1.项目背景
家庭烹饪作为日常生活的重要组成部分,不仅关乎健康,也是家庭情感交流的重要方式。
相信很多小伙伴在烹饪时也会困惑:不知道如何选择合适的食材和菜谱,或者缺乏灵感来创造新的菜品。
最近看到一本《家庭实用菜谱大全》,就想能不能结合它做一款推荐家常菜谱的专属大模型出来。
PaddleNLP大模型套件是一个基于飞桨(PaddlePaddle)开发的大语言模型(LLM)开发库,提供了大量的预训练 LLM 和高级 API,本次分享我们将尝试用飞桨的大模型套件,进行指令微调,做一款能够推荐菜品、具体食材和做法的大模型。
先简单画一个框架图,盘点一下本项目的具体工作,希望给感兴趣的同学一点大模型应用上的参考和帮助。
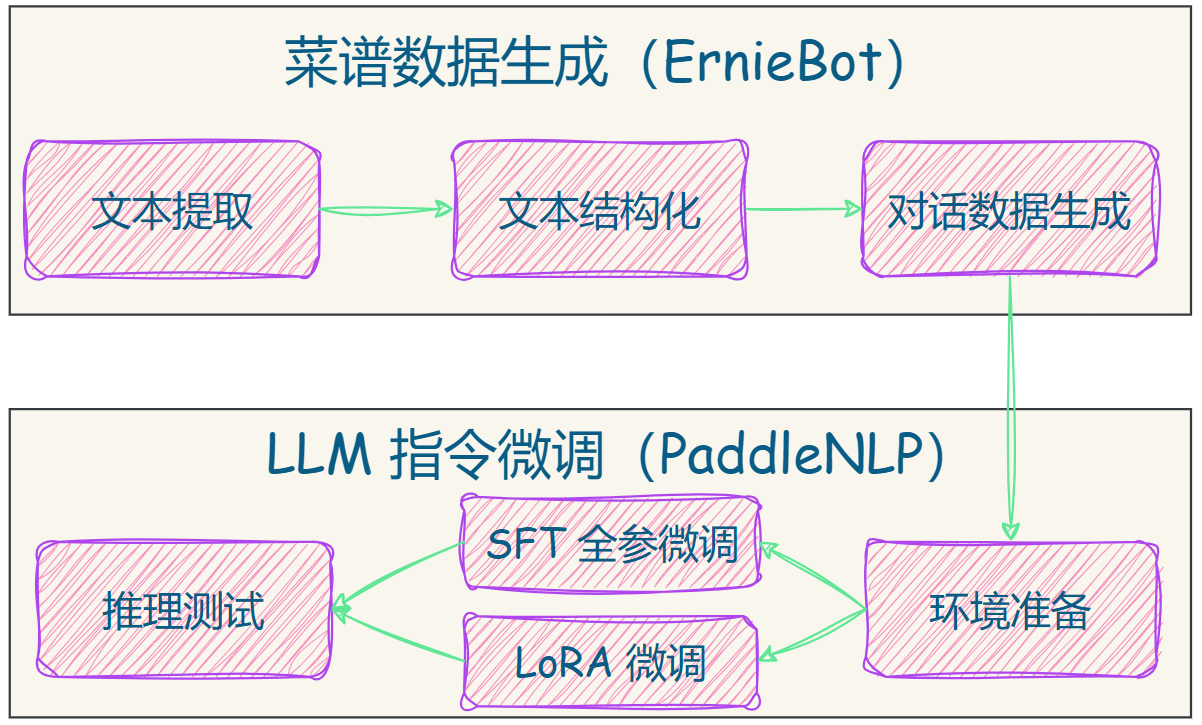
2. 百度 AI Studio 平台
本次将采用 AI Studio 平台中的免费 GPU 资源,在平台注册账号后,点击创建项目-选择 NoteBook 任务,然后添加数据集,如下图所示,完成项目创建。启动环境选择 GPU 资源。
创建项目的方式有两种:
- 一是在 AI Studio 平台参考如下方式,新建项目。
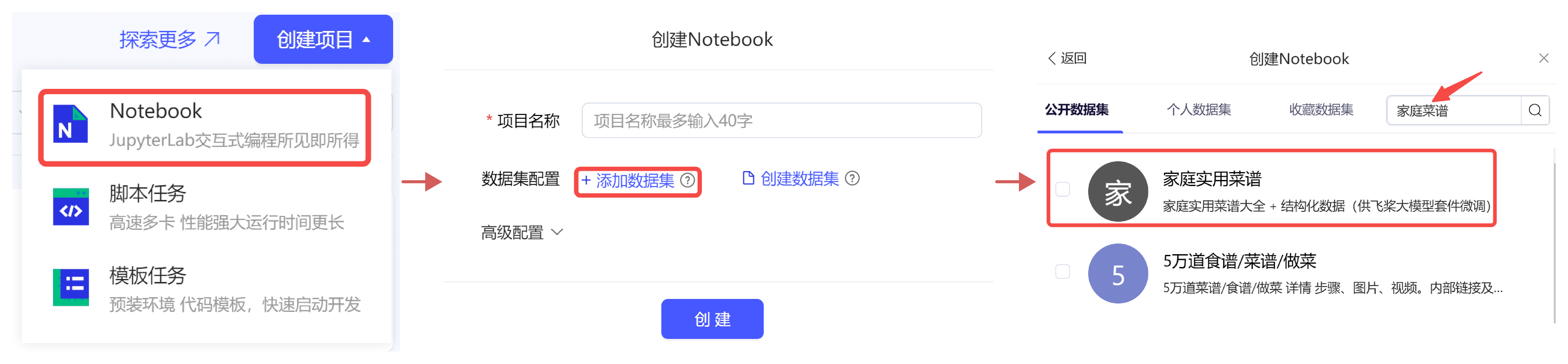
- 二是直接 fork 一个平台上的已有项目,选择【PaddleNLP大模型微调】从0打造你的专属家常菜谱管家的最新版本,点击 fork,成功后会在自己账号下新建项目副本,其中已经挂载了项目数据集和核心代码。

为了快速跑通项目流程,建议直接 fork 源项目。
3. 开始实战
3.1 菜谱数据生成
注:大模型微调使用的对话数据,已经上传到数据集中,可直接跳转到 3.2 进行微调使用。本节将主要介绍数据的制作过程,供感兴趣的同学参考。
首先我们准备一个虚拟环境,这样每次重启项目时,无需重新安装项目依赖
打开一个终端,在根目录下创建一个虚拟环境:
conda create -p /home/aistudio/envs/bot python=3.10一键启动虚拟环境:
source activate /home/aistudio/envs/bot/进入项目目录,安装相关依赖:
cd /home/aistudio/recipe_bot/
pip install -r requirements.txt3.1.1 文本提取
本次用于菜谱信息提取的文档,存放在加载的数据集中:/home/aistudio/data/data290409/家庭实用菜谱大全.pdf
参考代码:/home/aistudio/recipe_bot/core.py
我们首先需要将文档中的文本信息提取出来,可以采用两种方法:
- 方式一:PDF 文字提取:选用 PyPDF2
- 方式一:文字识别 OCR,选用 PaddleOCR
方式一实现:
from PyPDF2 import PdfReader
def pypdf_to_txt(input_pdf, output_path='data/pypdf'):
if not os.path.exists(output_path):
os.makedirs(output_path)
pdf_reader = PdfReader(input_pdf)
# 遍历PDF的每一页
for page_num in tqdm(range(len(pdf_reader.pages)), desc='pypdf_to_txt'):
page = pdf_reader.pages[page_num]
text = page.extract_text()
# 将文本写入txt文件
with open(f'{output_path}/{page_num:03d}.txt', "w", encoding="utf-8") as f:
f.write(text)
if __name__ == '__main__':
pypdf_to_txt('/home/aistudio/data/data290409/家庭实用菜谱大全.pdf')方式二实现:
from paddleocr import PaddleOCR
ppocr = PaddleOCR(use_angle_cls=True, debug=False)
def img_ocr(img_path=None, img_data=None):
if img_data is not None:
img = img_data
else:
img = cv2.imread(img_path)
result = ppocr.ocr(img)[0]
texts = []
if result:
for line in result:
# box = line[0]
text = line[1][0]
texts.append(text)
return '\n'.join(texts)
def pdfocr_to_txt(input_pdf, output_path='data/ocr'):
if not os.path.exists(output_path):
os.makedirs(output_path)
pdf_document = fitz.open(input_pdf)
# 遍历PDF的每一页
for page_num in tqdm(range(pdf_document.page_count)):
if os.path.exists(f'{output_path}/{page_num:03d}.txt'):
continue
page = pdf_document.load_page(page_num)
pm = page.get_pixmap()
pm.save("temp.png")
img = cv2.imread("temp.png")
texts = img_ocr(img_data=img)
with open(f'{output_path}/{page_num:03d}.txt', "w", encoding="utf-8") as f:
f.write(texts)
if __name__ == '__main__':
pdfocr_to_txt('/home/aistudio/data/data290409/家庭实用菜谱大全.pdf')上述代码会将每一页文本内容提取出来保存成 .txt 文件,给大家展示下两种方法提取的结果(左-方法一,右-方法二):
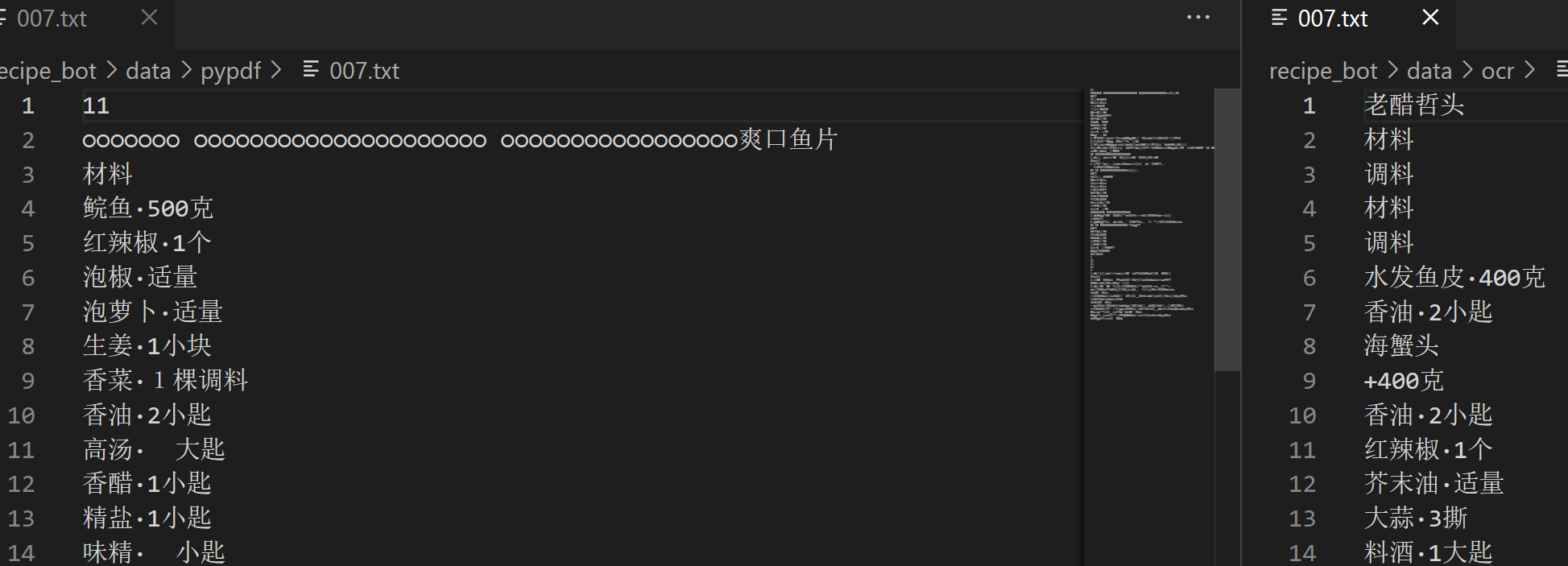
我们发现,单纯的 OCR 无法胜任文档结构化任务,相对方法二,方法一PyPDF2提取的内容更符合预期一点,不过依然不是我们想要的内容。
此时,不得不祭出最擅长文本结构化的 LLM 了~
3.1.2 文本结构化
LLM 我们选择直接调用百度开放的 ErnieBot API,省去本地部署的麻烦。
参考代码:/home/aistudio/recipe_bot/llm.py
注:调用 ErnieBot API,需要在代码中指定erniebot.access_token,可以通过如下方式获取:右上角账号头像-个人中心-访问令牌。
首先,编写对话代码:
def chat_completion(text='', system='', messages=[], model='ernie-3.5'):
if not messages:
messages = [{'role': 'user', 'content': text}]
response = erniebot.ChatCompletion.create(
model=model,
messages=messages,
system=system
)
return response.get_result()然后,编写给 LLM 的角色提示词:
system_reorg = '''
您是经验丰富的星级大厨和文档解析大师,擅长从图片中提取的文本中精准提取出结构化信息。我会给你文本内容,其中包括3-4道菜谱内容,因为文本内容是通过OCR识别出来的,所以内容有些错乱,您需要从中提取出每道菜的【菜名、材料、调料、做法、特点和厨师一点通】,并整理成markdown格式输出。
要求:
1. 直接回答提取内容即可,不要回答其他任何内容。
2. 整理成markdown格式输出,但不需要加```markdown和```。
3. 输出的markdown格式如下:
## 菜名1
### 材料
- 材料1 - 数量/重量
--- 此处省略,完整提示词可参考项目代码 ---
'''下面,编写批量化处理代码:
# 获取菜品信息
def get_recipe_info(input_path='data/pypdf', output_path='data/md/recipe'):
if not os.path.exists(output_path):
os.makedirs(output_path)
files = os.listdir(input_path)
for file in tqdm(files):
output_file = os.path.join(output_path, file.replace('.txt', '.md'))
if os.path.exists(output_file):
continue
text = open(os.path.join(input_path, file), 'r').read()
result = chat_completion(text=text, system=system_reorg)
if result:
with open(output_file, 'w') as f:
f.write(result)
if __name__ == '__main__':
get_recipe_info()给大家看下 ErnieBot 提取的结果:
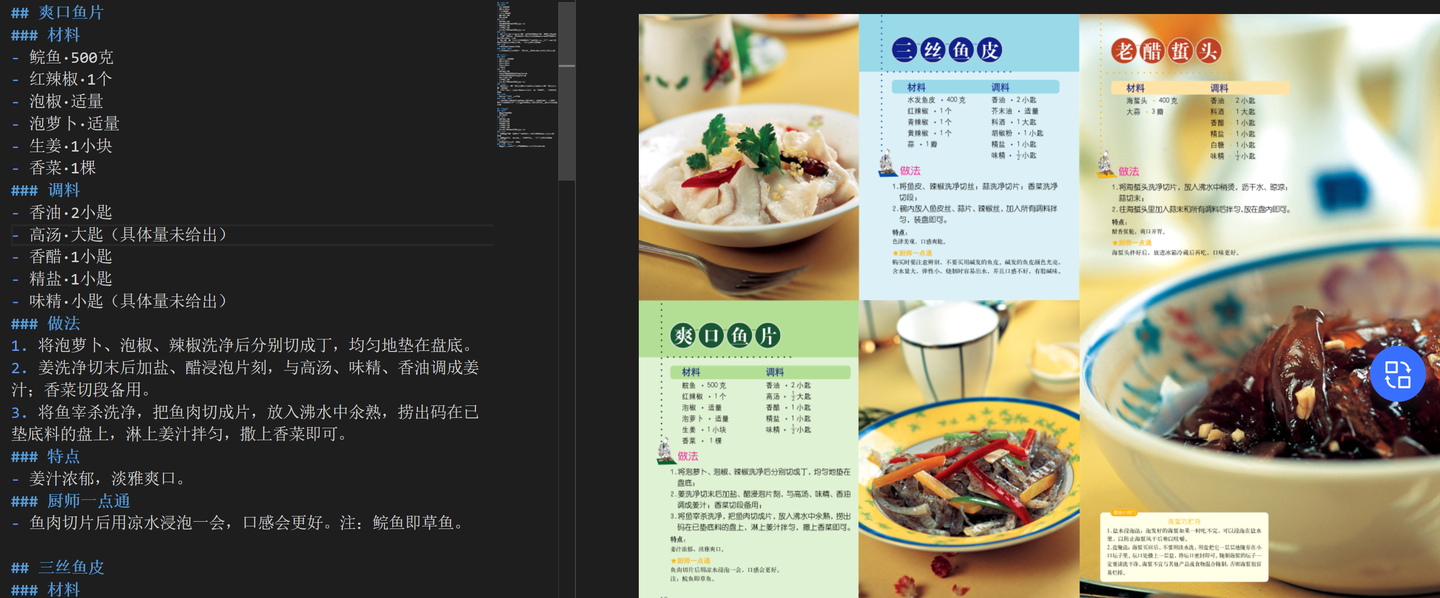
整体还是符合预期的,其中 高汤·大匙(具体量未给出),是因为文本并未识别成功,LLM 自然无法给出。
接下来,我们还要提取目录信息,同样编写角色提示词让 LLM 帮我们搞定:

最终,我们在 data/md 文件夹下得到两份 .json 文件,recipe.json 和 directory.json,分别是结构化的菜谱数据和分类数据:
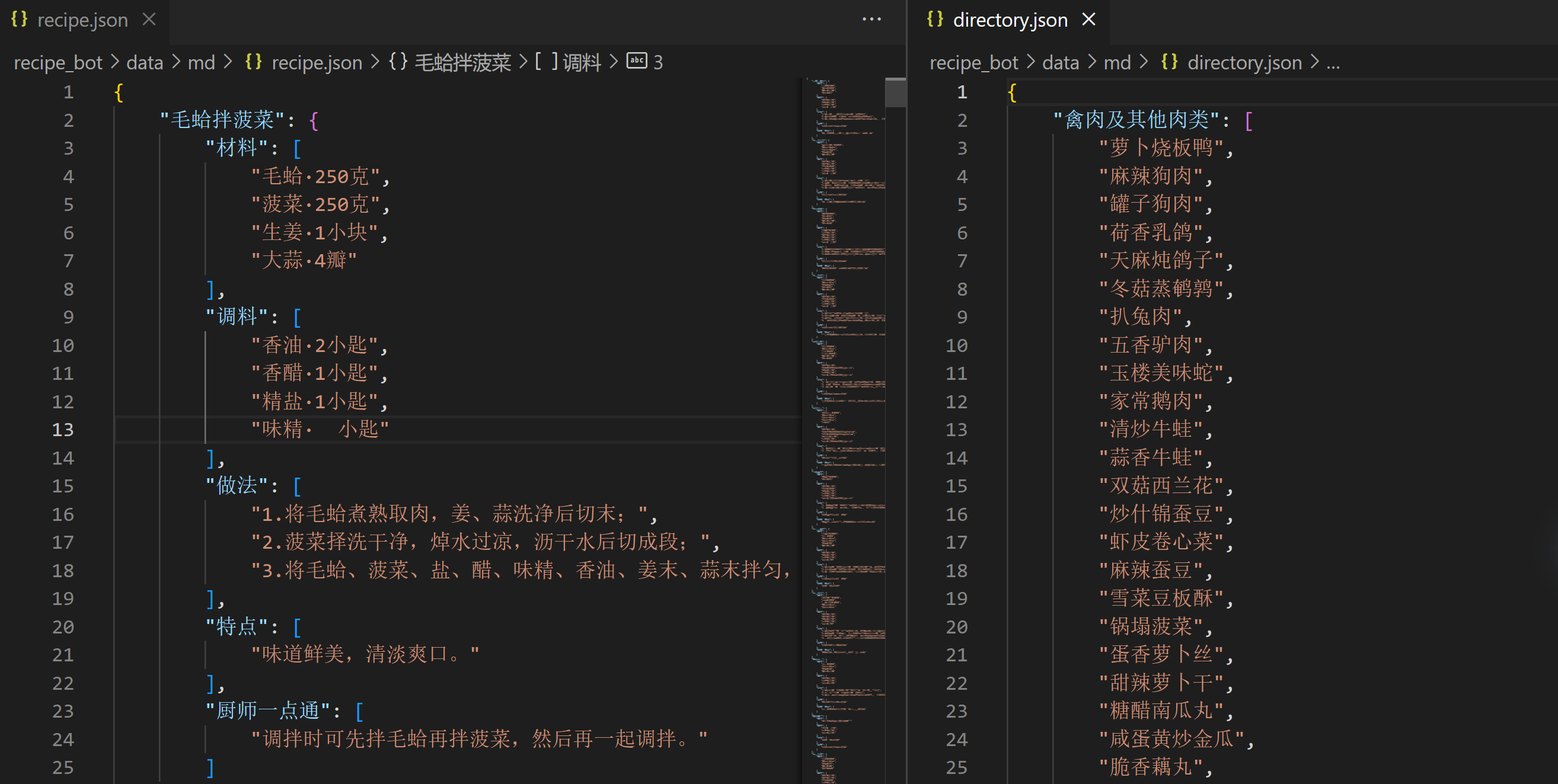
怎么把上述数据,转换成可供大模型微调的数据呢?
3.1.3 对话数据生成
参考飞桨大模型精调文档,PaddleNLP支持的数据格式是每行一个字典,每个字典包含以下字段:
- src : str, List(str), 模型的输入指令(instruction)、提示(prompt),模型应该执行的任务。
- tgt : str, List(str), 模型的输出。
- context(可选):在训练过程中动态调整 system prompt,传入 system 字段。
为此,参考上述格式,我们可以编写如下函数生成对话数据:
def get_sft_data():
context = {'system': '您是一位五星级大厨,擅长回答关于一切有关菜谱的问题,包括菜品推荐,食材选择,具体做法等等。'}
results = []
# 生成和类别相关的问题
dir_dict = json.load(open('data/md/directory.json', 'r'))
for cate, name_list in dir_dict.items():
for i in range(10):
src = f'请您帮我推荐几道关于{cate}的菜品'
tgt = random.sample(name_list, random.randint(2, min(len(name_list), 10)))
results.append({'src': src, 'tgt': '\n'.join(tgt), 'context': context})
for i in range(10):
num = random.randint(2, min(len(name_list), 10))
src = f'请您帮我推荐{num}道关于{cate}的菜品'
tgt = random.sample(name_list, num)
results.append({'src': src, 'tgt': '\n'.join(tgt), 'context': context})
# 生成和菜名相关的问题
rec_dict = json.load(open('data/md/recipe.json', 'r'))
for title, content_dict in rec_dict.items():
material = '\n'.join(content_dict.get('材料', ''))
if not material.strip():
continue
seasonings = '\n'.join(content_dict.get('调料', ''))
steps = '\n'.join(content_dict.get('做法', ''))
charcter = '\n'.join(content_dict.get('特点', ''))
tips = '\n'.join(content_dict.get('厨师一点通', ''))
src = f'{title}这道菜需要准备些什么食材和调料'
tgt = f'{title}这道菜需要准备的食材有:{material},调料有:{seasonings}'
results.append({'src': src, 'tgt': tgt, 'context': context})
src = f'{title}这道菜怎么做'
if tips:
tgt = f'{title}这道菜的具体做法如下:{steps},最后再给你点小建议:{tips}'
else:
tgt = f'{title}这道菜的具体做法如下:{steps}'
results.append({'src': src, 'tgt': tgt, 'context': context})
if charcter:
src = f'{title}这道菜有什么特点'
tgt = f'{title}的特点是:{charcter}'
results.append({'src': src, 'tgt': tgt, 'context': context})
src = f'我今天想吃点{charcter}的菜,你可以帮我推荐一道菜么'
tgt = f'没问题,{title}这道菜{charcter},需要准备的食材有:{material},调料有:{seasonings},具体做法如下:{steps},最后再给你点小建议:{tips}'
results.append({'src': src, 'tgt': tgt, 'context': context})
random.shuffle(results)
with open('data/sft_data.json', 'w') as f:
f.write(json.dumps(results, ensure_ascii=False, indent=4))上述代码分别生成:和类别相关的问题,和菜名相关的问题,共计 2083 条用于训练,我们随机抽取 100 条用于验证。

训练 & 验证数据放在了:/home/aistudio/data/data290409/:
- train.json
- dev.json
感兴趣的小伙伴,也可参考上述代码自行生成。
3.2 LLM 指令微调
数据准备好之后,我们开启 LLM 指令微调。
3.2.1 环境准备
首先,打开一个终端,下载 PaddleNLP 并安装依赖:
git clone https://github.com/PaddlePaddle/PaddleNLP.git
cd /home/aistudio/PaddleNLP/
pip install --upgrade paddlenlp==3.0.0b0
pip install paddlepaddle-gpu==3.0.0b1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/为了方便大家快速跑通流程,这里我们选用 Qwen/Qwen2-0.5B 进行简单测试:
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B", dtype="float16")
input_features = tokenizer("你好!请自我介绍一下。", return_tensors="pd")
outputs = model.generate(**input_features, max_length=128)
print(tokenizer.batch_decode(outputs[0]))Qwen/Qwen2-0.5B推理大概占用 4G 显存。
3.2.2 数据准备
微调需要进入 llm 目录:
cd /home/aistudio/PaddleNLP/llm然后准备训练数据,我们在第一步已经生成,直接软链接过来:
mkdir data_sft
ln -s /home/aistudio/data/data290409/train.json data_sft/train.json
ln -s /home/aistudio/data/data290409/dev.json data_sft/dev.json下面将开始进行模型训练,LLM 微调包括多种方式,这里我们选用最常见的两种方式进行展示。
SFT 全参微调:对模型的所有参数进行微调,需要更多的计算资源和时间,特别是对参数量巨大的模型LoRA 微调:一种参数高效的微调方法,基于 LLM 的内在低秩特性,通过增加旁路矩阵来模拟全参数微调。只训练新增参数,而保持原始参数固定,训练速度更快。
两种微调的脚本均为:python run_finetune.py,唯一的区别是指定不同的配置文件。
接下来,你需要根据自己的配置选择一个 LLM,如果你选择的是 16G 显存的 V100,那么 7B 以上的模型都是跑不了的。
为了方便大家快速跑通流程,下面我们选用 Qwen/Qwen2-0.5B 进行指令微调。SFT 全参微调 和 LoRA 微调 的配置文件分别在:config/qwen/sft_argument.json 和 config/qwen/lora_argument.json。
3.2.3 SFT 全参微调
首先,修改配置文件config/qwen/sft_argument.json,需要修改的几个地方如下:
"model_name_or_path": "Qwen/Qwen2-0.5B", # 指定选用的模型
"dataset_name_or_path": "./data_sft", # 指定数据集位置
"output_dir": "./checkpoints/sft_ckpts",# 指定训练输出模型权重的存放位置
"bf16": false,
"fp16": true,
"use_flash_attention": false特别注意:
-
如果选用的是 V100,不能使用 "bf16" 和 "use_flash_attention"。因为 V100 的 Compute Capability 为 7.0,不支持 bf16 计算,如需使用,可切换到飞桨的 A100 环境。
-
如果选用的是 A100,且使用"bf16" 和 "use_flash_attention",需安装 PaddleNLP 自定义 OP。
cd /home/aistudio/PaddleNLP/csrc
pip install -r requirements.txt
python setup_cuda.py install安装成功,提示如下:
Installed /home/aistudio/envs/bot/lib/python3.10/site-packages/paddlenlp_ops-0.0.0-py3.10-linux-x86_64.egg
配置文件准备好之后,一键开启训练:
python run_finetune.py ./config/qwen/sft_argument.json给大家展示下:不同训练配置下,训练时长对比:
- fp16 不用 flash attention

- fp16 用 flash attention

- bf16 用 flash attention

所以,flash attention 的提速还是很显著的!
bf16(BFloat16)和fp16(Float16)是两种不同的浮点数表示格式,有什么区别?
- bf16:1位符号位,8位指数,7位尾数。
- fp16:1位符号位,5位指数,10位尾数。
所以,bf16 指数范围更大,适合处理大范围的数值,可以减少内存带宽需求,同时保持较好的数值稳定性。,而 fp16 尾数精度更高,适合需要更高精度的小数运算。
3.2.4 LoRA 微调
首先,修改配置文件config/qwen/lora_argument.json,需要修改的几个地方,参考 SFT 全参微调 即可。
配置文件准备好之后,一键开启训练:
python run_finetune.py ./config/qwen/lora_argument.json训练结束后,还需将 lora 参数合并到主干模型中:
python merge_lora_params.py \
--model_name_or_path /home/aistudio/.paddlenlp/models/Qwen/Qwen2-0.5B \
--lora_path ./checkpoints/lora_ckpts \
--output_path ./checkpoints/lora_merge \
--device "gpu" \
--safe_serialization True脚本参数介绍:
- model_name_or_path: 主干模型参数路径。
- lora_path: LoRA参数路径。
- output_path: 合并参数后保存路径。
3.2.5 推理测试&结果对比
我们采用最简单的推理脚本对训练后的模型进行测试:
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "/home/aistudio/.paddlenlp/models/Qwen/Qwen2-0.5B"
# model_name = "/home/aistudio/PaddleNLP/llm/checkpoints/sft_ckpts/"
# model_name = "/home/aistudio/PaddleNLP/llm/checkpoints/lora_merge"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, dtype="float16")
input_features = tokenizer("我今天想吃点鲜香诱人,润滑爽口的菜,你可以帮我推荐一道么", return_tensors="pd")
outputs = model.generate(**input_features, max_length=512)
print(tokenizer.batch_decode(outputs[0]))对于问题:我今天想吃点鲜香诱人,润滑爽口的菜,你可以帮我推荐一道么
不同模型的回答,对比如下:
-
Qwen/Qwen2-0.5B
['? 你好,我可以帮你推荐一道菜。请问你想要吃什么口味的菜呢?比如辣、甜、咸、酸等等。<|im_start|>']
-
SFT 全参微调
['?没问题,爽口鱼片这道菜鲜香诱人,润滑爽口,需要准备的食材有:鲩鱼·1条(约750克)\n红辣椒·1个\n泡椒·适量\n泡萝卜·适量\n生姜·1小块\n大蒜·3瓣\n香菜·1棵\n淀粉·适量,调料有:香油·2小匙\n高汤·大匙(具体量未给出)\n香醋·1小匙\n精盐·1小匙\n味精·小匙(具体量未给出),具体做法如下:1. 将泡萝卜、泡椒、辣椒洗净后分别切成丁,均匀地垫在盘底。\n2. 将鱼宰杀洗净,把鱼肉切成片,放入沸水中氽熟,捞出码在已垫底料的盘上,淋上香油拌匀即可。,最后再给你点小建议:鱼肉切片后用凉水浸泡一会,口感会更好。注:鲩鱼即草鱼。<|im_end|>鱼肉切片后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>鱼片用沸水氽熟,捞出后用凉水浸泡一会,口感会更好。<|im_end|>']
-
LoRA 微调
['菜? 豆泥豆腐这道菜鲜香诱人,润滑爽口,需要准备的食材有:豆腐·200克\n鸡蛋·1个\n香葱·1棵\n生姜·1小块\n淀粉·适量,调料有:食用油·30克\n香油·1小匙\n酱油·1小匙\n高汤·2大匙\n料酒·1小匙\n胡椒粉·1小匙\n精盐·1小匙\n白糖·小匙\n味精·小匙,具体做法如下:1.将豆腐切成厚片,用开水焯熟,切成方块;葱、姜洗净切末;\n2.将鸡蛋打入碗内,加入精盐、味精、胡椒粉、高汤、淀粉、香油、料酒、葱、姜拌匀成蛋糊;\n3.锅内放油,烧热,下入豆腐块,炸成金黄色后捞起沥油;\n4.锅内留底油,下入葱、姜、酱油、白糖、味精、高汤、蛋糊,用小火烧至汤汁收浓,再用水淀粉勾芡,淋上香油,出锅即可。,最后再给你点小建议:炸豆腐时油温不要过高,以免豆腐炸焦。烹饪时要保持豆腐的形状,以免炸成"花边豆腐"。<|im_start|>']
从结果来看,对于这个简单任务而言,LoRA 微调的效果并不比全参微调差,且更经济高效。
当然这里为了演示,我们只训练了默认的 3 个 epoch,V 100 训练时长大概 1.2 小时。
总结
至此,我们共同走完了完整的 LLM 指令微调任务,从基于 ErnieBot 的数据生成,到基于 PaddleNLP 的 SFT 微调和 LoRA 微调。希望对你开发更多有意思的 LLM 应用有所帮助~
本系列将继续分享采用飞桨深度学习框架服务产业应用的更多案例。如果对你有帮助,欢迎点赞收藏备用~