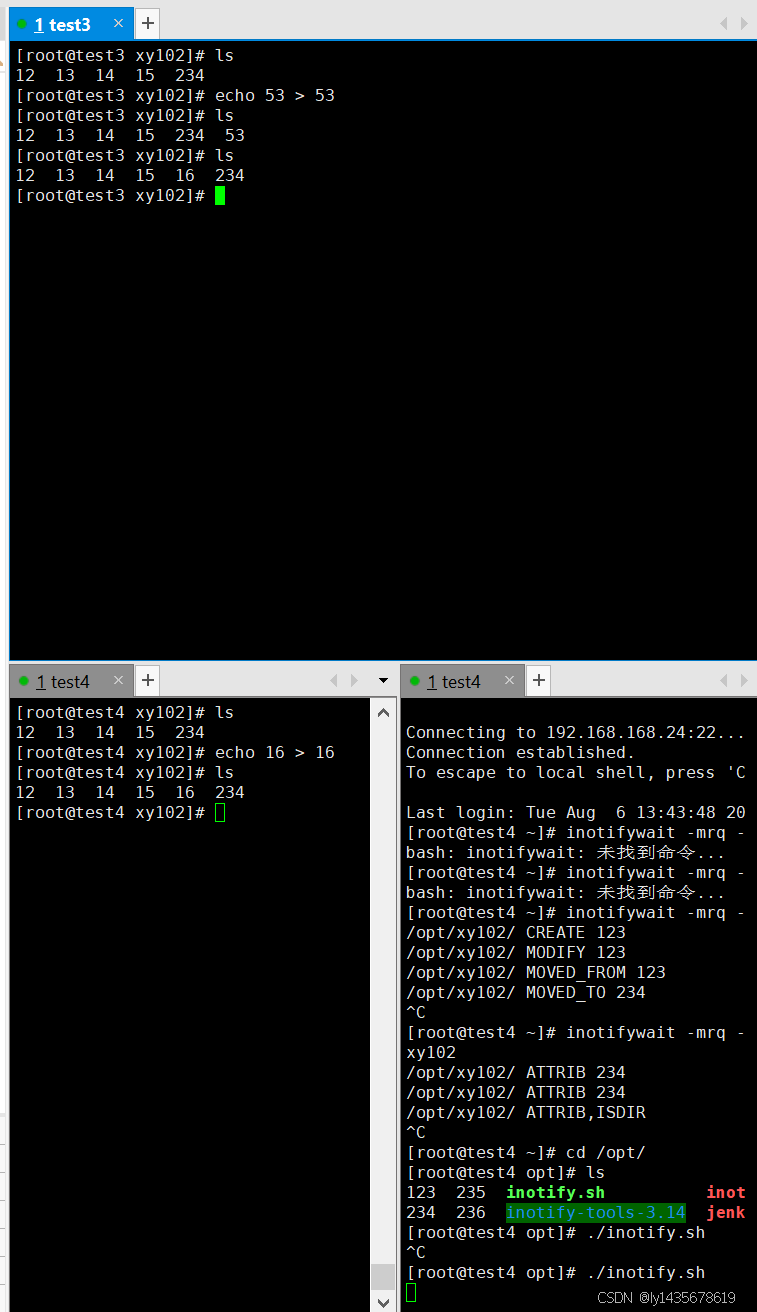
[root@test4 ~]# inotifywait -mrq -e modify,create,move,delete /opt/xy102
bash: inotifywait: 未找到命令...
yum install -y inotify-tools ##安装inotify管理工具
[root@test4 ~]# inotifywait -mrq -e modify,create,move,delete /opt/xy102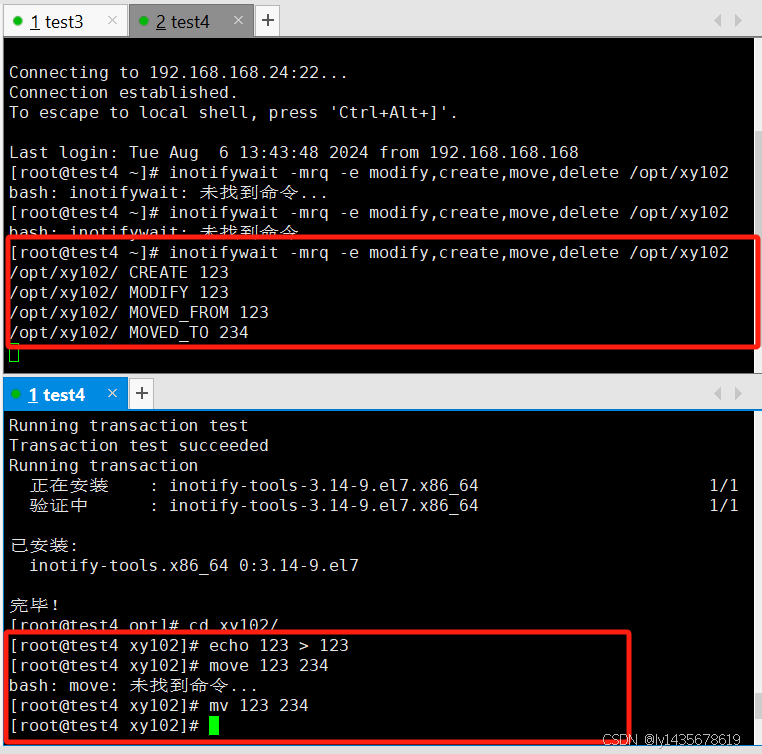
#可以先执行"inotifywait"命令,然后另外再开启一个新终端向 /opt/xy102 目录下添加文件、移动文件,
在原来的终端中跟踪屏幕输出结果。
inotifywait -mrq -e modify,create,move,delete /opt/test
#选项"-e":用来指定要监控哪些事件
#选项"-m":表示持续监控
#选项"-r":表示递归整个目录
#选项"-q":简化输出信息
[root@test4 ~]# inotifywait -mrq -e modify,create,move,delete,attrib /opt/xy102
/opt/xy102/ ATTRIB 234
/opt/xy102/ ATTRIB 234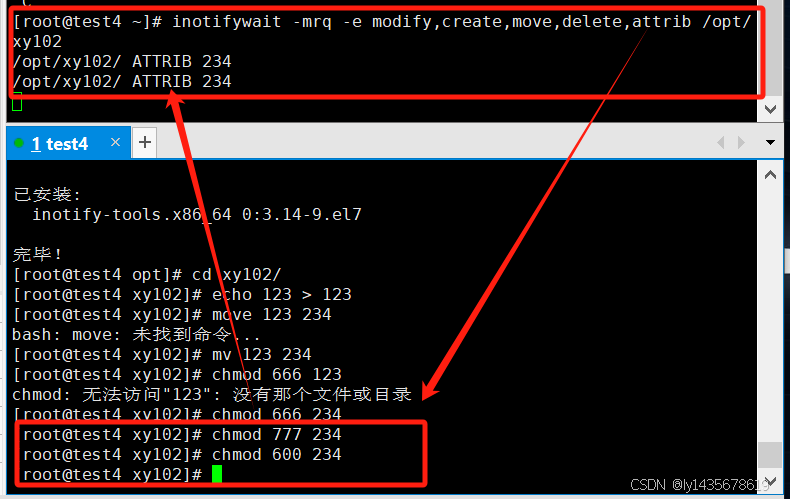
4.在另外一个终端(客户端)编写触发式同步脚本(注意,脚本名不可包含 rsync 字符串,否则脚本不生效),目的实现上传文件到服务端
vim /opt/inotify.sh
#!/bin/bash
INOTIFY_CMD="inotifywait -mrq -e modify,create,attrib,move,delete /opt/xy102"
RSYNC_CMD="rsync -azH --delete --password-file=/etc/server.pass /opt/xy102 backuper@192.168.168.23::test/"
$INOTIFY_CMD | while read DIRECTORY EVENT FILE
##while判断是否接收到监控记录
do
if [ $(pgrep rsync | wc -l) -le 0 ] ; then
$RSYNC_CMD
fi
done
-----------------理解----------------------------
--delete
A
/opt/test 1 2 3
B
/opt/xy102 4 5 6
保持A B相同
--delete删除1 2 3 删除(两边的内容完全一致)
----------------------------------------------------------------
chmod +x /opt/inotify.sh
chmod 777 /opt/xy102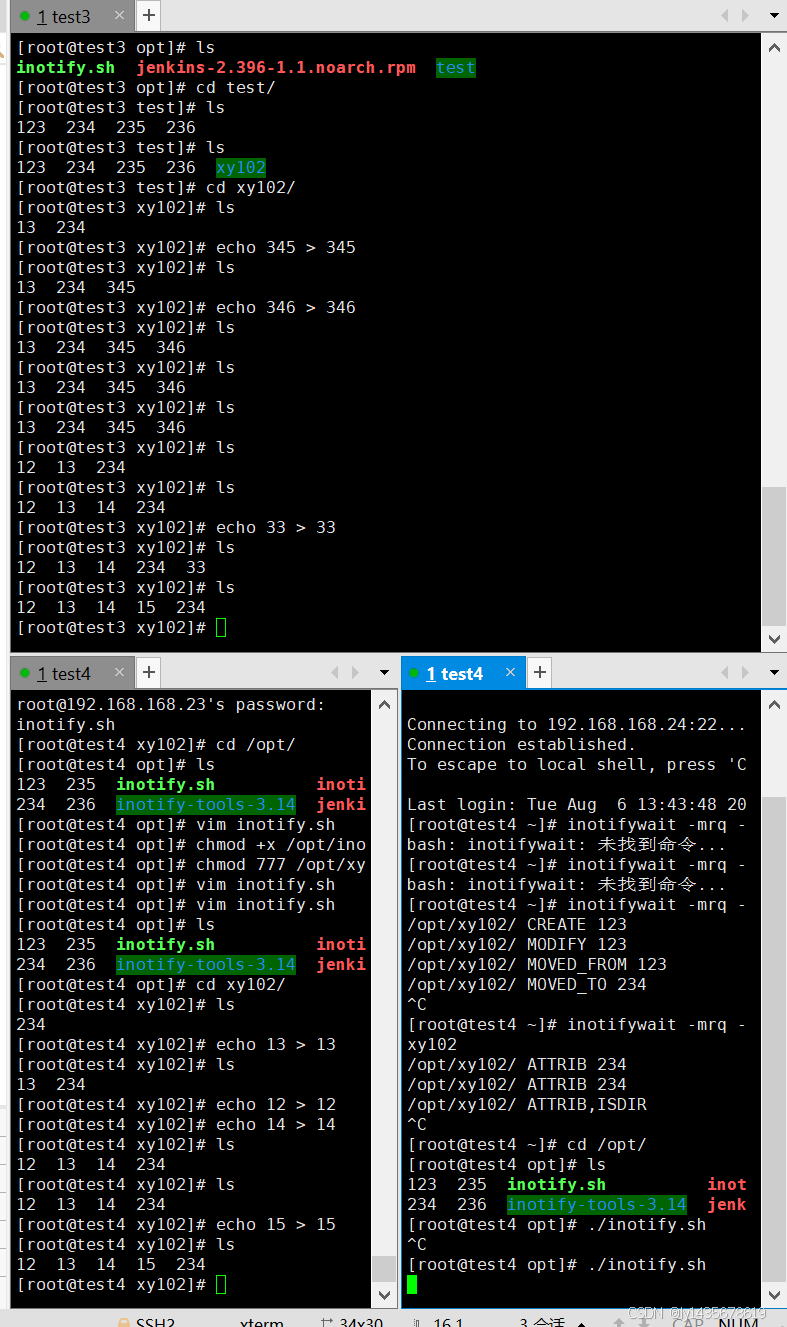
--------------------------------------------------以下有空可以了解--------------------------------------------------------
chmod +x /etc/rc.d/rc.local
echo '/opt/inotify.sh' >> /etc/rc.d/rc.local #加入开机自动执行
上述脚本用来检测本机/opt/data 目录的变动情况,一旦有更新触发 rsync 同步操作,上传备份至服务器 192.168.233.10 的test模块共享目录下。
触发式上行同步的验证过程如下:
(1)在本机运行 /opt/inotify.sh 脚本程序。
(2)切换到本机的 /var/www/html 目录,执行增加、删除、修改文件等操作。
(3)查看远端服务器中的 wwwroot 目录下的变化情况。
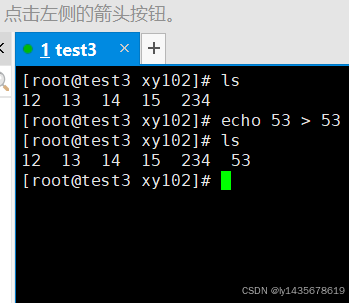
#快速删除大量文件:
rsync --delete-before -a -H -v --progress --stats /home/blank/ /opt/test1/
执行这个命令后,目标目录 /opt/test1 中所有不在源目录 /home/blank 中的文件和目录将被删除,
源目录中的所有文件将被同步到目标目录中。
选项说明:
--delete-before 接收者在传输进行删除操作
-a 归档模式,表示以递归方式传输文件,并保持所有文件属性
-H 保持硬连接的文件
-v 详细输出模式
--progress 在传输时显示传输过程
--stats 给出某些文件的传输状态
//使用rsync来实现快速删除大量文件。
假如要在linux下删除大量文件,比如100万、1000万,像/usr/local/nginx/proxy_temp的nginx缓存等,那么rm -rf * 可能就不好使了,因为要等待很长一段时间。在这种情况下我们可以使用rsync来巧妙处理。rsync实际用的是替换原理。
先建立一个空的文件夹:
mkdir /home/blank
用rsync删除目标目录:
rsync --delete-before -a -H -v --progress --stats /home/blank /usr/local/nginx/proxy_temp
这样目标目录很快就被清空了
选项说明:
--delete-before 接收者在传输进行删除操作
-a 归档模式,表示以递归方式传输文件,并保持所有文件属性
-H 保持硬连接的文件
-v 详细输出模式
--progress 在传输时显示传输过程
--stats 给出某些文件的传输状态在传输进行删除操作
-a 归档模式,表示以递归方式传输文件,并保持所有文件属性
-H 保持硬连接的文件
-v 详细输出模式
--progress 在传输时显示传输过程
--stats 给出某些文件的传输状态
//使用rsync来实现快速删除大量文件。
假如要在linux下删除大量文件,比如100万、1000万,像/usr/local/nginx/proxy_temp的nginx缓存等,那么rm -rf * 可能就不好使了,因为要等待很长一段时间。在这种情况下我们可以使用rsync来巧妙处理。rsync实际用的是替换原理。
先建立一个空的文件夹:
mkdir /home/blank
用rsync删除目标目录:
rsync --delete-before -a -H -v --progress --stats /home/blank /usr/local/nginx/proxy_temp
这样目标目录很快就被清空了
选项说明:
--delete-before 接收者在传输进行删除操作
-a 归档模式,表示以递归方式传输文件,并保持所有文件属性
-H 保持硬连接的文件
-v 详细输出模式
--progress 在传输时显示传输过程
--stats 给出某些文件的传输状态
---------------------------------------------------------------------------------------------------------------------------------