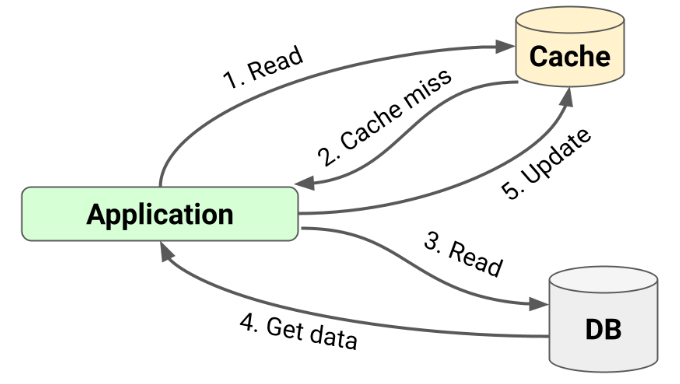
Cache-aside 模式的缓存操作
Cache-aside 模式,也叫旁路缓存模式,是一种常见的缓存使用方式。在这个模式下,应用程序可能同时需要同缓存和数据库进行数据交互,而缓存和数据库之间是没有直接联系的。这意味着,应用程序代码要负责处理数据的获取和存储,
一些应用程序使用"Read-Through"或"Write-Through"的缓存策略,其中缓存系统定义了更新或缓存失效的逻辑,并作为应用程序的透明接口。
如果缓存系统不提供这些功能,则应用程序代码需要负责管理缓存查找、在写操作时更新缓存,以及在缓存未命中时查询数据库。这就是 cache-aside 策略的作用所在:应用程序与缓存和数据库交互,而缓存与数据库完全没有交互。
Cache-aside 模式的读操作流程
在读取数据时,应用程序首先会去缓存中查看这个数据是否已经存在,如果数据存在于缓存中,这叫做缓存命中,则直接将缓存的数据返回给用户。
如果缓存中没有需要的数据,这叫做缓存未命中,这种情况下,应用程序需要从数据库中获取这个数据,从数据库中拿到数据后,应用程序还会将数据存入缓存,以便下次再需要这个数据时,可以直接从缓存里获取,而不需要再去查数据库。
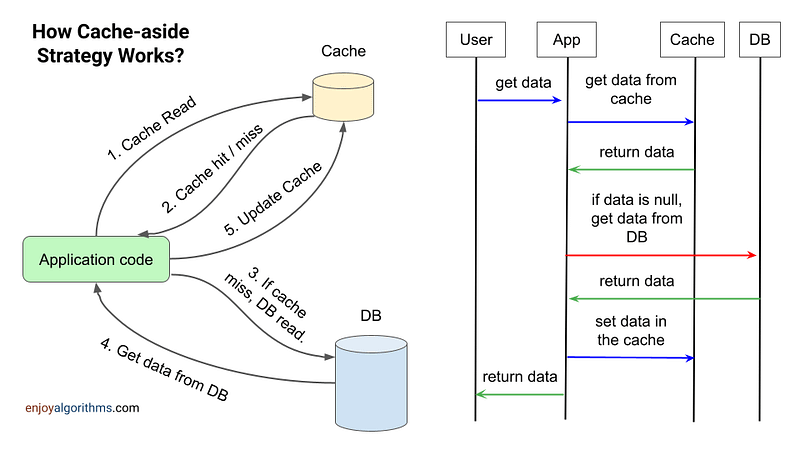
Cache-aside 模式的写操作流程
现在,关键问题是:在 Cache-aside 模式中,我们如何执行写操作?
当你需要写入数据(添加、修改或删除)时,有两种常见的处理方式:
1. 写入数据库并使缓存失效
这种方法是先更新数据库然后将缓存中对应的数据删除(如果缓存中存在该数据)。因此,当后续需要再次读取相同的数据时,由于缓存里没有,应用程序将从数据库中查找数据并将其添加到缓存中。
可以看出:在更新数据库后,数据不会立即存储在缓存中,直到有下一次读取该数据的请求。这样,缓存总是按需更新,不用担心存放了无用的数据。
但这种方式也存在一些缺点:
-
因为数据是在下一次读取时才更新到缓存中,所以第一次读取时可能会稍慢,导致一些延迟。如果读写比非常高,或者应用程序在数据库写入后频繁重新读取相同的数据,这种策略会很有用。
-
存在增加数据库负载的可能性。例如,如果多个请求同时触发缓存未命中,可能导致数据库查询的激增。
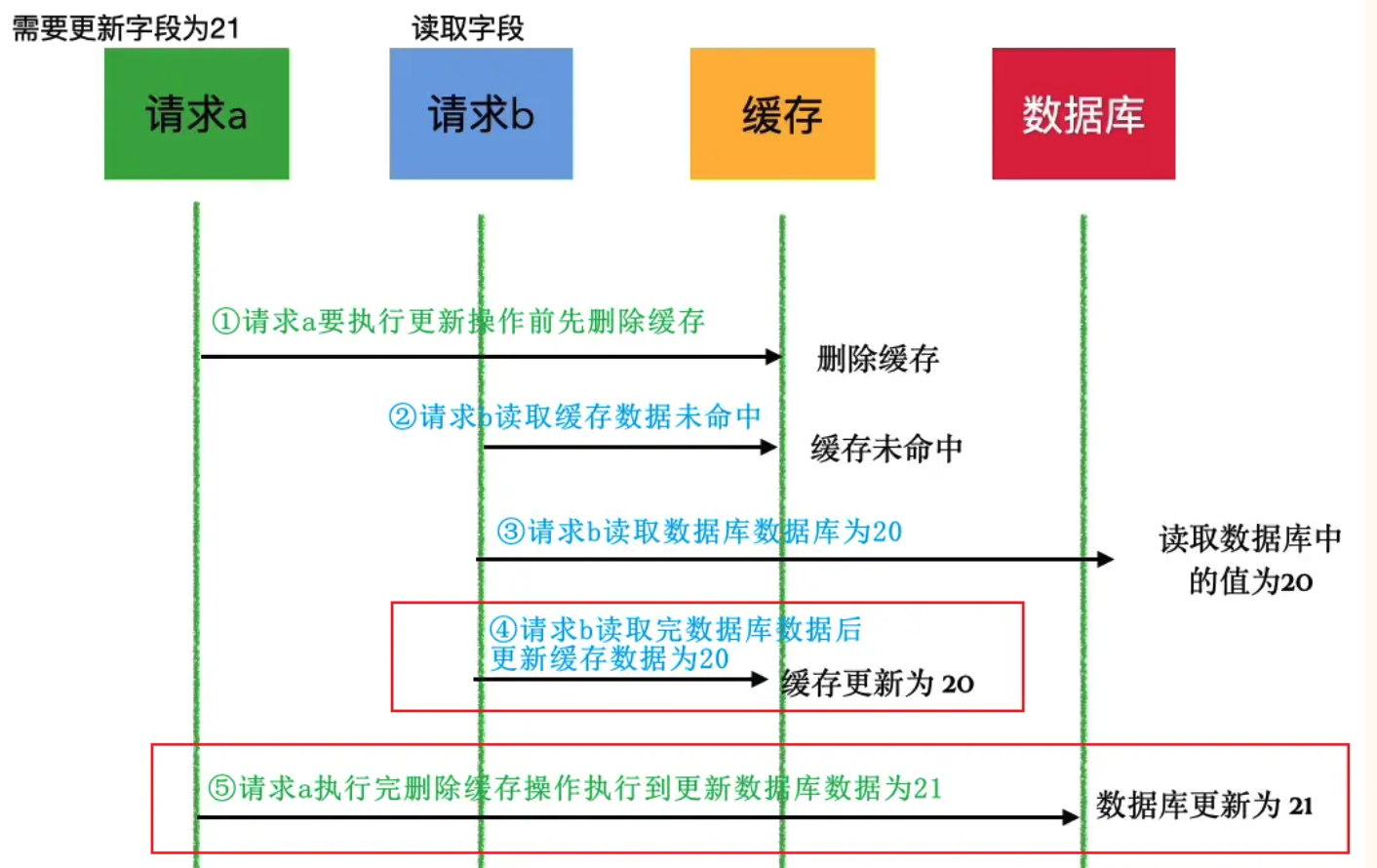
这里有一个关键问题:我们在更新数据时是否可以先使缓存失效,然后再更新数据库?答案是尽量不要这么玩,特别是在高并发的场景下,下面看看这么做会有什么问题。
在高并发的场景下,如果我们在更新数据时采用先使缓存失效,再更新数据库,如果某个时刻,同时有一个读请求和一个更新请求操作同一条数据,更新请求刚好让这条数据在缓存失效,然后读请求读取时缓存未命中(因为数据已被更新请求从缓存中删除),就会从数据库中获取旧数据并添加到缓存中。更新请求继续将数据库中的这条数据更新,这导致缓存数据和数据库的数据不一致。
下面这张图很好的说明了这种现象。
2. 写入数据库并立即更新缓存
这种方式在更新数据库后,应用程序也会把最新的数据更新到缓存中。由于在数据库更新后缓存已更新为最新数据,因此后续的读取请求更有可能命中缓存,从而减少对数据库的访问。
然而,这种方式也会带来以下问题:增加写入延迟,因为数据需要同时写入缓存和数据库。不过,如果你的系统是读多写少(即大多数请求都是读取数据),这个额外的时间开销是可以接受的。
Cache-aside 模式的特点
Cache-aside 模式的优点
-
为应用程序代码提供了灵活性和控制力。开发人员可以自己根据业务场景决定哪些数据应该缓存,缓存多久,或者什么时候需要刷新缓存。
-
Cache-aside模式能够抵御缓存层的故障。如果缓存系统出现故障,应用程序仍然可以从数据库中获取数据,不会因为缓存问题导致整个系统无法工作。
-
随着应用程序的增长以及处理更高流量所需资源的增加,可以添加更多的缓存服务器以分担负载。换句话说,在Cache-aside模式中,缓存层可以独立于数据库轻松扩展。
-
因为缓存和数据库是分离的,我们可以在缓存中使用与数据库不同的数据模型,例如据库中可能存储了完整的用户信息,但缓存中只存储了用户的ID和用户名,因为这些数据在前端展示中是最常用的。
-
Cache-aside模式只会包含应用程序实际请求的数据,这样可以有效利用缓存空间,不会浪费存储。
-
使用混合策略(比如与 Write-Through 结合)可以确保缓存中数据和数据库中的数据是同步更新的,减少数据过时或不一致的风险。
Cache-aside 模式的缺点
-
由于应用程序需要自己管理缓存的操作,包括缓存失效、并发处理等,增加了开发的复杂性。如果处理不当,可能会出现错误或bug。
-
当数据更新后,缓存中的旧数据会被删除,这样下次读取时缓存会未命中(因为缓存中没有数据),从而需要从数据库中重新加载数据。如果频繁更新数据,会导致缓存未命中频繁发生,影响性能。
-
当使用Cache-aside与Write-Through结合时,写操作的延迟会很高,因为数据将同时更新到缓存和数据库中。因此,对于写密集型的工作负载来说,这种策略效率不高。另一方面,这样做可能导致缓存中存储了许多不必要的数据,或者缓存中的数据未必是最常用的。这会导致缓存效率低下,增加缓存未命中率。如何处理这种情况?需要深入思考和探索。
-
在实际操作中,由于缓存和数据库是分离的,缓存中的数据可能不会及时反映数据库中的变化,导致数据不一致的情况。因此,应用程序开发人员应使用适当的缓存淘汰策略来处理数据不一致问题。举一个例子:假设你成功更新了缓存,但数据库更新失败。因此,代码需要实现重试机制。在最坏的情况下,在重试失败期间,缓存中可能包含数据库中不存在的值。