
作者 | Chao Tian (tyrantlucifer),Apache SeaTunnel PMC Member
摘要
Apache SeaTunnel作为一个高性能数据同步工具,以其高效的数据处理能力,为数据集成领域带来了创新。在引擎上,Apache SeaTunnel除了支持自身的Zeta引擎外,还支持Spark和Flink。在2024年的CommunityOverCode Asia,Apache SeaTunnel PMC Member 田超在论坛上为大家介绍了Apache SeaTunnel基于Flink的演进历程、架构设计、核心特性,以及社区的当前进展和未来规划。以下为演讲核心内容整理:
Apache SeaTunnel基于Flink的演进历程
Apache SeaTunnel的演进主要体现在两个API版本上:
- Flink API V1:SeaTunnel的初始API版本,与Flink的计算引擎紧密耦合,connector紧密依赖Flink接口。
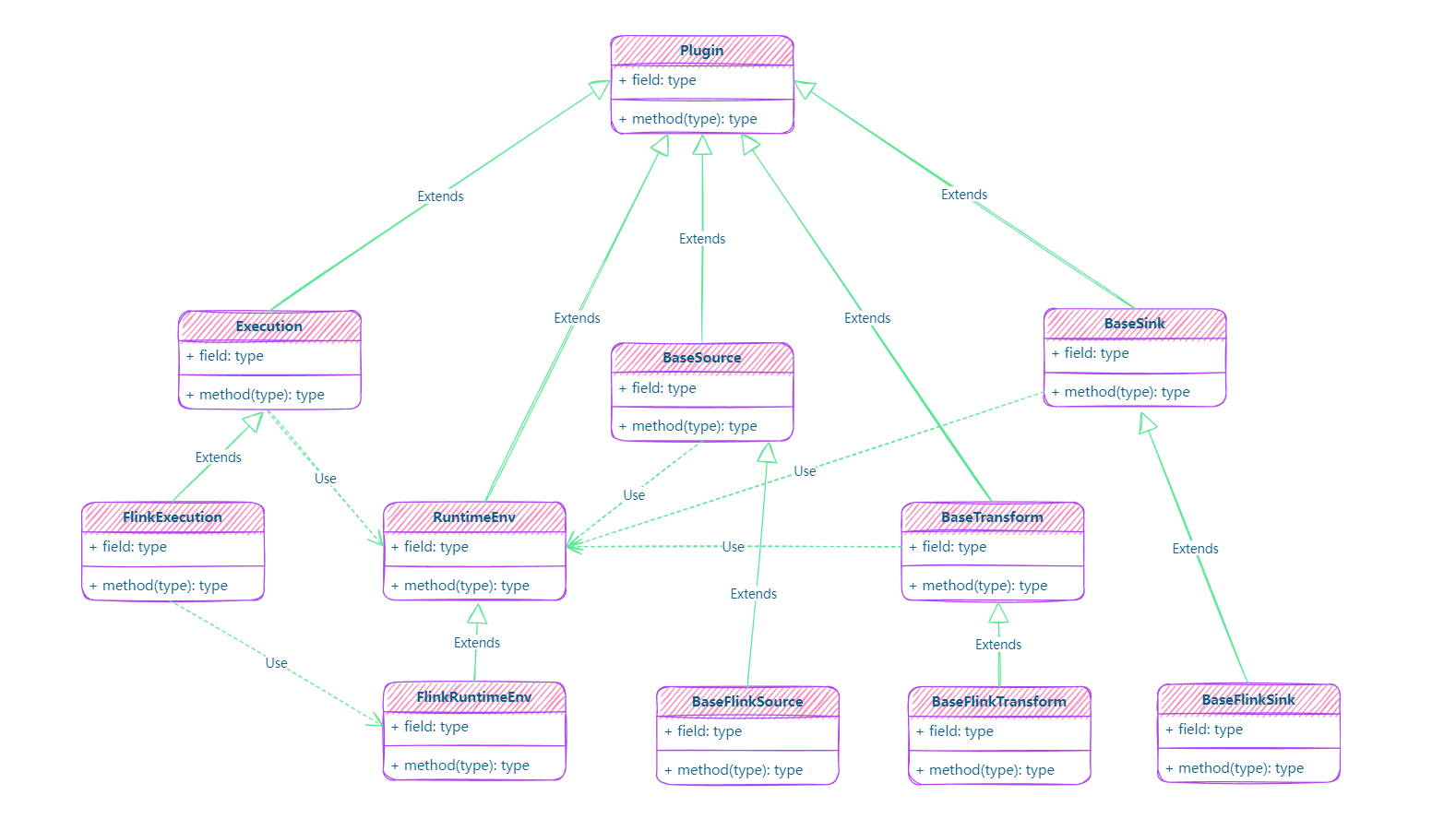
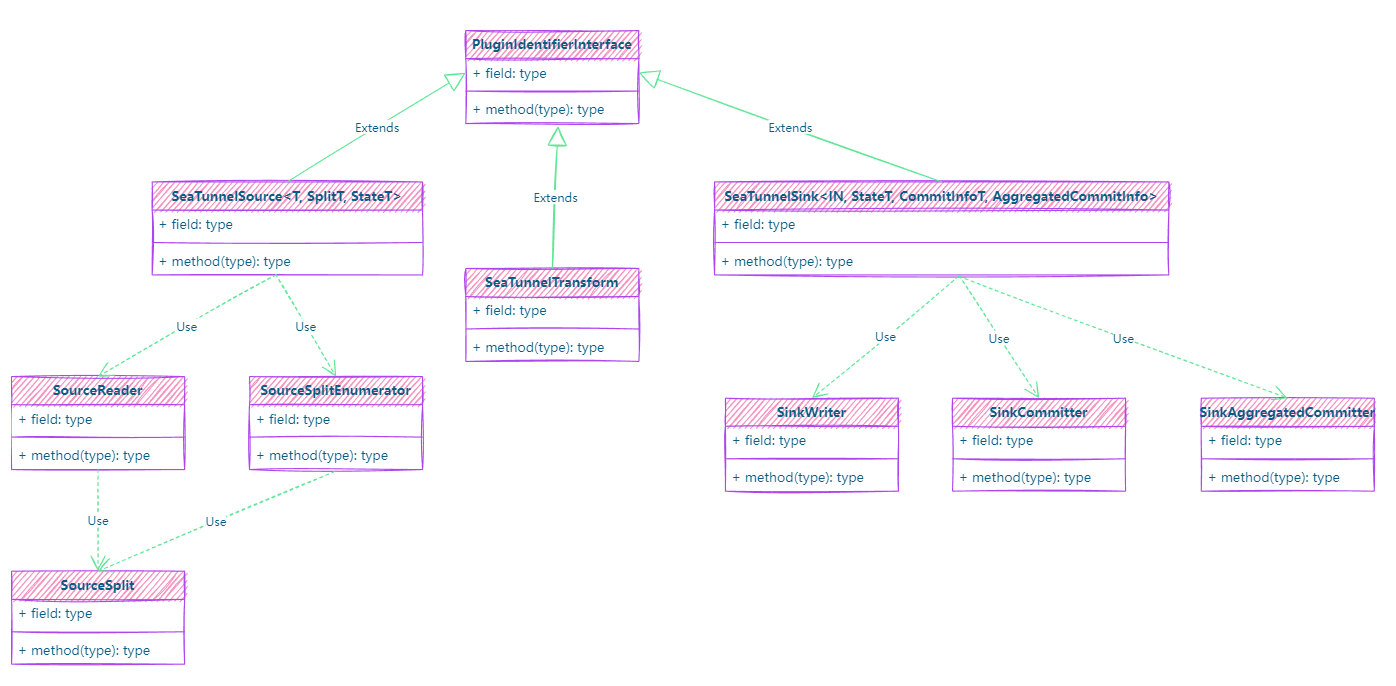
- Flink API V2:SeaTunnel的新一代API,所有的插件还是继承了plug-in的形式,但实现了与计算引擎的解耦;支持更多Flink版本;不依赖于Flink原生连接器,Sink增加了Writer、Committer和Aggregated Committer,Source增加了Reader、Split和Split Enumerator;降低了Flink升级的成本;并提供了更细粒度的接口,增强了系统的可扩展性,满足更多元化的数据源的同步需求。
基于Flink的架构设计
从Job运行的角度,Apache SeaTunnel的架构设计紧密依托于Flink的数据处理能力。
在Common API层,SeaTunnel做了插件的抽象化,基于插件的抽象化,SeaTunnel可以对接不同的计算引擎。
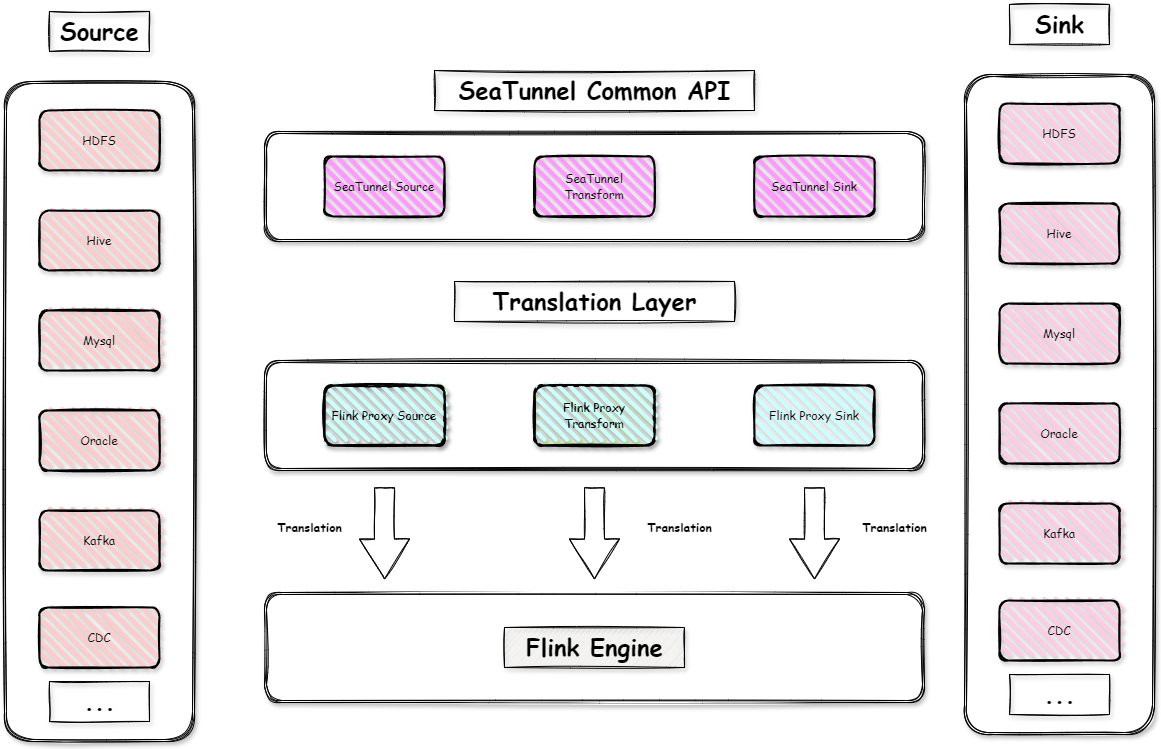
对接层在SeaTunnel中统称翻译层(Translation Layer)。针对Flink,SeaTunnel实现了Flink代理的Source、Sink和Transform,生成Flink引擎的Job graph后,以实现数据在Flink上高效转换和同步。

基于Flink好用的核心特性
市面上的数据同步工具很多,比如Apache Flink CDC、Chunjun等。
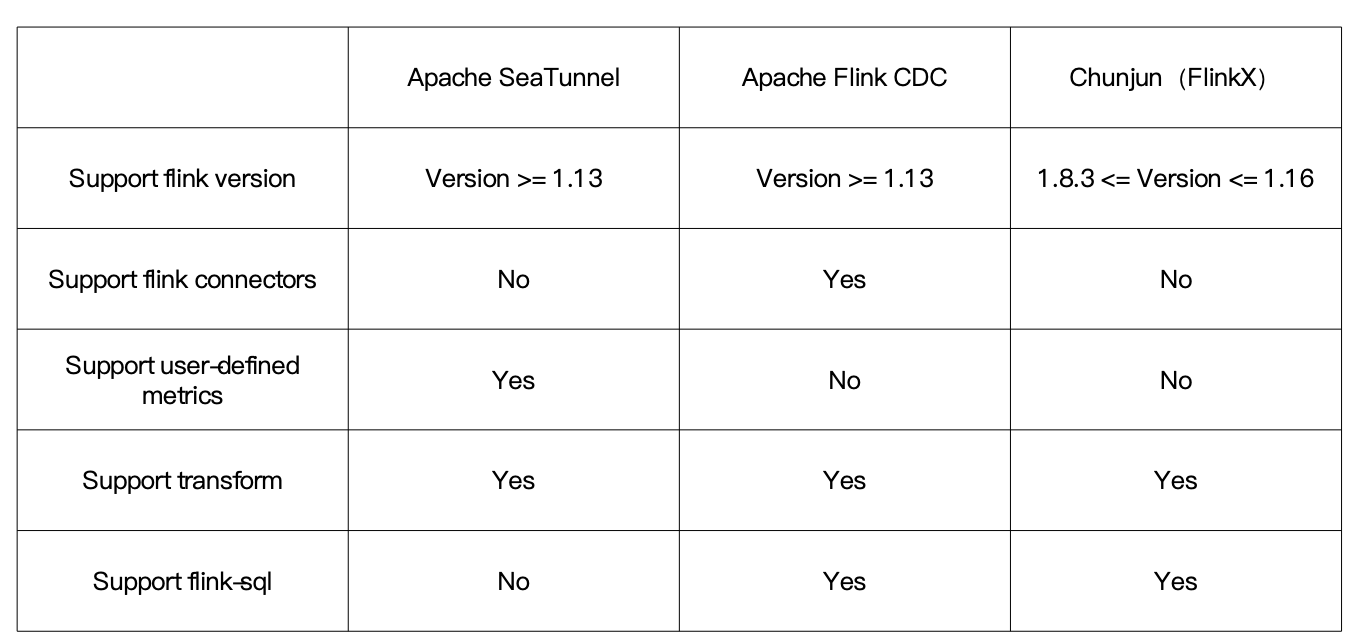
相比之下,Apache SeaTunnel展现了以下特点:
- 支持的Flink版本:SeaTunnel支持1.13及以上版本,提供更广泛的兼容性。
- Flink连接器:SeaTunnel不依赖于Flink原生连接器,提供了更高的灵活性。
- 用户自定义指标:SeaTunnel允许用户定义自己的指标,增强了监控和分析能力。
- 数据转换支持:SeaTunnel支持数据的转换操作,包括但不限于映射、过滤等。
- Flink-SQL:尽管目前SeaTunnel不支持Flink-SQL,但这是社区未来工作的重点之一。
Apache SeaTunnel基于Flink的特性和好用的功能,我们也来总结一下:
- 支持Flink原生的poll-push架构,可以实现实时获取分片数据,有效解决多并行度下的问题,最大化利用资源
- 支持 Flink原生的两阶段提交功能
- 支持Flink原生的用户自定义指标能力
- 支持使用Flink原生的global-accumulator记录数据同步作业详情
- 支持所有Flink作业提交模式(应用模式/会话模式)
- 支持枚举器和读取器之间用户定义的事件通信
- 支持Flink 1.13--1.18之间的所有版本
社区进展与未来规划
目前,Apache SeaTunnel社区正在积极推进以下工作:
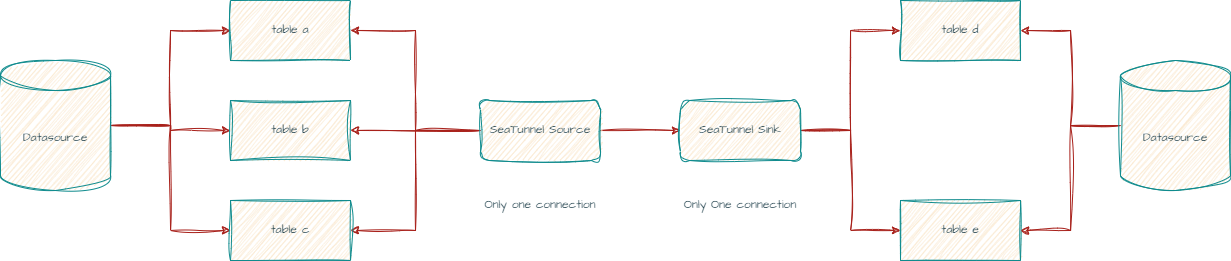
- 多表读写支持:正在开发在Flink引擎上支持多表同时读写的功能,以支持一库多表读写,多表路由等场景,提高数据处理的效率和灵活性。目前,这一功能已在SeaTunnel Zeta引擎上实现。
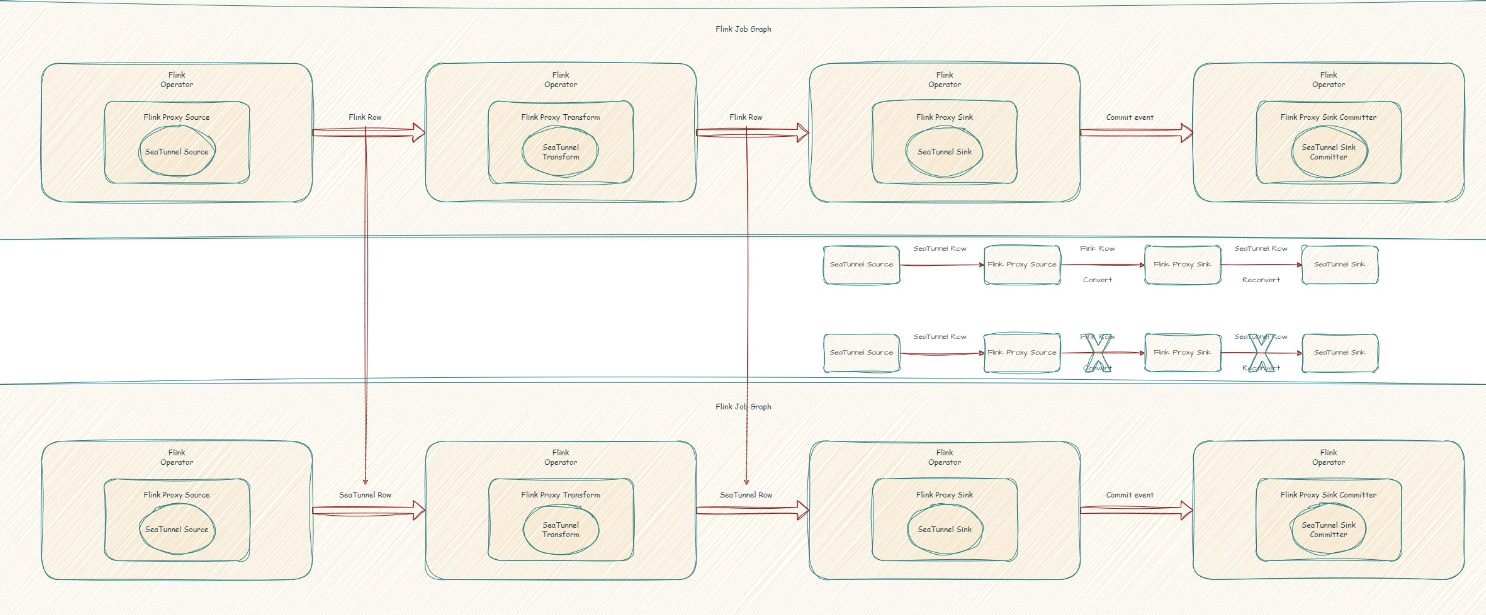
- Flink Proxy Source & Sink重构:当前,Flink Proxy数据的同步需要在Flink proxy Row和SeaTunnel Row数据格式之间进行多次转换,这样的转换不但会有数据精度损失的风险,还极大地降低了数据转化的性能。为此,社区正在进行源和接收器的重构工作,以优化性能和稳定性。
未来,社区还计划实现以下特性:
- 模式演化(Schema Evolution):目前,SeaTunnel仅在Spark和Zeta引擎上支持模式演化功能,未来,社区计划在Flink上支持数据模式的动态变化,以适应不断变化的数据需求。

- SQL转换支持:计划在Flink上支持SQL转换,包括选择投影、用户定义函数(UDF)、用户定义表函数(UDTF)和过滤条件等,以提供更丰富的数据处理能力。

结语
Apache SeaTunnel作为数据同步领域的一个创新工具,其基于Flink的高效数据处理能力,为数据集成带来了新的解决方案。社区的不断努力和创新,将使Apache SeaTunnel在未来的数据同步任务中发挥更大的作用。如需进一步了解或参与Apache SeaTunnel项目,欢迎加入社群参与讨论。
本文由 白鲸开源科技 提供发布支持!