最近在某个金融单位核心系统项目做ob的性能压测,期间遇到不少问题,现场两周了每天都加班到凌晨一两点左右,真的是累死。🤢🤢
我其实进ob之前有心理预期,卷就卷吧,八九点下班也能接受,没想到真到了干项目的情况下,天天凌晨下班,真怕不知道啥时候会猝死。😂😂
ob被挺多人诟病的是gv$ob_sql_audit视图,如果有大量的事物在数据库里面执行,这个视图保存的内容很快就会被刷掉,而且做查询分析速度非常慢,随便一条加个谓词过滤的语句估计都要执行个几分钟才能出结果,很难分析出业务接口到底是哪个事物的SQL缓慢。
虽然可以通过ob_sql_audit_percentage参数调大gvob_sql_audit视图保存的内容,但是如果连续的高并发压测情况下,一样也会把里面的内容很快刷新,所以我们需要将gvob_sql_audit数据持久化到数据表里面,添加合适的索引用来分析server层不同场景业务接口的sql语句,到底慢在哪个环节,来进行针对性的调优。
所以我到了现场了解情况以后,花半天时间编写和调试extract_sqlaudit_proc这个存储过程来帮我抓server层的数据,这个过程后续帮我分析不同场景的性能问题省了很多功夫。
1、xz_sql_audit表、extract_sqlaudit_proc 过程代码
重点提示:这个方案仅在oracle 租户上使用。
sql
-- 创建分析表
CREATE TABLE XZ_SQL_AUDIT(
C_ID NUMBER(38), -- 唯一ID
C_RQ_TIME TIMESTAMP, -- 请求时间
C_BATCH_ID NUMBER(38), -- 插入批次
C_NAME VARCHAR2(100), -- 场景名称
C_FLAG CHAR(2), -- s 为拉取单个事务,m 为拉取多个事务(压测)
SVR_IP VARCHAR2(46) ,
SVR_PORT NUMBER(38) ,
REQUEST_ID NUMBER(38) ,
SQL_EXEC_ID NUMBER(38) ,
TRACE_ID VARCHAR2(128) ,
SID NUMBER(38) ,
CLIENT_IP VARCHAR2(46) ,
CLIENT_PORT NUMBER(38) ,
TENANT_ID NUMBER(38) ,
EFFECTIVE_TENANT_ID NUMBER(38) ,
TENANT_NAME VARCHAR2(64) ,
USER_ID NUMBER(38) ,
USER_NAME VARCHAR2(64) ,
USER_GROUP NUMBER(38) ,
USER_CLIENT_IP VARCHAR2(46) ,
DB_ID NUMBER(38) ,
DB_NAME VARCHAR2(128) ,
SQL_ID VARCHAR2(32) ,
QUERY_SQL CLOB ,
PLAN_ID NUMBER(38) ,
AFFECTED_ROWS NUMBER(38) ,
RETURN_ROWS NUMBER(38) ,
PARTITION_CNT NUMBER(38) ,
RET_CODE NUMBER(38) ,
QC_ID NUMBER(38) ,
DFO_ID NUMBER(38) ,
SQC_ID NUMBER(38) ,
WORKER_ID NUMBER(38) ,
EVENT VARCHAR2(64) ,
P1TEXT VARCHAR2(64) ,
P1 NUMBER(38) ,
P2TEXT VARCHAR2(64) ,
P2 NUMBER(38) ,
P3TEXT VARCHAR2(64) ,
P3 NUMBER(38) ,
WAIT_CLASS_ID NUMBER(38) ,
WAIT_CLASS# NUMBER(38) ,
WAIT_CLASS VARCHAR2(64) ,
STATE VARCHAR2(19) ,
WAIT_TIME_MICRO NUMBER(38) ,
TOTAL_WAIT_TIME_MICRO NUMBER(38) ,
TOTAL_WAITS NUMBER(38) ,
RPC_COUNT NUMBER(38) ,
PLAN_TYPE NUMBER(38) ,
IS_INNER_SQL NUMBER(38) ,
IS_EXECUTOR_RPC NUMBER(38) ,
IS_HIT_PLAN NUMBER(38) ,
REQUEST_TIME NUMBER(38) ,
ELAPSED_TIME NUMBER(38) ,
NET_TIME NUMBER(38) ,
NET_WAIT_TIME NUMBER(38) ,
QUEUE_TIME NUMBER(38) ,
DECODE_TIME NUMBER(38) ,
GET_PLAN_TIME NUMBER(38) ,
EXECUTE_TIME NUMBER(38) ,
APPLICATION_WAIT_TIME NUMBER(38) ,
CONCURRENCY_WAIT_TIME NUMBER(38) ,
USER_IO_WAIT_TIME NUMBER(38) ,
SCHEDULE_TIME NUMBER(38) ,
ROW_CACHE_HIT NUMBER(38) ,
BLOOM_FILTER_CACHE_HIT NUMBER(38) ,
BLOCK_CACHE_HIT NUMBER(38) ,
DISK_READS NUMBER(38) ,
RETRY_CNT NUMBER(38) ,
TABLE_SCAN NUMBER(38) ,
CONSISTENCY_LEVEL NUMBER(38) ,
MEMSTORE_READ_ROW_COUNT NUMBER(38) ,
SSSTORE_READ_ROW_COUNT NUMBER(38) ,
DATA_BLOCK_READ_CNT NUMBER(38) ,
DATA_BLOCK_CACHE_HIT NUMBER(38) ,
INDEX_BLOCK_READ_CNT NUMBER(38) ,
INDEX_BLOCK_CACHE_HIT NUMBER(38) ,
BLOCKSCAN_BLOCK_CNT NUMBER(38) ,
BLOCKSCAN_ROW_CNT NUMBER(38) ,
PUSHDOWN_STORAGE_FILTER_ROW_CNT NUMBER(38) ,
REQUEST_MEMORY_USED NUMBER(38) ,
EXPECTED_WORKER_COUNT NUMBER(38) ,
USED_WORKER_COUNT NUMBER(38) ,
SCHED_INFO VARCHAR2(16384) ,
PS_CLIENT_STMT_ID NUMBER(38) ,
PS_INNER_STMT_ID NUMBER(38) ,
TX_ID NUMBER(38) ,
SNAPSHOT_VERSION NUMBER(38) ,
REQUEST_TYPE NUMBER(38) ,
IS_BATCHED_MULTI_STMT NUMBER(38) ,
OB_TRACE_INFO VARCHAR2(4096) ,
PLAN_HASH NUMBER(38) ,
PARAMS_VALUE CLOB ,
RULE_NAME VARCHAR2(256) ,
TX_INTERNAL_ROUTING NUMBER ,
TX_STATE_VERSION NUMBER(38) ,
FLT_TRACE_ID VARCHAR2(1024) ,
NETWORK_WAIT_TIME NUMBER(38),
PRIMARY KEY(C_ID,C_BATCH_ID))
PARTITION BY RANGE(C_BATCH_ID)
(
PARTITION P10 VALUES LESS THAN (10),
PARTITION P20 VALUES LESS THAN (20),
PARTITION P30 VALUES LESS THAN (30),
PARTITION P40 VALUES LESS THAN (40),
PARTITION P50 VALUES LESS THAN (50),
PARTITION P60 VALUES LESS THAN (60),
PARTITION P70 VALUES LESS THAN (70),
PARTITION P80 VALUES LESS THAN (80),
PARTITION P90 VALUES LESS THAN (90),
PARTITION P100 VALUES LESS THAN (100),
PARTITION P110 VALUES LESS THAN (110),
PARTITION P120 VALUES LESS THAN (120),
PARTITION P130 VALUES LESS THAN (130),
PARTITION P140 VALUES LESS THAN (140),
PARTITION P150 VALUES LESS THAN (150),
PARTITION P160 VALUES LESS THAN (160),
PARTITION P170 VALUES LESS THAN (170),
PARTITION P180 VALUES LESS THAN (180),
PARTITION P190 VALUES LESS THAN (190),
PARTITION P200 VALUES LESS THAN (200)
);
sql
CREATE OR REPLACE PROCEDURE extract_sqlaudit_proc(
P_NAME VARCHAR2,
p_FLAG CHAR,
P_START_TIME VARCHAR2, -- 开始时间
p_END_TIME VARCHAR2 -- 结束时间
)
/*
extract_sqlaudit_proc
作者:小至尖尖
时间:2024-08-01
用途:用于拉取gv$ob_sql_audit视图数据
*/
IS
V_NAME VARCHAR2(100) := UPPER(P_NAME); -- 场景名称
V_FLAG CHAR(2) := UPPER(p_FLAG); -- s 为拉取单个事务,m 为拉取多个事务(压测),
V_MAX_BATCH INT;
V_START_TIME VARCHAR2(100) := P_START_TIME; --开始时间
V_END_TIME VARCHAR2(100) := p_END_TIME; --结束时间
/*
V_NAME:场景名称
V_FLAG:S为拉取单个事务,M为拉取多个事务(压测)
V_MAX_BATCH:记录批次数
*/
V_SQL VARCHAR2(4000);
V_FLAG_EXCEPTION EXCEPTION;
BEGIN
IF V_FLAG != 'S' AND V_FLAG != 'M' THEN
RAISE V_FLAG_EXCEPTION;
END IF;
-- 找到最大批次数加1
SELECT NVL(MAX(C_BATCH_ID), 0) + 1 INTO V_MAX_BATCH FROM XZ_SQL_AUDIT;
-- 将传进来的值转换成字符串时间戳格式。
V_START_TIME := TO_CHAR(TO_TIMESTAMP(V_START_TIME, 'YYYY-MM-DD HH24:MI:SS:FF6'), 'YYYY-MM-DD HH24:MI:SS:FF6');
V_END_TIME := TO_CHAR(TO_TIMESTAMP(V_END_TIME, 'YYYY-MM-DD HH24:MI:SS:FF6'), 'YYYY-MM-DD HH24:MI:SS:FF6');
V_SQL := '
insert /*+ ENABLE_PARALLEL_DML PARALLEL(100)*/ into XZ_SQL_AUDIT
select (:1 * 10000000000)+i , scn_to_timestamp(x.request_time * 1000),:2,:3,:4,
x.SVR_IP,
x.SVR_PORT,
x.REQUEST_ID,
x.SQL_EXEC_ID,
x.TRACE_ID,
x.SID,
x.CLIENT_IP,
x.CLIENT_PORT,
x.TENANT_ID,
x.EFFECTIVE_TENANT_ID,
x.TENANT_NAME,
x.USER_ID,
x.USER_NAME,
x.USER_GROUP,
x.USER_CLIENT_IP,
x.DB_ID,
x.DB_NAME,
x.SQL_ID,
x.QUERY_SQL,
x.PLAN_ID,
x.AFFECTED_ROWS,
x.RETURN_ROWS,
x.PARTITION_CNT,
x.RET_CODE,
x.QC_ID,
x.DFO_ID,
x.SQC_ID,
x.WORKER_ID,
x.EVENT,
x.P1TEXT,
x.P1,
x.P2TEXT,
x.P2,
x.P3TEXT,
x.P3,
x.WAIT_CLASS_ID,
x.WAIT_CLASS#,
x.WAIT_CLASS,
x.STATE,
x.WAIT_TIME_MICRO,
x.TOTAL_WAIT_TIME_MICRO,
x.TOTAL_WAITS,
x.RPC_COUNT,
x.PLAN_TYPE,
x.IS_INNER_SQL,
x.IS_EXECUTOR_RPC,
x.IS_HIT_PLAN,
x.REQUEST_TIME,
x.ELAPSED_TIME,
x.NET_TIME,
x.NET_WAIT_TIME,
x.QUEUE_TIME,
x.DECODE_TIME,
x.GET_PLAN_TIME,
x.EXECUTE_TIME,
x.APPLICATION_WAIT_TIME,
x.CONCURRENCY_WAIT_TIME,
x.USER_IO_WAIT_TIME,
x.SCHEDULE_TIME,
x.ROW_CACHE_HIT,
x.BLOOM_FILTER_CACHE_HIT,
x.BLOCK_CACHE_HIT,
x.DISK_READS,
x.RETRY_CNT,
x.TABLE_SCAN,
x.CONSISTENCY_LEVEL,
x.MEMSTORE_READ_ROW_COUNT,
x.SSSTORE_READ_ROW_COUNT,
x.DATA_BLOCK_READ_CNT,
x.DATA_BLOCK_CACHE_HIT,
x.INDEX_BLOCK_READ_CNT,
x.INDEX_BLOCK_CACHE_HIT,
x.BLOCKSCAN_BLOCK_CNT,
x.BLOCKSCAN_ROW_CNT,
x.PUSHDOWN_STORAGE_FILTER_ROW_CNT,
x.REQUEST_MEMORY_USED,
x.EXPECTED_WORKER_COUNT,
x.USED_WORKER_COUNT,
x.SCHED_INFO,
x.PS_CLIENT_STMT_ID,
x.PS_INNER_STMT_ID,
x.TX_ID,
x.SNAPSHOT_VERSION,
x.REQUEST_TYPE,
x.IS_BATCHED_MULTI_STMT,
x.OB_TRACE_INFO,
x.PLAN_HASH,
x.PARAMS_VALUE,
x.RULE_NAME,
x.TX_INTERNAL_ROUTING,
x.TX_STATE_VERSION,
x.FLT_TRACE_ID,
x.NETWORK_WAIT_TIME
from(select /*+ PARALLEL(100) query_timeout(50000000000) */
rownum i, a.* from GV$OB_SQL_AUDIT a where
query_sql not like ''%用来排除不需要的表名,例如压测期间其他微服务的发起的远程调度任务,提前跟业务方确认好,如果有多个则继续添加 and query_sql not like%''
and query_sql not like ''%table_name_1%'' -- 排除的表
and query_sql not like ''%table_name_2%''
and query_sql not like ''%table_name_3%''
and query_sql not like ''%table_name_4%''
and query_sql not like ''%table_name_5%''
and query_sql not like ''%ob_sql_audit%'' -- 排除掉ob_sql_audit的查询sql
and TENANT_NAME <> ''sys''
and query_sql not like ''%extract_sqlaudit_proc%'' -- 排除掉extract_sqlaudit_proc的查询sql
) x ';
-- 添加过滤条件
V_SQL := V_SQL || ' where to_char(scn_to_timestamp((request_time * 1000)),''YYYY-MM-DD hh24:mi:ss:ff6'') >=' || ''''
|| V_START_TIME || '''' || ' AND ' ||
' to_char(scn_to_timestamp((request_time * 1000)),''YYYY-MM-DD hh24:mi:ss:ff6'') <= '
|| '''' || V_END_TIME || '''' || ';';
EXECUTE IMMEDIATE V_SQL USING V_MAX_BATCH,V_MAX_BATCH,V_NAME,V_FLAG;
COMMIT;
DBMS_OUTPUT.PUT_LINE(P_START_TIME || ' ~ ' || p_END_TIME || '时间段可以查询 XZ_SQL_AUDIT 表C_BATCH_ID:' ||
V_MAX_BATCH);
/*
-- 调试代码
dbms_output.put_line(V_NAME);
dbms_output.put_line(V_MAX_BATCH);
dbms_output.put_line(V_START_TIME);
dbms_output.put_line(V_END_TIME);
dbms_output.put_line(V_SQL);
*/
EXCEPTION
WHEN V_FLAG_EXCEPTION THEN
DBMS_OUTPUT.PUT_LINE('p_FLAG参数传入的值错误,S:为拉取单个事务、M:为拉取多个事务(压测)');
END;
sql
begin
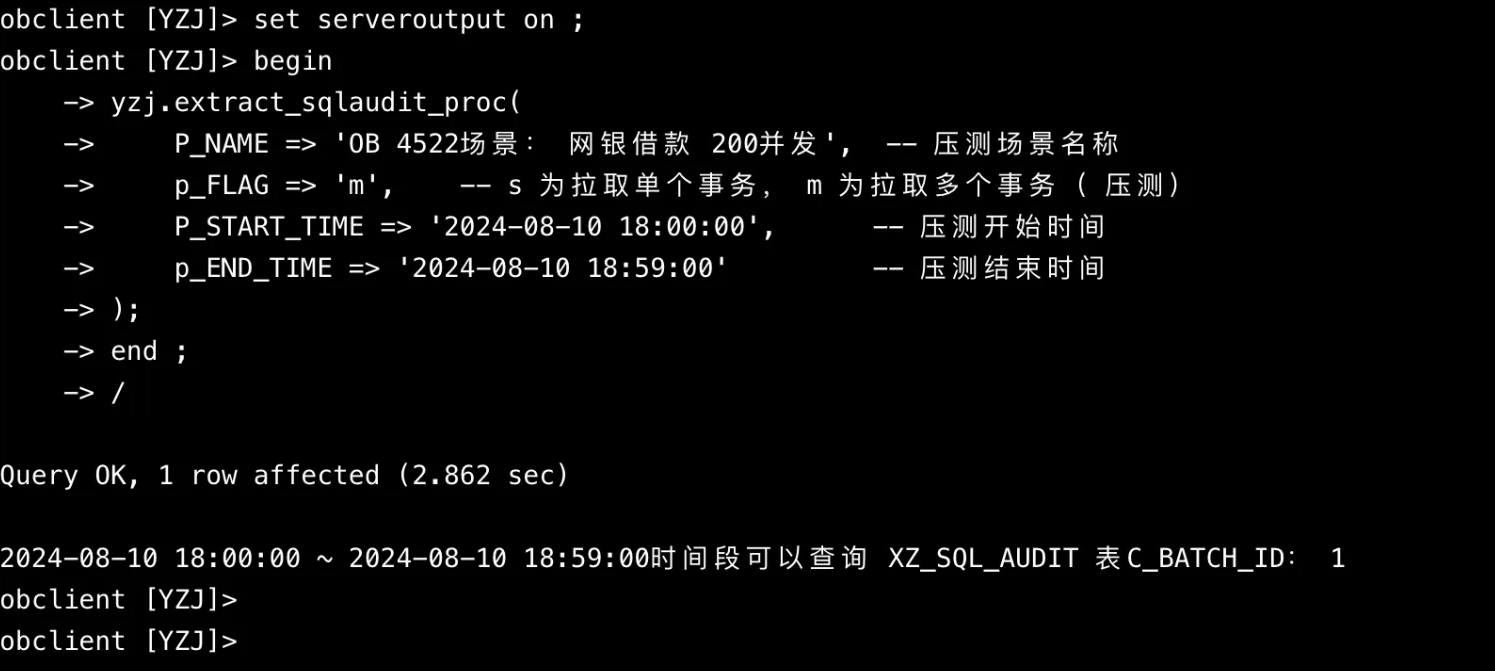
yzj.extract_sqlaudit_proc(
P_NAME => 'OB 4522场景:网银借款 200并发', -- 压测场景名称
p_FLAG => 'm', -- s 为拉取单个事务,m 为拉取多个事务(压测)
P_START_TIME => '2024-08-10 18:00:00', -- 压测开始时间
p_END_TIME => '2024-08-10 18:59:00' -- 压测结束时间
);
end ;
/
这张表为了迎合ob的特性而且还需要保存大量数据,我设计成分区表,c_batch_id 是这张表的核心字段。
每次执行extract_sqlaudit_proc后,c_batch_id 都会加1,存过自动执行,例如上面调用过程后,通过查询:select * from xz_sql_audit where c_batch_id = 1; ,可以将2024-08-10 18:00:00 ~ 2024-08-10 18:59:00 这段时间的所有数据查出来。呦西,是不是很方便呢。😁😁
温馨提示:如果在obclient黑屏执行,建议提前 set serveroutput on ; 选项打开,存过会提示这段时间的数据使用的c_batch_id是什么。
2、通过 xz_sql_audit 表分析案例一
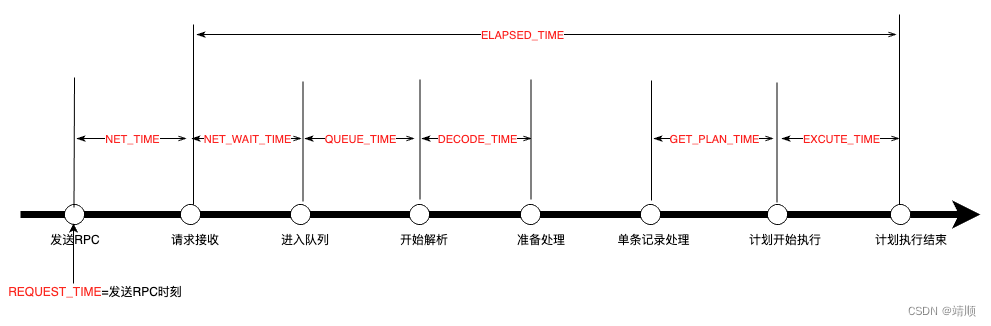
sql执行期间一些重要的事件间隔如下:
sql
SELECT /*+ PARALLEL(80) */
a.TX_ID 事务ID,
B.GG SQL统计次数,
round(a.ELAPSED_TIME) 最大总执行时间,
round(a.ELAPSED_TIME) 平均总执行时间,
round(a.ELAPSED_TIME) 最小总执行时间,
round( max(a.net_time) ) 最大RPC接收到时间,
round( max(a.net_wait_time) ) 最大请求接收的时间,
round( max(a.QUEUE_TIME) ) 最大队列时间,
round( max(a.DECODE_TIME) ) 最大出队列解析时间,
round( max(a.get_plan_time) ) 最大获取计划时间,
round( max(a.execute_time) ) 最大执行时间,
round( max(a.RETRY_CNT) ) 最大重试次数,
round( max(a.RPC_COUNT) ) 最大RPC次数,
round( avg(a.net_time) ) 平均RPC接收到时间,
round( avg(a.net_wait_time) ) 平均请求接收的时间,
round( avg(a.QUEUE_TIME) ) 平均队列时间,
round( avg(a.DECODE_TIME) ) 平均出队列解析时间,
round( avg(a.get_plan_time) ) 平均获取计划时间,
round( avg(a.execute_time) ) 平均执行时间,
round( avg(a.RETRY_CNT) ) 平均重试次数,
round( avg(a.RPC_COUNT) ) 平均RPC次数,
round( min(a.net_time) ) 最小RPC接收到时间,
round( min(a.net_wait_time) ) 最小请求接收的时间,
round( min(a.QUEUE_TIME) ) 最小队列时间,
round( min(a.DECODE_TIME) ) 最小出队列解析时间,
round( min(a.get_plan_time) ) 最小获取计划时间,
round( min(a.execute_time) ) 最小执行时间,
round( min(a.RETRY_CNT) ) 最小重试次数,
round( min(a.RPC_COUNT) ) 最小RPC次数
FROM XZ_SQL_AUDIT a inner join
(SELECT COUNT(to_char(substr(query_sql,1,2000))) gg,
C_BATCH_ID,
TX_ID
FROM XZ_SQL_AUDIT GROUP BY C_BATCH_ID,TX_ID ) b
ON a.TX_ID = b.TX_ID and a.C_BATCH_ID = b.C_BATCH_ID
WHERE a.C_BATCH_ID = 2 -- 改成相应的c_batch_id
GROUP BY a.TX_ID,B.GG ORDER BY 3 DESC;该SQL能够分析出服务端不同事物内sql的运行链路,看看top sql到底在哪个哪个环节上耗时高,是队列、网络、获取计划步骤,还是执行的阶段慢,具体问题具体分析。
sql内所有字段通过上图从左到右进行执行顺序来进行分析,方便项目人员能立马定位到耗时的步骤。
3、通过 xz_sql_audit 表分析案例二
压测期间遇到个怪问题,QPS每隔个2分钟会发生低谷现象,TPS响应时间会在同一时刻发生突刺现象。
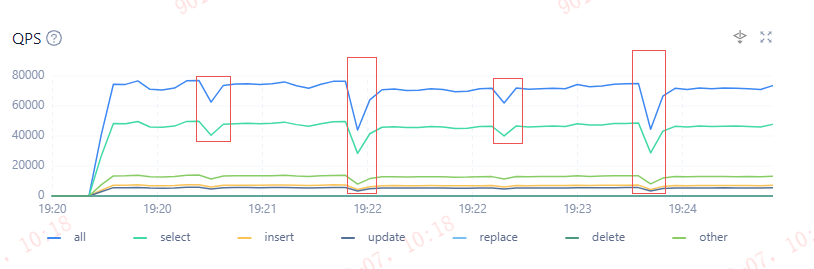
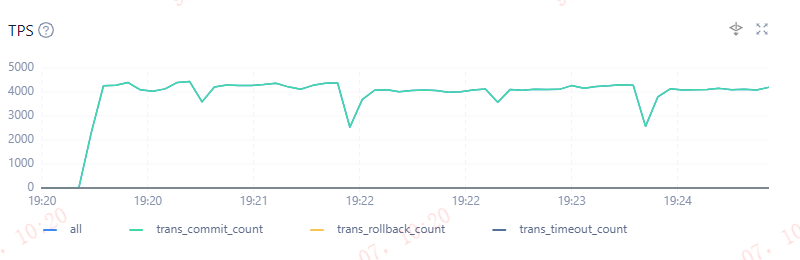
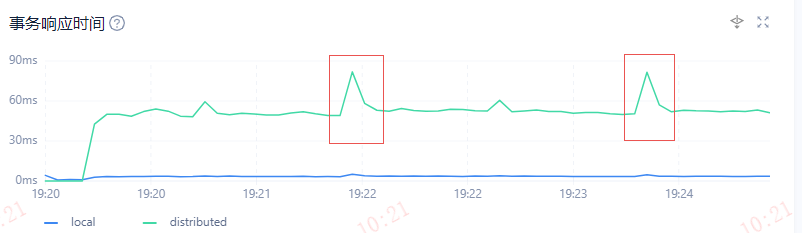
可以通过以下SQL,来定位QPS、TPS低谷期间的范围前后15秒左右的SQL访问流量。
sql
select /*+ PARALLEL(62) */
to_char(a.c_rq_time,'YYYY-MM-DD HH24:MI:SS') c_date,
case when a.plan_type = 0 then '内部计划' when a.plan_type = 1 then '本地计划' when a.plan_type = 2 then '远程计划' when a.plan_type = 3 then '分布式计划' else null end plan_type,
count(1) cnt
from XZ_SQL_AUDIT a
where a.C_BATCH_ID=2 and c_rq_time between to_timestamp('2024-08-06 19:22:00','YYYY-MM-DD HH24:MI:SS') and to_timestamp('2024-08-06 19:22:15','YYYY-MM-DD HH24:MI:SS')
group by to_char(a.c_rq_time,'YYYY-MM-DD HH24:MI:SS'),a.plan_type
order by 2,1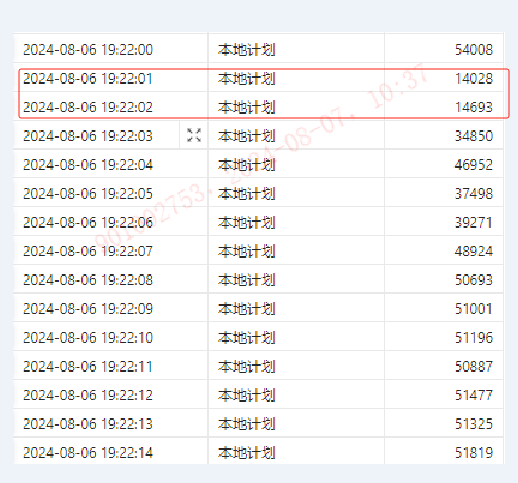
可以看到,19:22:00 这个时间段sql还是有54008的访问量,但是下一秒直接掉到14028的访问量。
但是这个案例最后石锤的是,在同网段的机器上使用benchmarkSQL压测一点问题都没,但是在跨网段的应用的压测机器上发起benchmarkSQL压测,完美复现这个现象。
所以有可能是跨网段,或者网络不稳定等一些的因素造成的QPS波谷,TPS响应尖刺的问题,其实目前还未排除清楚,只是往网络方向排查。
但是上面的分析sql流量的方法也能起到一定的佐证的效果,遇到一个问题要多维度层面和手段来排除,最后确定最终根源。
4、通过 xz_sql_audit 表分析案例三
客户核心系统是JAVA开发的微服务架构,应用机器就有8台,后面还有上百台虚拟机在运行各种辅助的服务。
应用层面的事务管理方式是采用TCC分布式事务模型,采用事务补偿的机制(应用层提供回滚方案,不需要数据库进行回滚)。
这种分布式事务模型优缺点如下:
- 优点:
- 业务层逻辑的实现往往只需要写简单的点查SQL,不需要写复杂的SQL。
- 缺点:
- 事务量巨大,一个事务里面包含非常多点查SQL。
- 回滚逻辑是应用提供,如果期间发生TCP断链,可能会导致数据不一致。
- 业务逻辑非常复杂,很考验开发人员对业务的理解能力。
像TCC这种分布式事务模型,如果跑在集中式数据库下,性能杠杠的。😁😁😁
由于事务量多,在原有的gv$ob_sql_audit视图下,很难分析出单个交易场景里面的SQL是由哪些组成,在不清楚业务接口的单交易的模型情况下,更不用说如何来优化这个接口。
我这边是这样跟业务人员沟通的:
- 让业务开发人员发起某个场景下的单笔交易的任务。
- 让业务人员提供交易开始时间和结束时间,最好精确到微秒,实在不行精确到毫秒也行。
- 然后我使用extract_sqlaudit_proc存过来收集对应的时间点,例如业务开发发起的交易任务,开始时间和结束时间为:2024-08-10 20:01:01.123 ~ 2024-08-10 20:01:01.500 (一笔交易毫秒级别),那我可以对开始时间和结束时间分别加1秒来扩大收集在这个时间段的所有SQL。
sql
begin
yzj.extract_sqlaudit_proc(
P_NAME => 'OB 4522场景:网银借款 单笔交易', -- 压测场景名称
p_FLAG => 's', -- s 为拉取单个事务,m 为拉取多个事务(压测)
P_START_TIME => '2024-08-10 20:01:00.123', -- 交易开始时间
p_END_TIME => '2024-08-10 20:01:02.123' -- 交易结束时间
);
end ;
/- 然后我使用extract_sqlaudit_proc存过来收集对应的时间点,例如业务开发发起的交易任务,开始时间和结束时间为:2024-08-10 20:01:01.123 ~ 2024-08-10 20:01:01.500 (一笔交易毫秒级别),那我可以对开始时间和结束时间分别加1秒来扩大收集在这个时间段的所有SQL。
- 还需要跟业务开发确定好这笔交易开始执行的表的SQL语句和事务结束执行的表的SQL语句,或者是SQL都行,最好是有标志性能确定是属于这个交易里面的操作。
- 最后使用以下SQL来分析单笔交易的所有事务的数量和不同事务包含的SQL语句。
sql
SELECT *
FROM (SELECT TO_CHAR(b.trans_start_time, 'YYYY-MM-DD HH24:MI:SS.FF6') 单笔事务开始时间,
TO_CHAR(b.trans_end_time, 'YYYY-MM-DD HH24:MI:SS.FF6') 单笔事务结束时间,
ROW_NUMBER() OVER (PARTITION BY a.tx_id ORDER BY a.c_rq_time) sql事务内执行顺序,
a.tx_id 事务ID,
TO_CHAR(a.c_rq_time, 'YYYY-MM-DD HH24:MI:SS.FF6') sql请求执行时间,
TO_CHAR(SUBSTR(a.query_sql, 1, 2000)) sql语句,
a.net_time RPC接收到时间,
a.net_wait_time 请求接收的时间,
a.QUEUE_TIME 队列时间,
a.DECODE_TIME 出队列解析时间,
a.get_plan_time 获取计划时间,
a.execute_time 执行时间,
a.RETRY_CNT 重试次数,
a.RPC_COUNT RPC次数,
a.ELAPSED_TIME 总执行时间
FROM xz_sql_audit a
INNER JOIN (SELECT MIN(c_rq_time) trans_start_time,
MAX(c_rq_time) trans_end_time
FROM xz_sql_audit
WHERE c_batch_id = 6 -- c_batch_id 自己环境去看,记得要改
AND (
query_sql LIKE '%insert%in_log%' -- 交易开始的SQL语句操作
OR query_sql LIKE '%update%in_log%') -- 交易结束的SQL语句操作
) b
ON a.c_rq_time >= b.trans_start_time AND a.c_rq_time <= b.trans_end_time AND a.c_batch_id = 6)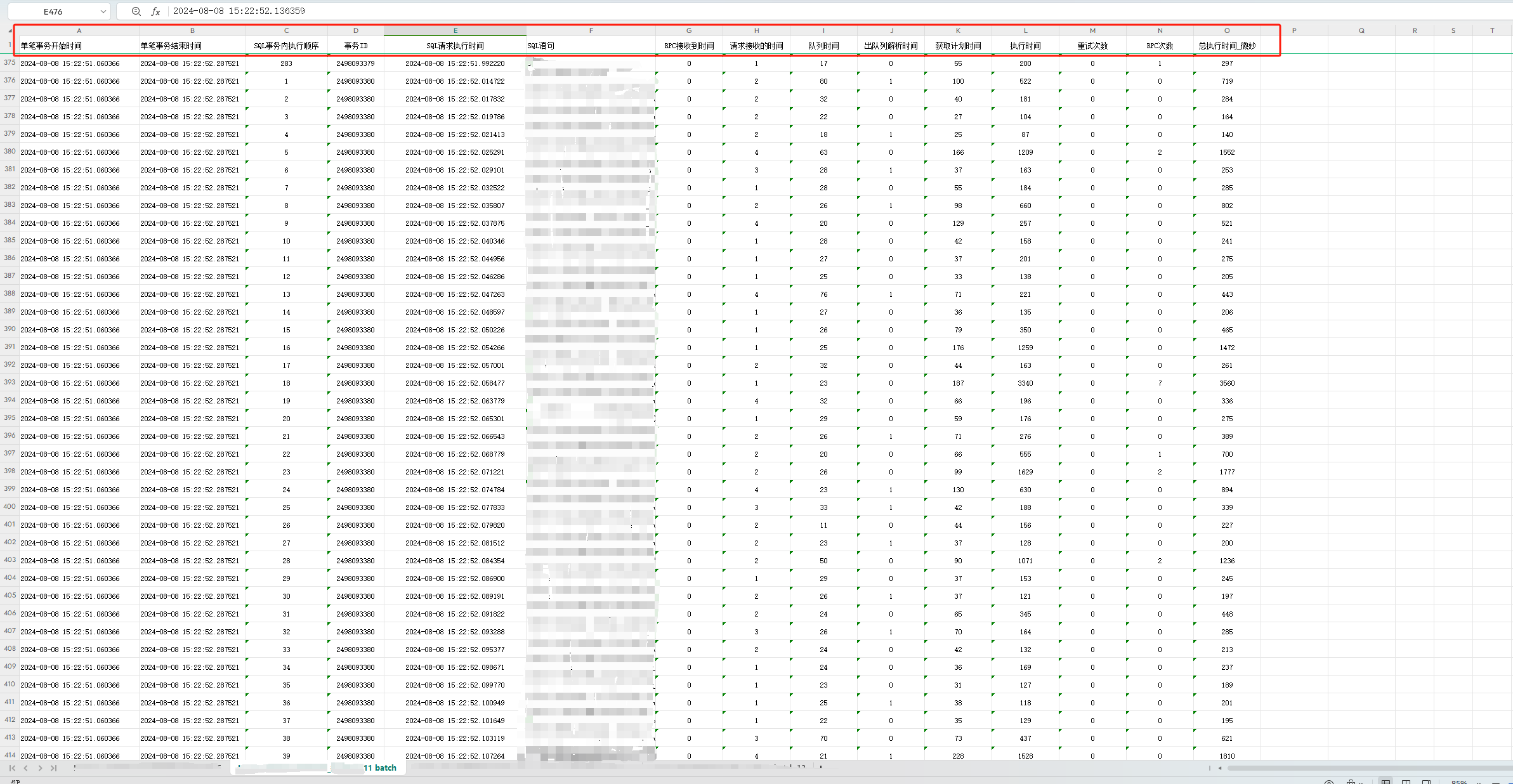
5、结束语
extract_sqlaudit_proc 过程起到的帮助是将gvob_sql_audit数据拉到xz_sql_audit表里面,但是如何分析出对项目人员有效的数据,还是取决于你对gvob_sql_audit表的理解还有个人的SQL能力。
SQL能力过关的情况下,才能写出不同场景所需要的数据的分析SQL,而不是只局限于一两个场景下的分析。
还有一点,你要写啥SQL分析,就对xz_sql_audit加相应的索引即可,能加速sql的分析效率,机器资源够的情况下,分析sql多加点并发,比gv$ob_sql_audit快多了,极大提高了工作效率。
我现在还在搞obproxy的日志分析脚本,将xz_sql_audit表数据的开始结束时间传入个脚本,来将obproxy的日志形成结构化数据导入到obproxy_audit表,后面可以写sql来分析一笔业务交易,server层和proxy层的消耗分别使用的多少时间。🤞🤞🤞