PromptAD: 仅使用正常样本进行小样本异常检测的学习提示

论文名称:PromptAD: Learning Prompts with only Normal Samples for Few-Shot Anomaly Detection
论文地址:https://arxiv.org/pdf/2404.05231
研究背景
异常检测(Anomaly Detection)是计算机视觉中非常重要的任务,在工业和医学中的缺陷检测任务中得到了广泛的应用。本文聚焦于无监督工业异常检测任务,这提出了一个被称为一类分类(OCC)设置的挑战。在这个框架中,模型在训练期间只使用正常样本,但在测试阶段,正常样本和异常样本都会用于测试,模型需要能识别异常样本。由于工业异常检测通常为不同的工业生产线定制模型,因此使用少量样本快速训练模型的能力对实际应用具有重要意义。
提示学习(prompt learning)的目的是通过对比学习自动学习提示,以指导图像分类。但是,如图1(右)所示,由于异常检测的单类设置,使用上述提示学习方法作为基线的效果较差,不如在图像级结果上使用手动提示的WinCLIP。导致这种结果的主要的问题在于:1. 提示学习依赖于对比学习,如何在one-class环境中设计prompt来完成对比学习? 2.由于异常样本的缺乏,如何控制正常和异常prompt之间的边缘距离?
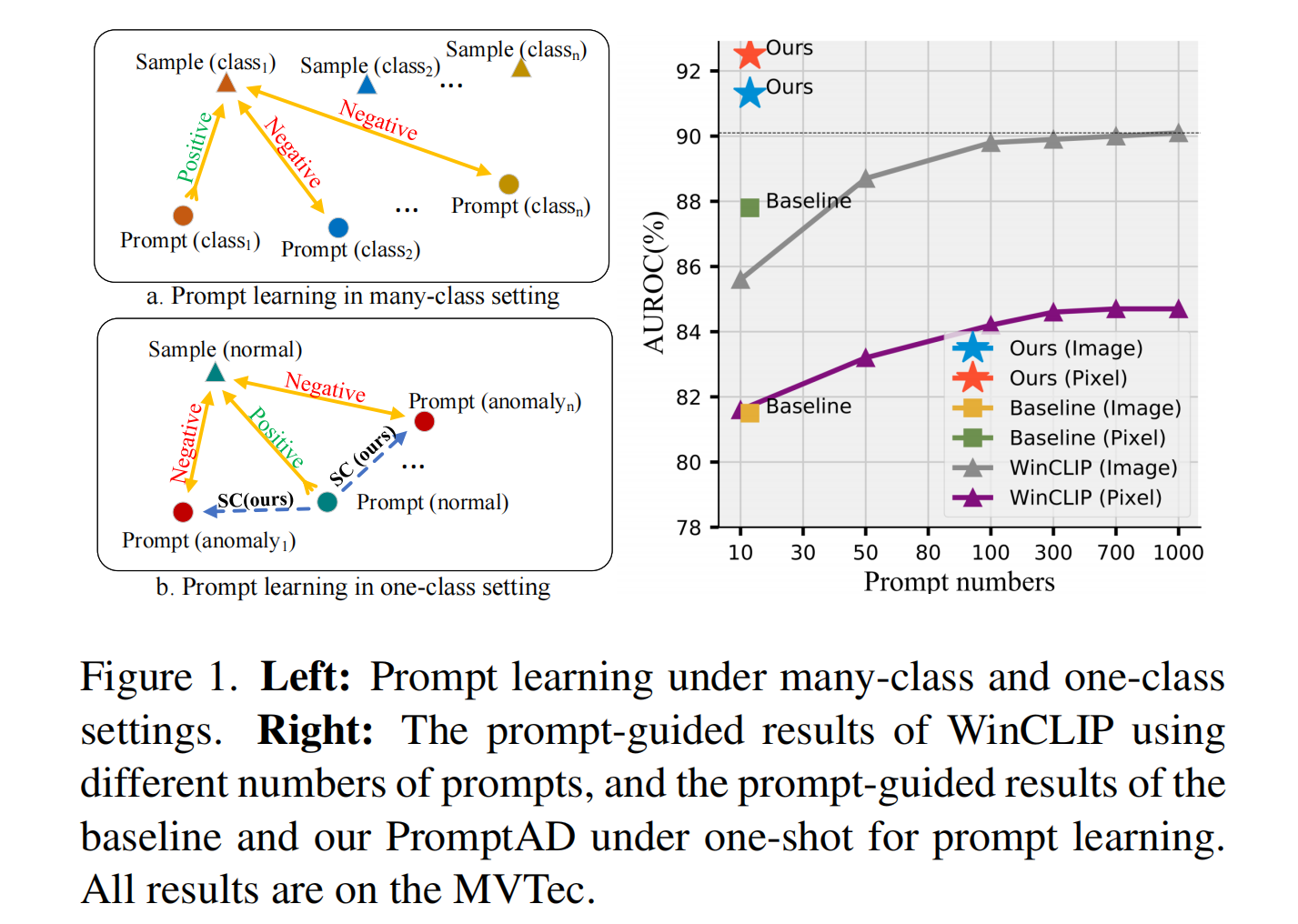
本文提出了一种只使用正常样本的单类提示学习异常检测方法PromptAD。为了解决以上的挑战1,本文提出了语义连接(SC),显然,将一个与提示语反义的文本和原始的提示连接可以改变这个提示的语义。基于这个想法,SC首先为正常样本设计了一个可学习的正常提示,例如**P** 1**P** 2 . . . **P** *EN* *obj.* ,接下来将正常提示与许多异常文本连接生成异常提示,例如**P** 1**P** 2 . . . **P** *EN* *obj.* *with* *flaw* ,并可在提示学习期间作为正常样本的负向提示使用。由于手动标注的异常文本有限,为了扩展异常信息的丰富性,SC也通过连接正常提示和可学习的token后缀设计了可学习的异常提示,例如**P** 1**P** 2 . . . **P** *EN* *obj.* **A** 1**A** 2 . . . **A** *EA* ,其中**A** *i* 是可学习的token。可学习的异常提示和手动设计的异常提示的分布是对齐的,从而确保可学习的异常提示学习更多正确的异常信息。
另外,在异常检测中异常样本不可用,因此不能通过对比损失明确控制正常和异常提示的边界。为了解决挑战2,本文提出了**显式异常边缘(EAM)**的概念,其中一个超参数确保正常特征和正常提示特征之间的距离小于正常特征和异常提示特征之间的距离。从而确保正常提示和异常提示之间有足够的间隔。
对比于WinCLIP和基线方法,在只使用10-20(下降~980和0)个提示的情况下,PromptAD图像级/像素级异常检测结果分别为91.3%(提高1.2%和9.8%)和92.5%(提高7.7%和3.7%)。
相关工作
Vision-Language Model
利用对比学习和vision transformer,一些视觉-语言模型(VLM)取得了巨大成功。CLIP是最常用的VLM之一,它在大规模的图像-文本对上进行预训练,展现出强大的零样本分类能力。基于预训练的CLIP和提示工程师,一些下游任务取得了巨大飞跃。受到自然语言处理(NLP)中提示学习成功的启发,近期出现了一些针对小样本图像分类任务的提示学习方法。这些方法旨在通过对比学习自动学习更好的提示,以指导基于CLIP的图像分类。
Anomaly Detection
大多数异常检测(AD)方法可以分为三种:基于特征嵌入的方法、基于知识蒸馏的方法和基于重建的方法。基于特征嵌入的异常检测方法通过神经网络提取图像的块特征,然后执行异常检测。基于知识蒸馏的异常检测方法让学生网络只学习教师网络的正常样本知识,并通过教师和学生之间的差异完成异常检测。基于重建的异常检测方法希望模型能够将异常图像重建为正常图像,并通过重建图像与异常图像之间的差异实现异常检测。
Few-Shot Anomaly Detection
TDG和RegAD是首先研究小样本异常检测方法的工作,PatchCore和DifferNet模型也在小样本设置中展示出较好的性能。WinCLIP和RWDA引入了CLIP模型进行异常检测,并在少样本设置中大幅提高了性能。最新的FastRecon通过带有分布正则化的回归重建异常特征,并取得了优异的性能。
本文方法
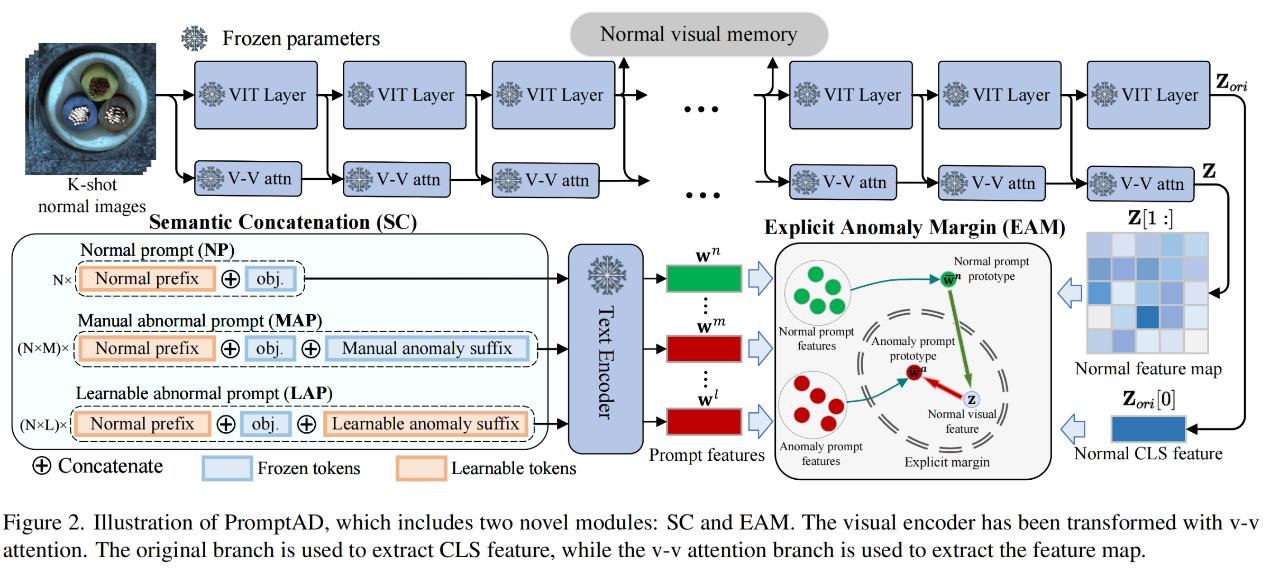
概述
本文提出的PromptAD模型结构如图2所示。PromptAD建立在VV-CLIP之上,其视觉编码器用于提取全局和局部的特征。本文提出的语义串联(SC)用来设计提示。具体来说,将N个可学习的普通前缀与目标名称串联起来获得普通提示(NPs),然后将这N个普通提示分别与M个手动设置的异常后缀和L个可学习的异常后缀串联,以获得N×M个异常提示(MAPs)和N×L个可学习的异常提示(LAPs)。视觉特征和提示特征用于通过对比损失和本文提出的显式异常边界(EMA)损失来完成提示学习。EMA可以通过超参数控制正常提示特征和异常提示特征之间的显式边际。最后,通过提示学习获得的提示被用于提示引导的异常检测(PAD)。
除了PAD,参考WinCLIP+ ,本文还引入了视觉引导的异常检测(VAD)。具体来说,如图2所示,在训练期间,视觉编码器输出的第i层特征(不包括CLS特征)被存储为正常的视觉记忆,记为R。在测试阶段,将查询图像的第i层特征图与R进行比较,以获得异常分数图:
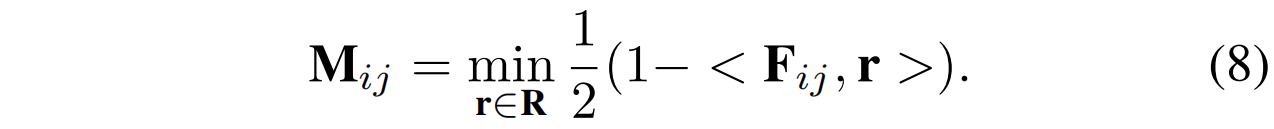
在实践中,本文使用两层的中间特征作为记忆,为每个查询图像获得两个分数图,然后将这两个分数图平均,以得到最终的视觉引导分数图。
Semantic Concatenation
由于在训练过程中只有正常的样本可以使用,导致了没有负样本用于引导提示学习从而影响了方法的性能。本文发现提示的语义可以通过连接来改变。例如,a photo of cable是正常的语义,当把这个提示和一个后缀连接后,a photo of cable with flaw就转换成了一个异常的语义。通过这种方法,本文提出了语义连接,可以通过将正常的提示与异常后缀连接将正常提示转换为异常提示,从而基于可学习的正常提示构造充足的对比样本。具体来说,遵循CoOp的格式,可学习的正常提示设计如下:
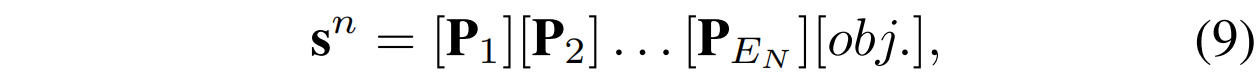
其中E_N代表可学习的正常前缀的长度,*obj.* 代表了被检测的物体的名字。具体来说,本从数据集的异常标签中生成异常后缀,例如\[\] with color stain, \[\] with crack等,然后将这些文本与正常提示连接起来,以获得异常提示:
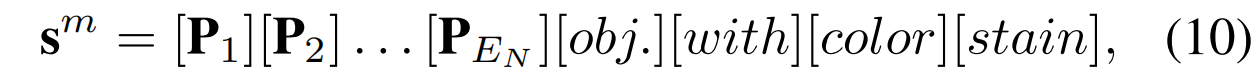
其中前缀是可训练的正常提示,而后缀是手动设置的异常文本。此外,本文将正常提示与一个可学习的标记后缀结合起来,设计出可学习的异常提示:
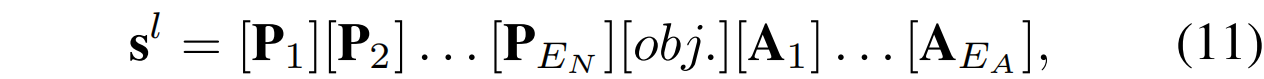
这里表示可学习异常后缀的长度。需要注意的是,由相同的普通前缀或异常后缀连接得到的提示的参数是共享的。在训练过程中,NP(正常提示)会向正常视觉特征靠近,而MAP(手动异常提示)和LAP(可学习异常提示)则会远离正常视觉特征。提示学习的训练损失与CLIP的训练损失一样,公式如下:
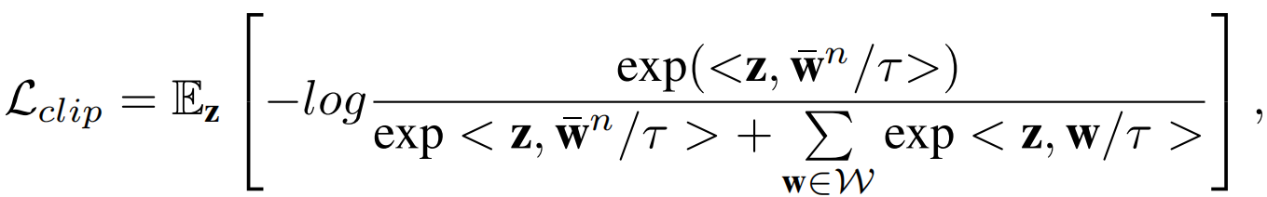
由于更多的异常样本可以产生更好的对比学习效果,每一个异常提示特征都会和视觉特征进行对比。
在传统的提示学习中,由于缺乏异常样本,系统只能设计出能够识别正常样本的提示,这在进行对比学习时存在较大的局限。本文提出的语义连接方法将原本代表正常样本的提示转换为代表异常样本的提示。通过共享参数,异常提示能够复用正常提示的语义信息,同时学习到异常的特征,从而在对比损失中更好地区分正常样本和异常样本。
Explicit Anomaly Margin
由于模型在训练中缺乏有异常的样本,MAP(手动异常提示)和LAP(可学习异常提示)只能将正常的视觉特征作为对比的负样本,并且在正常提示和异常提示之间缺少明确的边界。因此,本文提出了显式异常边界(EAM),它能够控制正常提示特征和异常提示特征之间的边界。实际上,EAM是通过边界超参数实现的正则化损失,其定义如下:
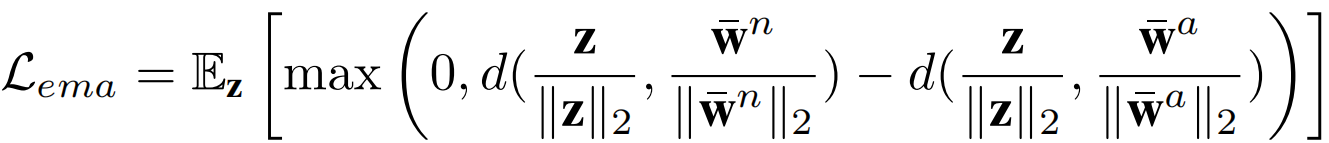
其中_d_(·, ·)代表欧氏距离,是所有异常提示特征的原型:
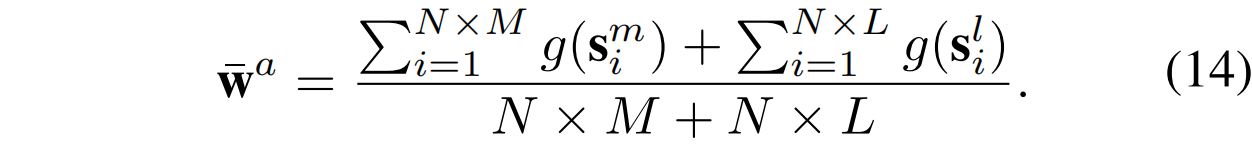
在CLIP中,最终的特征都被投影到单位超球面上,因此中的特征也进行了归一化,并且边界被固定为零。与对比损失()相比,EMA损失确保了正常样本与异常原型之间的距离大于正常样本与正常原型之间的距离,从而实现了正常和异常原型之间的明确区分。此外,由于MAP包含足够的异常信息,而LAP在初始化时没有任何语义指导,对齐它们有助于LAP模仿MAP的分布。具体来说,本文使用平方的L2范数对两种分布的均值进行对齐:
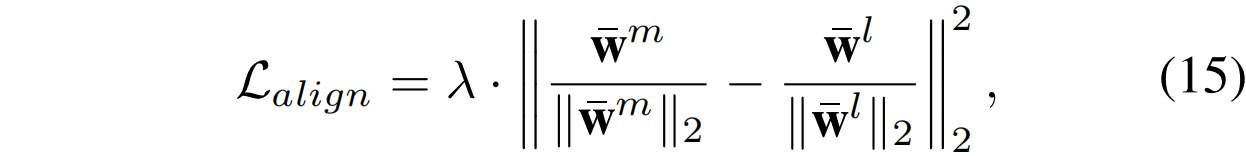
其中和分别是MAPs和LAPs的特征均值,λ 是控制MAPs和LAPs对齐程度的超参数。
Anomaly Detection
在测试阶段,作为正常原型,作为异常原型来完成提示引导的异常检测任务。图像级的得分和像素级得分图通过以下公式计算:

其中是图像/像素级异常检测的全局/局部图像特征。
最终,将视觉引导的和提示引导的融合以获得像素级异常得分图,将和的最大值融合以获得图像级的异常得分:
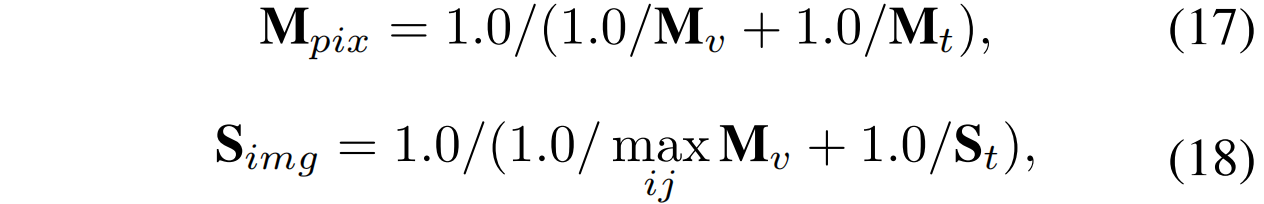
本文使用的融合方法是调和平均值,它对较小的值更为敏感。
实验
本文在1、2和4-shot的设置下完成了PromptAD与最新方法之间的对比实验,这些实验包括了图像级别和像素级别的结果。此外,本文还比较了many-shot和full-shot方法,以展示PromptAD强大的few-shot性能。最后,本文进行了消融实验,以验证通过所提出的SC(语义串联)和EAM(显式异常边界)对提示学习改进的效果,并展示了不同CLIP变换方法和超参数的影响。
数据集
MVTec-AD
该数据集模拟了真实的工业生产场景,填补了无监督异常检测的空白。它包含 5 种纹理和 10 种物体,共计 5,354 张来自不同领域的高分辨率图像。训练集包含 3,629 张仅有无异常样本的图像。测试集包含 1,725 张图像,包括正常和异常样本。提供了像素级标注用于异常定位评估。
VisA
该数据集包含共计 10,821 张高分辨率图像,包括 9,621 张正常图像和1,200 张带有 78 种异常的图像。VisA 数据集由 12 个子集组成,每个子集对应一个。
评估指标
本文图像级别和像素级别异常检测的评估指标均采用接收者操作特征曲线下面积(Area Under the Receiver Operation Characteristic,AUROC)。
实现细节
本文使用了OpenCLIP实现的CLIP及其预训练参数,以及超参数τ的默认值。参考WinCLIP,本文使用了基于LAION-400M的CLIP,配备ViT-B/16+。
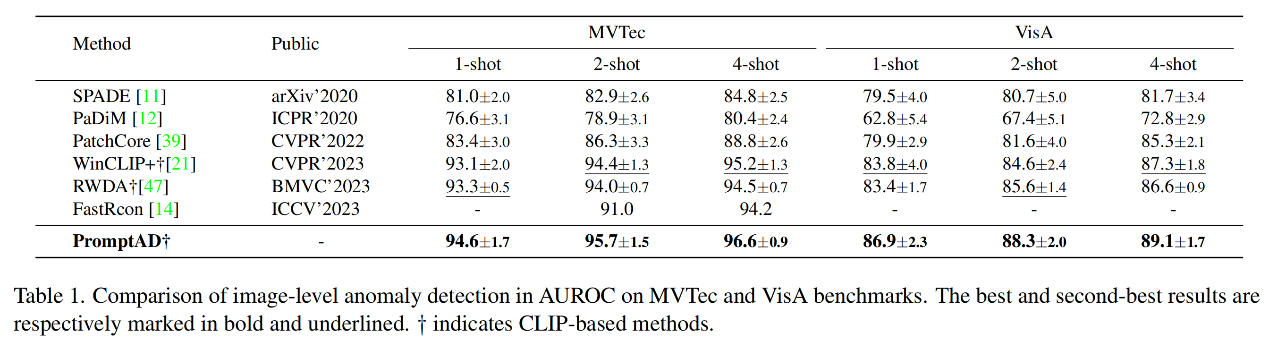
图像级对比实验
PromptAD和当前方法的图像级别比较实验结果如表1所示。实验结果显示,PromptAD在1、2和4-shot的少样本设置下,相比于其他传统方法和基于CLIP的方法,如WinCLIP+ 和 RWDA,都有显著的性能提升。特别是在MVTec和VisA数据集上,PromptAD的性能提升百分比在1.3%到2.9%之间,这表明PromptAD在少样本异常检测方面具有强大的能力。此外,PromptAD在实现这些性能提升的同时,使用的提示数量还少于对比方法,这进一步证明了其效率和有效性。
像素级对比实验
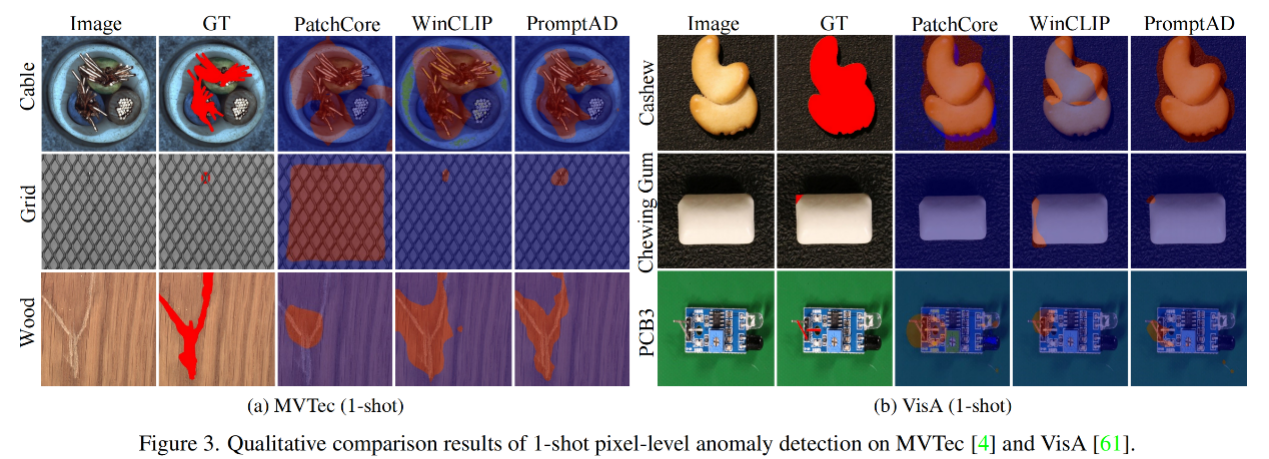
作者比较了PromptAD与其他方法在像素级别异常检测任务上的性能,实验结果如表4所示。实验结果表明,虽然基于CLIP的方法在像素级别的改进不如图像级别显著,但PromptAD在1-shot和2-shot的少样本设置下在MVTec和VisA数据集上均取得了最佳性能,较WinCLIP+有小幅提升。在4-shot设置下,PromptAD在VisA上保持了第一名,而在MVTec上以微弱差距位居第二。此外,通过可视化的异常定位结果,作者展示了PromptAD在定位小面积异常方面的高准确性,这表明PromptAD在像素级别的异常检测任务上具有较高的精确度和鲁棒性。这些结果进一步证实了PromptAD在少样本异常检测领域的有效性和优越性。

异常定位的定量结果如图3所示。PromptAD在1-shot设置中对对象和纹理具有更好的异常定位能力。此外,PromptAD还可以非常准确地定位一些非常小的异常区域。
与many-shoy方法的对比
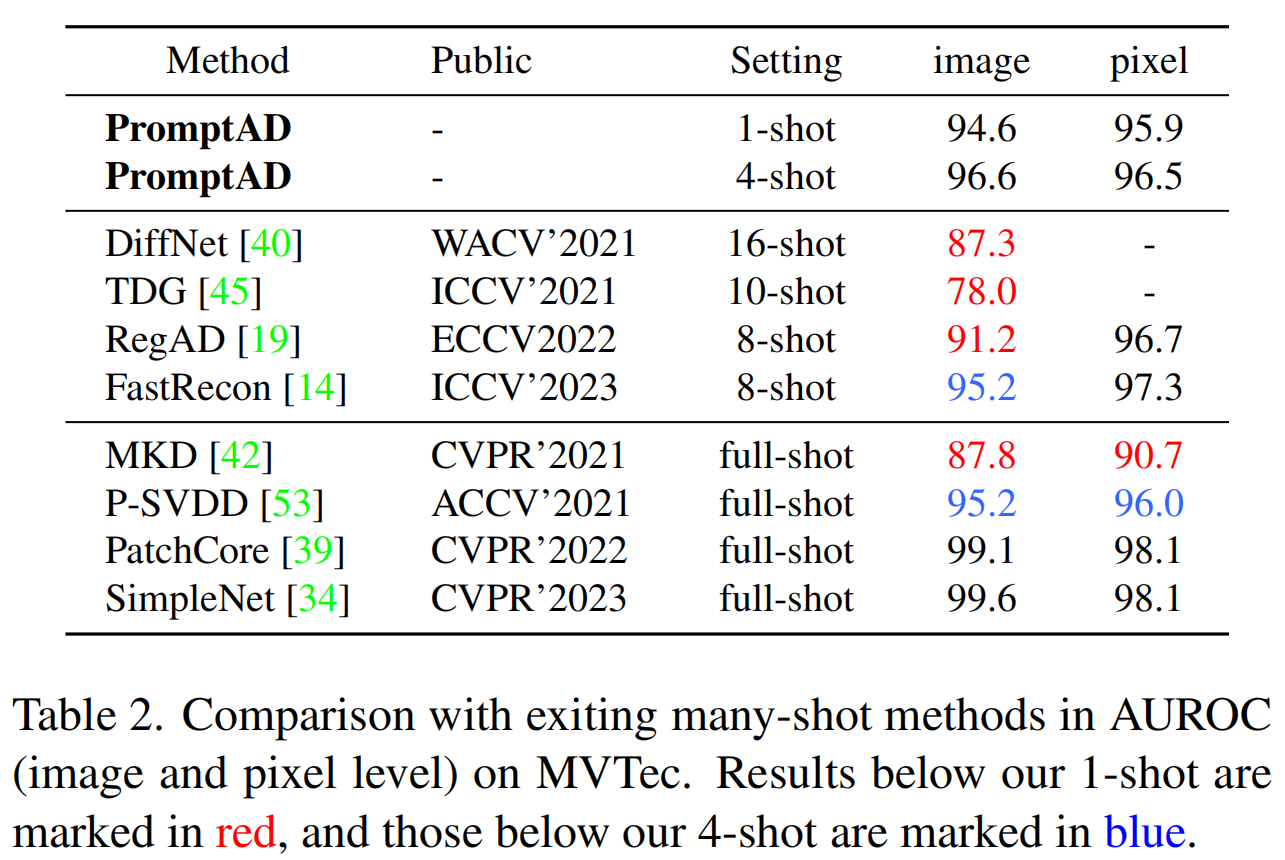
在少样本设置下PromptAD与其他many-shot/full-shot设置下的方法的比较结果,如表2所示。实验结果显示,PromptAD不仅在少样本设置下表现出色,其图像级别的异常检测结果优于其他多次射击方法,而且在像素级别上也展现出了有竞争力的性能。这表明PromptAD在处理只有少量样本可用的情况时,依然能够有效地进行异常检测。
消融实验
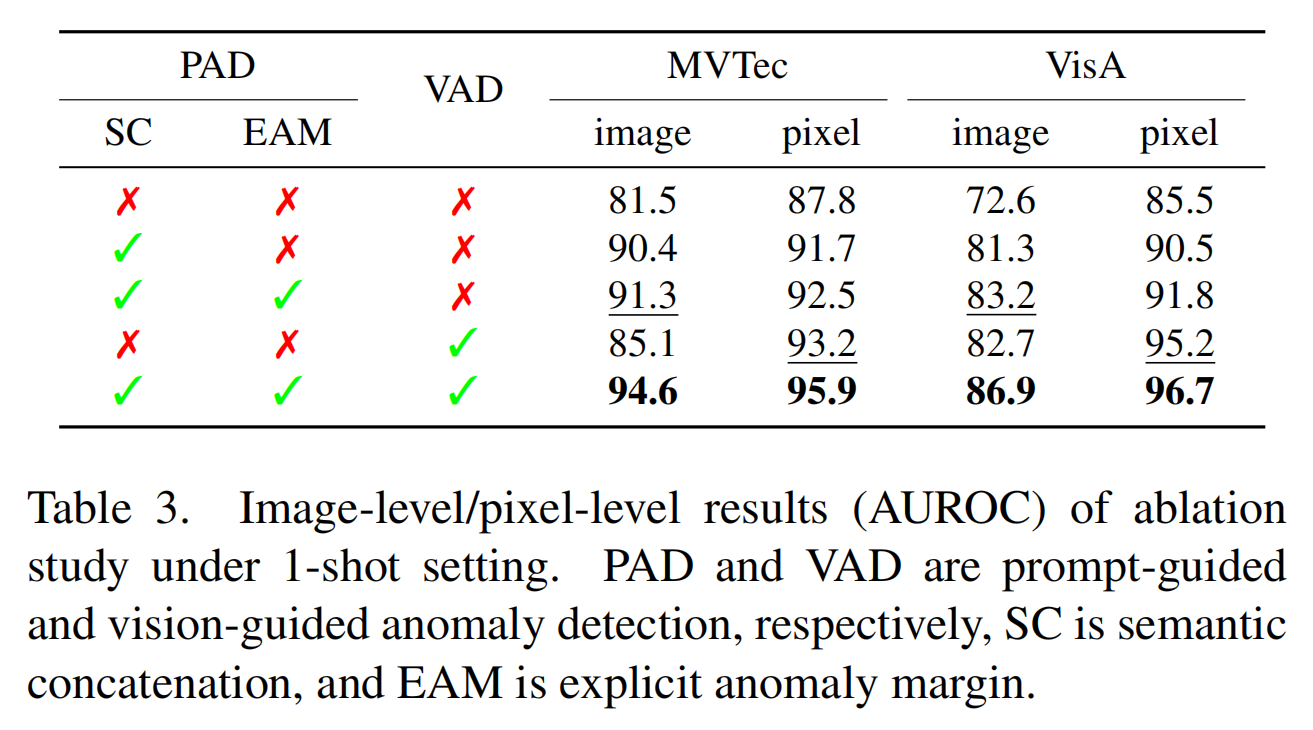
本文在MVTec和VisA数据集上,在1-shot设置下,对PromptAD的不同模块对整体性能的影响进行了实验验证。包括语义串联(SC)和显式异常边界(EAM)。同时,本文还验证了视觉引导的异常检测(VAD)的效果。消融研究的结果如表3所示:
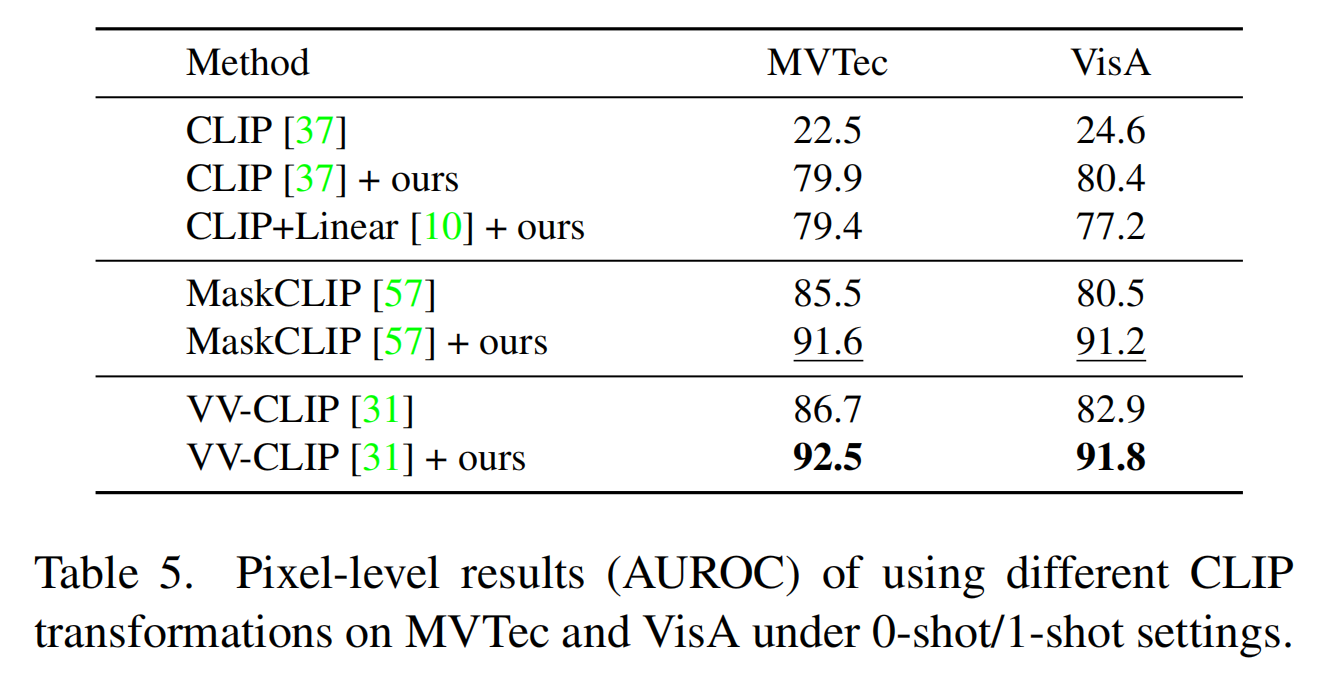
不同 CLIP 变换的结果
实验结果如表5所示:
超参数分析
本文分析了N、L和λ对PromptAD的影响。λ是损失的超参数,控制MAP和LAP特征分布的对齐程度。N是NP的数量。L是异常提示后缀的数量,N×L是LAP的数量。图4说明了N和L对PromptAD的影响。在图像级结果中,N影响不大,N = 1和N = 4之间没有明显差异。而L有显著的影响,较大的L可以得到更好的结果。在像素级结果中,N和L的影响都相对较小,较大的L略微改善了结果。

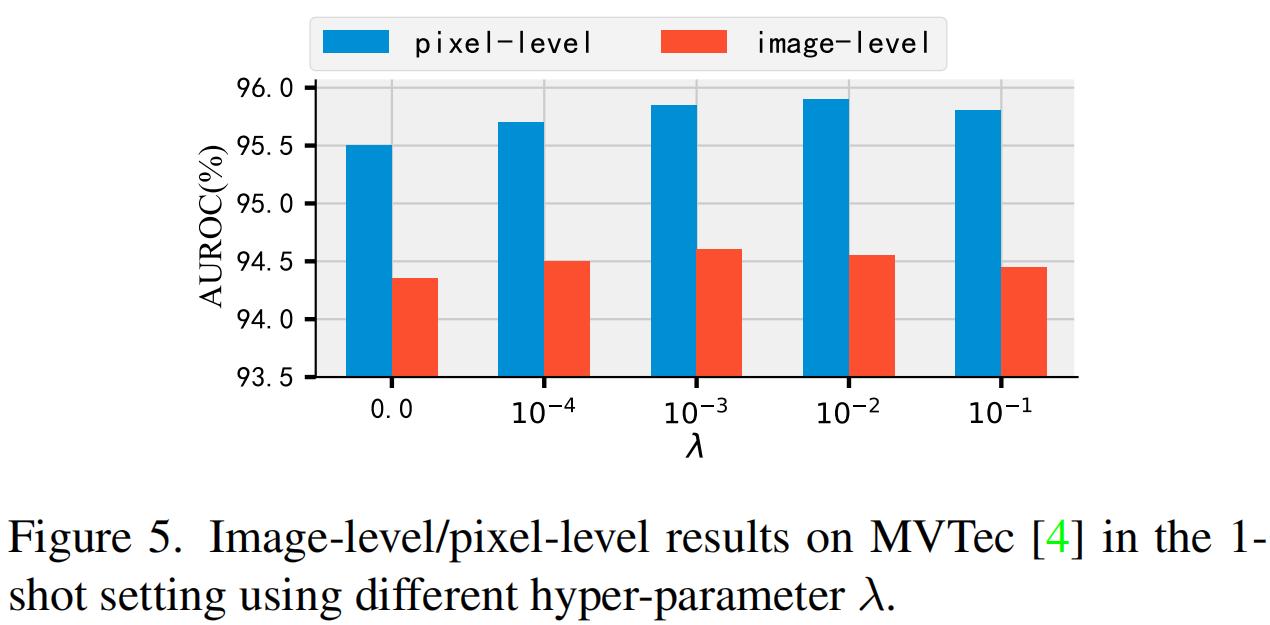
图5记录了不同λ的图像级/像素级结果。可以看出,当λ等于或大于0时,结果更差。这表明 MAP 和 LAP 的分布需要对齐,但不能过度对齐,这会降低异常提示的多样性,从而降低模型对异常图像特征的感知。
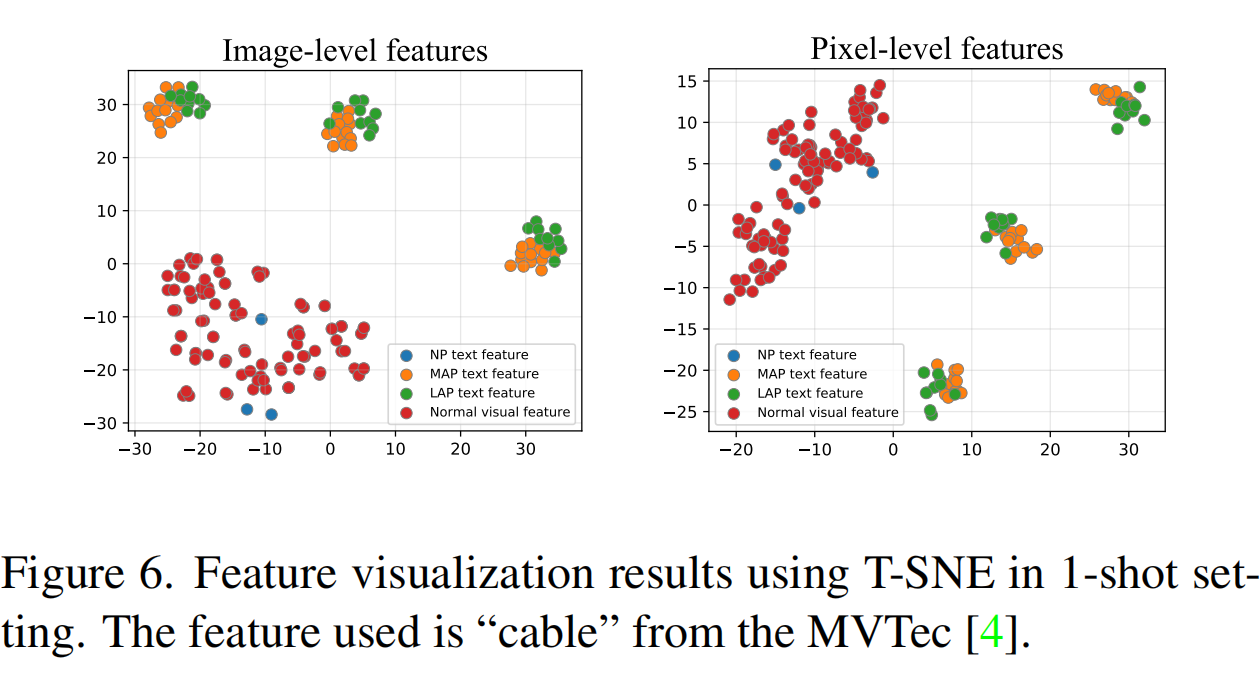
可视化结果
为了量化 PromptAD 的效果,本文对 L2 归一化后的视觉和文本特征进行了可视化。图 6 显示了可视化结果,可以看出正常提示特征和异常提示特征之间的区分非常明显,正常提示特征与正常视觉特征之间的重叠度非常高,证明了 PromptAD 的有效性。
结论
本文提出了一种新的异常检测方法PromptAD,可以在小样本异常检测场景中只使用正常样本自动地学习prompt。首先,为了解决one-class任务的挑战,本文提出了semantic concatenation通过连接mnormal prompt和anomaly suffixe构建anomaly prompt从而引导prompt learning。其次,本文提出了明确的异常边缘损失,通过超参数确定了正常和异常prompt的特征。最后,对于图像级/像素级异常检测,PromptAD在11/12个小样本任务中达到第一。