进入数字化时代,以数据驱动业务决策,已经成为各个企业所看重的重要环节,而数据的真正价值,也在于能够支撑业务流程的快速流转,以及业务经营决策的敏捷性。
在企业里,无论你是公司的高管、部门经理,还是一线的作业人员,都会通过管理驾驶舱,通过数据分析,对绩效进行考核,对用户运营、渠道运营、营销活动、订单管理等展开微观的业务决策,以达成业绩目标。
在这个过程中,站在业务视角,往往期望的数据分析体验总结为:快、全、准。而这,也是衡量数据分析是否做好的评判标准。
所谓快,核心有四点。
第一点是"试错快"。为了应对市场的快速变化,企业在持续创新,而创新探索类的业务需要快速利用指标刻画结果,衡量创新的好坏。
第二个是"决策快"。比如上线一个活动,做了一个 AB 实验,怎么能快速拿到活动、AB 实验的数据,基于这些数据快速调整策略,调整周期是周?天?还是小时?
第三个是"定位快"。当持续监测的数据发生异常,不符合预期,我们需要快速定位数据变化的原因,以快速发现和解决问题或识别与利用机会。
第四个是"查询快"。企业的数据量越来越大,如何快速满足业务对数据查询效率的需求,也是一大挑战。
除了速度,还有一个重点是"全"。
相信所有有过分析体验的业务同学其实最希望能够拥有一张大明细表。这张明细表中包含了所有可以分析的字段。为什么需要明细表呢?因为数据分析很多时候是一个灵活探索的过程,我们可能最初并不能完全确定需要哪些字段,甚至不确定要得出怎样的结论。因此,有了这张最全的表,我们可以灵活地筛选出自己想要的数据,可以灵活地透视这些数据。
而在"快"和"全"的同时,数据的准确性是它的底线和生命线。"准"的含义有两点:第一点是数据的一致性,即时间概念上的前后一致性;第二点是口径的一致性和清晰性,在不同的报表中,同样的一个指标,它的口径是否一致,不同的业务人员对同一个指标是否有着清晰和统一的理解。
而目前大部分企业采用的是经典的"数仓 + BI"的开发与分析模式。ETL 工程师通过数据开发平台进行了大量的数据资产沉淀和物理表开发。这些物理表开发完成后,被引入到 BI 工具中,将其转换为数据集,用于报表制作或自助分析。经典的数仓分层建模严重依赖于 ETL 专业知识和人工作业。大部分场景下,BI 工具消费的是我们的应用层或集市层的宽表和汇总表。
这种模式存在一系列问题,如需求响应慢、分析不灵活、指标口径不一致、大量维度冗余、维护成本很高等。为改变这一现状,实现数据分析的快、全、准,我们认为,通过在数仓和 BI 之间引入一个全新的、独立的指标平台(或者叫做指标语义层),将指标的业务逻辑和物理口径进行解耦,可以实现这一目标。
但前提是这样的指标平台需要具有 NoETL、自动化的特点,即基于数仓公共层的明细数据和维度表进行自动化语义建模,并由系统自动化代持数仓应用层宽表和汇总表的开发,实现"管、研、用"一体化:首先从管理角度,可实现指标口径的统一管理;其次从开发的角度,避免重复开发,提高指标交付的效率;最后从使用的角度,提供给业务侧快速、灵活、一致的指标消费体验。
Aloudata 作为国内首倡"NoETL"创新理念的企业,通过自主研发,打造了一款 NoETL 自动化指标平台------Aloudata CAN,集规范指标定义、自动指标生产、语义指标目录、开放指标服务于一体,能够帮助企业构建一个数据管得住、拿得到、用得好的指标开发、消费和管理的平台,真正实现指标管、研、用一体化,实现"快、全、准"的数据分析和业务决策,并大幅降低维护成本。
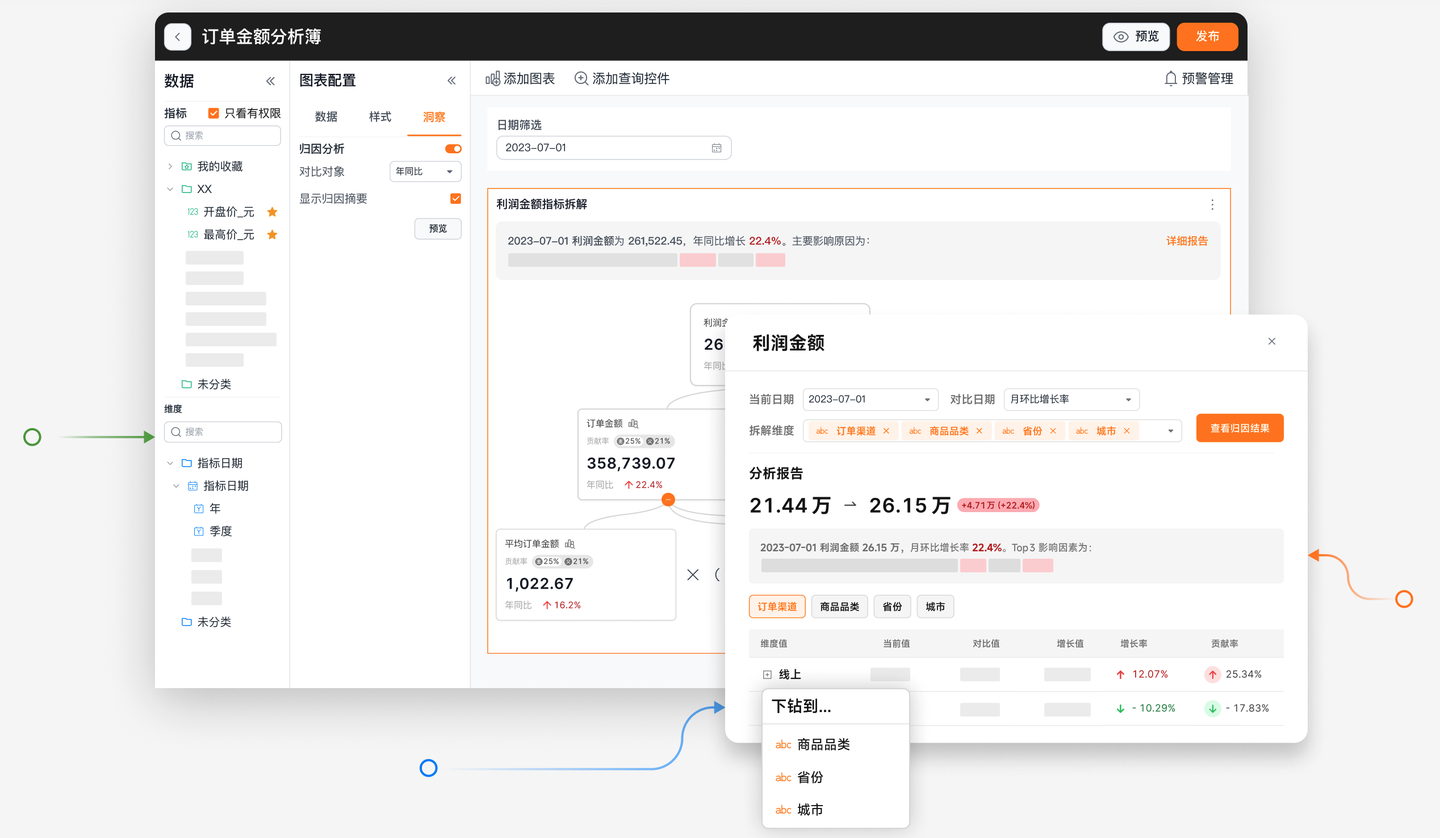
例如,通过 Aloudata CAN,企业可以构建统一指标体系,一次定义,处处使用。我们以"交易客户数"为例,可作为公司级北极星指标,衡量整体经营业绩;也可用于门店经营管理快报,衡量门店经营效果;还能用于策略投放效果分析,评估投放策略的有效性;同时还可以将指标作为行为标签,进一步刻画门店/渠道的客户画像,挖掘市场机会,优化营销策略。
基于统一的指标体系,Aloudata CAN 支持业务从"北极星指标监控 -> 下钻查看策略整体贡献度 -> 下钻查看每个策略的归因贡献度",将指标与业务流程结合,真正发挥指标的数据价值,实现指标驱动业务行动。
在实际的数据生产和消费环境中,某客户基于 Aloudata CAN 大幅提升了数据生产力,指标开发时间提升 16 倍,需求交付所需总时间提升 10 倍,业务部门和 IT 部门沟通协作所需时间提升 75%,报表打开和业务自助分析查询响应时间提升 7 倍,计算和存储资源节约 50%。如您希望加速实现数据分析的"快、全、准、省",Aloudata CAN或许是个不错的选择。