文章目录
- 一、概念
-
-
-
- 使用B+树不用B树和二叉查找树做索引:
- [MyISAM 和 InnoDB 的区别](#MyISAM 和 InnoDB 的区别)
- 判断是否使用索引
- 索引失效的几种情况
-
-
- 二、索引操作
一、概念
索引会可以提高查询速度,但是会增加大量的IO。数据库服务端本质是一个进程,所以是在内存中,而数据库文件本质是保存在内存当中,对数据操作都是在内存中进行的。
- B+ 树索引 原理是多路平衡查找树,每一次的查询都是从根节点出发,查询到叶子节点获得所查键值,查询判断是否需要回表,查询效率比较稳定,不需要回表.
- Hash 索引 底层就是 Hash 表,进行查询时调用 Hash 函数获取到相应的键值(对应地址),然后回表查询获得实际数据,避免不了回表查询数据.
使用B+树不用B树和二叉查找树做索引:
B+ 树的非叶子结点只存关键字不存数据,单个页可以存储更多的关键字, I/O 读取次数相对就减少,查找效率稳定
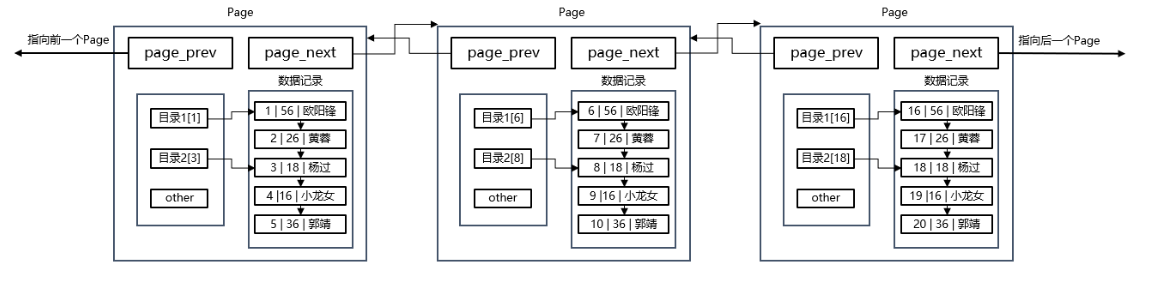
MySQL与磁盘交互的基本单位是16KB,叫做page,文件数据是以page为单位保存在磁盘当中,所以进行数据交互需要IO,为提升效率要减少IO的使用。
IO交互使用的是page,不用page查5条数据要调用5次IO,用page只要调用一次IO,之后要查的数据直接在内存中进行,采用的是B+树。
单个page,内部数据会按照主键进行排序
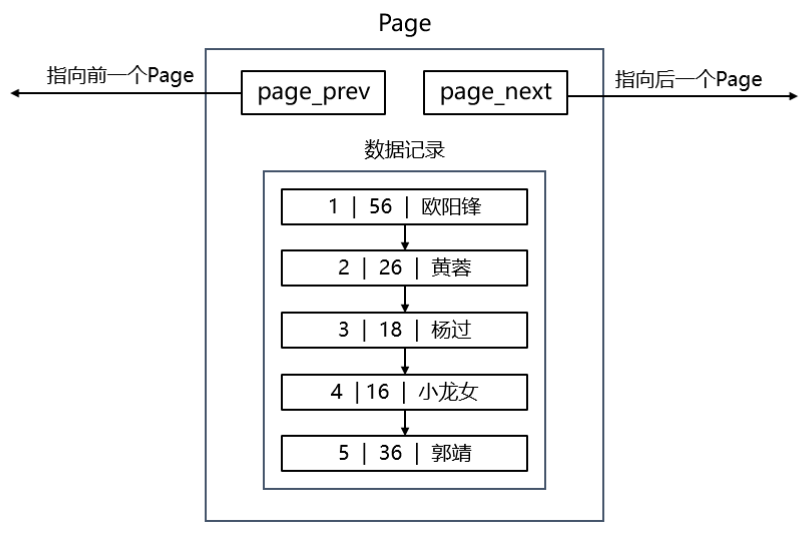
单个Page内创建页内目录
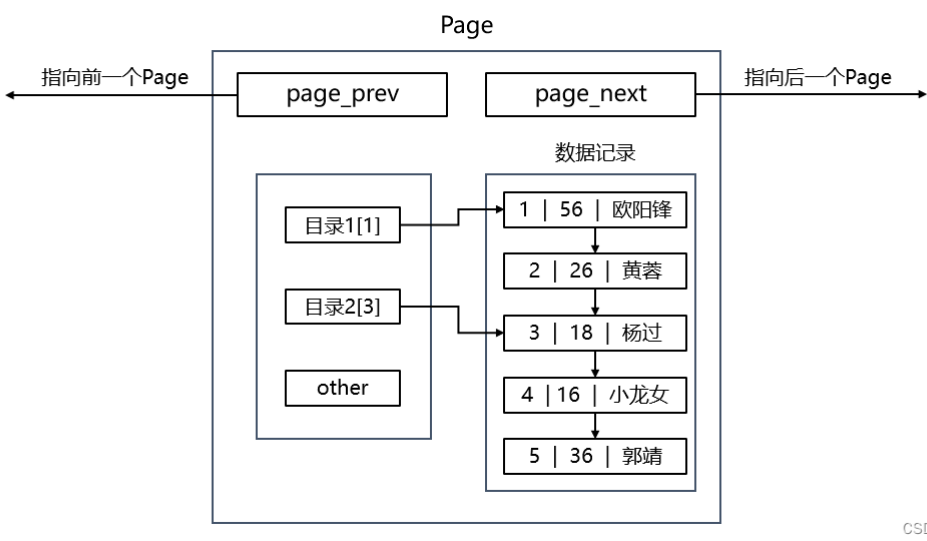
多个Page
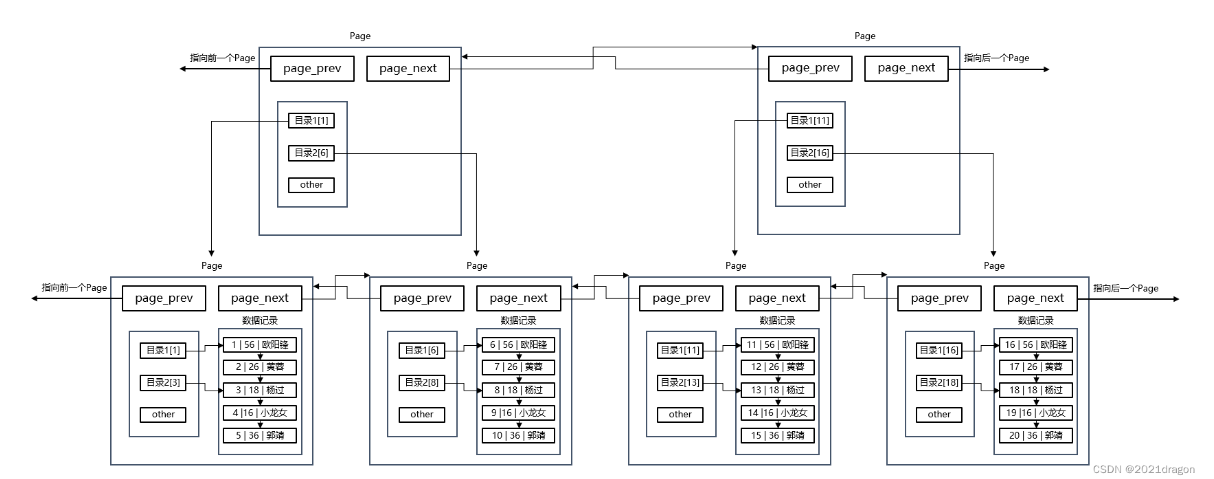
Page之上创建页目录
MyISAM 和 InnoDB 的区别
- InnoDB 支持事务,而 MyISAM 不支持
- 聚簇索引: 像InnoDB存储引擎这种,将数据记录与索引结构放在一起的索引方案,两个文件,叫做聚簇索引。
- 非聚簇索引: 像MyISAM存储引擎这种,将数据记录与索引结构分离的索引方案,三个文件,叫做非聚簇索引。
判断是否使用索引
只需在查询语句开头增加 EXPLAIN 这个关键字
索引失效的几种情况
- like 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效
- or 语句前后没有同时使用索引。当 or 左右查询字段只有一个是索引,该索引失效,只有左右查询字段均为索引时,才会生效
二、索引操作
1.主键索引-PRI
- 一个表中,最多只能有一个主键索引。
- 主键索引的引用率高。
- 主键索引的列一般是数字类型。
三种创建方式
//创建表的时候,直接在列名后指定 primary key
create table user1(
id int primary key,
name varchar(30)
);
//创建表的最后,指定某列或某几列为主键索引
create table user2(
id int,
name varchar(30),
primary key(id)
);
//创建表以后再添加主键
alter table user3 add primary key(id);2.唯一索引-UNI
-
一个表中,可以有多个唯一索引
-
如果在某一列建立唯一索引,必须保证这列不能有重复数据
-
如果一个唯一索引上指定not null,等价于主键索引
-
和普通索引一样
//表定义时,在某列后直接指定unique唯一属性。
create table user4(
id int primary key,
name varchar(30) unique
);
//创建表时,在表的后面指定某列或某几列为unique
create table user5(
id int primary key,
name varchar(30),
unique(name)
);
//创建表以后再添加唯一键
alter table user6 add unique(name);
3.普通索引-MUL
-
一个表中可以有多个普通索引
-
该列有重复的值,使用普通索引
-
和唯一索引一样
//在表的定义最后,指定某列为索引
create table user8(id int primary key,
name varchar(20),
email varchar(30),
index(name)
);
//创建完表以后指定某列为普通索引
alter table user9 add index(name);
//创建一个索引名为 idx_name 的索引
create index idx_name on user10(name);
4.全文索引
存储引擎必须是MyISAM,使用match(列1) against (关键字)
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,//内容很大
FULLTEXT (title,body)
)engine=MyISAM;
select * from articles where match(title,body) against ('database');//查询哪些文章中包含database关键字5.查询索引
show index from 表名\G;//加\G是方便看
show keys from 表名\G;
desc 表名;6.删除索引
alter table 表名 drop primary key;//删除主键索引
alter table 表名 drop index 索引名;//删除非主键索引7.索引创建原则
- 比较频繁作为查询条件的字段应该创建索引。
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件。
- 更新非常频繁的字段不适合创建索引。
- 不会出现在where子句中的字段不应该创建索引。