一、Flink是什么
Flink是一个框架和分布式计算引擎,用于对有界(批量)和无界(流式)数据流进行有状态的计算。
在这个概念中,说明了Flink既可以进行流式处理又可以进行批量处理。对于有界数据流的处理就是批量处理;对于无界数据流的处理就是流式处理。
有界数据流和无界数据流的区别就是两者的数据输入有无终止。无界数据流无终止,数据源源不断的输入;有界数据流的输入数据有终止。
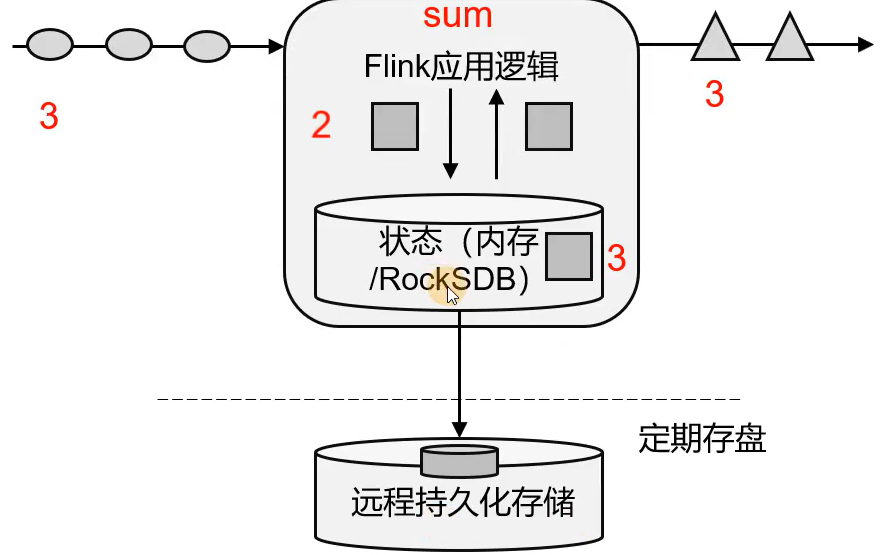
其次,Flink还是有状态的计算。状态就是在流处理的过程中需要的额外数据(比如中间结果),Flink会将这个数据保存成一个'状态',然后在后续的数据处理过程中会更新该状态。而且这个'状态'信息会被Flink保存在本身任务的内存中,同时为了'状态'的可恢复,Flink也会将'状态'信息持久化到磁盘中去。其大致流程如下:
二、Flink的主要特点
(1)、高吞吐和低延迟:Flink每秒可以处理百万级别的数据,且是毫秒级延时。
(2)、结果的准确性。Flink提供了事件时间和处理时间两种语义。对于乱序的数据,Flink利用事件时间语义一样可以保证数据结果的一致性。比如:某一个数据发出时候的时间是23:59(事件时间)分,到达Flink被处理时的时间是第二天的0:01(处理时间)分,那么Flink会将这条数据按照前一天的事件时间来处理,从而保证这一天的数据处理结果是准确的。其实这个特点是要和Spark Streaming对比着看才能体会到,Spark Streaming只有处理时间语义,就是每个数据只会被标记被处理时候的时间,那如果就像是上面的例子一样,这条数据就不会被算作是前一天的数据,而是会被当做是第二天的数据来处理。
(3)、精确一次(exactly-once)的状态一致性保证。
(4)、高可用。Flink本身可以保证高可用,加上与K8s,YARN和Mesos的集成,再加上从故障中快速恢复和动态扩展的能力,Flink可以做到7*24小时运行,极少停机。
三、Flink和Spark Streaming的对比
从数据处理方式对比:Flink是流式处理;Spark Streaming是微批量处理。
从时间语义上对比:Flink有事件时间语义和处理时间语义;Spark Streaming只有处理时间语义。
从状态上来看:Flink是会在内存中存储状态的;Spark Streaming中不会在内存中存储状态,他一般要将中间结果存储在MySQL或者Redis中的。
从流式SQL中来说:Flink是支持使用Flink SQL来进行数据处理的;Spark中尽管有Spark SQL但是他并不是针对批量数据的数据处理,不是在Spark Streaming中使用的。