简介
nanopb是一种小代码量的协议缓冲区实现,适用于任何内存受限的系统。
下载安装
直接在OpenHarmony-SIG仓中搜索nanopb并下载。
使用说明
以OpenHarmony 3.1 Beta的rk3568版本为例
-
将下载的Nanopb库代码存在以下路径:./third_party/nanopb
-
修改添加依赖的编译脚本,路径:/developtools/bytrace_standard/ohos.build
{
"subsystem": "developtools",
"parts": {
"bytrace_standard": {
"module_list": [
"//developtools/bytrace_standard/interfaces/innerkits/native:bytrace_core",
"//developtools/bytrace_standard/bin:bytrace_target",
"//developtools/bytrace_standard/bin:bytrace.cfg",
"//developtools/bytrace_standard/interfaces/kits/js/napi:bytrace",
"//third_party/nanopb:protobuf-nanopb",
"//third_party/nanopb:hiperf_nanopb_test"
],
"inner_kits": [
{
"type": "so",
"name": "//developtools/bytrace_standard/interfaces/innerkits/native:bytrace_core",
"header": {
"header_files": [
"bytrace.h"
],
"header_base": "//developtools/bytrace_standard/interfaces/innerkits/native/include"
}
}
],
"test_list": [
"//developtools/bytrace_standard/bin/test:unittest"
]
}
}
} -
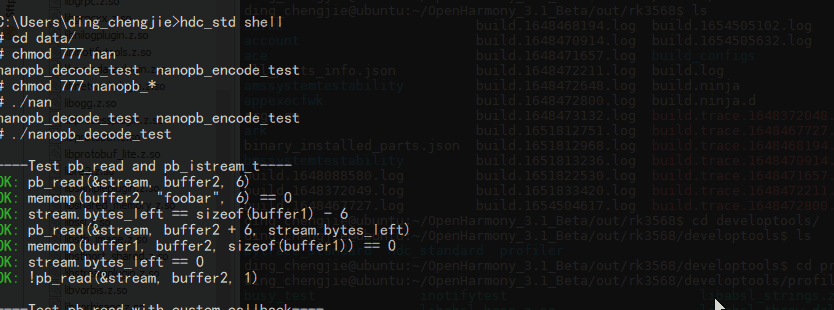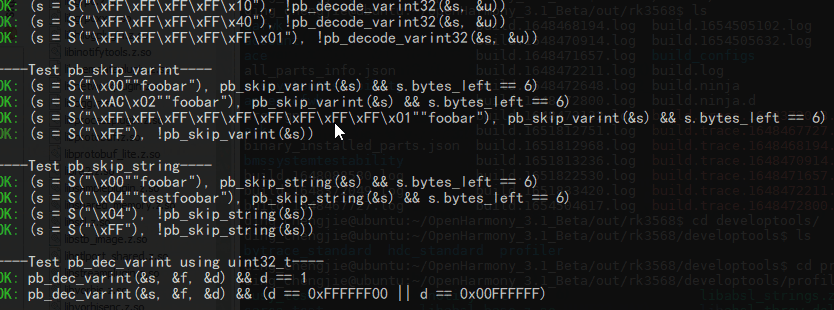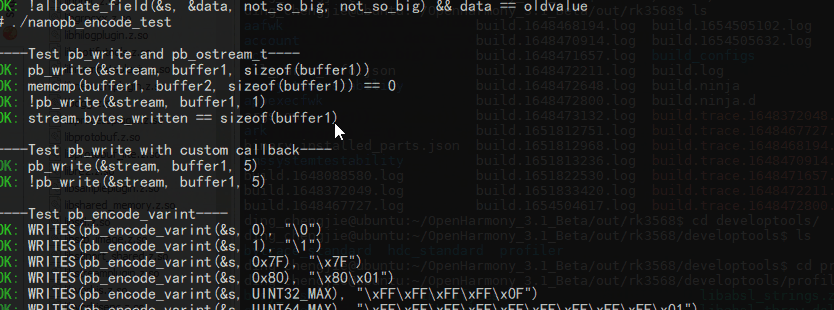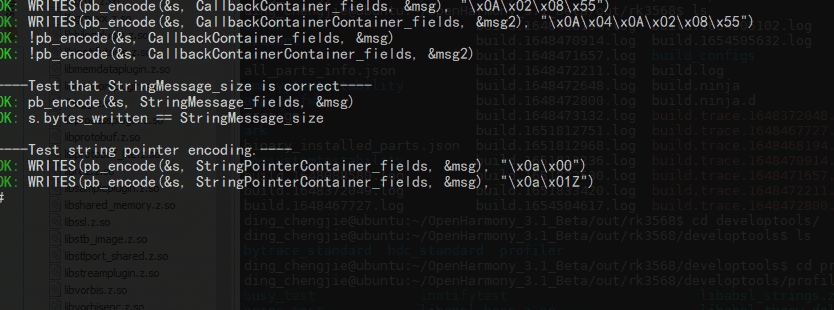
编译:./build.sh --product-name rk3568 --ccache
-
生成库文件和一些可执行测试文件,路径:out/rk3568/developtools/profiler
接口说明
- 从流中获取当前错误消息,如果没有错误消息,则获取占位符字符串:
PB_GET_ERROR() - 设置错误消息并返回false:
PB_RETURN_ERROR() - 构造输出流以写入内存缓冲区:
pb_ostream_from_buffer() - 将数据写入输出流:
pb_write() - 将结构的内容编码为协议缓冲区消息,并将其写入输出流:
pb_encode() - 使用标志设置的扩展行为对消息进行编码:
pb_encode_ex() - 计算编码消息的长度:
pb_get_encoded_size() - 以varint格式对有符号或无符号整数进行编码。适用于类型为bool、enum、int32、int64、uint32和uint64的字段:
pb_encode_varint() - 将字符串的长度写入变量,然后写入字符串的内容。适用于字节和字符串类型的字段:
pb_encode_string() - 将4个字节写入流,并在big-endian体系结构上交换字节。适用于fixed32、sfixed32和float类型的字段:
pb_encode_fixed32() - 将8个字节写入流,并在big-endian体系结构上交换字节。适用于fixed64、sfixed64和double类型的字段:
pb_encode_fixed64() - 对32位浮点值进行编码,使其在编码消息中显示为64位双精度:
pb_encode_float_as_double() - 对子消息字段进行编码,包括其大小标头:
pb_encode_submessage() - 创建从内存缓冲区读取数据的输入流helper函数:
pb_istream_from_buffer() - 从输入流读取数据:
pb_read() - 读取和解码结构的所有字段:
pb_decode() - 与pb_decode相同,但允许扩展选项:
pb_decode_ex() - 释放任何动态分配的字段:
pb_release() - 从流中删除字段的数据,而不进行实际解码:
pb_skip_field() - 读取并解码可变编码整数:
pb_decode_varint() - 与pb_decode_varint相同,但将值限制为32位:
pb_decode_varint32() - 解码fixed32、sfixed32或浮点值:
pb_decode_fixed32() - 解码fixed64、sfixed64或double值:
pb_decode_fixed64() - 将64位双精度值解码为32位浮点变量:
pb_decode_double_as_float() - 使用导线类型PB\U WT\U字符串解码字段的长度,并创建用于读取数据的子流:
pb_make_string_substream() - 关闭使用pb_make_string_substream创建的子流:
pb_close_string_substream() - 开始迭代消息类型中的字段:
pb_field_iter_begin() - 前进到消息中的下一个字段:
pb_field_iter_find() - 验证UTF8编码的字符串:
pb_validate_utf8()
兼容性
支持OpenHarmony API version 8 及以上版本。
目录结构
|---- nanopb
| |---- docs #数据文件
| |---- examples
| |---- cmake_relpath #使用CMake的Nanopb示例
| |---- cmake_simple #使用CMake的Nanopb示例
| |---- network_server #使用nanopb通过网络进行通信连接示例
| |---- simple #Nanopb简单示例
| |---- using_double_on_avr #在avr编译器上使用双精度数据类型的Nanopb示例
| |---- using_union_messages #使用union消息的Nanopb示例
| |---- tests #测试文件
| |---- tools #不同系统打包工具
| |---- pb.h #nanopb库的常见部分
| |---- pb_common.c #pb_encode.c和pb_decode.c的通用支持功能
| |---- pb_common.h #pb_encode.c和pb_decode.c的通用支持功能
| |---- pb_decode.c #使用最少的资源解码protobuf
| |---- pb_decode.h #用于解码协议缓冲区的函数
| |---- pb_encode.c #使用最少的资源对protobuf进行编码
| |---- pb_encode.h #对协议缓冲区进行编码的函数
| |---- README.md #安装使用方法写在最后
如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
- 点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
- 关注小编,同时可以期待后续文章ing🚀,不定期分享原创知识。
- 想要获取更多完整鸿蒙最新学习资源,请移步前往小编:
gitee.com/MNxiaona/733GH
