网络爬虫是自动化获取网络信息的高效工具,Python因其强大的库支持和简洁的语法成为编写网络爬虫的首选语言。本教程将通过一个具体的案例(基于Microsoft Edge浏览器的简单爬取),指导你使用Python实现一个完整的网络爬虫,涵盖环境准备、网站爬取、数据处理及存储等环节,内容简单,适合小白。
目录
[1. Python与相关库安装](#1. Python与相关库安装)
[2.下载并配置Microsoft Edge WebDriver](#2.下载并配置Microsoft Edge WebDriver)
[3. 网络爬虫的基本概念与原理](#3. 网络爬虫的基本概念与原理)
[1. 打开浏览器并访问网站](#1. 打开浏览器并访问网站)
[2. 获取并打印网页标题](#2. 获取并打印网页标题)
[3. 提取并打印网页中的链接](#3. 提取并打印网页中的链接)
[4. 获取并打印网页源代码](#4. 获取并打印网页源代码)
[5. 提取并保存所有图片的URL](#5. 提取并保存所有图片的URL)
[1. 处理动态内容](#1. 处理动态内容)
[2. 处理JavaScript弹窗](#2. 处理JavaScript弹窗)
[3. 处理多种网页结构](#3. 处理多种网页结构)
[4. 处理网页爬取速度](#4. 处理网页爬取速度)
[5. 遵守法律和道德规范](#5. 遵守法律和道德规范)
[1. 电商网站价格监控](#1. 电商网站价格监控)
[2. 新闻聚合](#2. 新闻聚合)
[3. 社交媒体分析](#3. 社交媒体分析)
[4. 品牌声誉监控](#4. 品牌声誉监控)
Python爬虫新手指南及简单实战

一、环境准备与基本理论
在开始之前,确保你的计算机上安装了Python环境,并熟悉基本的Python语法。
1. Python与相关库安装
- Python : 访问Python官网下载并安装最新版本的Python。
- Pip: Python的包管理器,通常与Python一起安装。
- Requests : 用于发起网络请求。安装方法:
pip install requests。
- BeautifulSoup : 用于解析HTML文档。安装方法:
pip install beautifulsoup4。
- Selenium : 用于处理JavaScript渲染的页面。安装方法:
pip install selenium。
2.下载并配置Microsoft Edge WebDriver
Microsoft Edge WebDriver是用于Microsoft Edge浏览器的自动化测试工具,我们可以从这里下载适用于你的操作系统的WebDriver:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
下载完成后,将WebDriver解压到一个文件夹,并将该文件夹的路径添加到系统环境变量PATH中。
3. 网络爬虫的基本概念与原理
网络爬虫是一种自动获取网页内容的程序,其基本原理包括种子页面、链接抓取、内容分析以及链接跟踪等步骤。 而它的核心原理则基于超文本传输协议(HTTP)来获取网页资源。网络爬虫主要经历以下几个步骤:
- 种子页面 :
- 爬虫启动时需要一个或多个初始URL,这些被称为种子页面。
- 种子页面的选择对爬虫的起始方向有决定性作用。
- 通常,种子页面与爬取目标密切相关,以确保后续爬取内容的相关度。
- 链接抓取 :
- 爬虫通过访问种子页面,解析页面上的HTML代码,抓取其中的所有链接。
- 这些链接可能是内部链接,也可能是外部链接,它们为爬虫提供了进一步爬取的路径。
- 内容分析 :
- 爬虫会对抓取的每个页面进行内容分析,提取出有价值的信息,如文本、图片、视频等。
- 在分析过程中,可能涉及到网页内容的渲染、执行JavaScript代码以及解码加密数据等操作。
- 链接跟踪 :
- 提取出的链接会被加入到爬取队列中,爬虫会按照一定的策略跟踪这些链接,继续抓取新页面。
- 爬虫会根据设定的爬行策略,比如深度优先或广度优先策略,循环地进行爬取,直到满足停止条件。
- 数据存储 :
- 抓取到的数据会被存储到适当的位置,例如文件、数据库或其他存储系统中。
- 存储方式取决于数据类型及后续使用的需求,比如数据分析、信息检索或其他自动化任务。
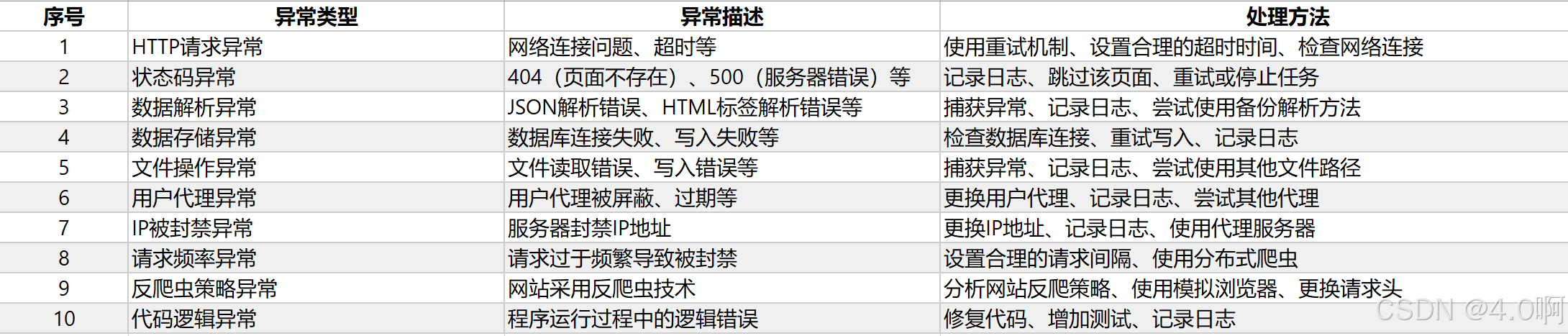
- 异常处理 :
- 在爬虫工作中会遇到各种异常情况,包括但不限于网络请求失败、页面解析错误、反爬机制等。
- 良好的异常处理机制能够保证爬虫稳定运行,比如通过重试、延时、代理切换等方式应对不同的异常。
二、实战案例:简单爬取获取信息
在这部分,我们将通过Microsoft Edge浏览器爬取某些网站上更多的信息,并展示如何提取这些信息。
1. 打开浏览器并访问网站
首先,我们需要启动Edge浏览器并打开目标网站。
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 创建一个Microsoft Edge浏览器实例
driver = webdriver.Edge(executable_path="<你的Microsoft Edge WebDriver路径>")
# 访问目标网站
url = "网站"
driver.get(url)
# 等待页面加载完成
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.TAG_NAME, "body")))2. 获取并打印网页标题
接下来,我们将获取网页的标题并打印出来。
python
# 获取网页标题
title = driver.title
print("网页标题:", title)3. 提取并打印网页中的链接
我们可以使用selenium来定位所有的链接元素,并打印出它们的URL和文本。
python
# 找到页面中的所有链接
links = driver.find_elements(By.TAG_NAME, "a")
# 遍历链接并打印
for link in links:
link_text = link.text
link_url = link.get_attribute('href')
print(f"链接文本:{link_text} | 链接地址:{link_url}")4. 获取并打印网页源代码
最后,我们可以获取整个网页的源代码,这在需要查找特定元素或进行更复杂操作时非常有用。
python
# 获取网页源代码
page_source = driver.page_source
print("网页源代码:", page_source)
# 关闭浏览器
driver.quit()5. 提取并保存所有图片的URL
假设我们想要提取网页上所有图片的URL并保存。
python
# 找到页面中的所有图片
images = driver.find_elements(By.TAG_NAME, "img")
# 创建一个列表来保存图片的URL
image_urls = []
# 遍历图片并获取它们的URL
for image in images:
image_url = image.get_attribute('src')
image_urls.append(image_url)
# 打印图片的URL
for url in image_urls:
print("图片链接:", url)
# 保存图片URL到文件(可选)
with open('image_urls.txt', 'w') as file:
for url in image_urls:
file.write(url + '
')6.注意事项
通过上述代码,我们不仅爬取了网站的标题,还提取了网页中的所有链接和图片URL。这些数据可以用于进一步分析或保存为后期使用,同时在上述代码中,需要将<你的Microsoft Edge WebDriver路径>替换为您实际下载并解压的Microsoft Edge WebDriver的路径。例如,如果您将其保存在C:\webdrivers\msedgedriver.exe,则应将代码中的<你的Microsoft Edge WebDriver路径>替换为"C:\\webdrivers\\msedgedriver.exe"。
此外,您还可以根据需要修改目标网站的URL。在示例代码中,我们使用了"网站"作为目标网站。你需要将他替换为你想要爬取的任何其他网站的URL。
代码简单讲解:
- 导入所需的库和模块。
- 创建一个Microsoft Edge浏览器实例,并指定WebDriver的路径。
- 访问目标网站。
- 等待页面加载完成。
- 获取网页标题并打印。
- 提取网页中的所有链接,并打印它们的文本和URL。
- 获取网页源代码并打印。
- 关闭浏览器实例。
- 可选:提取网页上所有图片的URL并保存到文件中。
三、进阶技巧与问题处理
在进行网页爬取时,我们可能会遇到各种问题,如网页结构变化、动态内容加载等。本节将介绍一些进阶技巧和常见问题的处理方法。
1. 处理动态内容
有时,网页上的内容是通过JavaScript动态加载的。selenium可以处理这种情况,因为它会模拟浏览器操作,等待JavaScript执行完成后再进行爬取。但在某些情况下,如果页面加载时间过长,我们可能需要手动设置一个等待时间。
python
# 设置显式等待时间
wait = WebDriverWait(driver, 20)
element = wait.until(EC.presence_of_element_located((By.ID, "someId")))2. 处理JavaScript弹窗
有些网站在爬取过程中可能会弹出JavaScript对话框,这可能会中断爬取过程。我们可以使用selenium来接受或取消这些弹窗。
python
# 接受警告框
driver.switch_to.alert.accept()
# 取消警告框
driver.switch_to.alert.dismiss()3. 处理多种网页结构
不同的网页可能有不同的布局和结构。在定位元素时,我们需要根据实际的网页结构来选择最适合的定位方式。例如,如果我们无法通过ID定位元素,可以尝试使用其他方式,如类名、XPath等。
python
# 通过类名定位元素
elements = driver.find_elements_by_class_name("someClassName")
# 通过XPath定位元素
element = driver.find_element_by_xpath("//some/xpath/selector")4. 处理网页爬取速度
在爬取大量数据时,速度可能成为一个问题。我们可以使用多线程或异步的方式来提高爬取速度。此外,适当设置延时,模拟人类浏览行为,也可以减少被网站封禁的风险。
python
# 设置延时
time.sleep(2)5. 遵守法律和道德规范
在进行网页爬取时,我们必须遵守相关的法律法规和道德规范。确保我们的行为合法,并且不会侵犯网站的版权或其他权利。此外,我们还应该尊重网站的robots.txt文件,该文件指定了哪些页面可以被爬取,哪些不可以。

通过掌握这些进阶技巧,我们可以更有效地处理网页爬取过程中的各种问题,并确保我们的爬虫程序能够稳定、高效地运行。
四、实际案例的高阶应用
在掌握了基础和进阶技巧之后,我们来看看一些具体的实际案例,这些案例展示了如何运用我们到目前为止学到的技术来解决实际问题。
1. 电商网站价格监控
许多电商网站会定期更改商品价格。我们可以创建一个爬虫来监控特定商品的价格变动,并在价格低于某个阈值时发送通知。
python
# 假设我们正在监控一个具有特定ID的商品
product_price = driver.find_element_by_id("productPrice").text
if float(product_price) < price_threshold:
# 发送通知的代码
send_notification("Price dropped below threshold!")2. 新闻聚合
我们可以创建一个聚合器,从多个新闻网站抓取最新的新闻报道,并将这些信息汇总到一个单一的界面中。
python
# 爬取新闻标题和链接
news_headlines = driver.find_elements_by_class_name("newsHeadline")
for headline in news_headlines:
news_title = headline.text
news_link = headline.get_attribute('href')
# 保存或显示新闻标题和链接3. 社交媒体分析
使用爬虫技术,我们可以分析社交媒体上的趋势,例如跟踪特定话题的热度或情绪。
python
# 收集关于特定话题的推文
tweets = driver.find_elements_by_css_selector(".tweet")
for tweet in tweets:
tweet_text = tweet.text
# 分析推文情绪或保存数据4. 品牌声誉监控
通过监控论坛、评论和社交媒体,企业可以了解自己的品牌在公众中的形象,并及时响应可能的问题。
python
# 收集品牌相关的评论
comments = driver.find_elements_by_xpath("//div[contains(text(), '品牌名称')]/following-sibling::div")
for comment in comments:
comment_text = comment.text
# 分析或保存评论通过这些实际的案例,我们可以看到网络爬虫技术在解决现实问题中的广泛应用。每一个案例都需要对基础知识的深入理解和应用,以及对进阶技巧的灵活使用。希望通过这些实例,您能找到解决问题的灵感,并将其应用到您的项目中去。
五、总结
在本文中,我们全面介绍了使用Python和Microsoft Edge浏览器进行网页爬取的过程,从环境准备到编写爬虫代码,再到进阶技巧与问题处理,最后通过实际案例展示了爬虫技术的应用。我们强调了安装selenium库和配置Microsoft Edge WebDriver的重要性,并逐步介绍了如何使用selenium库编写简单的爬虫代码,包括打开浏览器、访问网页、获取网页标题、提取链接和图片等操作。此外,我们还讨论了如何处理动态内容加载、JavaScript弹窗、不同的网页结构以及提高爬取速度等进阶技巧。通过电商价格监控、新闻聚合、社交媒体分析、竞争对手分析和品牌声誉监控等案例,我们展示了爬虫技术在实际应用中的多样性和潜力。总之,网络爬虫技术是一个强大而复杂的领域,需要我们不断学习和实践,以便充分利用Python和Microsoft Edge浏览器的功能,从互联网上获取有价值的数据。希望本文能为您的网络爬虫之旅提供一个坚实的起点,并助您在实际项目中取得成功。