背景
目前本人在公司负责的模块中,有一个模块是负责数据同步的,主要是将我们数据产线使用的 AWS Dynamodb 同步的我们的测试QA 的环境的 MongoDB 的库中,去年开始也提供了使用 EMR 批量同步的功能,但是有时候业务也需要少量的数据进行同步测试,所以也通过了抽样数据同步的功能。
过程
本周的时候,LS项目研发的同事,和我反馈一个问题,主要是表现是发现同步到MongoDB库中的部分表的字段有问题,下游没法解析使用,随后我就开始排查代码
看下的这边同步的部分代码
java
/**
* Synchronizes data by rewriting from source to sink database.
*
* @param syncMessage The message model containing synchronization details.
* @param source_db The source DynamoDB client.
* @param sink_db The sink DynamoDB client.
* @param parameters Parameters for querying the source database.
* @return The number of successful sync operations.
*/
private static int syncDataByRewrite(SyncPartDDBMessageModel syncMessage, AmazonDynamoDBClient source_db, AmazonDynamoDBClient sink_db, List<String> parameters) {
int syncSuccessCount = 0;
String table_name = syncMessage.getTable_name();
List<Map<String, AttributeValue>> sync_items = new ArrayList<>();
for (String parameter : parameters) {
QueryResult queryResult = queryDataFromSource(source_db, syncMessage, parameter);
if (queryResult != null && queryResult.getItems() != null && !queryResult.getItems().isEmpty()) {
sync_items.addAll(queryResult.getItems());
syncSuccessCount++;
}
}
try {
log.info("start sync data:" + JSON.toJSONString(sync_items));
AWSDynamoDBUtils.batchWrite(sink_db, table_name, sync_items);
} catch (Exception e) {
log.error("Error syncing data for table {}: {}", table_name, e.getMessage(), e);
}
return syncSuccessCount;
}其实核心代码就如上面一样,咋一看,这段代码是没有问题的,因为之前我也对齐进行过测试,数据同步也是 OK 的,后来同事和我说 正常的字段都是 OK 的,但是 Binary 类型的字段存在问题,由于公司的之前使用的 Dynamodb的数据库,Dynamodb对每个 Item 的大小有限制,即512K,为了更多存储,减少不必要的 Chunk,我们将很多大的字段进行的 GZIP 压缩后用二进制的Binary 存储。
定位问题
当我听到是 Binary 类型的字段有问题的时候,第一反应是 想,是不是我们的 proxy 有问题,因为我这边使用的了写 Mongodb 适配Dynamodb 的 proxy, 后来问了组件的同事,说代码也已经很久没问题了,应该没问题的~
后来也是考虑是不是batchWrite的底层写得有问题,也是各种猜测去定位问题,浪费了很长时间
后来无意之前,我注释了下代码,仅仅 就注释了一行代码,你们猜是什么?
··
··
··
就是 log.info("start sync data:" + JSON.toJSONString(sync_items));
对,我注释了一样记录日志的代码,居然程序没问题了这搞的我很尴尬哎呀
寻找问题的根源
最近也比较忙,当时定位到问题后,我想找找为什么会这样~
刚好今天周六有时间,我吧 FastJson 的源码来了来,我调试看下,我使用的版本是: fastjson2 git:(2.0.26)
测试
在实际我们的数据同步过程中,Map<String, AttributeValue> 里面的AttributeValue 是 Dynamodb返回的实体对象,是一个比较复杂的对象,我就不使用了,我这边只是测试了Buffer的
java
@Test
public void testBufferObjectToJsonString1() throws Exception {
String drugId = "53b8acd8694f4ddabefc76b3a6d58976";
ByteBuffer byteBuffer = compressString(drugId);
System.out.println("byteBuffer:" + byteBuffer);
System.out.println("drugIdJSONString:" + JSON.toJSONString(byteBuffer));
System.out.println("byteBuffer2:" + byteBuffer);
System.out.println("drugIdJSONString2:" + JSON.toJSONString(byteBuffer));
}
@Test
public void testBufferObjectToJsonString2() throws Exception {
String drugId = "53b8acd8694f4ddabefc76b3a6d5897653b8acd8694f4ddabefc76b3a6d5897653b8acd8694f4ddabefc76b3a6d58976";
ByteBuffer byteBuffer = compressString(drugId);
System.out.println("byteBuffer:" + byteBuffer);
System.out.println("drugIdJSONString:" + JSON.toJSONString(byteBuffer));
System.out.println("byteBuffer2:" + byteBuffer);
System.out.println("drugIdJSONString2:" + JSON.toJSONString(byteBuffer));
}可以给大家看下 这2个测试方法的返回:
第一个测试的返回:
byteBuffer:java.nio.HeapByteBuffer[pos=0 lim=32 cap=32]
drugIdJSONString:{"char":"㔳","direct":false,"double":1.4039733842967137E165,"float":2.1439479E-7,"int":1684103781,"long":7377801321278300470,"readOnly":false,"short":25653}
byteBuffer2:java.nio.HeapByteBuffer[pos=28 lim=32 cap=32]
com.alibaba.fastjson.JSONException: toJSONString error
at com.alibaba.fastjson.JSON.toJSONString(JSON.java:1477)
at com.patsnap.data.process.platform.job.syncPartDDB.SyncPartDDBJobTest.testBufferObjectToJsonString1(SyncPartDDBJobTest.java:143)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at junit.framework.TestCase.runTest(TestCase.java:176)
at junit.framework.TestCase.runBare(TestCase.java:141)
at junit.framework.TestResult$1.protect(TestResult.java:122)
at junit.framework.TestResult.runProtected(TestResult.java:142)
at junit.framework.TestResult.run(TestResult.java:125)
at junit.framework.TestCase.run(TestCase.java:129)
at junit.framework.TestSuite.runTest(TestSuite.java:252)
at junit.framework.TestSuite.run(TestSuite.java:247)
at org.junit.internal.runners.JUnit38ClassRunner.run(JUnit38ClassRunner.java:86)
at org.junit.runner.JUnitCore.run(JUnitCore.java:137)
at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:69)
at com.intellij.rt.junit.IdeaTestRunner$Repeater$1.execute(IdeaTestRunner.java:38)
at com.intellij.rt.execution.junit.TestsRepeater.repeat(TestsRepeater.java:11)
at com.intellij.rt.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:35)
at com.intellij.rt.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:232)
at com.intellij.rt.junit.JUnitStarter.main(JUnitStarter.java:55)
Caused by: java.nio.BufferUnderflowException
at java.nio.Buffer.nextGetIndex(Buffer.java:510)
at java.nio.HeapByteBuffer.getDouble(HeapByteBuffer.java:531)
at com.alibaba.fastjson2.writer.FieldWriterDoubleValueFunc.write(FieldWriterDoubleValueFunc.java:44)
at com.alibaba.fastjson2.writer.ObjectWriter8.write(ObjectWriter8.java:97)
at com.alibaba.fastjson.JSON.toJSONString(JSON.java:1469)
... 21 more第二个测试的返回:
byteBuffer:java.nio.HeapByteBuffer[pos=0 lim=96 cap=96]
drugIdJSONString:{"char":"㔳","direct":false,"double":1.4039733842967137E165,"float":2.1439479E-7,"int":1684103781,"long":7377801321278300470,"readOnly":false,"short":25653}
byteBuffer2:java.nio.HeapByteBuffer[pos=28 lim=96 cap=96]
drugIdJSONString2:{"char":"㠹","direct":false,"double":9.958328793464587E-43,"float":1.3592432E22,"int":879113316,"long":7233170664182724406,"readOnly":false,"short":25139}第一个测试居然报错了,从报错的堆栈上看,java.nio.HeapByteBuffer.getDouble(HeapByteBuffer.java:531)这个异常了
第二个测试没有报错,但是存在问题,就是明显2个对象不一样了,我们从第二个HeapByteBuffer的position的值可以看到,他的值偏移了,说明了什么 ,说明了 FastJosn 读取了ByteBuffer的内容,但是没有做buffer rewind重置位置的操作,这也太坑了
查看源码
java
static String toJSONString(Object object) {
JSONWriter.Context writeContext = new JSONWriter.Context(JSONFactory.defaultObjectWriterProvider);
boolean pretty = (writeContext.features & JSONWriter.Feature.PrettyFormat.mask) != 0;
JSONWriter jsonWriter;
if (JVM_VERSION == 8) {
jsonWriter = new JSONWriterUTF16JDK8(writeContext);
} else if ((writeContext.features & JSONWriter.Feature.OptimizedForAscii.mask) != 0) {
....
} else {
....
}
try (JSONWriter writer = pretty ?
new JSONWriterPretty(jsonWriter) : jsonWriter) {
if (object == null) {
writer.writeNull();
} else {
writer.rootObject = object;
writer.path = JSONWriter.Path.ROOT;
Class<?> valueClass = object.getClass();
if (valueClass == JSONObject.class) {
writer.write((JSONObject) object);
} else {
JSONWriter.Context context = writer.context;
boolean fieldBased = (context.features & JSONWriter.Feature.FieldBased.mask) != 0;
ObjectWriter<?> objectWriter = context.provider.getObjectWriter(valueClass, valueClass, fieldBased);
objectWriter.write(writer, object, null, null, 0);
}
}
return writer.toString();
} catch (NullPointerException | NumberFormatException e) {
throw new JSONException("JSON#toJSONString cannot serialize '" + object + "'", e);
}
}上面的toJSONString的部分代码的截取,主要是看 objectWriter.write(writer, object, null, null, 0);这个地方的实现,最终我调试发现调用了com.alibaba.fastjson2.writer.ObjectWriter8 里面的 write方法
java
@Override
public void write(JSONWriter jsonWriter, Object object, Object fieldName, Type fieldType, long features) {
long featuresAll = features | this.features | jsonWriter.getFeatures();
boolean beanToArray = (featuresAll & BeanToArray.mask) != 0;
if (jsonWriter.jsonb) {
if (beanToArray) {
writeArrayMappingJSONB(jsonWriter, object, fieldName, fieldType, features);
return;
}
writeJSONB(jsonWriter, object, fieldName, fieldType, features);
return;
}
if (beanToArray) {
writeArrayMapping(jsonWriter, object, fieldName, fieldType, features | this.features);
return;
}
if (!serializable) {
if ((featuresAll & JSONWriter.Feature.ErrorOnNoneSerializable.mask) != 0) {
errorOnNoneSerializable();
return;
}
if ((featuresAll & JSONWriter.Feature.IgnoreNoneSerializable.mask) != 0) {
jsonWriter.writeNull();
return;
}
}
if (hasFilter(jsonWriter)) {
writeWithFilter(jsonWriter, object, fieldName, fieldType, 0);
return;
}
jsonWriter.startObject();
if (((features | this.features) & WriteClassName.mask) != 0 || jsonWriter.isWriteTypeInfo(object, features)) {
writeTypeInfo(jsonWriter);
}
fieldWriter0.write(jsonWriter, object);
fieldWriter1.write(jsonWriter, object);
fieldWriter2.write(jsonWriter, object);
fieldWriter3.write(jsonWriter, object);
fieldWriter4.write(jsonWriter, object);
fieldWriter5.write(jsonWriter, object);
fieldWriter6.write(jsonWriter, object);
fieldWriter7.write(jsonWriter, object);
jsonWriter.endObject();
}最终代码是执行了fieldWriter0到fieldWriter7的8个方式,这也解释了 我们的为什么我们打印的 Bytebuffer类型是这样的:
json
{
"char":"㔳",
"direct":false,
"double":1.4039733842967137E165,
"float":2.1439479E-7,
"int":1684103781,
"long":7377801321278300470,
"readOnly":false,
"short":25653
}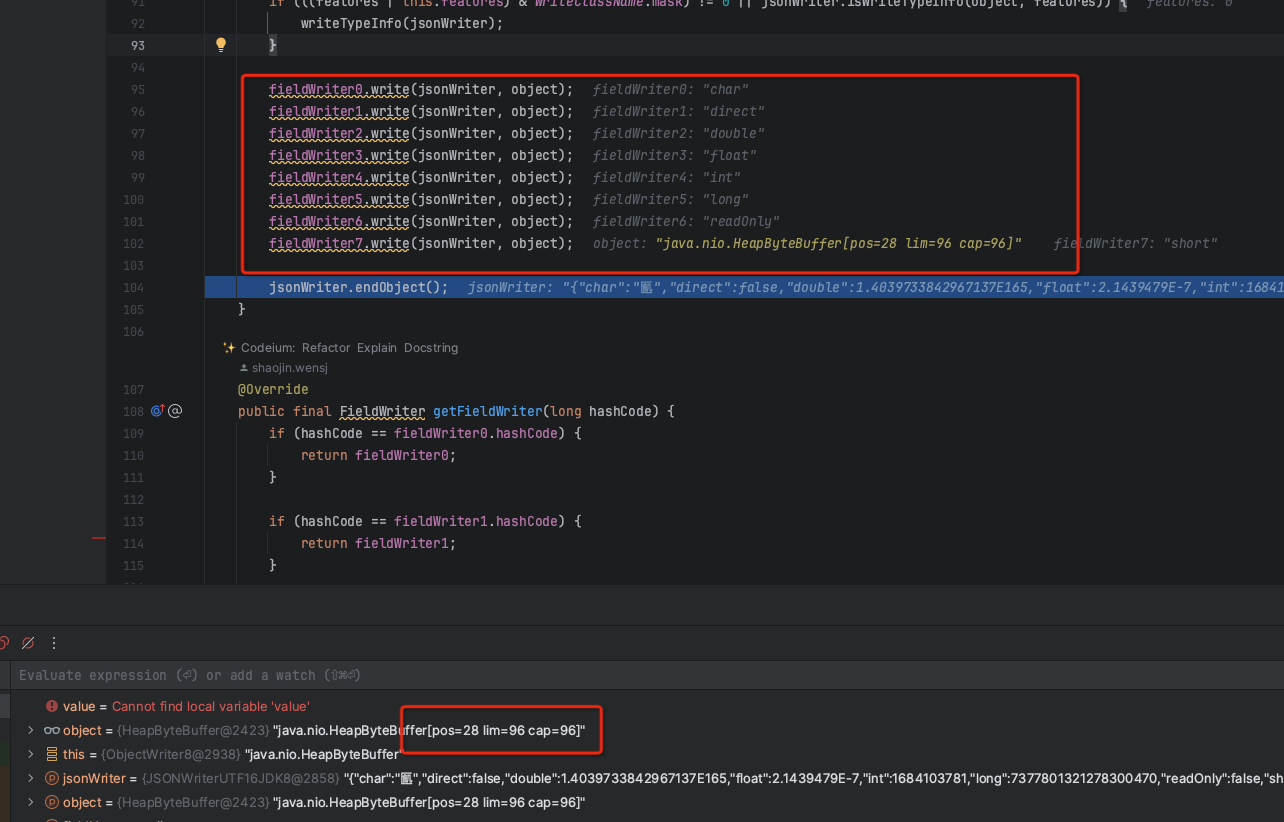
这边也是刚好8个方式加起来读取了28
这边也同能解释了我第一个测试方式为什么会报错,再回头看下我第一个的 buffer 对象byteBuffer:java.nio.HeapByteBufferpos=0 lim=32 cap=32
byteBuffer2:java.nio.HeapByteBufferpos=28 lim=32 cap=32
为什么第二次 toJSONString 的错误就是因为,读取的位置不够了~所以在第一个测试在at java.nio.HeapByteBuffer.getDouble(HeapByteBuffer.java:531)的位置发送了错误,也应对了上面的源码的逻辑
解决方法
如果是的执行方法在使用toJSONString之前的,那是没有问题的,正常我们读取 buffer 完成后的,会重置位置,或者使用一个输出流去接收,然后再去读取,也是没有问题的,或者使用 ByteBuffer wrap = ByteBuffer.wrap(byteBuffer.array()); 也是没有问题的
当然你如果想要解决这个toJSONString的错误,也是可以的,正常我们都会将二进制使用 base64来表示的,这样就不存在问题,
上代码:
java
public class ByteBufferValueFilter implements ValueFilter {
@Override
public Object process(Object object, String name, Object value) {
if (value instanceof ByteBuffer) {
ByteBuffer buffer = (ByteBuffer) value;
byte[] bytes = new byte[buffer.remaining()];
buffer.get(bytes); // 读取剩余的字节
buffer.rewind(); // 重置 position 到起始位置
return Base64.getEncoder().encodeToString(bytes);
}
return value;
}
}是可以解决的
后续
这个问题其实我在官方的issues也找到了这个问题:https://github.com/alibaba/fastjson/issues/2357
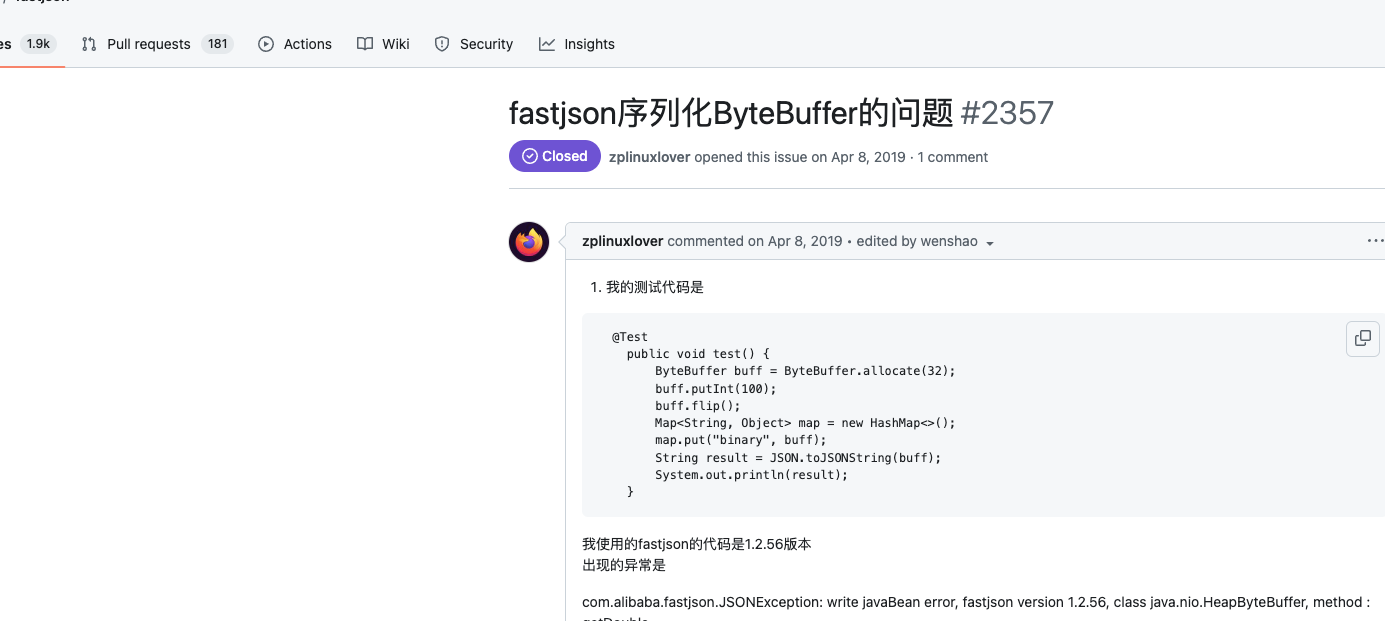
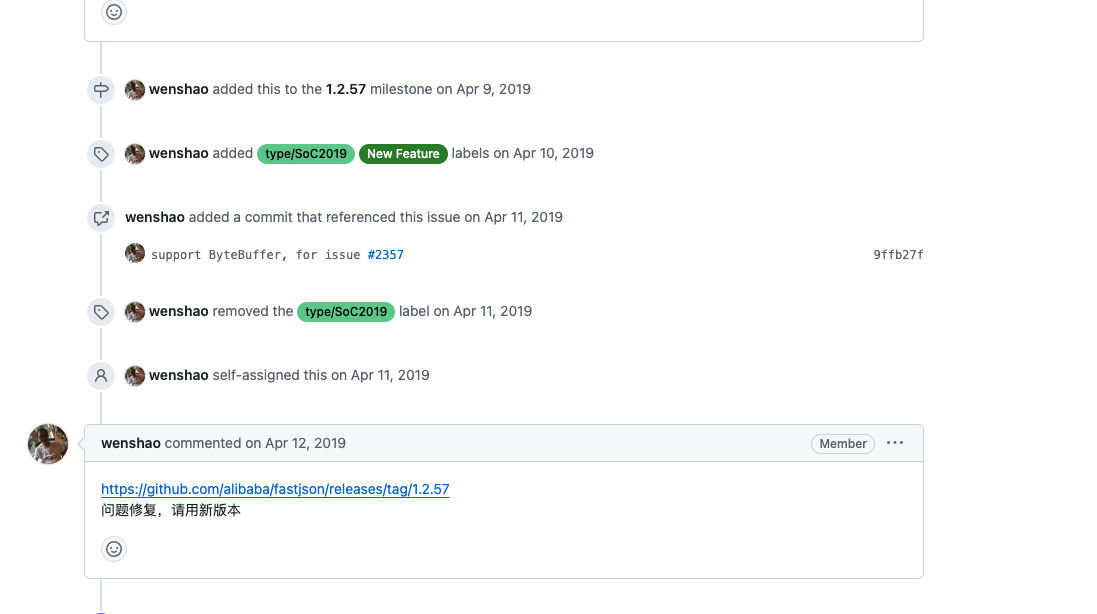
下面的回复是已经解决了这个问题的,但是我使用的2.0.26 居然还有这个问题,
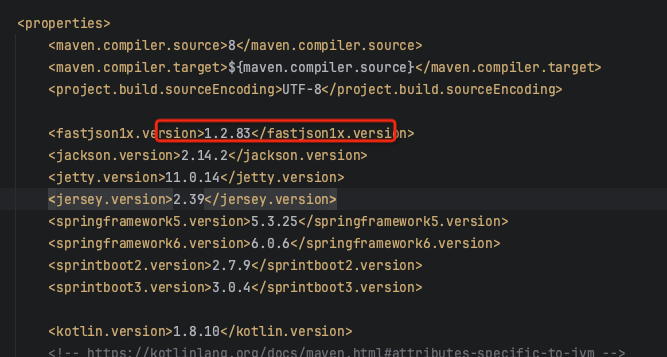
我就顺便测试了1.2.83版本,这个也是2.0.26版本引用之前1.X的fastjson 的版本,
java
@Test
public void testBufferObjectToJsonString2() throws Exception {
String drugId = "53b8acd8694f4ddabefc76b3a6d5897653b8acd8694f4ddabefc76b3a6d5897653b8acd8694f4ddabefc76b3a6d58976";
ByteBuffer byteBuffer = compressString(drugId);
System.out.println("byteBuffer:" + byteBuffer);
System.out.println("drugIdJSONString:" + com.alibaba.fastjson.JSON.toJSONString(byteBuffer));
System.out.println("byteBuffer2:" + byteBuffer);
System.out.println("drugIdJSONString2:" + JSON.toJSONString(byteBuffer));
}输出:
java
byteBuffer:java.nio.HeapByteBuffer[pos=0 lim=96 cap=96]
drugIdJSONString:{"array":"NTNiOGFjZDg2OTRmNGRkYWJlZmM3NmIzYTZkNTg5NzY1M2I4YWNkODY5NGY0ZGRhYmVmYzc2YjNhNmQ1ODk3NjUzYjhhY2Q4Njk0ZjRkZGFiZWZjNzZiM2E2ZDU4OTc2","limit":96,"position":0}
byteBuffer2:java.nio.HeapByteBuffer[pos=0 lim=96 cap=96]
drugIdJSONString2:{"char":"㔳","direct":false,"double":1.4039733842967137E165,"float":2.1439479E-7,"int":1684103781,"long":7377801321278300470,"readOnly":false,"short":25653}可以看到 在之前的做法也是将二进制去 base64表示的,不知道为什么在2.0.26 还会出现上面的问题
那我就顺便去官方 提一个issues吧,https://github.com/alibaba/fastjson2/issues/2877
后面看下是否会修复这个问题
总结
回顾上面,其实最大的一个问题就是,在记录日志的时候,不应该添加在代码执行逻辑之前,这是一个不好的代码习惯,应该将日志记录放在代码执行逻辑之后。此外,代码的测试用例要做全,排查代码的时候,定位问题的时候 更加敏锐些。