目录
[1. 数据类型和内部编码](#1. 数据类型和内部编码)
[1.1 Redis 数据类型 vs Redis 真实编码方式](#1.1 Redis 数据类型 vs Redis 真实编码方式)
[1.1.1 string](#1.1.1 string)
[1.1.2 hash](#1.1.2 hash)
[1.1.3 list](#1.1.3 list)
[1.1.4 set](#1.1.4 set)
[1.1.5 zset](#1.1.5 zset)
[1.2 object encoding key](#1.2 object encoding key)
[2. Redis 单线程模型](#2. Redis 单线程模型)
[2.1 Redis 效率高/速度快的原因 经典面试题](#2.1 Redis 效率高/速度快的原因 [经典面试题])
[3. 数据类型 - string](#3. 数据类型 - string)
[3.1 set / get](#3.1 set / get)
[3.1.1 setnx / setex / psetex](#3.1.1 setnx / setex / psetex)
[3.2 mset / mget](#3.2 mset / mget)
[3.3 incr / incrby / decr / decrby / incrbyfloat](#3.3 incr / incrby / decr / decrby / incrbyfloat)
[3.4 append](#3.4 append)
[3.5 getrange](#3.5 getrange)
[3.6 setrange](#3.6 setrange)
[3.7 strlen](#3.7 strlen)
[3.8 string 内部编码](#3.8 string 内部编码)
[3.9 string 应用场景](#3.9 string 应用场景)
[3.9.1 缓存](#3.9.1 缓存)
[3.9.2 计数功能](#3.9.2 计数功能)
[3.9.3 存储 session 会话](#3.9.3 存储 session 会话)
[3.10 string 命令总结](#3.10 string 命令总结)
1. 数据类型和内部编码
Redis 中的数据类型有很多(注: 是 value 的数据类型), 但最常用到的是以下几个:
- string: 字符串
- list: 列表
- hash: 哈希
- set: 集合, 元素不能重复
- zset: 有序集合 . zset 中存入的元素, 除元素本身外, 每个元素还关联一个 score(权重/分数)
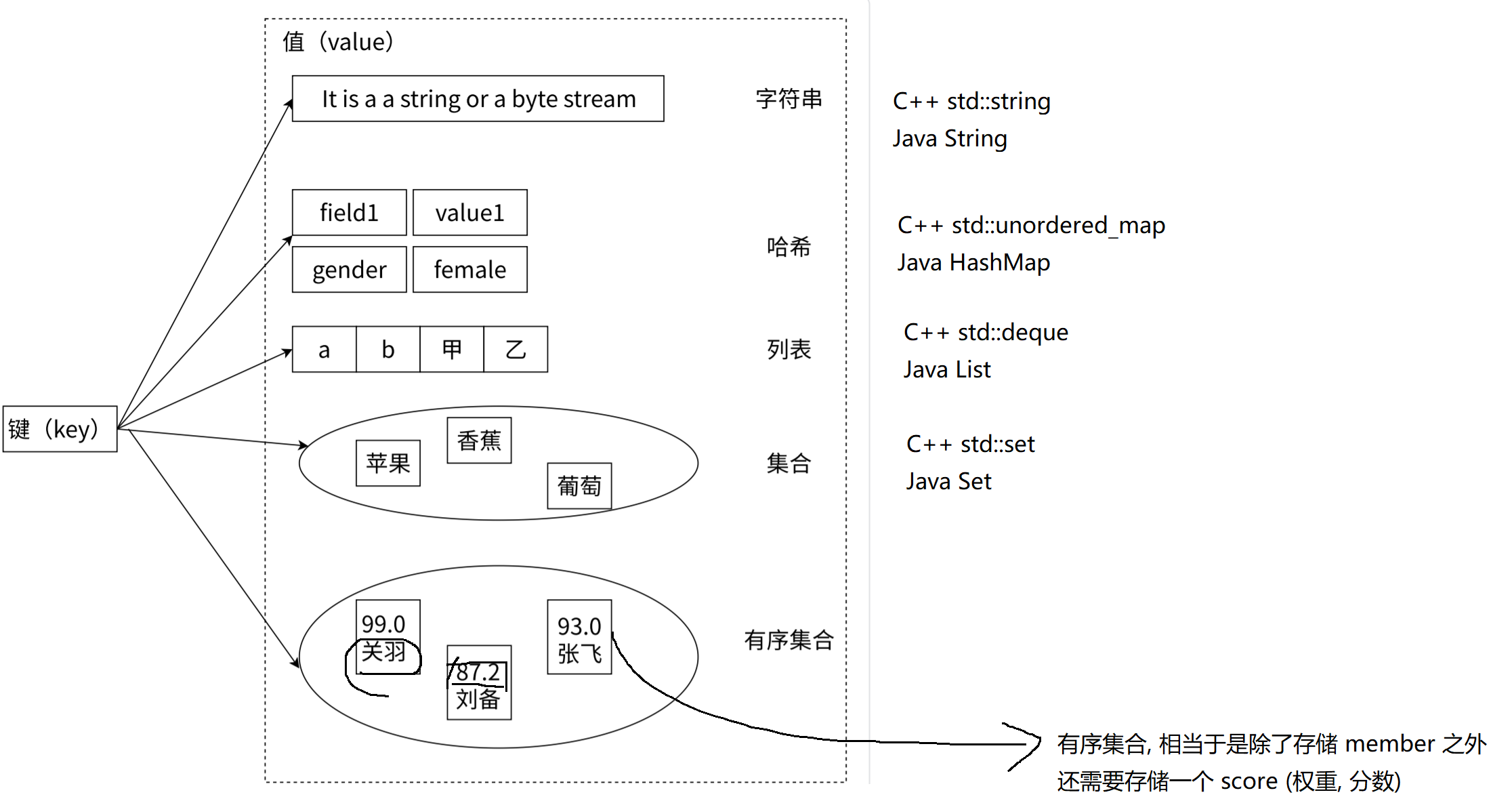
注: 以上几种数据类型, 只是 Redis 对外承诺的数据类型, 但是 Redis 底层的代码实现, 会根据特定的场景进行优化.
比如说 hash, 虽然 Redis 说是 hash, 但是它底层的编码实现不一定就是一个哈希表, 可能采取了其他手段进行了优化, 能够保证 增删查改 的时间复杂度为 O(1).
具体是怎样优化的, 下文会讲.
1.1 Redis 数据类型 vs Redis 真实编码方式
上文提到, 数据类型是 Redis 承诺给我们的类型, 但是类型内部具体的编码实现, Redis 根据特定场景, 进行了优化改进.
具体情况如下:
|--------|------------|
| 数据类型 | 内部编码 |
| string | raw |
| string | int |
| string | embstr |
| hash | hashtable |
| hash | ziplist |
| list | linkedlist |
| list | ziplist |
| set | hashtable |
| set | intset |
| zset | skiplist |
| zset | ziplist |
注: Redis 会根据当前的实际情况, 自适应的选择合适的编码方式.
1.1.1 string
Redis 的 string 类型, 它就有多种编码实现:
- raw : 最基本的字符串(和我们平常 Java 里使用的字符串一样), 底层持有一个 byte 数组.
- int : 整数, 当 set 存入的 value 是整数时, 就会使用 int 来保存. (计数的场景)
- embstr : 针对短字符串进行的优化. (比 raw 节省空间)
1.1.2 hash
- hashtable : 最基本的, 我们平常使用的哈希表 (注: 此 hashtable 非 Java 标准库里的 HashTable)
- ziplist : 压缩列表. 当哈希表中的数据较少时, 就优化为 ziplist, 节省内存空间并且能够保证效率(数据少, 能够保证遍历的时间复杂度为 O(1))
1.1.3 list
- linkedlist : 链表, 方便从中间位置插入删除. 消耗空间大, 但操作效率较高. 元素多用这个.
- ziplist : 压缩列表. 节省空间, 但操作效率低. 元素少用这个.
但是, 以上两种都是 Redis 以前版本的实现, 从 Redis 3.2 开始, 引入了新的实现方式:
- quicklist : 结合了 linkedlist 和 ziplist, 兼顾了他们的优点. quicklist 本身是一个链表, 但是每个元素是一个 ziplist (本身是链表, 链表的每一个元素是压缩列表), 把空间和效率都折衷的兼顾到.
1.1.4 set
- hashtable : 哈希表
- intset : 集合中存的都是整数
1.1.5 zset
- skiplist : 跳表. 本质是一个链表, 但和普通链表不同的是, 每个节点上有多个指针域, Redis 通过巧妙搭配这些指针域的指向, 来做到从跳表上查询元素的时间复杂度为 O(logN).
- zset 中存入的元素, 除元素本身外, 每个元素还关联一个 score(权重/分数), 跳表会根据元素关联的分数的值, 高效的去排序和定位元素.
- ziplist : 压缩列表
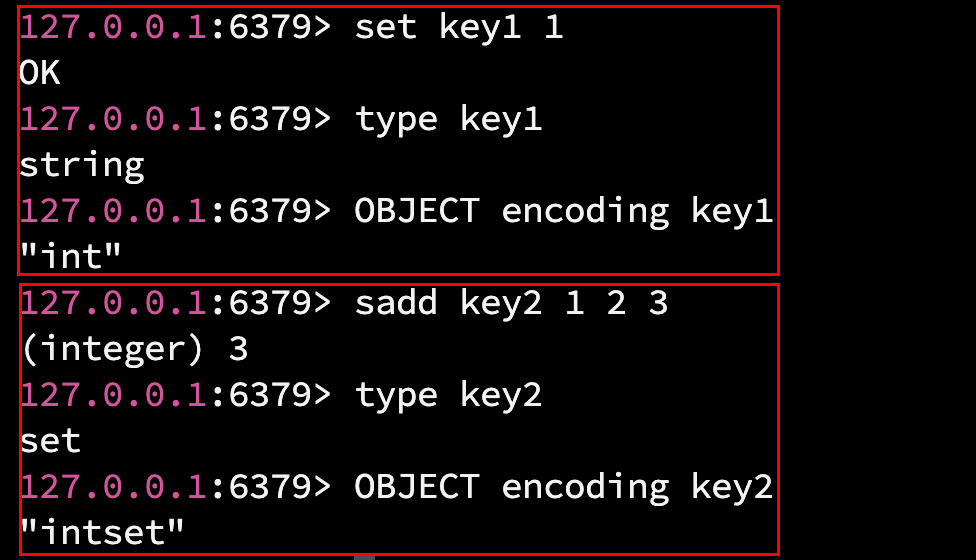
1.2 object encoding key
查看 key 对应 value 的实际编码方式: object encoding key
2. Redis 单线程模型
Redis 是单线程模型的服务器, 其中的单线程是指:
- Redis 服务器内部使用的是一个线程处理所有的命令请求. 但是, Redis 中不是只有一个线程, 还有其他的多个线程用来处理网络 IO.
也就是说, Redis 服务器可以 并发 的接受多个 Redis 客户端发来的请求, 但是处理这些请求命令时, 是一个一个的串行处理的.
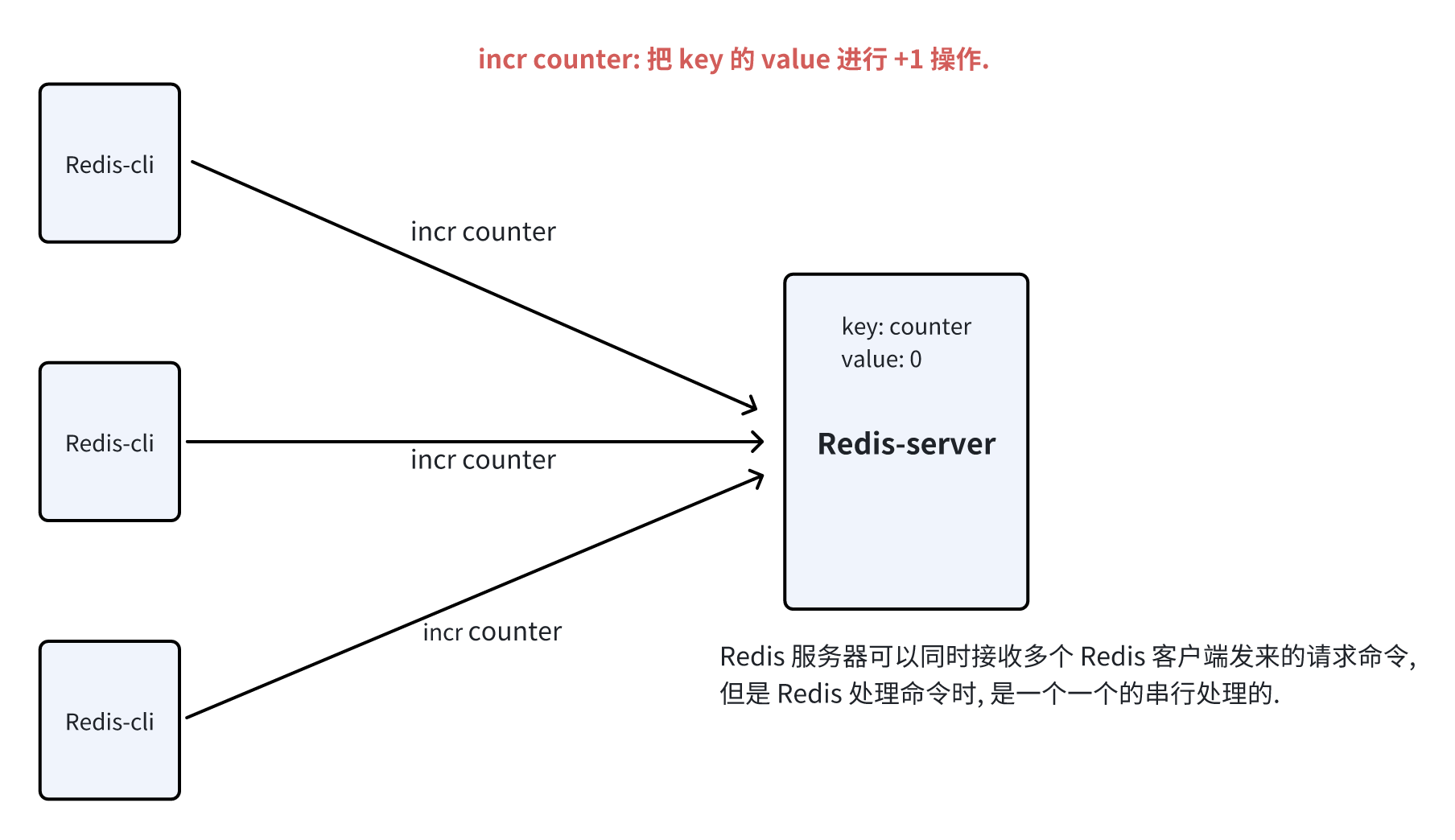
因此即使多个客户端同时对同一个 key 的 value 发起了 +1 操作的命令, 但是由于 Redis 是单线程模式, 保证命令是串行执行的, 因此也不会存在线程安全问题.
注意:
Redis 之所以能够使用 单线程 去很好的工作, 是因为 Redis 的核心命令都是 "短平快" 的, 不会消耗太多的 cpu 资源.
2.1 Redis 效率高/速度快的原因 经典面试题
而 Redis 既然是 单线程的, 为啥它还那么快呢? (注: Redis 的快, 是对比 数据库(mysql/oracle/sql server) 来说的)
- Redis 访问的是内存, 而 mysql 等数据库访问的是硬盘.
- Redis 的核心功能, 比数据库的核心功能要简单.
- 数据库的各种增删查改, 都支持更复杂的功能, 因此花销更大, 效率就低了.
- 比如: 针对插入删除操作, 数据库有各种约束, 如果是唯一约束, 插入前就要看看这个字段的值是否唯一.
- 比如: 查询操作, 支持 distinct 去重查询, group by 分组查询, order by 排序查询..... 这些功能都是会降低效率的.
- 而 Redis 直接就是从哈希表中进行操作, 效率更高.
- 数据库的各种增删查改, 都支持更复杂的功能, 因此花销更大, 效率就低了.
- Redis 是单线程模型, 避免了一些不必要的线程竞争开销. (线程竞争锁导致的阻塞)
- Redis 的基本操作, 就是操作一下内存数据, 不会太消耗 cpu, 因此没有必要去搞多线程(提升不大)
- Redis 处理网络 IO 时, 采取了 epoll 这样的 IO 多路复用机制.
IO 多路复用是指:
一个线程, 管理多个 socket(套接字).
一个 Redis 服务器, 会给多个 Redis 客户端提供服务, 服务器就会给每个客户端都安排一个 socket, 而在绝大多数情况下, 每个客户端和服务器的交互都不是很频繁, 也就是说绝大多数的 socket 都是处于静默状态 的, 没有数据需要传输. 那么, 如果给每个 socket 都分配一个线程, 那么线程数越多, 开销也就越大, 而同一时刻只有少数的 socket 是活跃的, 因此, 就可以使用一个线程来处理多个 socket, 这种方式就是 IO 多路复用.
注意: 采用 IO 多路复用, 一定有个前提: 客户端和服务器之间的交互不频繁, socket 绝大部分时间都是静默的.
Linux 提供有三套 IO 多路复用的 API:
- select
- poll
- epoll (Redis 采用的是这个, 也是效率最高的)
(IO 多路复用技术, 在 99% 的应用场景下, 都是针对网络 IO 来说的.)
3. 数据类型 - string
Redis 没有编码集, 存入 string 数据时, 直接存的就是二进制数据, 不会进行编码转化, 你存的是啥, 取出来就是啥.
它**不关心你存入的字符串是什么编码,**它接收到的所有字符串(包括键和值)都只是一连串的二进制字节序列. 你传的什么字节, 它就原封不动地存储什么字节; 你来取的时候, 它也原封不动地把这些字节还给你.
而 mysql 是有自己的字符集编码的, 之前旧版本的 mysql 的默认字符集是拉丁, 因此如果我们存入一个 uft-8 编码的汉字, 这个汉字会先按照 uft-8 的编码方式转换为二进制数据发出去, mysql 收到这些二进制数据后, 会先将这些二进制数据按照拉丁的规则进行验证和转换(校验是否合法的), 而在拉丁的字符集中是找不到这些二进制对应的内容, 因此 mysql 会将这些无法识别的字节序列(二进制数据), 自主替换为 ?/#/* 等其他数据存入(并且不可逆, 变不回来了), 那我们后续再去取, 取到的也就是这些 ?/#/* 东西, 就会乱码.
字符集编码的过程是什么?
字符串的编码方式, 如 GBK/UTF-8 是由客户端/应用程序决定的, 你的应用程序在写入 Redis 前会按照字符集(GBK/utf-8)将字符串编码为二进制, 这个二进制数据就会被存入 Redis 中, 取的时候 Redis 会返回这个二进制数据, 客户端收到后, 再按照相同的字符集进行解码.
因此使用 Redis 时, 只要保证写入和读取时使用相同的编码方式, 就不会出现乱码问题.
3.1 set / get
使用 set 命令, 往 Redis 中存储 string 类型的 value 数据.
时间复杂度为 O(1)


FLUSHALL: 清空 Redis 中所有的数据.
相当于 mysql 的 drop database
get, 获取 key 对应的 value. 时间复杂度为 O(1)
注: value 必须是字符串.

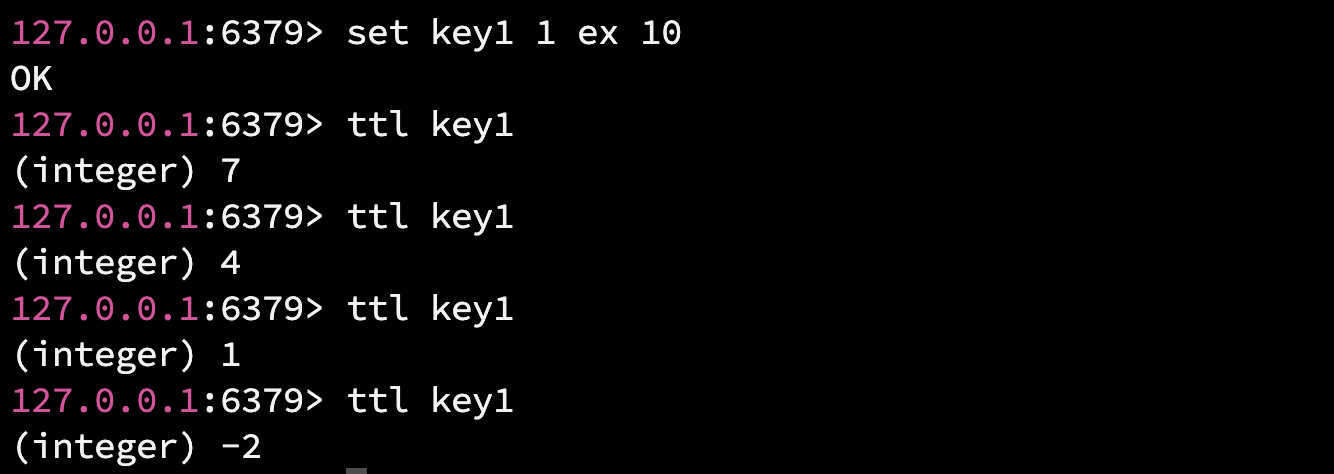
3.1.1 setnx / setex / psetex
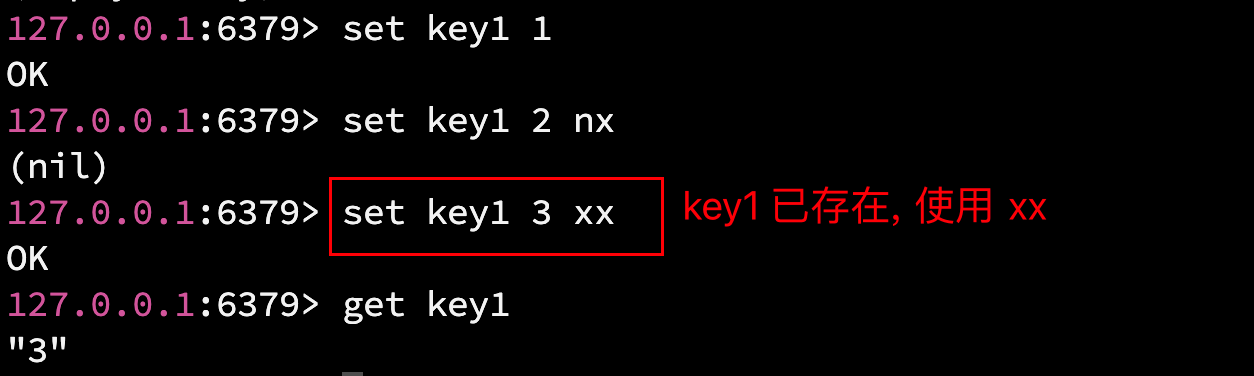
- setnx key seconds value : 相当于 set key value nx, 当 key 不存在时才设置, key 存在则设置失败.

- setex key seconds value : 相当于 set key value ex seconds, 创建 key 的并设置过期时间(单位是秒).

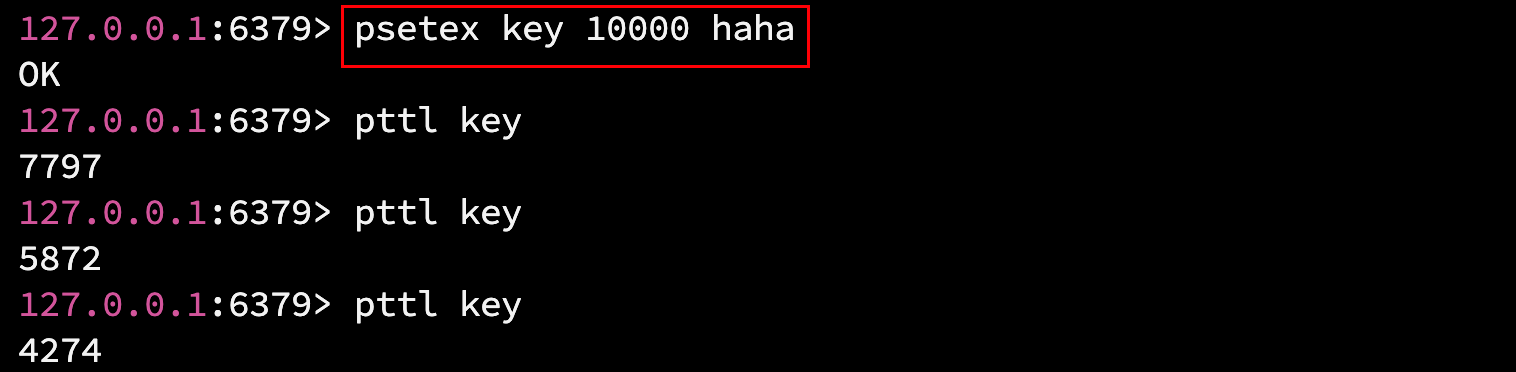
- psetex key milliseconds value : 相当于 set key value px milliseconds, 过期时间单位是毫秒.
3.2 mset / mget
上面提到的 set / get , 一次只能操作一组键值对.
而 mset 和 mget, 一次可以操作多组键值对.
语法:
- mset key value key value ...
- mget key key ...
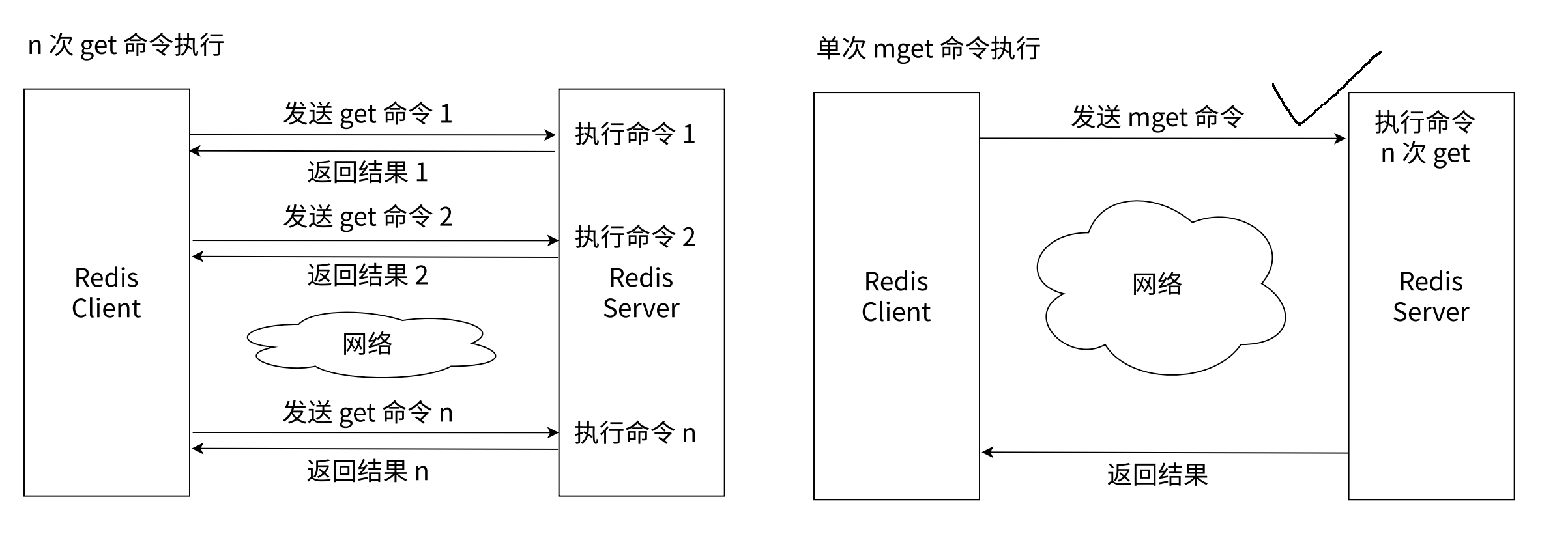
mset/mget 的时间复杂度为 O(N), 注: 这里的 N 指的是 mset/mget 命令中 key 的数量, 不是 Redis 服务器中所有 key 的数量.

当操作多组数据时, mset/mget 的效率是比 set/get 的效率要高的.
因为 Redis 是通过网络来接受命令的, 每个命令都需要进行一次网络 IO, 若有 N 组数据需要操作, 那么 mset/mget 只需一个命令, 一次网络 IO 即可. 而 set/get 则需 N 次命令, N 次网络 IO.
3.3 incr / incrby / decr / decrby / incrbyfloat
当 key 对应的 value 是数字时, 可以使用 incr / incrby / decr / decrby / incrbyfloat 操作 value 的值, 进行加减运算.
若value 是整数(8字节内)时 , 则使用 incr / incrby / decr / decrby:
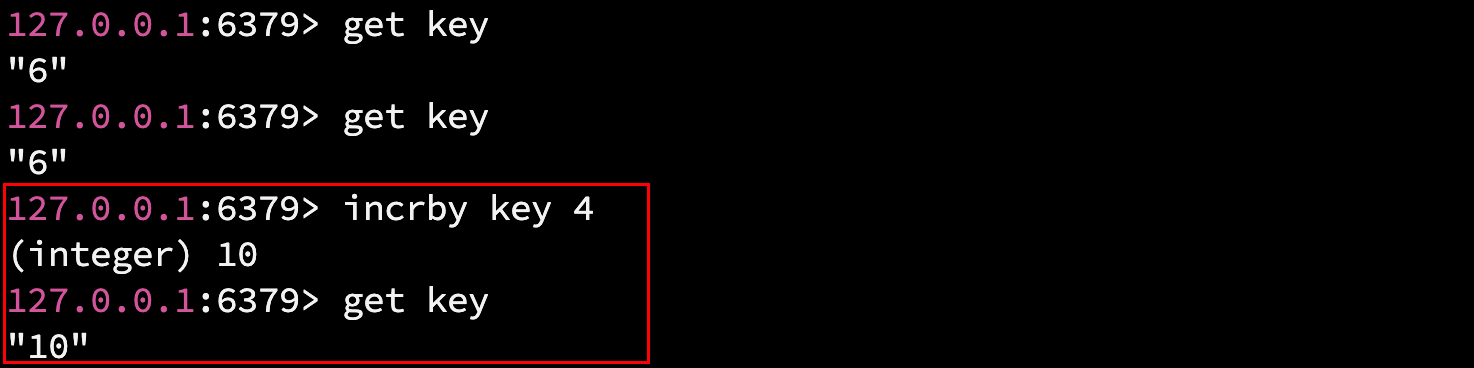
- incr key : 针对 value + 1

- incrby key n : 针对 value + n
- decr key : 针对 value - 1

- decrby key n : 针对 value - n

若value 是小数时 , 则使用 incrbyfloat:
- incrbyfloat key 小数 : 针对 value +/- 小数

上述所有操作的时间复杂度, 均为 O(1). 返回值是运算后的结果.
使用上述命令时, 如果 key 不存在, 则把 value 当做 0 进行计算:

注: 由于 Redis 是单线程模式, 因此多个 Redis-cli 对同一个 key 进行 incr/decr/... 操作, 不会引起 "线程安全" 问题.
3.4 append
如果 key 已存在, 并且 value 是 string, 使用 append 可以往 value 后拼接字符串.
如果 key 未存在, 那么 append 就相当于 set, 新建一个键值对.
语法为:append key 内容
返回值: 拼接后的字符串长度, 单位字节. 时间复杂度为 O(1)

注意:
append 返回的字符串长度, 单位是字节(Redis 没有字符编码集, 在内部只按字节存储数据)
假如 append 的内容是中文, 那么通过 get 展示出来的就是在 utf8 编码下 "你好" 二进制数据的十六进制形式:
我们通过终端输入 你好 , 终端的字符编码是 utf8, 而 utf8 中一个汉字通常是三个字节, 因此 你好 就是六个字节.
由于 Redis 展示的是汉字的十六进制形式, 不易观察. 因此, 在启动 Redis 客户端时, 可以加上 --raw 选项, Redis 客户端就会对二进制数据进行翻译, 将二进制数据返回为汉字:
Linux 终端快捷键:
- ctrl + l : 清除当前界面内容, 相当于 clear.
- ctrl + s : 冻结当前界面, 便于观察日志.
- ctrl + q : 解除冻结.


3.5 getrange
getrange 用于截取字符串的部分内容 , 类似于 Java 中的 substring 方法, 不同之处在于 Redis 的 getrange 是左闭右闭区间.
语法: getrange key start end
返回截取到子串, 时间复杂为 O(N), N 是指 start, end 区间的长度.
截取到的子串为 value start, end 区间(下标从 0 开始).

需要注意的是, 在 Redis 中, 下标是支持负数的:
- -1 代表倒数第一个元素(相当于 len - 1)
- -2 代表倒数第二个元素(相当于 len - 2)
- ......

如果对汉字进行 getrange 操作, 可能获取到的就是不是完整的汉字了:
这是因为 Redis 的 getrange 是按 字节 来截取的, 而不是按字符.
一个汉字在 UTF-8 编码下通常占用 3 个字节, 如果截取范围刚好落在字节中间, 就会导致结果无法正确解码成完整汉字, 出现其他符号.

3.6 setrange
使用 setrange 命令, 从指定字节的位置开始, 替换/覆盖 value 原有字符串的一部分.
语法: SETRANGE key offset value
返回值: 替换后的字符串长度.(以字节为单位)
- offset : 从第几个字节的位置开始替换.
- value : 要替换的新的字符串
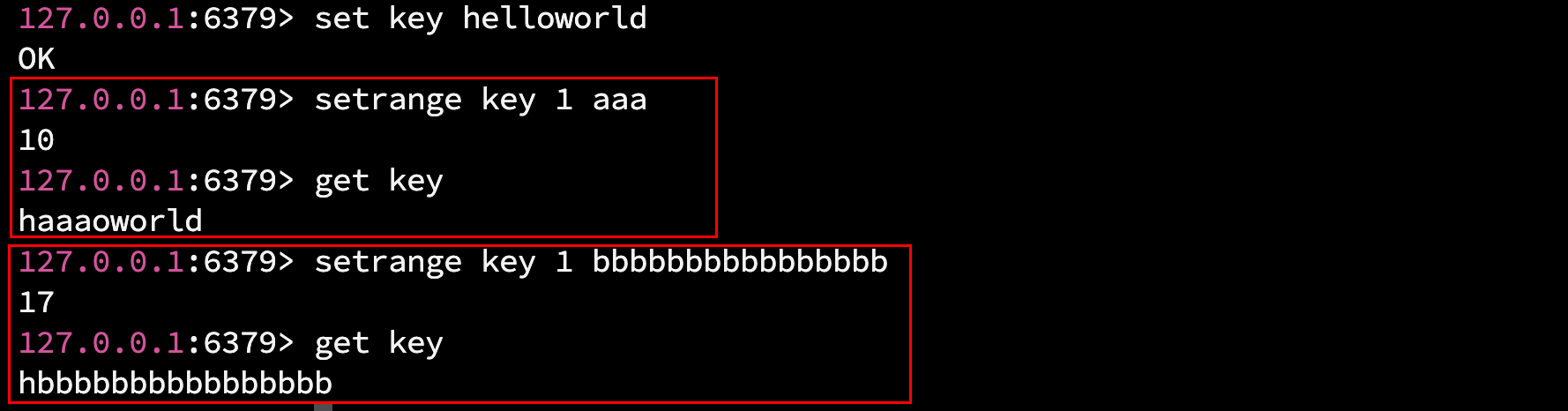
替换的字节长度以 setrange 中 新字符串的长度为准.
setrange 也可以操作不存在的 key , 但是会默认 offset 前的字节全是 '0x000' :

如果使用 setrange 操作中文字符, 需要处理好要覆盖的字节的长度.
3.7 strlen
使用 strlen 来获取字符串的长度(单位是字节).
返回值是 key 对应 value 的字节数.

Redis 客户端的编码方式是 utf8, 在 UTF-8 编码中, 一个英文字符占 1 个字节, 而一个中文字符占 3 个字节.
因此, 而"蔚来"是两个中文字符, 因此长度为 6 个字节.
在不同系统中,字符串长度的单位并不相同:
- **Redis :**按字节计数.
- MySQL / Java 等 : 按字符计数, 一个字符可能包含多个字节. 例如 MySQL 中使用
utf8编码的varchar(N),这个 N 表示字符数, 而非字节数, 这个 N 包括英文字符, 也包括中文字符.
不同字符集下, 一个汉字的字节数也不同:
- Java 的
char类型:使用 Unicode 编码, 一个汉字 = 2 字节. - Java 的
String类型:使用 UTF-8 编码, 一个汉字 = 3 字节.
使用 char 和 String 时, Java 在底层会自动完成 unicode 与 utf8 的转换,因此程序员感知不到.
3.8 string 内部编码
上文提高 Redis 的数据类型, 内部是有多种编码实现的, Redis 会根据特定的场景, 使用不同的内部编码, 来达到优化性能的效果.
string 类型有三种编码实现:
- raw : 存储长字符串时.
- embstr : 压缩字符串, 用于存储短字符串.
- int : 8 字节 / 64 位的整数.
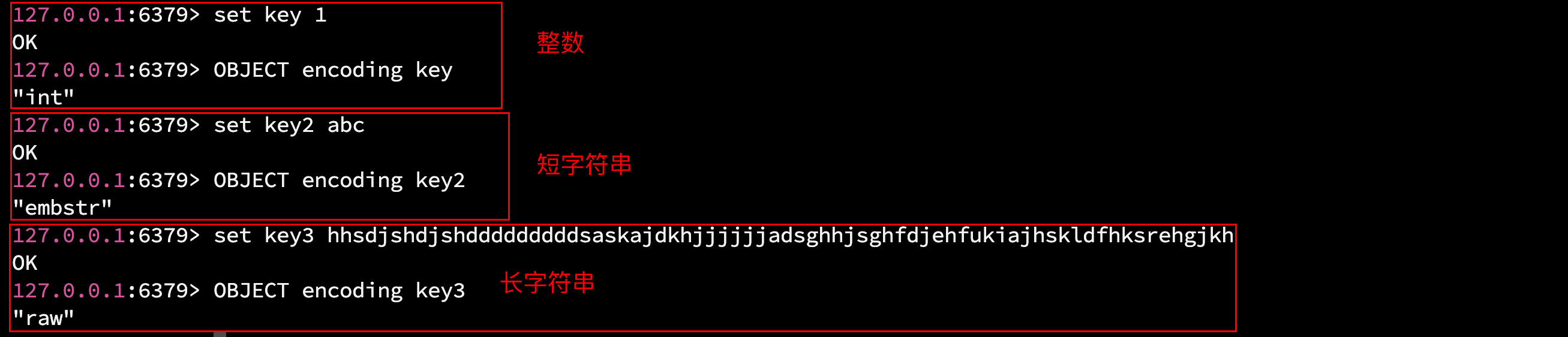
若存储的是小数, 那 Redis 还是当做字符串(raw/embstr)去存储的
3.9 string 应用场景
3.9.1 缓存
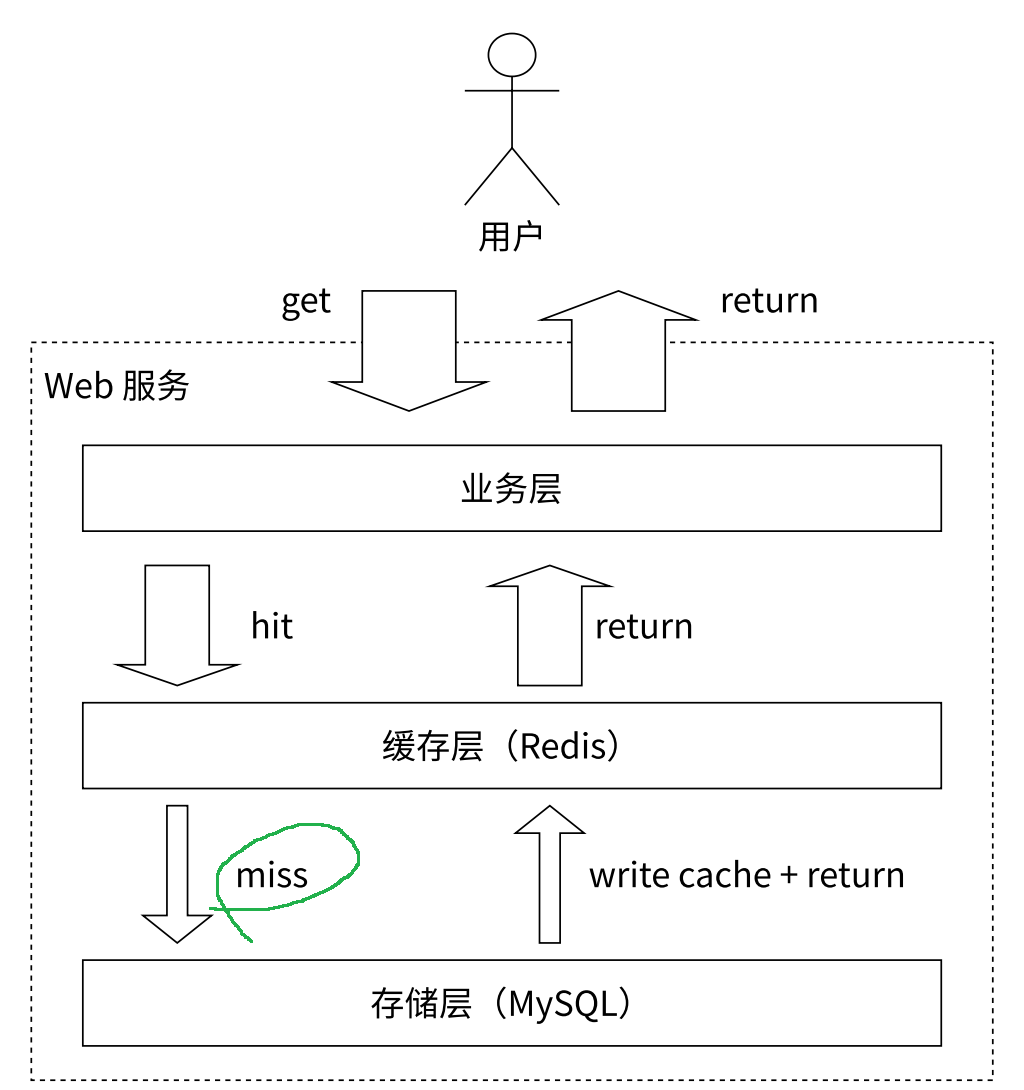
Redis 最常见是用作缓存, 把热点数据存到 Redis 中, 把全量数据存到数据库中, 应用服务器访问时, 先从 Redis 中查, 如果命中(hit)则直接返回. 如果没有命中, 则从数据库中查, 同时把查到的数据也存到 Redis 中.
对于 "热点" 数据, 需要结合具体的业务场景去划分, 常见的定义有:
- 把最近一段时间内, 访问次数做多的前 10% / 20% 的数据当做热点数据.
- 把最近访问的数据, 当做热点数据. (即假设: 某个数据一旦被用到, 那在最近的一段时间内, 这个数据还会被反复用到) 上文和下图, 就是根据这种方式定义的热点数据.
3.9.2 计数功能
Redis 可以存储整数, 记录视频/文章的阅读量点赞量等等...
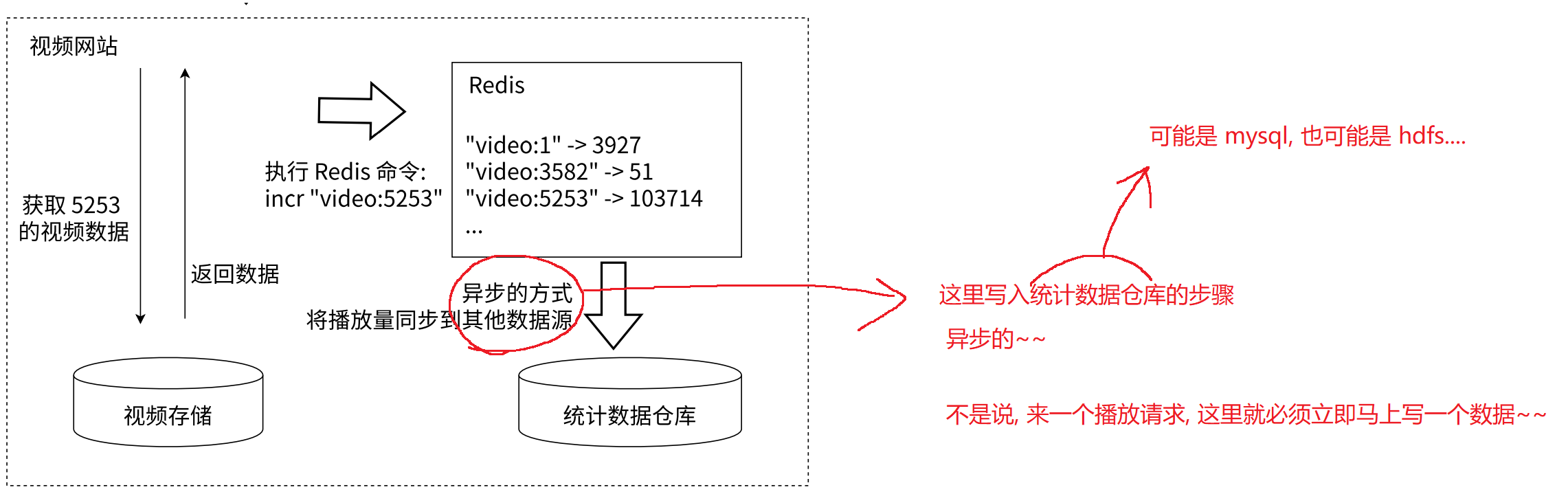
异步是指, 新建一个线程去执行任务, 以达到执行该任务不会阻塞当前主线程的目的.
这里的异步是指, 当主程序(视频网站)在 Redis 中更新计数后, 就会立即返回(这个过程是很快的). 而数据从 Redis 写入数据库的这一步骤, 则交由一个后台程序去完成, 不阻塞为用户提供服务的核心流程. (因为写入数据库的过程较慢, 异步的方式就可以保证不影响用户体验)
3.9.3 存储 session 会话
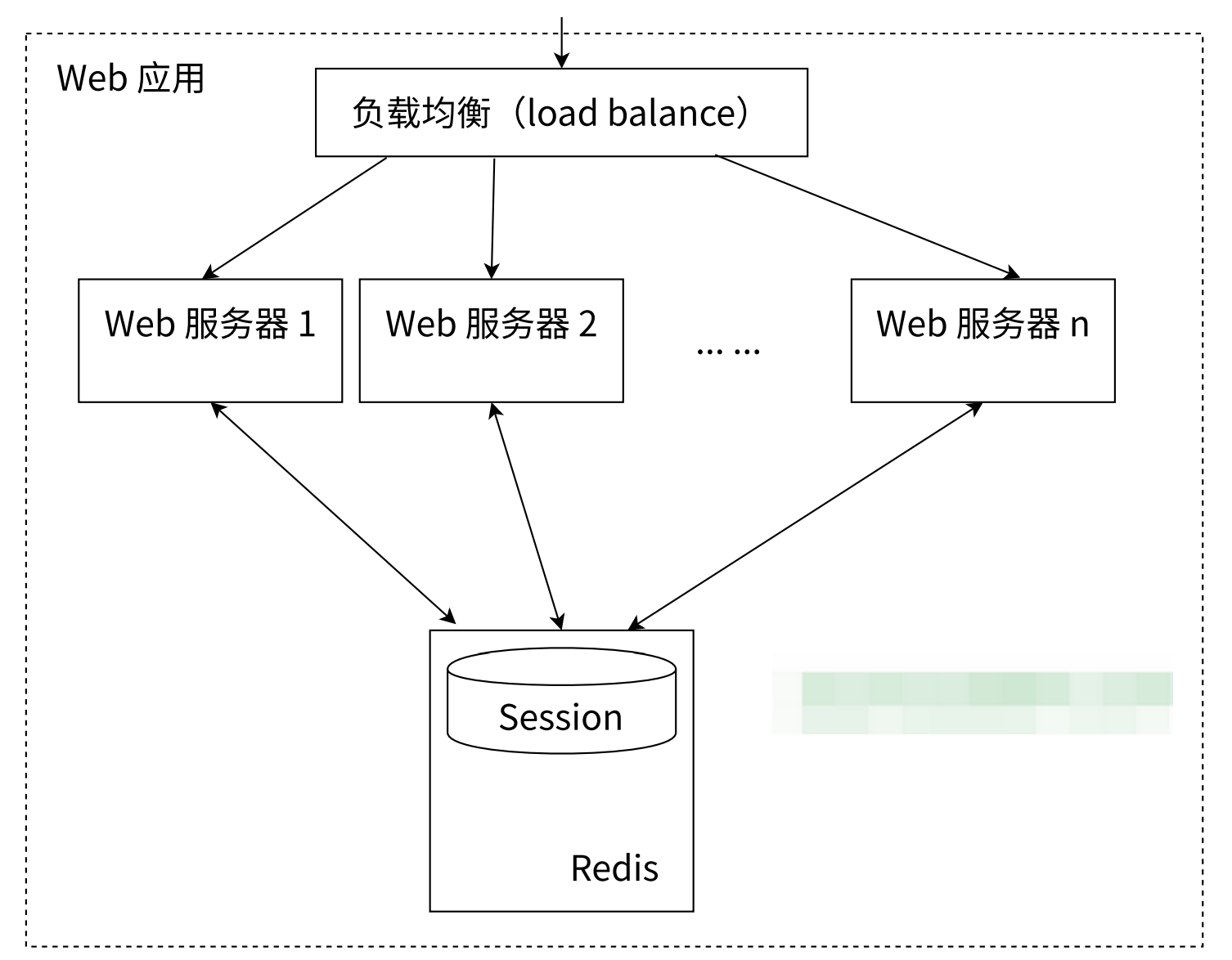
分布式系统中存在多台应用服务器, 如果每个应用服务器维护自己的 session 数据, 彼此之间不共享, 那么当用户请求到不同的服务器上时, 这些服务器就可能无法识别用户的身份.
当用户的 session 存储到 Redis 中后, 所有 Web 服务器都能从 Redis 查询到用户的 session, 实现 session 共享.
这样, 无论用户请求被负载均衡分发到哪台服务器, 都能正确识别其身份, 从而解决多节点间的登录状态同步问题.
3.10 string 命令总结
|----------------------------------|------------------------------|--------------------------|
| 命令 | 执行效果 | 时间复杂度 |
| set key value key value... | 设置 key 的值是 value | O(k), k 是键个数 |
| get key | 获取 key 的值 | O(1) |
| del key key ... | 删除指定的 key | O(k), k 是键个数 |
| mset key value key value ... | 批量设置指定的 key 和 value | O(k), k 是键个数 |
| mget key key ... | 批量获取 key 的值 | O(k), k 是键个数 |
| incr key | 指定的 key 的值 +1 | O(1) |
| decr key | 指定的 key 的值 -1 | O(1) |
| incrby key n | 指定的 key 的值 +n | O(1) |
| decrby key n | 指定的 key 的值 -n | O(1) |
| incrbyfloat key n | 指定的 key 的值 +n | O(1) |
| append key value | 指定的 key 的值追加 value | O(1) |
| strlen key | 获取指定 key 的值的长度 | O(1) |
| setrange key offset value | 覆盖指定 key 的从 offset 开始的部分值 | O(n), n 是字符串长度,通常视为 O(1) |
| getrange key start end | 获取指定 key 的从 start 到 end 的部分值 | O(n), n 是字符串长度,通常视为 O(1) |
end