Flink提供了两种基于时间的合流操作,分别是窗口联结(Window Join)和间隔联结(Interval Join)。
一、窗口联结(Window Join)
Flink为基于一段时间的双流合并提供了一个窗口联结算子。在定义的时间窗口中,通过两条流中共享的公共键(key)来进行两条流中的数据的匹配。
窗口联结在代码中的实现,首先需要调用DataStream的.join()方法来合并两条流,得到一个JoinedStreams;接着通过.where()和.equalTo()方法指定两条流中联结的key;然后通过.window()开窗口,并通过.apply()传入联结窗口函数进行处理计算。其调用形式如下所示:
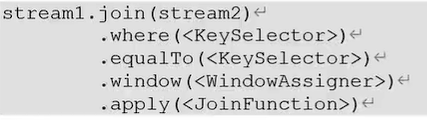
上述代码中.where()的参数是键选择器(KeySelector),用来指定第一条流中的key;而.equalTo()传入的KeySelector则指定了第二条流中的key。两者相同的元素,如果在同一个窗口内,就可以进行匹配,如果不在同一个窗口内,即便是key相同也不会进行数据匹配。这里的.window()传入的就是窗口分配器,就是前几节讲的滚动窗口、滑动窗口、会话窗口。.apply()就是对两个流中匹配的数据进行处理的操作。
二、间隔联结(Interval Join)
在有些场景下,利用窗口联结会有些问题,就是我们要处理的时间间隔可能并不是固定的,这时就不应该应用滚动窗口或者滑动窗口来处理了。
间隔联结的原理就是针对一条流中的每一条数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另外一条流中的数据匹配。
间隔联结的具体定义方式是,我们给定两个时间点,分别叫做间隔的"上界"(upperBound)和"下界"(lowerBound);于是对于一条流中的任意一个数据元素a,就可以开辟这条数据的时间间隔a.timestamp + lowerBound,a.timestamp + upperBound,然后根据这个时间间隔去另外一条流中找在这个时间间隔内并且有相同key的数据。其大致详情如下图:
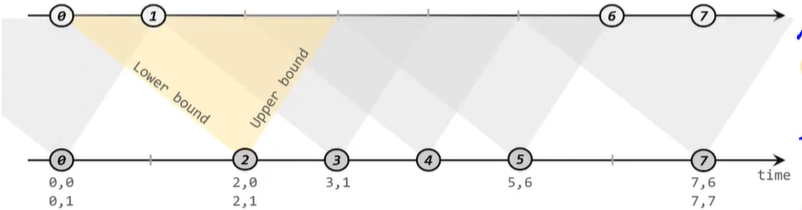
对于迟于这个时间间隔的数据才到来的数据,由于其水位线可能已经高于这个时间间隔,那么它就不会再被纳入处理,这种数据就会被丢弃。如果想把丢弃的数据展示出来,可以采用侧输出的方式将数据输出到侧输出流中。