说明
此文档主要说明一些常见compaction问题的排查思路和临时处理手段。这些问题包括
- Compaction socre高
- Compaction失败
- compaction占用资源多
- Compaction core
如果问题紧急,可联系社区同学处理
如果阅读中有问题,可以反馈给社区同学。
1 compaction score高
找出score最高的若干个tablet,一般是用户比较高频导入的表
分析score最高的tablet形成的原因,以下几个为常见的原因
1.1 compaction持续失败导致的compaction socre高
判断方式:
1 grep ${tablet_id} be.INFO | grep compaction,看是否有持续失败的日志
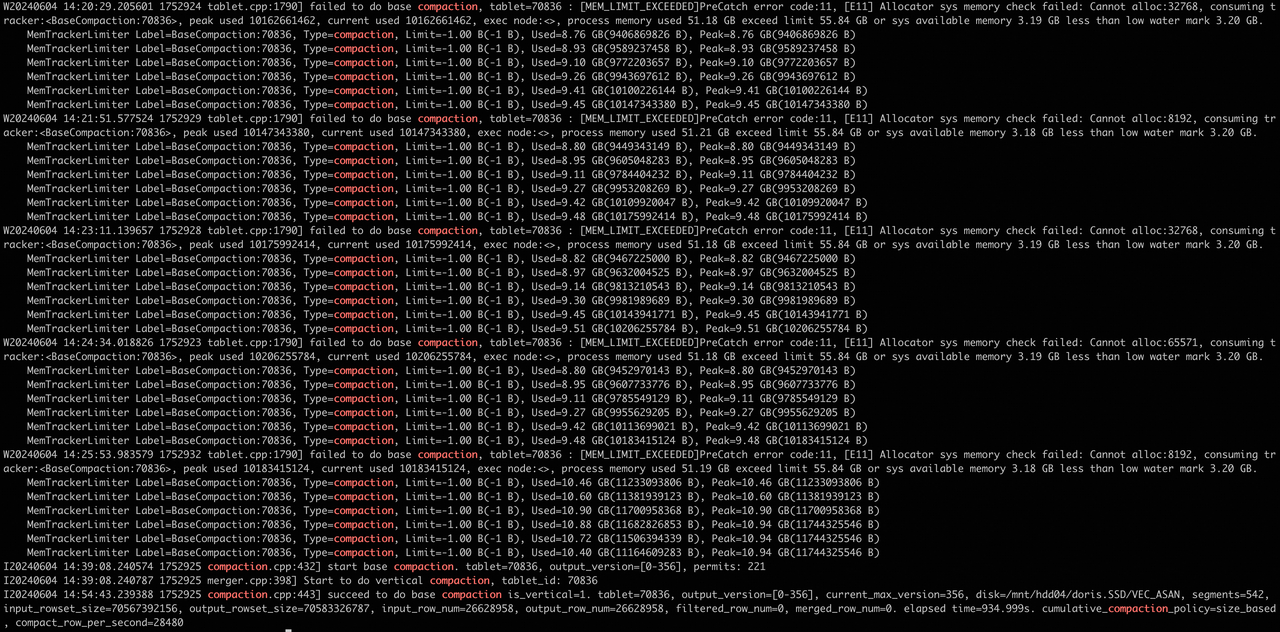
2 curl ip:port/api/compaction/show?tablet_id=${tablet_id} ,可以看curl命令查看compaction status,目前只有base的status。
处理方式:参照第2节进行处理
1.2 用户使用不当
1.2.1 建表时,bucket数量设置的不合适。
设置的太小,导致的compaction可能不能充分并发执行。
设置的太多,可能会有比较多的compaction任务调度。
建议根据tablet 1GB - 10GB的最佳实践,设置bucket数量
其他使用不当的方式,待补充...
1.3 compaction策略问题
score很高的tablet,却很久没有执行过compaction
判断方式:
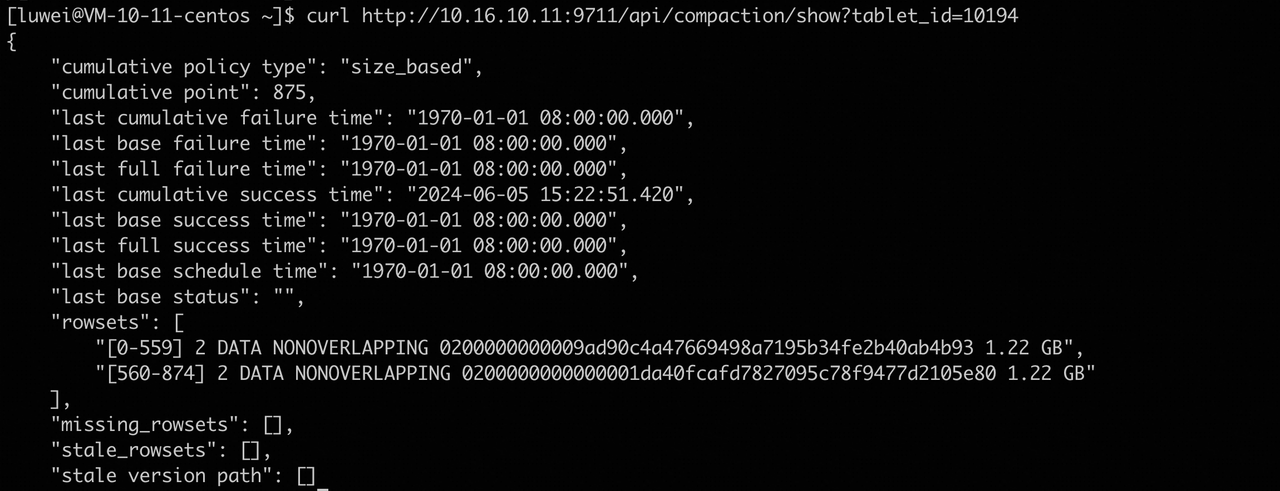
1 通过curl ip:port/api/compaction/show?tablet_id=${tablet_id} 查看tablet compaction上一次执行的时间。
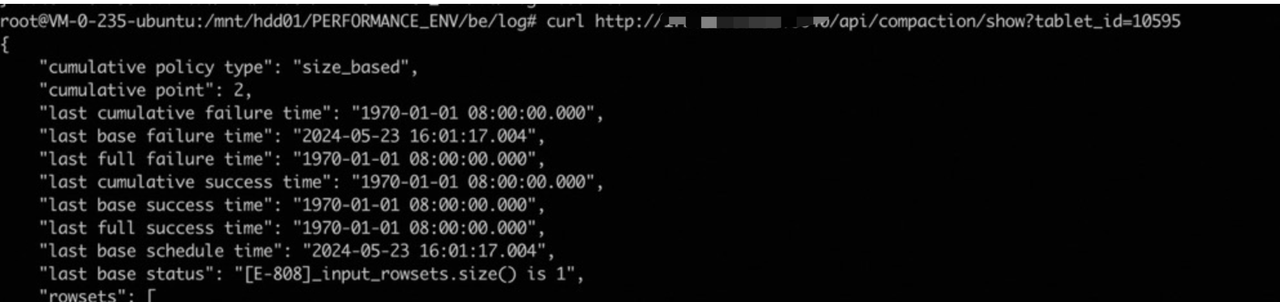
2 grep ${tablet_id} be.INFO | grep compaction,看该tablet compaction执行的历史,是否该tablet很长时间没有进行compaction
处理方式:
1 临时处理手段,手动触发compaction:
curl -X POST http://be_host:webserver_port/api/compaction/run?tablet_id=xxxx&compact_type=cumulative
2 这类问题可能是策略的bug,需要联系社区同学跟进处理,需要以下信息
Compaction score的监控
Compaction score从低到高涨上来时BE的日志
Compaction score比较高的tablet的rowset 布局,通过curl ip:port/api/compaction/show?tablet_id=${tablet_id} 可以拿到
1.4 导入速度超过了compaction的速度
这里又分为两种情况
1.4.1 cpu负载不高
可能是compaction的并发不够,需要调整下面这些配置(根据情况修改)
max_base_compaction_threads 默认是4
max_cumu_compaction_threads 默认是每个盘1个
compaction_task_num_per_disk,默认是4
compaction_task_num_per_fast_disk,默认是8判断方式:
1 查看compaction 一段时间内的平均并发数
cloud使用这个命令
grep -i compaction be.INFO | grep -i finish | awk '{print $8}' | awk -F\| '{print $1}' | awk -Fms '{print $1}' | awk -F= '{sum+=$2} END {print sum}'开源doris使用这个命令
cat be/log/be.INFO | grep -E "succeed to do base compaction|succeed to do cumulative compaction" | awk '{print $23}' | awk -F= '{print $2}' | awk -Fs '{sum+=$1} END {print sum}'- 用上述的命令统计一段时间内compaction的总耗时(注意,cloud统计出的耗时单位是毫秒,而社区统计出的耗时单位是秒)。比如耗时是4000秒
- 计算统计的clock time,比如统计的日志文件包含14:00 到 14:20日志,那clock time = 20min * 60 = 1200秒
- compaction的平均并发 4000 / 1200 = 3.3 并发
2 获取BE的配置的并发限制和compaction线程数量,查看BE conf,如果没有配置则为默认
如果实际的并发已经接近设置的并发,则是并发不足
1.4.2 cpu负载比较高
处理方式:
1 如果BE的负载比较高,且用户的导入比较高频,看下能否攒批导入,降低导入频率
2 如果导入频率也不高,则需要考虑扩容
1.5 compaction score持续升高,导致导入报-235
这种现象之前出现的比较多,单独列出来,这是一个现象,原因可能还是上述的一种,针对此现象有一个临时的处理手段,如果对报-235的表没有频繁的导入和查询,可以适当调大max_tablet_version_num。这只是一个临时手段,还是要找到compaction score升高的原因
max_tablet_version_num,默认值是2000
2 Compaction 失败
2.1 定位问题
通过grep compaction be.INFO | grep {tablet_id} 查看compaction失败的具体原因。
原因包括但不限于,内存分配失败,compaction数据校验失败
2.1.1 内存问题
内存分配失败会有类似一下日志
W0427 19:40:58.254163 7873 compaction.cpp:372] fail to do CloudBaseCompaction. res=[MEM_LIMIT_EXCEEDED]PreCatch error code:11, [E11] Allocator sys memory check failed: Cannot alloc:5148, consuming tracker:<BaseCompaction:135202205>, peak used 1435738416, current used 1164740816, exec node:<>, process memory used 105.03 GB exceed limit 109.63 GB or sys available memory 11.71 GB less than low water mark 12.18 GB.
no enable stack, _FILE:/home/ec2-user/selectdb-core/be/src/olap/rowset/segment_v2/segment_iterator.cpp, __LINE:2000, __FUNCTION_:auto doris::segment_v2::SegmentIterator::next_batch(vectorized::Block *)::(anonymous class)::operator()() const, tablet=135202205.758764227.6e8b36c0cc1b4ac2-9f14bb5b6d058fe6, output_version=[2-8237]内存问题又分为以下几种情况
- compaction本身占用内存不多,BE其他的请求(比如导入,查询)占用了过多的内存,导致的compaction偶发失败。
- 单个compaction占用内存多
- 多个compaction占用内存多
对于上述细分的原因需要查看memtracker,当前compaction内存使用的情况来定位。
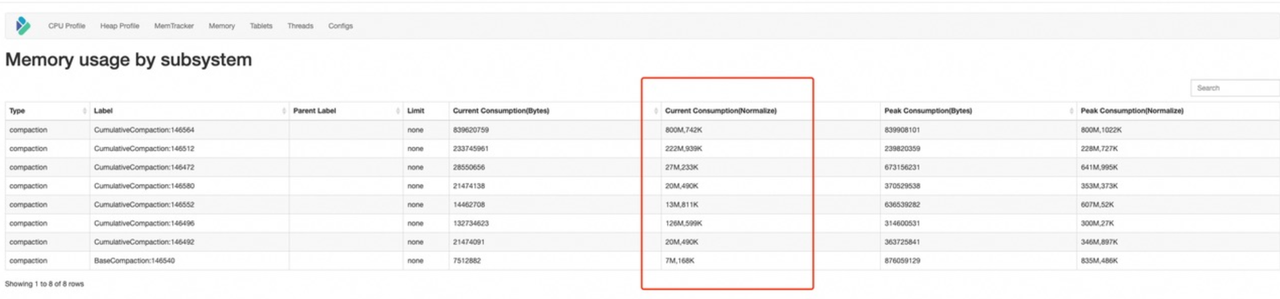
2.1.2 compaction校验失败
if (_input_row_num != _output_rowset->num_rows() + _stats.merged_rows + _stats.filtered_rows) {
return Status::Error<CHECK_LINES_ERROR>(
"row_num does not match between cumulative input and output! tablet={}, "
"input_row_num={}, merged_row_num={}, filtered_row_num={}, output_row_num={}",
_tablet->tablet_id(), _input_row_num, _stats.merged_rows, _stats.filtered_rows,
_output_rowset->num_rows());
}2.2 处理方式
2.2.1 内存问题
细分原因1:compaction本身占用内存不多,BE其他的请求(比如导入,查询)占用了过多的内存,导致的compaction偶发失败。
本身问题不在compaction,可以观察下,如何compaction不是持续的失败,并且compaction score没有明显的身高,可以暂不处理,持续观察。
细分原因2:单个compaction占用内存多
可以暂时通过限制参与compaction的rowset个数来限制compaction的使用,调节BE的cumulative_compaction_max_deltas这个配置值,默认是1000
细分原因3:多个compaction占用内存多
可以暂时通过限制参与compaction的rowset个数来限制compaction的使用,调节BE的cumulative_compaction_max_deltas这个配置值,默认是1000
或者:
可以通过限制compaction线程的个数来限制内存,be对应配置,max_base_compaction_threads和max_cumu_compaction_threads
2.2.2 compaction 校验失败
可能是正确性问题,需联系社区同学定位处理
3 compaction占用资源多
3.1 compaction占用cpu资源多
top -H 确认是否是compaction线程
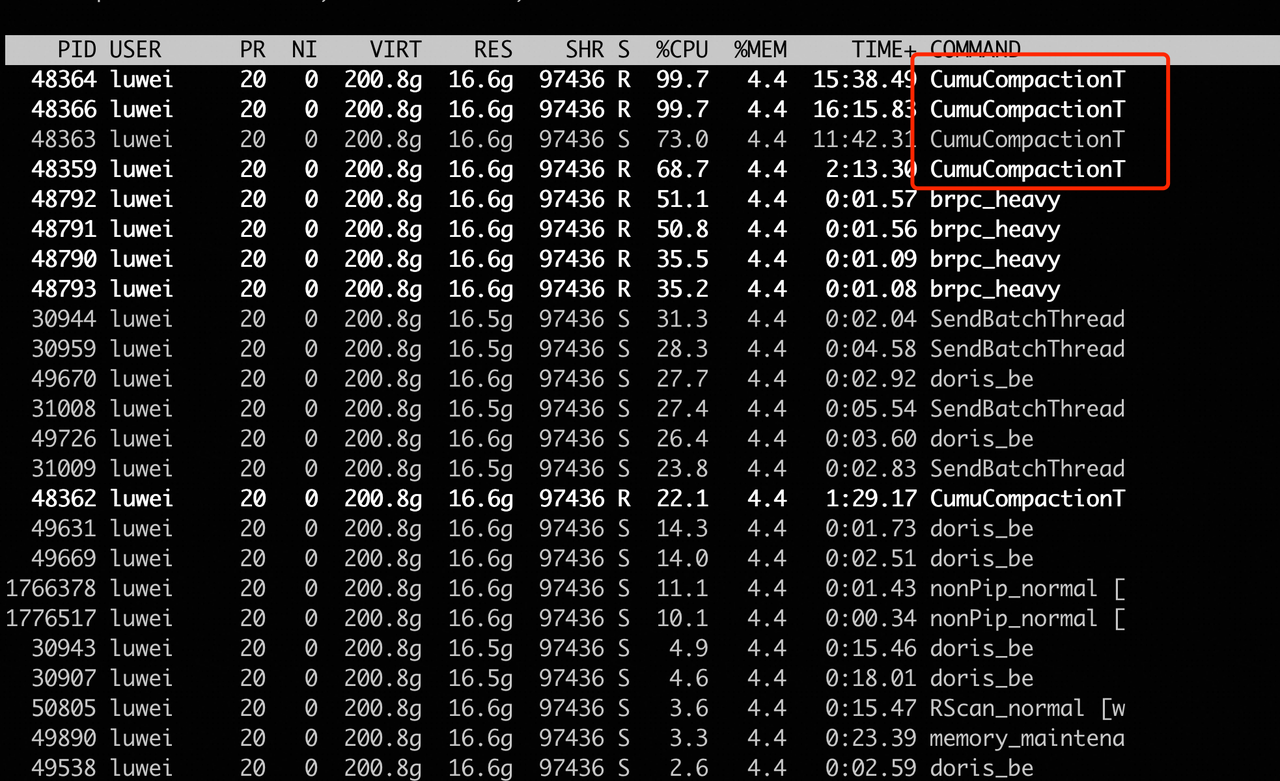
处理方式
处理方式1
可以调整做compaction的线程数量
max_base_compaction_threads,默认是4
max_cumu_compaction_threads,默认每块盘1个处理方式2
可以调整每个盘上compaction的并发数量
如果配置的是HDD盘,调整compaction_task_num_per_disk,
如果配置的是SSD盘,调整compaction_task_num_per_fast_disk
compaction_task_num_per_disk,默认是4
compaction_task_num_per_fast_disk,默认是8调节完,要主要观察compaction score的变化,防止出现compaction并发限制的太小,导致的compaction score升高的问题
3.2 compaction占用内存资源多
参考第二节关于内存超限导致compaction失败的处理方式
4 compaction导致BE core
分情况处理
偶发一次:
收集be.out,BE.info,core dump,be版本信息(包括具体的commit id),判断是否有特殊的操作,比如scheam change等操作,然后联系社区同学
持续失败:
这种情况可能会影响用户的可用性,可以先止损。关掉这个表的compaction
1 先通过导致compaction的tablet id找到表,show tablet {tablet_id}命令可以找到表名
2 关闭这个BE的compaction,配置BE.conf disable_auto_compaction = true
3 关掉这个表的compaction,alter table ${tableName} set ("disable_auto_compaction" = "true")
4 打开BE的compaction,配置BE.conf disable_auto_compaction = false
虽然core在compaction的栈上,但是很可能不是compaction的问题,因为compaction是一个后台的不断进行的读写线程,不断的触发读写。很可能查询也会core,只是没有进行查询,所以通过compaction暴露了这个问题。对于此类core,需要联系社区的同学定位处理。