免责声明
本文所述内容仅供学术研究和技术讨论之用。作者提供的信息仅为个人观点,并不代表任何组织或公司的立场。所涉及的技术和方法仅用于教育目的,不鼓励或支持任何非法或不道德的行为。
任何使用本文所述技术的行为,请确保遵守适用的法律法规和相关网站的使用条款。作者对于因使用本文信息而导致的任何直接或间接的损失或法律责任不承担任何责任。请在进行网络爬虫相关操作时,保持合法合规的操作,并尊重他人的知识产权和隐私权。
1、常见的反爬策略(了解)
概述:常言道:"知己知彼方能百战不殆",在学习爬虫反反爬之前一定要了解有哪些反爬的手段,方能对症下药,逐个击破。
1.1、通过请求头headers反爬
概述:headers中有很多字段,这些字段都有可能会被对方服务器拿过来进行判断是否为爬虫。
1.1.1、通过User-Agent字段反爬
反爬原理:爬虫默认情况下没有User-Agent,而是使用模块默认设置。
解决方案:请求之前在配置文件settings.py中添加User-Agent即可;更好的方式是使用User-Agent池来解决(收集一堆User-Agent的方式,或者是随机生成User-Agent,例如第三方库fake-useragent)
1.1.2、通过referer字段反爬
反爬原理:爬虫默认情况下不会带上referer字段,服务器端通过判断请求发起的源头,以此判断请求是否合法。
解决方案:在目标网站中通过浏览器工具获取referer字段并将其添加到请求头中。
1.1.3、通过cookie字段反爬
反爬原理:通过检查cookies来查看发起请求的用户是否具备相应权限,以此来进行反爬。
解决方案:进行模拟登陆,成功获取cookies之后将其添加到请求头中再进行数据爬取。
1.2、通过请求参数反爬
概述:请求参数的获取方法有很多,向服务器发送请求,很多时候需要携带请求参数,通常服务器端可以通过检查请求参数是否正确来判断是否为爬虫。
1.2.1、通过html静态文件获取请求参数
反爬原理:通过增加获取请求参数的难度进行反爬。
解决方案:通过查看html源码观察登录页是否传递了什么参数。
1.2.2、通过发送请求获取请求数据
反爬原理:通过增加获取请求参数的难度进行反爬(说白了就是通过ajax实现了动态页面,通过地址栏的地址获取不到数据)。
解决方案:通常情况下通过抓包获取某条数据的地址后就能找到整页数据的地址。
1.2.3、通过js生成请求参数
反爬原理:通过js对数据进行加密。
解决方案:首先抓取js包,观察加密的实现过程,通过js2py获取js的执行结果,或者使用selenium来实现。
1.2.4、通过验证码反爬
反爬原理:对方服务器通过弹出验证码强制验证用户浏览行为。
解决方案:打码平台或者是机器学习的方法识别验证码,其中打码平台廉价易用,更值得推荐。
1.3、基于爬虫的行为进行反爬
1.3.1、基于请求频率或请求次数反爬
概述:爬虫的行为与普通用户有着明显的区别,爬虫的请求频率与请求次数要远高于普通用户。
①、通过请求ip/账号单位时间内总请求数量进行反爬:
反爬原理:正常浏览器请求网站,速度不会太快,同一个ip/账号大量请求了对方服务器,有更大的可能性会被识别为爬虫。
解决方案:对应的通过购买高质量的ip的方式能够解决问题/购买个多账号。
②、通过同一ip/账号请求之间的间隔进行反爬
反爬原理:正常人操作浏览器浏览网站,请求之间的时间间隔是随机的,而爬虫前后两个请求之间时间间隔通常比较固定同时时间间隔较短,因此可以用来做反爬。
解决方案:请求之间进行随机等待,模拟真实用户操作,在添加时间间隔后,为了能够高速获取数据,尽量使用代理池,如果是账号,则将账号请求之间设置随机休眠。
1.3.2、通过js跳转实现反爬
反爬原理:开发者在代码中埋了只有爬虫能获取到的链接或按钮,使爬虫重定向到指定页面,从而无法获取数据。
解决方案:多次抓包获取url,分析规律。
1.3.3、通过陷阱获取爬虫ip(或者代理ip)
反爬原理:在爬虫获取链接进行请求的过程中,爬虫会根据正则,xpath,css等方式进行后续链接的提取,此时服务器端可以设置一个陷阱url,会被提取规则获取,但是正常用户无法获取,这样就能有效的区分爬虫和正常用户。
解决方案:完成爬虫的编写之后,使用代理批量爬取测试/仔细分析响应内容结构,找出页面中存在的陷阱。
1.3.4、通过假数据反爬(投毒)
反爬原理:向返回的响应中添加假数据污染数据库,通常不会被正常用户看到。
解决方案:长期运行,核对数据库中数据同实际页面中数据对应情况,如果存在问题/仔细分析响应内容。
1.3.5、阻塞任务队列
反爬原理:通过生成大量垃圾url,从而阻塞任务队列,降低爬虫的实际工作效率。
解决方案:观察运行过程中请求响应状态/仔细分析源码获取垃圾url生成规则,对URL进行过滤。
1.3.6、阻塞网络IO
反爬原理:发送请求获取响应的过程实际上就是下载的过程,在任务队列中混入一个大文件的url,当爬虫在进行该请求时将会占用网络io,如果是有多线程则会占用线程。
解决方案:观察爬虫运行状态/多线程对请求线程计时。
1.3.7、运维平台综合审计
反爬原理:通过运维平台进行综合管理,通常采用复合型反爬虫策略,多种手段同时使用。
解决方案:仔细观察分析,长期运行测试目标网站,检查数据采集速度,多方面处理。
1.4、基于数据加密进行反爬
概述:通常的特殊化处理主要指的就是css数据偏移/自定义字体/数据加密/数据图片/特殊编码格式等。
1.4.1、通过自定义字体反爬
反爬原理:使用自有字体文件。
解决方案:切换到手机版/解析字体文件进行翻译。
1.4.2、通过css反爬
反爬原理:源码数据不为真正数据,需要通过css位移才能产生真正数据。
解决方案:计算css的偏移。
1.4.3、js动态生成数据实现反爬
反爬原理:数据通过js动态生成。
解决方案:解析关键js,获得数据生成流程,模拟生成数据。
1.4.4、通过数据图片化反爬
解决方案:通过使用图片解析引擎从图片中解析数据。
1.4.5、通过编码格式进行反爬
反爬原理:不适用默认编码格式,在获取响应之后通常爬虫使用utf-8格式进行解码,此时解码结果将会是乱码或者报错。
解决方案:根据源码进行多格式解码,或者真正的解码格式。
2、图片验证码
2.1、初识图片验证码
概述:
验证码(CAPTCHA)是"Completely Automated Public Turing test to tell Computers and Humans Apart"(全自动区分计算机和人类的图灵测试)的缩写。也就是说,这个东西最开始设计的目的,就是为了区分请求来自机器还是人类。可想而知,验证码就是为了反爬而生的。如果这个世界没有爬虫,可能也就不会诞生验证码
早期的验证码只是能够把一些简单的文字转换成图片来让用户识别,但也是一大杀器了。因为在 OCR 技术(Optical Character Recognition,光学字符识别)还不发达的时候,验证码可以说秒杀所有的爬虫。但是后来随着 OCR 的发展,识别验证码已经沦落为机器学习的入门课程,成了学生练手项目。最开始无敌的验证码,就这样被时代秒杀了。
随着技术的发展,现在的验证码变得越来越奇葩,已经不仅仅是图片识别成文字的形式了。例如 Google 的找出自行车、12306 的找出手表,甚至一些网站的出现各种动态验证码等等,原本用于识别人类的验证码,逐渐变得越来越反人类。
使用场景:
- 注册
- 登录
- 频繁发送请求时,服务器弹出验证码进行验证
处理方案:
-
手动输入(input) 这种方法仅限于登录一次就可持续使用的情况
-
图像识别引擎
-
Tesseract
- Tesseract,一款由HP实验室开发由Google维护的开源OCR引擎,特点是开源,免费,支持多语言,多平台。
-
TensorFlow
- TensorFlow是一个开源软件库,用于各种感知和语言理解任务的机器学习,目前被50个团队用于研究和生产许多Google商业产品,如语音识别、Gmail、Google 相册和搜索
-
PyTorch
-
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序
- PyTorch是相当简洁且高效快速的框架
- 设计追求最少的封装
- 设计符合人类思维,它让用户尽可能地专注于实现自己的想法
- 与google的Tensorflow类似,FAIR的支持足以确保PyTorch获得持续的开发更新
- PyTorch作者亲自维护的论坛 供用户交流和求教问题
- 入门简单
-
-
2.2、通过手动输入通过验证码
概述:通过手动输入绕过验证码的核心思路如下:
- 获取验证码
- 输入验证码
- 提交并验证数据
实操:通过手动输入验证码的方式通过某平台的登录验证。
python
# 导包
import requests
from fake_useragent import UserAgent
def smalte_login():
# 定义目标网址
login_url = 'https://www.chaojiying.com/user/login/'
image_url = 'https://www.chaojiying.com/include/code/code.php?u=1'
# 获取一个可以保存session的请求对象(解决爬虫不会自动保存session的问题)
session = requests.Session()
# 创建请求头
headers = {'User-Agent':UserAgent().chrome}
# 向验证码图片发送请求并获取响应
img_resp = session.get(image_url,headers=headers)
# 将验证码图片响应的内容保存到本地
with open("./log.jpg",'wb') as f:
f.write(img_resp.content)
# 等待手动输入验证码
code = input("验证码:")
# 构建表单(表单内容通过登录页的负载获取)
# 下面省略了用户名和密码,替换成自己的用户名和密码即可
form = {
'user': '',
'pass': '',
'imgtxt': code,
'act': 1
}
# 发送请求
login_resp = session.post(login_url,data=form,headers=headers)
# 打印登录后的内容
print(login_resp.text)
if __name__ == '__main__':
smalte_login()运行结果如下:
2.3、通过平台输入通过验证码
概述:通过平台输入通过验证码的核心思路如下:
- 获取图片内容
- 提交给打码平台
- 获取验证码
- 提交并验证数据
实操前准备:
①、进入超级鹰平台注册一个账号;
②、在超级鹰平台购买至少1元的题分;
③、进入超级鹰首页 > 开发文档 > 各语言SDK例子下载 > 下载超级鹰Python语言demo,将下载的压缩包解压后放进python文件的同级目录;
④、进入超级鹰平台首页 > 用户中心 > 软件ID > 生成一个软件ID 。
下面给出超级鹰平台提供的python语言demo:
python
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
'file_base64':base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print (chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码下面给出项目结构方便理解(chaojiying_Python是从官方文档下载的python语言的demo解压后的文件夹):
实操:通过超级鹰解析目录中log.jpg图片中的验证码内容。
python
from chaojiying_Python.chaojiying import Chaojiying_Client
def pic_str(img,pic_type=1902):
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '实操前生成的软件ID')
# 打开要识别的图片,传入本地图片的路径
im = open(img, 'rb').read()
# 将本地图片上传到打码平台
resp = chaojiying.PostPic(im, pic_type)
# 获取返回的json数据中验证码的值
resp_code = resp.get('pic_str')
# 打印验证码方便验证
print(resp_code)
# 实战中将resp_code替换到表单中的验证码即可
return resp_code
if __name__ == '__main__':
pic_str('图片地址','这里传入验证码的类型,参考首页中的价格体系')运行结果如下:

3、图片加密之base64
问题
获取的图片内容为如下所示,如果下载图片?
解决方案
这个内容就是图片数据,只不过是通过base64进行了图片的转码。将内容转码保存数据即可。

实操:将一个被base64加密的图片进行解码并将其保存。
python
import base64
import re
# decode_img用于演示被base64加密的图片进行解码
def decode_img(src,img_name):
# 提前图片中的后缀名和数据
img = re.search('data:image/(.+);base64,(.+)',src)
# 如果提取到了内容就执行以下操作
if img:
# 保存图片后缀
img_type = img.group(1)
# 保存图片数据
img_data = img.group(2)
# 对通过base64编码加密的数据进行解码
decode_img_data = base64.urlsafe_b64decode(img_data)
# 保存图片
with open(f'./{img_name}.{img_type}','wb') as f:
f.write(decode_img_data)
else:
raise Exception("图片解析失败")
if __name__ == '__main__':
src = 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAANkAAABfCAYAAABlV2KzAAAAAklEQVR4AewaftIAAB5sSURBVO3B/VMc953g8fdn6GFgGAkEiJEEQkLPQrYkW2pH68jOOrneTcqX2t27q1y2Lj/1HzZ1VXd1t7V1W3eXnLOpnd31bozjxGNFsmzQIxoJARIIECA0MNOIz6n3W1TTzAAzMOjJ83qJqlJTU7N9ItTU1Gwriw2ICG8IoeZVo7wBVJX1WLwcQk0NCC+e8oJZbB9h+whvJqF6lDeTsjXC2pRtYFEdwsaEzRGqQ/huEV59SuWEYsrmKGFCMWWLLLZGKE0oTVibUDlha4RXi1A9yqtFKSaUT1mbUJqyNgWEYkqYYCibZLE5QjEhTAgTigmlCRsTNiZsD+G7S9keysaUjSkBIaCECaCEKSAElIBgKBWyqJwQJoQJhhAQAkKYUEwoTVibUD6hPMKLI1Sf8uIo5VHKp6xNKU0ppoAQUAwBlGKKIRhKQAClAhaVEcKEgGAIhmAIhhAQAkJACBOKCaUJaxPWJmyOUH1C9SjVp2yOsjZlbUppSjElTAkoAQUEQwEBlNIUQwAlIIBSJovyCWGCIRiCIRgCCIZgCIZgCAHBEMKEMCEglCaUJpQmrE+oDuHVoVSHsj6lNKU0pTQloIQpYYqhBBRDMRQQQAEBlLUpIIASEEApg8XmCIZgCCAYAgggGAIIhgCCIRiCIRhCQAgIASFMCBNKE8KE0oT1CVsnvHjK1inrU0pTwpTSlDAlTAkoASWgGIqhGIqhgGIooIAACihhCgiggABKhSzKIwQEQzAEEEAAwRBAAAEEEEAwBBAMAQRDMARDCAiGEBACQpgQJoQJxYRiQmnC1gkbE8qnbEzZOqU0pZhSTAlTwpQwJaAEFEMJKIZiKIYCiqGAYiiggAJKQAAloIAACgigGAIoG7DYGgEEEEAAAQQQQAABBBBAAMEQQADBEAwBBEMwBEMwhIAQEAJCQAgTwoQwoZhQmrB5wsaE8ikbUzZPKU0ppoQpYUqYElACSkAJKIZiKIZiKKAYiqGAAoqhgAIKKKCAAgooxZRNsqiMYAilCSCAAAIIIEAEEEAAwRBAAMEQQDAEEAzBEAzBEAwhIASEgBAQwoQwIUwIE8ojlE/YmFBM2ZhSPqU8SpgSpoQpYUpACSgBJaAYiqEYiqEYCiiGAoqhgAKKoYACCixRmlJMAAUEUMpksXkCCCCAAIIhgAACRAABBBBAAAEEEEAAAQRDAMEQQDAEEAzBEAwhIBhCQAgTAkJACBPChGJC+YT1CRsTAsrGlPUp5VOKKWFKmBJQAkqYElAMJaAYiqEYCiiGAoqhgGIooIACCihhEUCBJQIKCMWUTbDYmFAeAQRDAMEQQAABBIgAgiGAAAIIIBgCCCAYAgiGYAiGYAgBISAEhIBgCGFCQAgTShMqI5QmrE8IKOtTSlMqo5SmhCkBJUwxlIASUAJKQDEUQzEUQwHFUEABBQRQQAkTQIElwhQQDAUEQ9mYAMo6LKpDCAiGAIIhgABCQAABBBBAAMEQQADBEEAwBEMwBEMwhIBgCAEhIASEgBAmhAnrE8onFBM2JpSmGEJACQjrU8KEMMUQDMUQDAUEQzEEUEAwFBAMBQRQDAGU7aEYQkABwVBAAMUQQNkii+oSiglhAggggABCmBAmBARDMARDMISAYAgBISAYQkAIE8KEYkJlhNKEtQlrU8KEgGIIYcrahGJKQDAUQzAUQzAUEAwFBFAMARRDAAUEUAwBFBBAAQEUEEABARRDACUggBIQiikBAZQwAZQqsaguBYQwBYSAUkwIKCAEFBAMBQRQQAAFBFBAAAUEQwEBFBAMBQRDAQEUQwDFEAzFEAzFEAJKMWFtSphgKAEhTCmfUkwpn7I+JUwJUwJKQAkoAcVQAoqhGIqhGEpACVPCFFBAAQWUMKWYUkUW1aGAYCgggAKCoQQEQ9keCgiGAgIohgCKIYACgqEYAiiGYCiGYChhQpiyPiGgBARDKU0IKOtTSlMqo5SmhCkBJUwxlIASUAJKQDEUQzEUQwHFUEABxVBAAQUUUAIKKKAEFEMJKFVgsTEFhI0phgCKoRRbAgQQwhQQQAAFBBAMAQRDMARDCAiGEBDChIAQEAJCmFBMqIywPmFjQkDZmLI+pTJKMSVMCSgBJaCEKQHFUAKKoRiKoYBiKKAYCiiGAgoooIACCiiggAIKKKAYCijlUTZgsXlKMQGUwBIQoZgCAgggGAIIhgCCIRiCIRiCIQSEgBAQAkKYEBDChGJCeYTyCesT1qasTymfUh6lmBKmBJQwJaAElIASUAzFUAzFUAwFFEMBxVBAAcVQQAEFFFgCFFBAMRRQQAEFlE2yqIwCAiggFFOKLQECCCAYAgggGIIhgGAIhmAIhhAQAkJACAhhQpgQJoQJaxM2T9iYUD5lY8rmKWtTwpQwJUwJUwJKQAkoAcVQDMVQDAUUQzEUUEAxFFBAAQUUUEABpTTFUCpgsTVKMQUEEEAAAQQQDAEEQwDBEAzBEAKCIQSEgBAmhAlhQjGhmFCasHXCxoTyKRtTtk4pTSmmFFPClDAlTAkoAcVQAoqhGIqhgGIooBgKKKCAAgoohgIKKKBsgUV5FBAMBQRQQAAloIAQUEAAwRBAMARDMARDCAgBISCECWFCaUKYUJqwPmHrhBdP2TplfUppSphSmhKmhCkBJaAEFEMxFEMxFFAMBRRDAQUUQwHFUAwloJTBYnMUEEABAZQwBQQQQAHBEAzBEAKCIYQJYUJAKE0oTShNWJ9QHcKrQ6kOZX1KaUppSmlKQAlTwhRDCSiGYiiGYiigGIqhGIqhbIJF+RQQAgoIoKxNAQEUEEAxhIAQEMKEYkJpwtqEtQmbI1SfUD1K9Smbo6xNWZtSmlJMCVMCSkAJKIZiKIZiKAElTCmTRWUUEAIKCIZSmgICKIYASkAoJpQmrE0on1Ae4cURqk95cZTyKOVT1qaUphRTwpSAElAMJUwJUypgUTkFhIBiCIZSTAHBUAICKMWEjQkbE7aH8N2lbA9lY8rGlNKUYkqYEqYUUypksTmKIQSUgABKmAJCmBIQAkp5hK0RXi1C9SivFmVrlMopa1NKU0pTNsliaxRDCFOKCaCsTSlNWJtSPqGYUvMyKdWhbI6yMWWLLKpDKSaEKZujFBMqp7z6hOpR3kzK9lG2gcX2UdYmbI3yZlJqtpvyglm8HMqLJ9S8apTvAFFVampqtk+EmpqampqampqampqampqampqamprNEH2ObSTPsYo+xzaS51hFn2MbyXOsos+xjeQ5VtHn2EbyHKvoc2wjeY5V9Dm2kTxHlVisMjMxTHagDy+fo1zRWJye3os0t3dRTYWFOZ7OTmJFYyRaOhCJUPN6mJkYJjvQh5fPUa5oLE5P70Wa27t4k1iskh3ow8vnqISXz5Ed6OPshz+nWkYGL/MgewVVxdfQ1Myxd/6MWOMOal592YE+vHyOSnj5HNmBPs5++HOqZdHLc+/6F6DKgZN/ghVt4EWzWMXL5/CdtD8m0ZJkI3PTY1zLfIKXz1EtMxPDjN65TH1Dgt2dx8jnZpl4cJvBb/6F3vd+Sk1l/vjpf+fZYoFK1Fn1vPvRL9gsL5/DZzsu5cqkU3j5HNUy/WiIuwOf4xXm8T15/IADJ99nV8dBXiSLNSRakpQj0ZKk2saHr+M7cuaHNO1sx7e4WGD60RBPZydo2tnOdrmW+QTfSftjal5Pi16e+ze/ZGL0Fr4du/bge/L4Ibe//mda9xziwIk/wYrGeBEsXkHzc4+J1EVp2tnOsp2te5l+NMT83GOadrazXfLzT/DyOYZu/J79x95DJMLr7t2PfkEmncJnOy7ryaRT+N796BdUQyad4kWafjTE3Wu/w8vniNRZdB05T3L/SXxj9wcYvvUVUw/v8GTqAQdOvs+ujgNsN4t1ZNIpNmI7LtUWidShusRKS0vP8EXqLLZT5+F3uHf994wNDZB7MsXh0x8RrW9kq3JzU4zd62d26gFePocVjRHf0UqipYNdyR4a4jvxLeRmeTyWZW56nNyTKRa9PNFYnJ2te0keOEU80crrxHZcypVJp9isRS/P0I3fM/lgEF+iuYOetz6kIb6TZcnuUzS3dZHt/4y5mXFuf/1PtO09TPfxC1jRGNvFYh224/IyRGNx5p9Os+jlsaIxfF5+Hl99LM522t15nHiildtf/xNPHj9k4Pf/lyNnfkRT825Wy81O8uTxQ5IHTrGe0TtXGLlzGVRZ5hXmmZkcYWZyhJHBy6ynsDDHxOgtJh7cpvPQO+w7dJatyqRT2I6LL5NOYTsuL0omncJ2XKpldnKEO9/+Fq8wz7K5mXG++fx/sZHJB4PMTj3gYO/3aWnfz3aweAUtPVvE5xXmsaIxfPn5J/isaAObNTMxTHagDy+fYz2JliS9F/6Cwauf8uTxQwa+/BXJ7l66j1/AV8jnuH/zS6Ye3iFa30jywCnWMnL7EqPZrxEROrpPsbvrOA2NO1n0Fnjy+CGPRm6ykJvFy+fwRWNxovUNJLtPsbN1L1a0gYX5WR6N3GB8aICRwT+iS8/oPHKO11EmncKXSaewHZdqGB++jleYZ7O8fI7x+9doad/PdrBYRyadohTbcdkOXmGBe9d+x9zMOD4vn6OxqQXf09kJfNmBPg699SGxxh1UKjvQh5fPUY5ofSPHz/2Y+ze/ZGxogEfDN+g+foGxoX6Gb/+RpWcePq8wz1qezk4wevcqIhGOvvPvaG7rYlk0Fqd1zyFa9xxiI41NLXQf+x7NbZ3cuvKPjGa/pqXjAFthOy7LbMflRcikU9iOSyadwnZcMukUtuOyVUfO/IhXmcU6bMflRXk8fpd7136HV1igvqGJwsJTvMI8yyKROkSEuekxvv3if7P/qE3H/pNUwsvn8NmOSzlEInQfv8DY0ABLS8+4dSXN9KP71Fn1dB/7Ho9GbjD/dJq1jN+/BqokD75Fc1sXK2XSKWzHpRLNbV0ku0/x8O43jN+/xlZk0ilsx8WXSaewHZcXzXZcqiWTTrEVtuOyXSzWkUmnWIvtuFTDopdn6MbvmXwwiEiEzsPvUt/QRLb/M7z8PMsWvQVijTtIHniL4VsZ7l3/gqmxu/ScukiscQeVyqRTrMV2XEqZfnSfREuSw2//gPqGBI9Gb7KemckRfLv3HaNadu87xsO73zA7NcrrxnZcMukUvkw6he24VIvtuLyqLNZhOy7baWZymLv9fRTyORoTuzj01ofEd7QxOzWKz8vn8C09W+TZokd8RysdXSdobuvi7sBnzE494Nsv/g/7j56nY/9JKmE7LpXa23OGzsPvIBKhHF4+h6++McGyTDrFskw6hc92XFbKpFOsZjsuvljjDnxeYZ6tsB2XZbbj8iJk0ilsxyWTTmE7Lpl0CttxqZZMOoXPdlx8mXQKn+24+DLpFD7bcfFl0il8tuOynSxeopt//AdWujvwOb6lZ4v4vMI8Pi+fwzc/N83AH36JT1FEhKVnHveuf8HYUD9vf/8/sZ06D7+DSIRyRWNxvHyOwvwcDU3N+GzHxZdJp7Adl1Jsx2Ut+fkn+KL1jdS8HixeEfNzj1nNy8/j8wrz+Ba9PItenlIWcrNst4Evf8XBk9+naWc75Whu62Ri9BaPRm+y/6hNNTwavYlvZ+s+1jIzMUx2oA8vn2Mtw7cv8fDeN/j2HHibriPnWCmTTrEsGovT03uR5vYutsJ2XDLpFL5MOoXtuHwXWLxEtuOylq/+6b/iFebxefl5fF1HzrG35wwvS252koEvf0VH53E6j7zLRpLdp5h4cJuxoX52tu6lua2LZbbjUqmZyWHGhvpBhGT3KdaSHejDy+dYz8O7V3nnT/8Lvsv/+j/oOnKOtXj5HNmBPs5++HO2ynZcMukUtuPyXWHxiorWx/HyOXyFQg5fNBZnK6KxOF4+RyadolLR+kYOnHyfoRt/YHz4OpMP7wDKeuI7WtnXc4bRO1e4dTlNR3cvHZ0niMV3sFhYYHbqAWND/XiFBbxCDl+0Pk5DfCe7O4+xY9cerPoG8rknPBq5wdhQP6rKvp4zxHe0shYvn8N30v6YREsSXyadYiVVpc6qx6dLS6xmOy6+2alRblz6DV4+R7XYjst3icUrSJeW0KVFFr08urTEYn4e39RYlrY9h5FIhM3o6b1Itv8zvMI8laiPxTnYe5Hm9i6a27t4eO9bHmSvsvTMYyOdh99FJMLIncuM3etn7F4/6ykszFFYmGN2apQiInQefpd9h85SjkRLkkw6he24bEYmncJ2XLYik07xXWfxivHyOW5f/WeQCD6vkKNQmMenS8+4funXHDn9Q6KxOJVqbu/i7A/+mq2IROrY13OG3Z3HGL9/jaezE2xk36GztHR0M3avn9mpUbz8PFa0nviONhItHexK9tAQ34lvITfL47Esc9Pj5J5MsugViMYa2dm6j+SBU8QTrVTCdlw2y3Zctsp2XMqVSad4E1m8QuZmxhm8+im7u05QWJjj0fANvMICXj6H79BbP+DR6C0GvvwVh09/RKK5g5clWt9I5+F3KVc80UrPqQ/YSGNTC42H3qGmcrbjspLtuKxkOy4r2Y7Li2Cxjkw6he24LMukU9iOy7JMOoXtuFSLLi1RWHjKyO1LLHuQvcrTmUdE6iyu/PZvWKZLS9SUZjsuq9mOy0q247LMdlyW2Y7LarbjUqloLI6Xz5FJp6hEtL6RSj15/JDrX/2arThx/ifs2LWX7WCxhkw6hS+TTmE7Lpl0Cl8mncJ2XDLpFL5MOkW17Ni1B9tx8XmFea59+f94PH4X3/5jNnsOvE3N66Gn9yLZ/s/wCvOUqz4W52DvRSo1MniZrRoZvMKJ83vZDhbrsB2XTDpFJp3CZzsumXSKTDqFz3ZcMukU2yFa38ipC3/Jk+mH1NfHie9so+b10dzexdkf/DUvwonzP+FVZrGK7bisZDsuK9mOy0q247Jd6qwoLe37qampqampqampqampqampqampqXkFiT7HNpLnWEWfYxvJc6yiz7GN5DlW0efYRvIcq+hzbCN5jpqKWJQwMzFMdqAPL5+jXNFYnJ7eizS3d1ENC7lZhm99xezUCL6drZ10HT1PQ3wn1TY1lmX0zhUWcjM0xJvZd+gsrcke3nSFfI5otAGJRKjZPhFKyA704eVzVMLL58gO9FENC09nGPjDL3k8fpdnix7PFj0ej99l4A+/ZOHpDNX0eOwug1c/ZX7uMbq0xPzcYwavfsrUWJY32fj9a3z7u7/j5uV/YHZqlJrtY1GCl8/hO2l/TKIlyUbmpse4lvkEL5+jGoZvX+LZYoHmti56Tl3El+3vY2ZymOHblzhy5odUy8idy/i6jpwj2d3L2NAAw7cvMXrnCq3JHt5EE6O3uHf9C3yzU6M8nZ3g5Hv/nsamFmqqz2IdiZYkmXSKlWzHJZNOsZLtuFTT7NQIvp5TF4nG4vh6Tl3kym//hpnJEappITeDb8+Bt5FIhGR3L8O3L7GQm+FNNDczzt1rn+PrOfUBM5PDTD3McuvKP9L73k+xojFqqsuiDLbj4sukUyyzHRdfJp1iKwoLc2QHPmduepxESwc9vd+nJBGWFRbmyA58ztz0OImWDnp6v099Q4LNaIg3Mz/3mIf3viHZ3cvY0AC+hngz1TAzMUx2oA8vn6MaorE4Pb0XaW7volLzT6e5deUf0aUl9hx4m/Z9R2lN9pDPPeHp7ASDVz/l2Lt/hkiEmuqJ8JJl+/uYnRxh6ZnH7OQId779jJ2tnfiyA314hXkKC0/J9n+Gr7mtk2x/H7OTIyw985idHOHOt5+xWfsOncU3fPsSl/75vzF8+xK+fT1nqYbsQB9ePke1ePkc2YE+KpXPzXLjq79nsbBAy+5uuo6exxepszhy5kc0NDXzdHaCfO4JNdVl8ZLNzTzCd+L8x1z/6hPmZsZ468JfMTs1yszEMFf+9X+yrM6qp+vIOfr/8Et8J85/zPWvPmFuZozNak32wNsweucyC7lZGuI72XfoHVr39FANXj6Hz3ZcqiGTTuHlc1SisPCU65d+g1eYp7mtk8OnP0JEWFbf0MSpC3/JnW/+lWeLBWqqy+IlSzTvZnZqlOtffYIv0ZykoamZ3vd+yvDtS8xOjeDb2dpJ15FzNDQ1k2jezezUKNe/+gRfojnJVrTu6aF1Tw9voqVni9y8/A8UFubYsWsvR878iEikjtUikTqOnPkhvkw6he241FSHxUvWc+oi2f4+5mbGSTR30HPqIr6GpmaOnPkhpfScuki2v4+5mXESzR30nLpIpXRpifu3vmTywSCLXp6VrGiMtr2H2X/0PSQS4XU2fPsS83OPaWxq4ejZHzGa/Zq2vYdpbGqh5sWweMnqGxIcP/djlunSEkM3fs/kg0EWvTwrWdEYbXsPs//oexw/92O24v6tDGNDA5Sy6OUZGxogErHoOnqe11VhYY7x4WuIRDj01g+YfHCb2alR9h06SymZdIplmXQKn+241GyNxUs2MzFMdqAPkQhnPvgZ929lGBsaoJRFL8/Y0AALT2fY1XGQ4dtfIZE6enov0tzeRSUmH9zGd9L+mERLkpXmpse4d/0LGpqaeZ2N37+GLi3RvvcI9Q1NjPzxCr3f+ymRSB2l2I6LL5NOYTsuNdVh8ZJlB/rw8jnqGxL4Jh/cxnfS/phES5KV5qbHuJb5hKezExx7988ZzX5NYWGO7EAfZz/8OZVY9PL4Ei1JVku0JDn1vb8AEaotk06xzHZcMukU5bAdl0pNTwzja9t3lEejN9mVPEiscQc1L5ZFGTLpFKtl0imqwcvn8J354Gf4Fr08vkRLktUSLUl8i14e35kPfkYmncLL56i2Qv4pD7JXmZ4YxivkiNbHaWnvYm/PaeobEmyF7bhk0il8tuOyXRaezuDb0ZLk4d2rdHT3Ug7bcVnIzTD96D6ROouOrhPUbJ7FBmzHZTXbcXmTzUwOM3j1U54teiwrLMwxPnydyYeDHD79Ec1tXWxWJp1iWSadYi2247JZS888VJeos6JIJMKilyda30i5FnKz3L/5Ja3JHjq6TlCzeRYbyKRTbMR2XF43VjTGopdnbnqMREuSZfn5OQavfsqzRY/WZA/7Dp2lId7MQm6G0TtXmBrLMnj1U05d+CtijQkqZTsuK9mOy3aI1EWJ1EV5tujhFRZoTOyiMD9H0852yrHwdAZftL6Rmq2x2IDtuLyJ2vYeYWyon2uZT/DZjovvwd2vebbosSt5kMOnP8KXSaewHZfDpz+CqzA1luXh3ascOPk+r7Idu5LMTAwz+eA2B06+T0QilGvq4R188Z1t1GyNxTrmpsdItCTZyNz0GK+b/UdtQBkfvo4uLbFsZmIYX+ehd/Bl0il8mXQK23HZd+gsU2NZpieGOcDGorE4Xj5HJp2iWqL1jZSjY/9JZiaGeZD9mpbd+/nm87/Ddlw2Mnavn6ezE0RjcVqTB6nZGosSorE4Xj7HtcwnVCJa38jrQiIRuo9fYGxogJW8wjy+hngzK9mOi68h3ozPK+QoR0/vRbL9n+EV5qmG+licg70XKUdL+352JQ/yeOwu17/6e06c/5j1qC7xIHuVkcE/4jt48n0idVFqtsaihJ7ei2T7f4tXWKBc0Vicnt6LVCoai+Plc3z92d9y5oOfYUVjLHp55qbHSLQkWWluegyfFY3h+/qzv8UXrW+kWqL1jRQWnrKQm6ExsQvbccmkU2TSKWzHZSE3gy9aH6ccze1dnP3BX/OyHDr1IbcWPWYnR7h+6dfs2t1N294jJFo6iNY3orpEPveE2akRxu9fZ/7pNL7uExdo2d1NzdZZlNDU3E401oRXWKC+IcGJ8z8h1riD1bzCAjcv/Ybc3BQN8Z3s2JWkUj29F7l77XPqrCi+tr1HGBvq51rmExItSU7aH+O7lvmEuekxfLs7j+GLROqoj8U52HuRamlu7+LR8A1G7lzmyOkfkkmnWGn0zhV8ze2dvA4idRbH3nEYGbzM2L1veTx+j8fj9/g3IqDKSrHGBAdOvk9zWxc11WFRwuDVT8k9mSTWuIMT539CfUOCUqL1DRw//xNuXPoNTx4/ZPCbf+HoWYdKNLd3ceaD/8yy/UdtQJl8MMhqVjRG297DdB4+h+/t7/9Hqm3vwTNMPbzD47G7DH7zKW+9/x9oiO9kITfL4DefMjWWpc6KsvfgGV4XIhG6jpwj2X2KidGbzEyMMD83xaKXRyIRovVxEi0d7Oo4wK6OA4hEqKkeixIamnaxtLTE4bf/lPqGJtZjRWMcP/dj7nzzL0Tr42yVRCJ0H79A9/ELrHTS/pjtkGhJslKsMcHh0x8xePVTph5mmXqYZaU6K8rh0x8Ra0zwuonWN7D34Gn2HjzNv1EFEWq2l0UJB05coBJWNMaxd/+c19FJ+2NWa27r4q0/+StGs1eZmbiPV5gnWt9Ic/t+9vWcpr4hwRtBhJrt9/8BQeBTuXPy6i0AAAAASUVORK5CYII='
decode_img(src,'myImg')保存后的图片如下:

实操:了解base64对图片的加密过程。
python
import base64
# 以下是扩展知识,了解base64的加密过程
def encode_img(img):
img_type = img.split('.')[-1]
with open(img,'rb') as f:
data = f.read()
# 将图片数据进行加密
encode_data = base64.urlsafe_b64encode(data).decode()
# 拼接图片
src = f'data:image/{img_type};base64,{encode_data}'
# 将拼接后的数据打印
print(src)
if __name__ == '__main__':
encode_img('myImg.png')运行结果如下:

4、滑动验证码
4.1、破解思路
滑动验证码也是反爬常见的一种
-
通过selenium滑动到指定位置
-
获取验证码
- 方式:抓包、截图
-
解析验证码图
- 获取滑动的距离
- 执做行为轨迹
-
移动并验证
-
-
通过抓包,看看滑动产生了什么参数,可直接构造参数,发送即可 (难度高)
4.2、获取图片
概述:起初是准备一次性获取大背景图和小图然后利用模板匹配计算出距离,但是目标网站貌似不太适合这一解决办法(小图需要截取),所以本章节只获取大背景图,后期利用opencv解决距离问题。
python
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait # 等待类
from selenium.webdriver.support import expected_conditions as ec # 等待条件类
from time import sleep
import re
def get_img_url():
# 创建驱动并启动浏览器(msedgedriver.exe是edge的驱动,在selenium学习记录中有讲)
edge = webdriver.Edge(service=Service('msedgedriver.exe'))
# 发送请求
edge.get('https://accounts.douban.com/passport/login_popup?login_source=anony')
# 设置全屏显示
edge.maximize_window()
# 设置全局等待,最多等待10s
edge.implicitly_wait(10)
# 切换到账号密码登录
edge.find_element(By.CLASS_NAME,value='account-tab-account').click()
# 找到账号&密码输入框输入任意账号密码
edge.find_element(By.ID,value='username').send_keys('16352897452')
sleep(0.6)
edge.find_element(By.ID,value='password').send_keys('2347jigh')
sleep(0.5)
# 点击登录按钮
edge.find_element(By.CLASS_NAME,value='account-form-field-submit ').click()
sleep(4)
# 切换层级
edge.switch_to.frame('tcaptcha_iframe_dy')
# 创建等待对象
wait = WebDriverWait(edge,300)
# 设置等待事件(直到指定元素加载完成)
wait.until(ec.presence_of_element_located((By.ID,'slideBg')))
# 获取图片url
big_img_div = edge.find_element(By.ID,value='slideBg')
big_img_about = big_img_div.get_attribute('style')
big_img_url = re.search('url\("(.+)"\);',big_img_about).group(1)
save_img(big_img_url,'scralBig.png')
# 关闭浏览器
edge.quit()
import requests
from fake_useragent import UserAgent
def save_img(img_url,img_name='scralImg.png'):
header = {'User-Agent':UserAgent().edge}
resp = requests.get(img_url,headers=header)
with open(f'./img/{img_name}','wb') as f:
f.write(resp.content)
if __name__ == '__main__':
get_img_url()获取到的图片如下:

4.3、标记大背景图的轮廓
思路:
-
为了更快精准的找出滑动的距离,因此可以给图片做适当的处理
- 灰度化。所谓灰度,就是图像没有色彩。举个例子,原本的彩色图片是有RGB三种颜色组成的(也就是每个像素点由三个值),现在给图像灰度化,每个像素点只有一个值(0-255)表示颜色的深度
需要提前在Pycharm等开发工具中安装opencv:
python
pip install opencv-python运行结果如下:

程序如下:
python
def get_position(imgSrc):
# 读取指定图片
img = cv2.imread(imgSrc)
# 对图像应用5x5的高斯模糊,减少噪点和细节,使边缘检测更有效
blurred = cv2.GaussianBlur(img,(5,5),0,0)
# 使用Canny边缘检测算法在模糊后的图像中找到边缘
canny = cv2.Canny(blurred,0,100)
# 查找边缘检测后的图像中的轮廓,contours是一个列表,其中每个元素都是一个轮廓的点集,hierarchy是一个数组,用于表示轮廓之间的层级关系
contours,hierarchy = cv2.findContours(canny,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
# 遍历获取的轮廓
for contour in contours:
# 该函数用于计算给定轮廓的最小外接矩形,x表示矩形左上角的x坐标,y表示矩形左上角的y坐标,w表示矩形的宽度,h表示矩形的高度
x,y,w,h = cv2.boundingRect(contour)
# 计算每个轮廓的面积
area = cv2.contourArea(contour)
# 计算每个轮廓的周长
c = cv2.arcLength(contour,True)
# 这里我提前用ps了解到大背景图的凹槽大致是一个80*80的正方形,然后为防误差对长度做了+5-5的操作得到大致的面积和周长
if 5625 < area < 7225 and 300 < c < 340:
# 再次获取给定轮廓的最小外接矩形(主要是拿x,方便后面打印)
x,y,w,h = cv2.boundingRect(contour)
# 在图像上绘制一个红色的矩形框,表示轮廓的位置
cv2.rectangle(img,(x,y),(x+w,y+h),(0,0,255),2)
# 将标记了矩形框的图像保存
cv2.imwrite('./img/ciclePos.png',img)
# 返回矩形左上角的x坐标,方便了解矩形左上角距离图片最左侧的距离
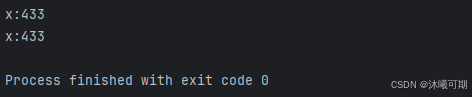
print(f"x:{x}")运行结果如下:
保存的ciclePos.png图像如下:

4.4、获取距离并滑动滚动条
概述:在前面的章节中已经获取了大背景图片及其凹槽最小矩形的左上角x轴的坐标,下面我们要获取滑动的距离,但因为网站上的图片与我们下载的图片尺寸不一样,所以要做对应的缩放处理,最后,利用selenium滑动对应的距离即可。
以下是整合过的代码:
python
import cv2
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait # 等待类
from selenium.webdriver.support import expected_conditions as ec # 等待条件类
from time import sleep
import re
def get_img_url():
# 创建驱动并启动浏览器(msedgedriver.exe是edge的驱动,在selenium学习记录中有讲)
edge = webdriver.Edge(service=Service('msedgedriver.exe'))
# 发送请求
edge.get('https://accounts.douban.com/passport/login_popup?login_source=anony')
# 设置全屏显示
edge.maximize_window()
# 设置全局等待,最多等待10s
edge.implicitly_wait(10)
# 切换到账号密码登录
edge.find_element(By.CLASS_NAME,value='account-tab-account').click()
# 找到账号&密码输入框输入任意账号密码
edge.find_element(By.ID,value='username').send_keys('16352897452')
sleep(0.6)
edge.find_element(By.ID,value='password').send_keys('2347jigh')
sleep(0.5)
# 点击登录按钮
edge.find_element(By.CLASS_NAME,value='account-form-field-submit ').click()
sleep(4)
# 切换层级
edge.switch_to.frame('tcaptcha_iframe_dy')
# 创建等待对象
wait = WebDriverWait(edge,300)
# 设置等待事件(直到指定元素加载完成)
wait.until(ec.presence_of_element_located((By.ID,'slideBg')))
# 获取图片url
big_img_div = edge.find_element(By.ID,value='slideBg')
big_img_about = big_img_div.get_attribute('style')
big_img_url = re.search('url\("(.+)"\);',big_img_about).group(1)
# 将大背景图保存
img_name = save_img(big_img_url,'scralBig.png')
# 获取大背景图凹槽中最小框图的左上角x的坐标
dis = get_position(f'./img/{img_name}')
# 获取实际移动距离并滑动滚动条
sliding_scroll_bar(edge,int(dis))
sleep(10)
# 关闭浏览器
edge.quit()
import requests
from fake_useragent import UserAgent
def save_img(img_url,img_name='scralImg.png'):
"""
对获取的大背景图进行保存
"""
header = {'User-Agent':UserAgent().edge}
resp = requests.get(img_url,headers=header)
with open(f'./img/{img_name}','wb') as f:
f.write(resp.content)
# 将图片最终保存的名字返回
return img_name
def get_position(imgSrc):
"""
主要用于获取大背景图的轮廓并返回轮廓左上角x的坐标
"""
# 读取指定图片
img = cv2.imread(imgSrc)
# 对图像应用5x5的高斯模糊,减少噪点和细节,使边缘检测更有效
blurred = cv2.GaussianBlur(img,(5,5),0,0)
# 使用Canny边缘检测算法在模糊后的图像中找到边缘
canny = cv2.Canny(blurred,0,100)
# 查找边缘检测后的图像中的轮廓,contours是一个列表,其中每个元素都是一个轮廓的点集,hierarchy是一个数组,用于表示轮廓之间的层级关系
contours,hierarchy = cv2.findContours(canny,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
# 遍历获取的轮廓
for contour in contours:
# 该函数用于计算给定轮廓的最小外接矩形,x表示矩形左上角的x坐标,y表示矩形左上角的y坐标,w表示矩形的宽度,h表示矩形的高度
x,y,w,h = cv2.boundingRect(contour)
# 计算每个轮廓的面积
area = cv2.contourArea(contour)
# 计算每个轮廓的周长
c = cv2.arcLength(contour,True)
# 这里我提前用ps了解到大背景图的凹槽大致是一个80*80的正方形,然后为防误差对长度做了+5-5的操作得到大致的面积和周长
if 5625 < area < 7225 and 300 < c < 340:
# 再次获取给定轮廓的最小外接矩形(主要是拿x,方便后面打印)
x,y,w,h = cv2.boundingRect(contour)
# 在图像上绘制一个红色的矩形框,表示轮廓的位置
cv2.rectangle(img,(x,y),(x+w,y+h),(0,0,255),2)
# 将标记了矩形框的图像保存
cv2.imwrite('./img/ciclePos.png',img)
print(f"x:{x}")
# 将矩形左上角的x坐标返回,方便了解矩形左上角距离图片最左侧的距离
return x
# 引入动作类
from selenium.webdriver.common.action_chains import ActionChains
import random
def sliding_scroll_bar(edge,dis):
smallImg = edge.find_element(By.CSS_SELECTOR,'#tcOperation > div.tc-fg-item.tc-slider-normal')
# 网站图片的大小是278x198.56,但下载的图片通过ps可知是672x390,因此要对前面获取的距离进行缩放再减去小滑块已经移动的距离
distance = (dis*(278/672)-smallImg.location['x'])
print(f"distance:{distance}")
edge.implicitly_wait(1000)
# 鼠标按住滑动条
ActionChains(edge).click_and_hold(smallImg).perform()
move = 0
while move<distance:
# 实现每次滑动的距离基本不一样
x = random.randint(2,8)
# 对滑动的距离做记录
move += x
# 移动滑动条
ActionChains(edge).move_by_offset(xoffset=x,yoffset=0).perform()
# 抬起鼠标
ActionChains(edge).release().perform()
if __name__ == '__main__':
get_img_url()运行结果如下:

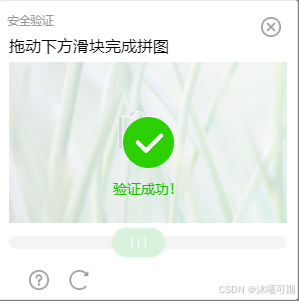
验证结果如下:
5、解决浏览器无限debug
方案一:通过F12检查时会自动跳转到debug的js代码位置,直接对其设置一律不在此处暂停并放行即可。
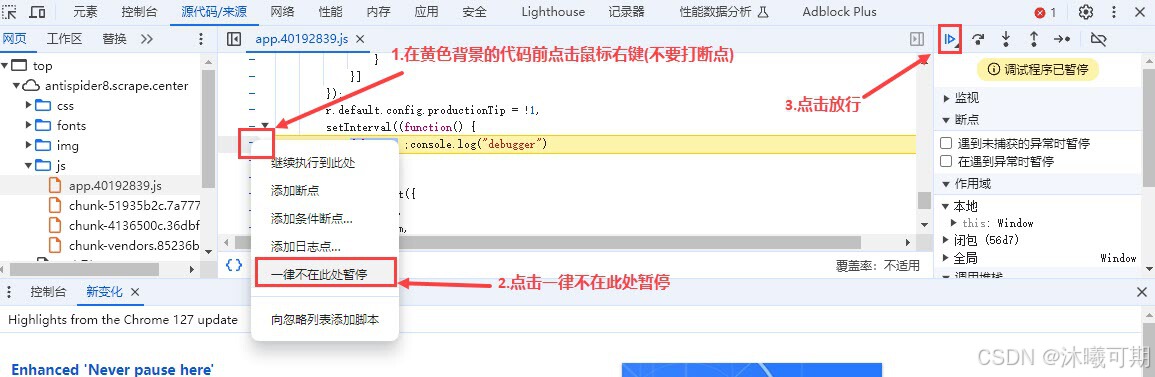
方案二:通过方案一的方法 "解决了无限debug的问题" 后,我们会发现无法加载其它数据了,即使是刷新网页(这可能就是网站对debug做了内存的数据注入,让浏览器内存溢出,进而无法加载数据),此时需要重启浏览器,然后按下图所示步骤解决:
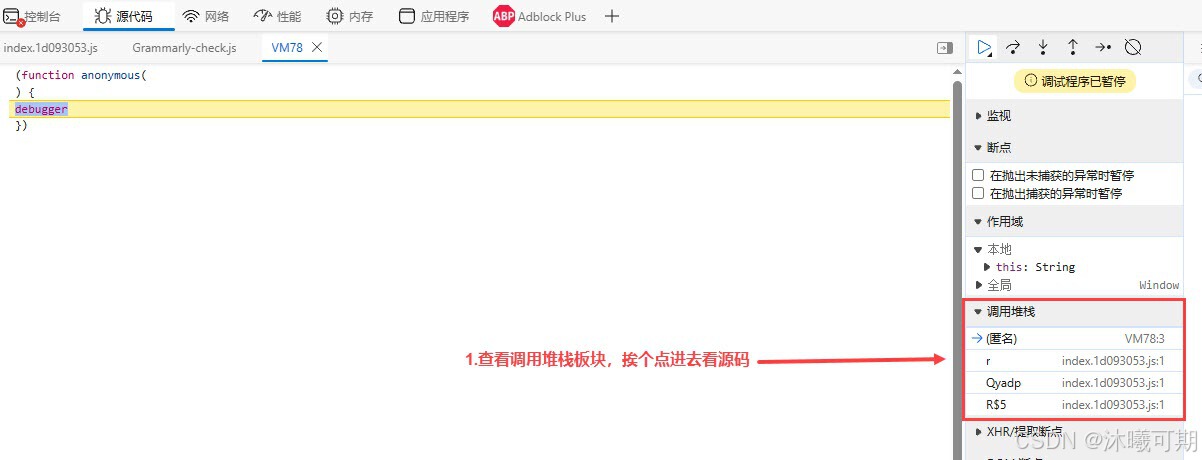
看不懂没关系,我们可以拿到控制台去运行(不难发现代码已经做了混淆):
javascript
[h("*Wzf", 1448, 1437, 0, 1175) + W(139, 78, 321, "m*]b") + "r"](n[W(-241, -125, 34, "d%Rh")](n[W(-186, -192, -148, "g@X$")], n[v(981, 940, 828, 0, "@INp")]))[v(546, 583, 677, 0, "bpfh")](n[v(1094, 998, 1189, 0, "d%Rh")])运行结果如下:

拼接后的结果如下:(大概率第一个就是导致内存溢出的的罪魁祸首)
javascript
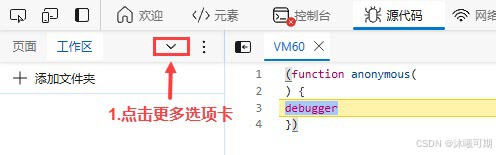
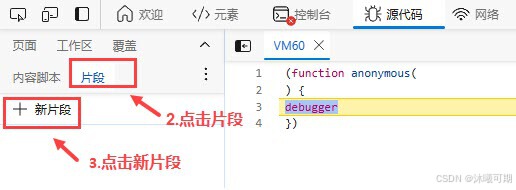
[constructor](debugger)[call](action)解决办法就是按照下图步骤实现本地注入:
javascript
// 重写Functiong构造函数
func_a = Function.prototype.constructor;
Function.prototype.constructor = function (params) {
if (params == "debugger"){
return function () {}
}
return func_a(params)
}
// 写完以上程序后按Ctrl+Enter,如果有运行结果将debug放行即可遗憾的是目前遇到的一个测试网站也想到了这一点,将Function函数设置成了静态方法,导致无法重写Function,因此目前个人没有解决办法,但可能。