前一阵介绍的使用 DeepSeek-R1 部署的 7b 模型,在电脑本地进行 RAG 问答的简单演示项目,目前收获了 72 个 star,下方视频演示了下升级后的支持多文档上传和多轮问答的功能特性。
参考文章:
无需联网!DeepSeek-R1+本地化RAG,打造私有智能文档助手
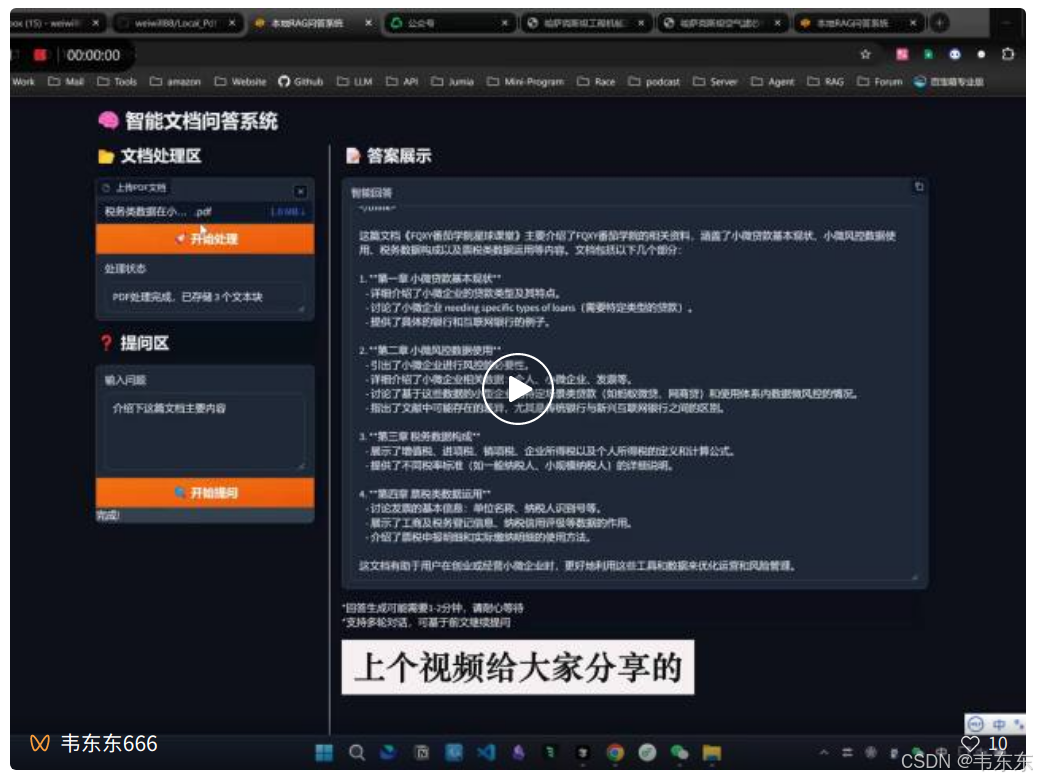
视频链接:https://mp.weixin.qq.com/s/QdVAJRsvnecbgzXYJ0tMOQ
需要说明是,因为只是一个演示项目,大家在测试不同领域的专属文档问答时,效果不一定符合预期。
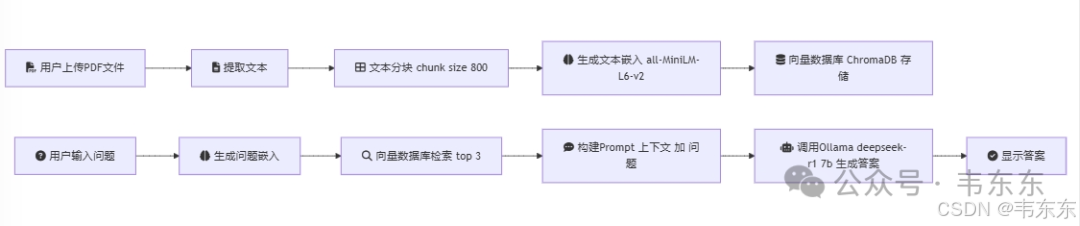
当前核心代码流程
根据个人有限经验,提供以下六个关键的技术优化路径供参考,各位可以根据具体的应用场景和资源限制,选择合适的优化方向进行实施。

优化后代码逻辑(基于六点优化建议)
每个优化点都可以独立实现和评估,建议先从影响最大的方向开始:
首先,优化文本分块策略和实现混合检索;
然后,添加 Re-ranking 机制;
最后,考虑引入知识图谱等更复杂的优化。
1、 文本分块优化
现有问题:目前使用的是固定大小的分块策略(chunk_size=800),这可能会切分到语义完整的段落
优化建议:
实现语义感知的分块策略,基于段落、章节等自然边界进行分割可以使用基于滑动窗口的动态分块引入重叠度自适应调整,对于语义密集的部分增加重叠
python
# 示例:基于语义的分块策略
from langchain.text_splitter import SpacyTextSplitter
# 或使用更轻量的
from nltk.tokenize import sent_tokenize
def semantic_chunk(text):
sentences = sent_tokenize(text)
chunks = []
current_chunk = []
current_length = 0
for sentence in sentences:
if current_length + len(sentence) > 800:
chunks.append(" ".join(current_chunk))
current_chunk = [sentence]
current_length = len(sentence)
else:
current_chunk.append(sentence)
current_length += len(sentence)
if current_chunk:
chunks.append(" ".join(current_chunk))
return chunks2、检索增强
现有问题:目前只使用向量相似度检索,可能会遗漏一些语义相关但表达不同的内容
优化建议:
实现混合检索:结合关键词检索(BM25)和向量检索添加 Re-ranking 层:使用交叉编码器对检索结果重新排序引入 MMR(Maximum Marginal Relevance)降低结果冗余度
python
from rank_bm25 import BM25Okapi
from sentence_transformers import CrossEncoder
def hybrid_search(query, documents, top_k=5):
# BM25检索
bm25 = BM25Okapi(documents)
bm25_scores = bm25.get_scores(query)
# 向量检索(你现有的方案)
vector_results = COLLECTION.query(...)
# 结果融合
combined_results = combine_scores(bm25_scores, vector_results)
# Cross-Encoder重排序
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
reranked_results = cross_encoder.predict([(query, doc) for doc in combined_results])
return sorted(zip(combined_results, reranked_results), key=lambda x: x[1], reverse=True)[:top_k]3、知识图谱增强
现有问题:缺乏文档间的结构化关联信息
优化建议:
构建文档级知识图谱,捕获文档间的关系提取实体和关系,建立三元组知识库在检索时结合图谱关系进行扩展查询
python
from spacy import displacy
import networkx as nx
def build_knowledge_graph():
# 实体提取
entities = extract_entities(documents)
# 关系抽取
relationships = extract_relationships(documents)
# 构建图谱
G = nx.Graph()
for entity in entities:
G.add_node(entity)
for rel in relationships:
G.add_edge(rel[0], rel[2], relation=rel[1])
return G
def graph_enhanced_search(query, graph):
# 基于图谱进行查询扩展
related_entities = get_related_entities(query, graph)
expanded_query = expand_query(query, related_entities)
return search(expanded_query)4、上下文优化
现有问题:检索的上下文可能不完整或包含无关信息
优化建议:
实现动态上下文窗口添加上下文相关性打分引入文档结构感知的上下文选择
python
def optimize_context(query, retrieved_chunks):
# 计算每个chunk的相关性分数
relevance_scores = calculate_relevance(query, retrieved_chunks)
# 动态调整上下文窗口
window_size = adaptive_window_size(relevance_scores)
# 合并相邻的相关chunk
merged_context = merge_relevant_chunks(retrieved_chunks, window_size)
return merged_context5、查询优化
现有问题:用户查询可能不够精确或存在歧义
优化建议:
实现查询改写和扩展添加查询意图识别引入查询建议机制
python
def optimize_query(original_query):
# 查询意图识别
intent = classify_intent(original_query)
# 查询改写
rewritten_query = rewrite_query(original_query, intent)
# 查询扩展
expanded_query = expand_query(rewritten_query)
return expanded_query6、评估与监控
现有问题:缺乏系统性能的评估指标
优化建议:
建立检索质量评估指标(MRR, NDCG 等)实现答案质量评估添加用户反馈机制
python
def evaluate_system(queries, ground_truth):
metrics = {
'mrr': calculate_mrr(queries, ground_truth),
'ndcg': calculate_ndcg(queries, ground_truth),
'precision': calculate_precision(queries, ground_truth)
}
return metrics(完)