前言
我们看门见山,生产环境一般用的是在YARN上面采用应用模式进行部署flink程序。实际生产中一般需要和资源管理平台(如YARN)结合起来,选择特定的模式来分配资源、部署应用。
部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink 为各
种场景提供了不同的部署模式,主要有以下三种:
- 会话模式(Session Mode)
- 单作业模式(Per-Job Mode)
- 应用模式(Application Mode)
它们的区别主要在于:
- 集群的生命周期以及资源的分配方式;
- 以及应用的 main 方法到底在哪里执行------客户端(Client)还是 JobManager。接下来我们就做一个展开说明。
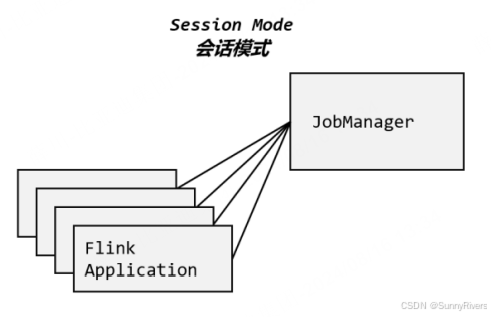
1. 会话模式(Session Mode)
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中
通过客户端提交作业,如图 所示。集群启动时所有资源就都已经确定,所以所有提交的
作业会竞争集群中的资源。
(1)优点
只需要一个集群,所有作业都这个集群提交,作业结束直接释放资源,集群依然正常运行。
(2)缺点
- 资源共享、资源不够的时候,作业提交就会失败。
- 同一个 TaskManager 上可能运行了很多作业,如果其中一个发生故障导致 TaskManager 宕机,那么所有作业都会受到影响。
- 客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给
JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的
资源消耗。
(3)适用场景
会话模式比较适合于单个规模小、执行时间短的大量作业。
-
单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个
提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式,如下图所示。

(1)优点
提交一个作业,就会启动一个集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager
管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。
(2)缺点
客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给
JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的
资源消耗。
(3)适用场景
作业通常是短暂运行的,并且可能经常更改或更新,那么每次作业运行都启动一个新的JobManager实例可能会更有优势。
-
应用模式(Application Mode)
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给 JobManager
的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给
JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的
资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到 JobManger 上运行。而这也就
代表着,我们需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这
个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了,这就是所
谓的应用模式,如下图所示。

应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交
的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应
用程序的,并且即使应用包含了多个作业,也只创建一个集群。
(3)适用场景
实际生产中最常用的模式。
YARN结合三种部署模式
独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他
第三方资源框架的耦合性,独立性非常强。但我们知道,Flink 是大数据计算框架,不是资源
调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架
集成更靠谱。而在目前大数据生态中,国内应用最为广泛的资源管理平台就是 YARN 了。
一句话总结YARN上部署过程
客户端把 Flink 应用提交给 Yarn 的 ResourceManager,
Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署
JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业
所需要的 Slot 数量动态分配 TaskManager 资源。
-
会话模式提交作业
bin/flink run -c com.exmple.FlineDemo FlinkDemo-1.0-SNAPSHOT.jar -
单作业模式模式提交作业
bin/flink run -d -t yarn-per-job -c com.exmple.FlineDemo FlinkDemo-1.0-SNAPSHOT.jar早期的另一个写法:
bin/flink run -m yarn-cluster -c com.exmple.FlineDemo FlinkDemo-1.0-SNAPSHOT.jar -
应用模式提交作业
bin/flink run-application -t yarn-application -c com.exmple.FlineDemo FlinkDemo-1.0-SNAPSHOT.jar常用参数详解:
-yjm 指定JobManager所在的Container内存。单位:MB -ytm 每一个TaskManager Container的内存,单位MB。 -ys 每一个TaskManager中slots的数量。 -ynm YARN中application的名称。 -c 指定Job对应的jar包中主函数所在类名。 -yj,--yarnjar <arg> jar包位置 -yt,--yarnship 传输指定目录下的文件(t用于传输) -yqu,--yarnqueue <arg> 指定yarn队列 -yD <property=value> 自定义参数 -yid,--yarnapplicationId <arg> 指定yarnid执行 -yq,--yarnquery 显示可用的YARN资源(内存,核心) -d,--detached 后台执行
YARN高可用
YARN 的高可用是只启动一个 Jobmanager, 当这个 Jobmanager 挂了之后, YARN 会再次
启动一个, 所以其实是利用的 YARN 的重试次数来实现的高可用。
-
在 yarn-site.xml 中配置
yarn.resourcemanager.am.max-attempts 4 The maximum number of application master execution attempts.
注意: 配置完不要忘记分发, 和重启 YARN。
-
在 flink-conf.yaml 中配置
yarn.application-attempts: 3
high-availability: zookeeper
high-availability.storageDir: hdfs://hadoop102:9820/flink/yarn/ha
high-availability.zookeeper.quorum:
hadoop102:2181,hadoop103:2181,hadoop104:2181
high-availability.zookeeper.path.root: /flink-yarn -
启动 yarn-session。
-
杀死 JobManager, 查看复活情况。
注意: yarn-site.xml 中配置的是 JobManager 重启次数的上限, flink-conf.xml 中的次数应该
小于这个值。