一、定义
关联散点图是一种强大的可视化工具,它结合了散点图和线图的特点,以展示数据随时间或其他有序变量的变化趋势。这种图表类型特别适合于分析时间序列数据,因为它能够清晰地展示数据点之间的演变关系,同时也突出了每个单独的观测值。
在关联散点图中,每个数据点都是通过坐标轴上的点来表示的,这些点按照时间或其他有序变量的顺序排列。与简单的散点图不同,关联散点图通过线段将相邻的数据点连接起来,从而形成了一条折线,这条折线可以直观地显示出数据随时间的波动情况。
例如,如果我们使用关联散点图来展示2018年4月比特币价格的演变过程,我们可以从CoinMarketCap网站获取每日的比特币价格数据。这些数据点将按照日期顺序排列在图表上,每个点代表一天的比特币价格。然后,我们将这些点通过线段连接起来,形成一条折线,这样就可以清楚地看到比特币价格在那个月的波动情况。
通过观察关联散点图,我们可以识别出比特币价格的高峰和低谷,以及价格变化的趋势。例如,如果折线在某个时间段内持续上升,这可能表明市场对比特币的需求增加,导致价格上涨。相反,如果折线在某个时间段内持续下降,则可能表明市场对比特币的需求减少,或者其他因素导致价格下跌。
此外,关联散点图还可以帮助我们识别数据中的异常值或异常波动。如果某个数据点远离其他点,或者与其他点的连接线出现明显的弯曲,这可能意味着那一天的比特币价格受到了某些特殊因素的影响,如重大新闻事件或市场情绪的变化。
二、代码演示
以下示例展示了2018年4月比特币价格的演变过程。
R
# 清除变量
rm(list = ls())
# 加载所需的库
library(tidyverse)
library(hrbrthemes)
library(plotly)
library(patchwork)
library(babynames)
library(viridis)
# 设置文件路径
file_path <- "/Users/luoxiaoluotongxue/Desktop/硕士课题进展记录/科研绘图/每日科研绘图/24-08/24-08-22/24-08-22.csv"
# 使用read.table()函数读取CSV文件
# 注意:header=TRUE表示第一行是列名,sep=","表示数据分隔符是逗号
data <- read.table(file_path, header = TRUE, sep = ",", fileEncoding = "UTF-8")
# 将'date'列转换为日期格式
data$date <- as.Date(data$date)
# 绘制图表
data %>%
tail(10) %>% # 只取最后10条数据
ggplot( aes(x=date, y=value)) + # 设置x轴为日期,y轴为数值
geom_line(color="#69b3a2") + # 添加线条,颜色为#69b3a2
geom_point(color="#69b3a2", size=4) + # 添加点,颜色为#69b3a2,大小为4
ggtitle("Evolution of Bitcoin price") + # 设置图表标题
ylab("bitcoin price ($)") + # 设置y轴标签
theme_minimal() # 使用最小化主题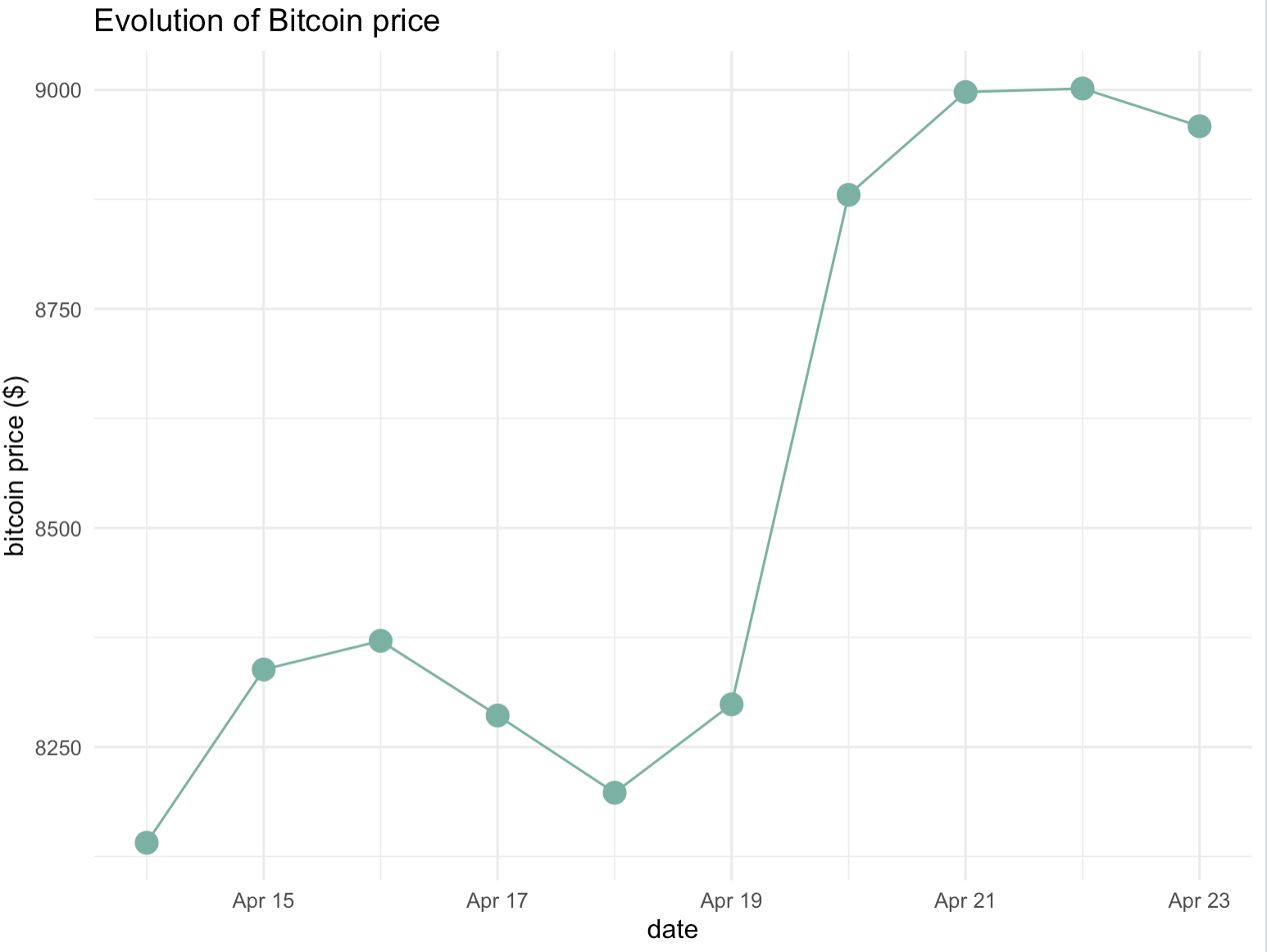
三、用途
关联散点图的用途非常广泛,特别是在需要同时展示数据点的精确位置和它们之间趋势关系的情况下。
以下是一些关联散点图特别适用的场景:
-
时间序列分析:在金融市场分析、气象学、生物医学研究等领域,时间序列数据非常常见。关联散点图能够清晰地展示数据随时间的变化,帮助分析师识别趋势、周期性模式或异常波动。
-
工程和科学研究:在工程领域,如机械应力测试或电子信号分析,关联散点图可以展示实验数据随时间或其他有序变量的变化,同时突出每个测量点的精确值。
-
医疗监测:在医疗领域,关联散点图可以用来追踪病人的生命体征,如心率、血压等,随时间的变化。这有助于医生及时发现病情变化并做出相应的医疗决策。
-
教育和培训:在教育领域,关联散点图可以用来展示学生的成绩随时间的提高或下降,帮助教师了解学生的学习进度和需要额外关注的地方。
-
物流和供应链管理:在物流行业,关联散点图可以用来追踪货物的运输过程,展示货物在不同时间点的位置,帮助管理者优化物流路径和调度。
-
环境监测:环境科学家使用关联散点图来展示污染物浓度、温度、湿度等环境因素随时间的变化,这对于理解环境变化趋势和制定保护措施至关重要。
-
体育数据分析:在体育领域,关联散点图可以用来分析运动员的表现,如跑步速度、投篮命中率等,随比赛进程的变化,帮助教练制定训练计划。
-
软件和网站性能监控:在IT行业,关联散点图可以用来监控服务器的响应时间、网站访问量等指标随时间的变化,及时发现性能瓶颈。
-
经济指标分析:经济学家和分析师使用关联散点图来展示GDP、失业率、通货膨胀率等经济指标随时间的变化,帮助政府和企业制定经济政策和商业策略。
-
用户行为分析:在市场营销和用户体验研究中,关联散点图可以用来展示用户对产品或服务的使用频率、满意度等指标随时间的变化,帮助企业优化产品和提升用户体验。
关联散点图的优势在于它结合了散点图和线形图的特点,既能够展示数据点的精确位置,又能够通过连接线清晰地展示数据的趋势和模式。这种图表类型特别适合于需要深入分析和解释数据变化的场景,提供了一种直观、灵活的数据展示方式。
代码演示
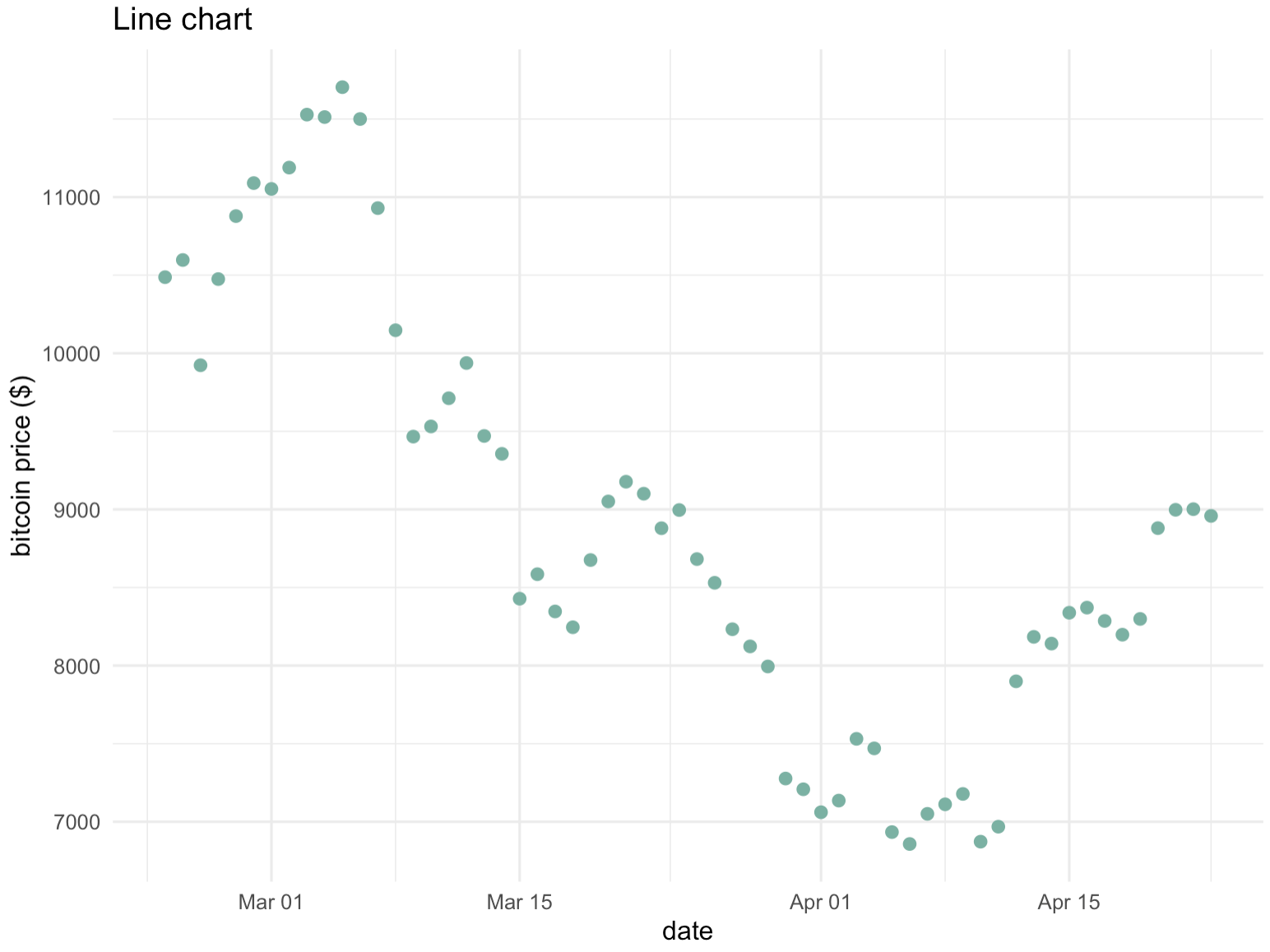
这段代码的目的是创建两个不同的图表,一个是线图,另一个是连接的散点图,它们都显示了比特币价格随时间的变化。每个图表都只显示了数据的最后60条记录。
R
# 创建第一个图表:线图
p1 <- data %>%
tail(60) %>% # 只取最后60条数据
ggplot( aes(x=date, y=value)) + # 设置x轴为日期,y轴为数值
geom_line(color="#69b3a2") + # 添加线条,颜色为#69b3a2
ggtitle("Line chart") + # 设置图表标题
ylab("bitcoin price ($)") + # 设置y轴标签
theme_minimal() # 使用最小化主题
# 创建第二个图表:连接的散点图
p2 <- data %>%
tail(60) %>% # 只取最后60条数据
ggplot( aes(x=date, y=value)) + # 设置x轴为日期,y轴为数值
geom_line(color="#69b3a2") + # 添加线条,颜色为#69b3a2
geom_point(color="#69b3a2", size=2) + # 添加点,颜色为#69b3a2,大小为2
ggtitle("Connected scatterplot") + # 设置图表标题
ylab("bitcoin price ($)") + # 设置y轴标签
theme_ministic() # 使用最小化主题
# 将两个图表组合在一起显示
p1 + p2
当您的X轴是有序的时候,您必须将点连接起来以获得一个关联散点图。确实,如果点没有连接,图案将难以阅读,如下面的图形所示。
R
# 创建图表:散点图
data %>%
tail(60) %>% # 只取最后60条数据
ggplot( aes(x=date, y=value)) + # 设置x轴为日期,y轴为数值
geom_point(color="#69b3a2", size=2) + # 添加点,颜色为#69b3a2,大小为2
ggtitle("Line chart") + # 设置图表标题
ylab("bitcoin price ($)") + # 设置y轴标签
theme_minimal() # 使用最小化主题请注意,这甚至可能导致误导性的结论。
四、变体
关联散点图在展示两个变量随时间变化的演化故事时,提供了一种直观且强大的可视化手段。
假设,我们可以通过关联散点图来深入分析和比较两个名字Amanda和Ashley在不同年份的流行趋势。
常规线形图的局限性
首先,如果我们使用常规的线形图来展示这两个名字的演变,我们可能会得到两条随时间变化的曲线,每条曲线代表一个名字的婴儿数量。
虽然这种图表可以展示出趋势,但它可能无法清晰地传达每个年份的具体数据点,特别是当数据点较多时,曲线可能会变得拥挤,难以区分具体的年份和数据值。
关联散点图的优势
使用关联散点图,我们可以克服这些局限性,并提供更多的信息:
-
数据点的清晰展示:每个年份的数据点都会以散点的形式清晰地展示在图表上,用户可以轻松地看到每个年份的具体数值。
-
时间序列的直观表示:通过将数据点按照年份顺序排列,关联散点图可以直观地展示时间序列,用户可以一目了然地看到数据随时间的演变。
-
趋势线的辅助:尽管关联散点图强调了数据点,但我们仍然可以通过连接这些点来形成趋势线,这样既可以展示每个数据点,又可以观察到整体的趋势。
-
数据比较的便捷性:通过在同一张图表上展示两个名字的数据,我们可以轻松地比较Amanda和Ashley在不同年份的流行程度,以及它们之间的相对变化。
-
模式和异常的识别:关联散点图可以帮助我们识别数据中的模式,例如某些年份两个名字的流行度是否同时上升或下降,以及任何异常的年份,比如某个名字的流行度突然大幅增加或减少。
-
数据的动态变化:关联散点图可以展示数据的动态变化,比如Amanda和Ashley的流行度是否交替领先,或者一个名字是否在某个时间段内持续领先。
实际应用示例
假设我们有从1980年到2020年的数据,我们可以在关联散点图上为Amanda和Ashley各绘制一条趋势线。每个点代表对应年份的婴儿数量,点与点之间通过线段连接。通过这种图表,我们可以观察到:
- Amanda和Ashley在某些年份的流行度是否相近。
- 某个名字是否在特定时间段内特别流行。
- 名字流行度的长期趋势,比如Amanda是否在某个时期开始逐渐被Ashley取代。
通过这种方式,关联散点图不仅讲述了两个名字随时间变化的故事,还提供了丰富的数据洞察,帮助我们更好地理解社会文化趋势和命名习惯的演变。
R
# 加载babynames包
library(babynames)
# 加载数据集并筛选出名为"Ashley"和"Amanda"的女性名字
data <- babynames %>%
filter(name %in% c("Ashley", "Amanda")) %>%
filter(sex=="F")
# 绘制图表
data %>%
ggplot( aes(x=year, y=n, group=name, color=name)) + # 设置x轴为年份,y轴为名字出现的次数,按名字分组并着色
geom_line() + # 添加线条
scale_color_viridis(discrete = TRUE, name="") + # 使用viridis颜色方案,并且不显示颜色条的名称
theme(legend.position="none") + # 不显示图例
ggtitle("Popularity of American names in the previous 30 years") + # 设置图表标题
theme_minimal() # 使用最小化主题