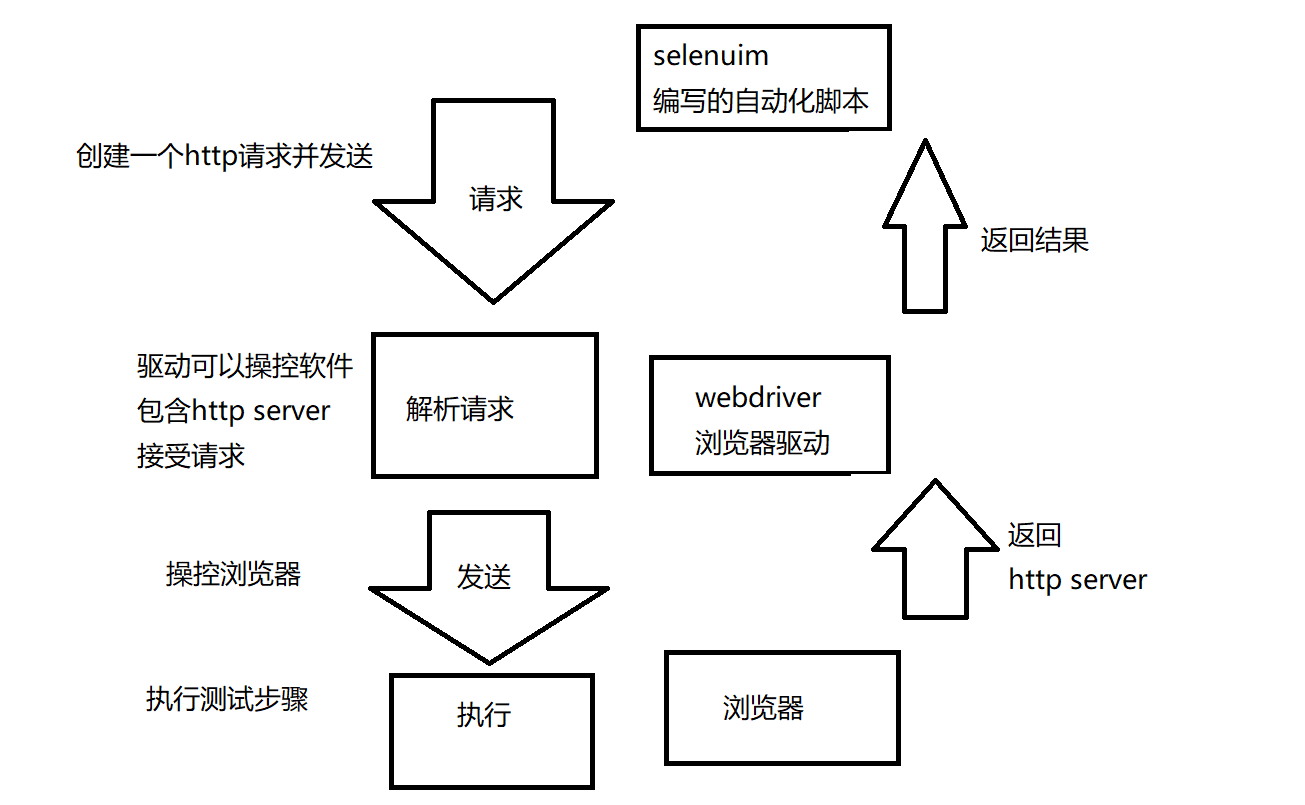
1自动化脚本的实现示意图
selenium实现的自动化脚本和webdriver和浏览器的关系
selenium:提供方法编写脚本
webdriver:驱动软件
浏览器:访问web
2 元素的定位
web⾃动化测试的操作核⼼是找到⻚⾯对应的元素,然后对元素进⾏操作。
常⻅的元素定位⽅式⾮常多,如id,classname,tagname,xpath,cssSelector
常用的是cssSelector和xpath
2.1find_element
find_element(方式,"元素名")
find_elements(方式,"元素名")
2.2cssSelector
选中⻚⾯中指定的标签元素
选择器的种类分为基础选择器和复合选择器
常⻅的元素定位⽅式:通过id选择器和⼦类选择器
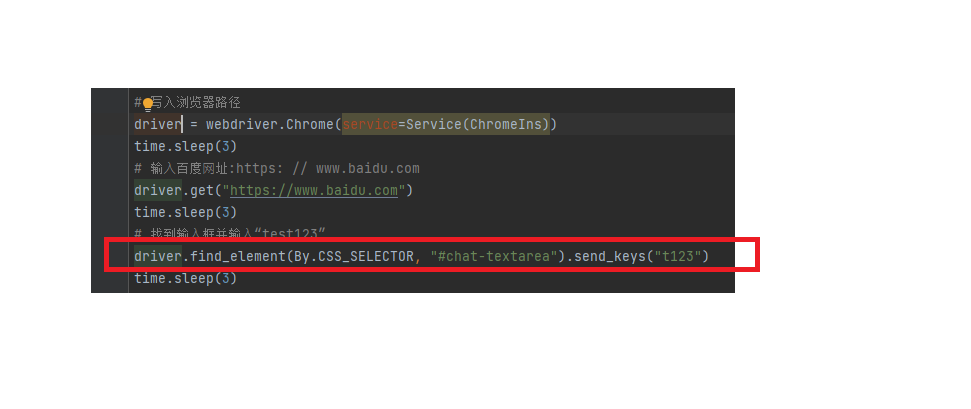
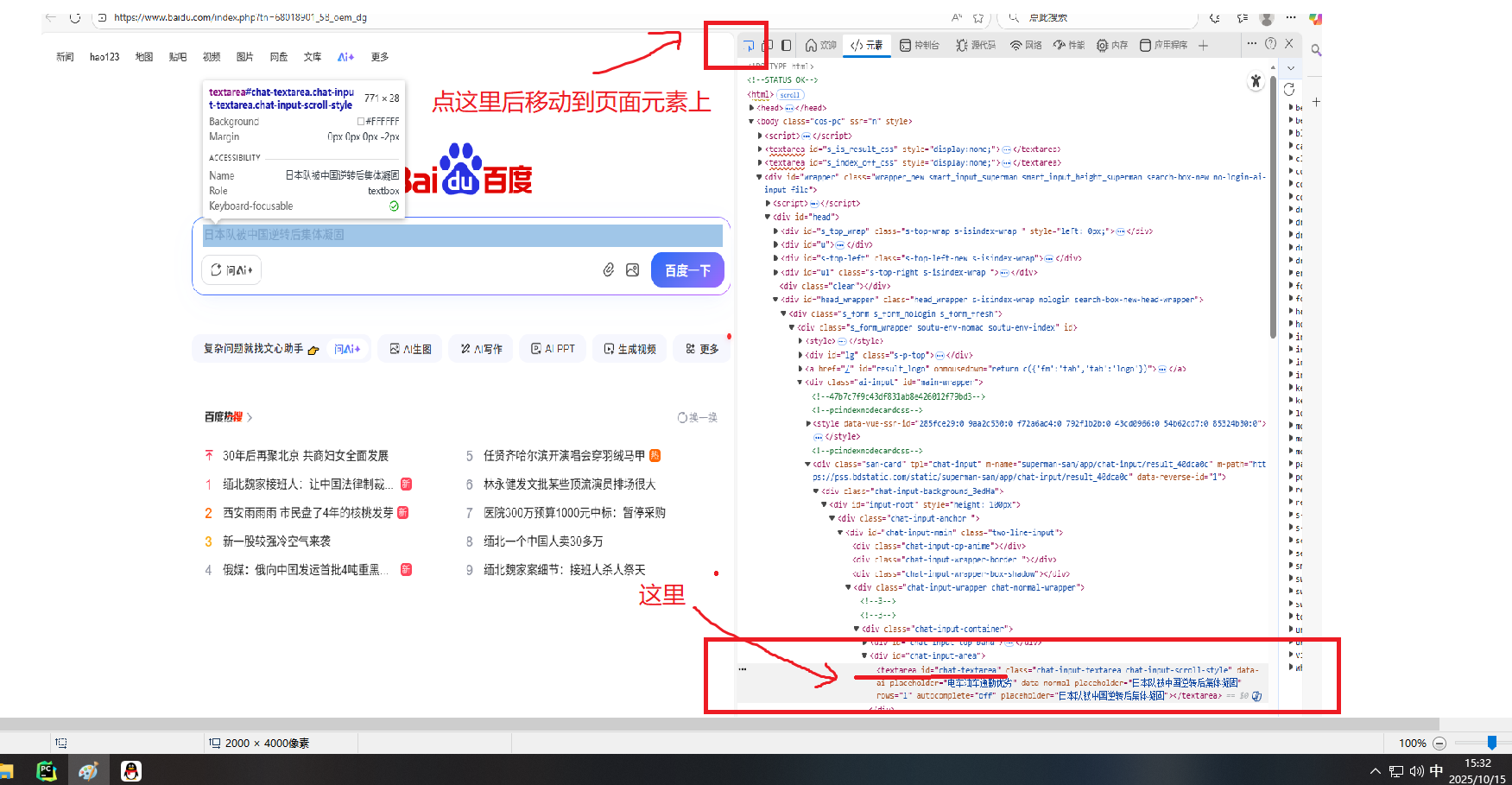
举例:定位百度⾸⻚的搜索框
2.3 xpath
XML路径语⾔,可以在XML⽂件中查找信息,HTML中选取节点。
xpath⽤路径表达式来选择xml⽂档中的节点
2.3.1 获取HTML⻚⾯所有的节点
//*
2.3.2 获取HTML⻚⾯指定的节点
// 指定节点
//ul:获取HTML⻚⾯所有的ul节点
//input:获取HTML⻚⾯所有的input节点
2.3.3 获取⼀个节点中的直接⼦节点
//span/input
2.3.4 获取⼀个节点的⽗节点
//input/..获取input节点的⽗节点
2.3.5 实现节点属性的匹配
//*@id='chat-textarea'
匹配HTML⻚⾯中id属性为chat-textarea的节点
2.3.6 使⽤指定索引的⽅式获取对应的节点内容
xpath的索引是从1开始的。
例:百度⾸⻚通过://div/ul/li3定位到第三个百度热搜标签
3 操作测试对象
3.1 点击/提交对象
click()

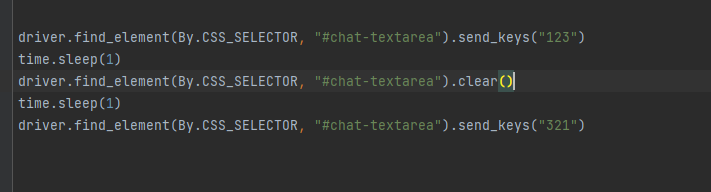
3.2 模拟按键输⼊
send_keys("")

3.3 清除文本内容
换新的关键词
clear()
3.4 获取文本信息
获取元素对应的⽂本
text

3.5 获取当前页面标题
title

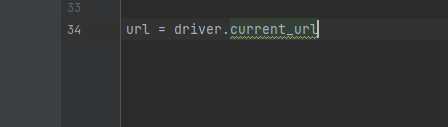
3.6 获取当前页面URL
current_url
4. 窗⼝
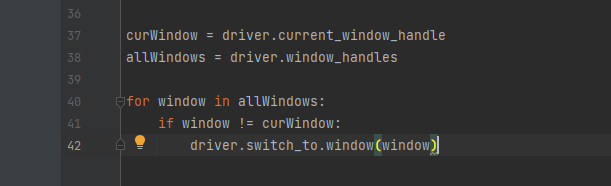
4.1 切换窗⼝
4.1.1获取当前⻚⾯句柄:
driver.current_window_handle
4.1.2获取所有⻚⾯句柄:
driver.window_handles
4.1.3切换当前句柄为最新⻚⾯:
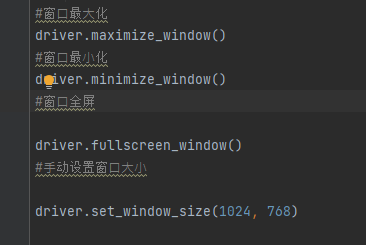
4.2 窗⼝设置大小
4.3 屏幕截图
driver.save_screenshot('../images/image.png')
4.4 关闭窗⼝
driver.close()
5. 弹窗
5.1 警告弹窗和确认弹窗
alert = driver.switchTo.alert
// 确认
alert.accept()
// 取消
alert.dismiss()
5.2 提示弹窗
alert = driver.switchTo.alert
alert.send_keys("hello")
alert.accept()
alert.dismiss()
6. 等待
6.1 强制等待
time.sleep ()
优点:使⽤简单,调试的时候⽐较有效 缺点:影响运⾏效率,浪费⼤量的时间
6.2 隐式等待
智能等待,查找元素时,在指定时间内不断查找元素
隐式等待作⽤域是整个脚本的所有元素。只要driver对象没有被释放掉就⼀直⽣效
driver.implicitly_wait()

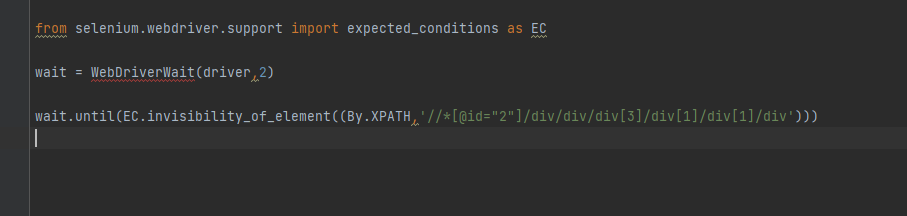
6.3 显⽰等待
也是⼀种智能等待,在指定超时时间范围内只要满⾜操作的条件就会继续执⾏后续代码
可以⾃定义显⽰等待的条件
WebDriverWait(driver,sec).until(functions)
7. 浏览器导航
1)打开⽹站
driver.get("https://baidu.com")
2)浏览器的前进、后退、刷新
driver.back()
driver.forward()
driver.refresh()
8. ⽂件上传
⽂件上传的场景下会弹窗系统窗⼝,进⾏⽂件的选择。
selenium⽆法识别⾮web的控件,上传⽂件窗⼝为系统⾃带,⽆法识别窗⼝元素 但是可以使⽤sendkeys来上传指定路径的⽂件
driver.get("file:///D:/file/%E6%AF%94%E7%89%B9%E6%95%99%E5%8A%A1/%E6%B5%8B%E8%AF%95/selenium4html/selenium-html/upload.html")
ele = driver.find_element(By.CSS_SELECTOR,"body > div > div > input[type=file]")
ele.send_keys("D:\\file\\test.txt")
9. 浏览器参数设置
1)设置⽆头模式
程序在后端运行,不显示窗口
默认为有头模式
options = webdriver.ChromeOptions()
options.add_argument("-headless")
driver=webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),options=options)
2)⻚⾯加载策略
options.page_load_strategy = ' 加载⽅式 '
⻚⾯加载⽅式主要有三种类型:
normal 默认,等待所有资源下载
eager DOM访问已准备就绪,但诸如图像的其他资源可能仍在加载
none 完全不会阻塞WebDriver