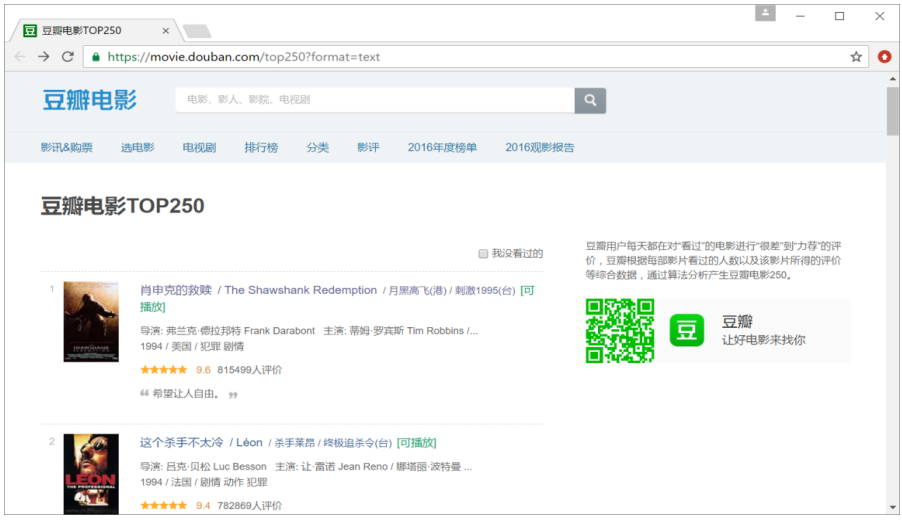
for tag in soup.find_all(attrs={"class":"item"}):
title = tag.find_all(attrs={"class":"title"}) #电影名称
info = tag.find(attrs={"class":"star"}).get_text() #爬取评分和评论数
print(title[0])
print(info.replace('\n',''))
# <span class="title">肖申克的救赎</span>
# 9.72279813人评价
# -*- coding: utf-8 -*-
# By:Eastmount CSDN
import urllib.request
import re
from bs4 import BeautifulSoup
import codecs
#-------------------------------------爬虫函数-------------------------------------
def crawl(url, headers):
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
contents = page.read()
soup = BeautifulSoup(contents, "html.parser")
infofile.write("")
print('爬取豆瓣电影250: \n')
for tag in soup.find_all(attrs={"class":"item"}):
#爬取序号
num = tag.find('em').get_text()
print(num)
infofile.write(num + "\r\n")
#电影名称
name = tag.find_all(attrs={"class":"title"})
zwname = name[0].get_text()
print('[中文名称]', zwname)
infofile.write("[中文名称]" + zwname + "\r\n")
#网页链接
url_movie = tag.find(attrs={"class":"hd"}).a
urls = url_movie.attrs['href']
print('[网页链接]', urls)
infofile.write("[网页链接]" + urls + "\r\n")
#爬取评分和评论数
info = tag.find(attrs={"class":"star"}).get_text()
info = info.replace('\n',' ')
info = info.lstrip()
print('[评分评论]', info)
#获取评语
info = tag.find(attrs={"class":"inq"})
if(info): #避免没有影评调用get_text()报错
content = info.get_text()
print('[影评]', content)
infofile.write(u"[影评]" + content + "\r\n")
print('')
#-------------------------------------主函数-------------------------------------
if __name__ == '__main__':
#存储文件
infofile = codecs.open("Result_Douban.txt", 'a', 'utf-8')
#消息头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
#翻页
i = 0
while i<10:
print('页码', (i+1))
num = i*25 #每次显示25部 URL序号按25增加
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
crawl(url, headers)
infofile.write("\r\n\r\n")
i = i + 1
infofile.close()
运行结果如图7所示,爬取了电影名称、网页连接、评分评论数和影评等信息。
并且将爬取的250部电影信息存储到"Result_Douban.txt"文件中,如下图所示。
在代码中,主函数定义循环依次获取不同页码的URL,然后调用crawl(url)函数对每页的电影信息进行定向爬取。在crawl(url)函数中,通过urlopen()函数访问豆瓣电影网址,然后调用BeautifulSoup函数进行HTML分析,前面第一部分讲解了每部电影都位于< li >< div class="item" >...< /div >< /li >节点下,故采用如下for循环依次定位到每部电影,然后再进行定向爬取。
复制代码
for tag in soup.find_all(attrs={"class":"item"}):
#分别爬取每部电影具体的信息
具体方法如下。
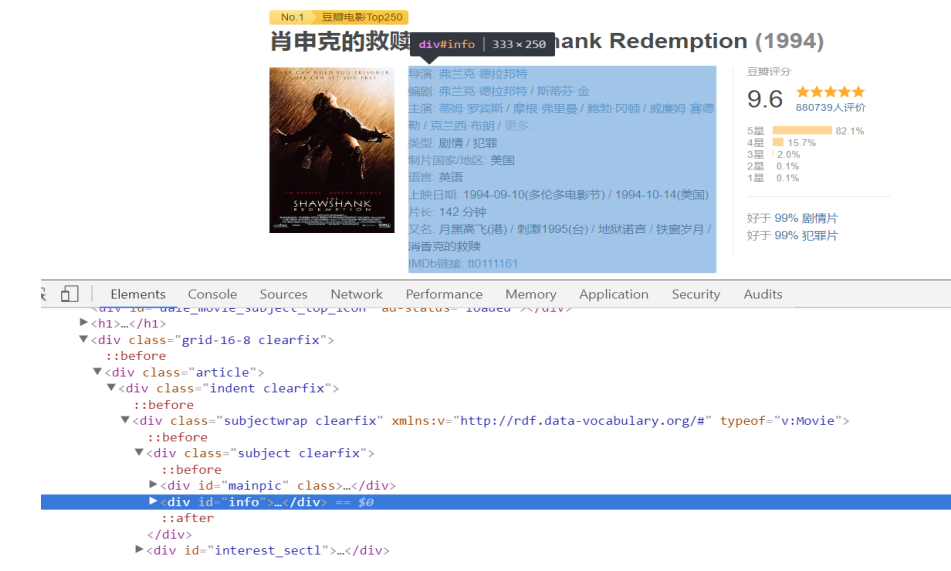
(1) 获取序号
序号对应的HTML源码如图8所示,需要定位到< em class >1< /em >节点,通过find('em')函数获取具体的内容。
#爬取评分和评论数
info = tag.find(attrs={"class":"star"}).get_text()
info = info.replace('\n',' ')
info = info.lstrip()
print(info)
mode = re.compile(r'\d+\.?\d*') #正则表达式获取数字
print(mode.findall(info))
i = 0
for n in mode.findall(info):
if i==0:
print('[分数]', n)
infofile.write("[分数]" + n + "\r\n")
elif i==1:
print('[评论]', n)
infofile.write(u"[评论]" + n + "\r\n")
i = i + 1
下面对详情页面进行DOM树节点分析,其基本信息位于< div class='article' >...< /div >标签下,核心内容位于该节点下的子节点中,即< div id='info' >...< /div >。使用如下代码获取内容:
复制代码
info = soup.find(attrs={"id":"info"})
print(info.get_text())
2.爬取详情页面电影简介
同样,通过浏览器审查元素,可以得到如图14所示的电影简介HTML源码,其电影简介位于< div class='related-info' >...< /div >节点下,它包括简短版(short)的简介和隐藏的详细版简介(all_hidden),这里作者通过下列函数获取。代码replace('\n','').replace(' ','')用于过滤所爬取HTML中多余的空格和换行符号。
复制代码
other = soup.find(attrs={"class":"related-info"}).get_text()
print other.replace('\n','').replace(' ','') #过滤空格和换行
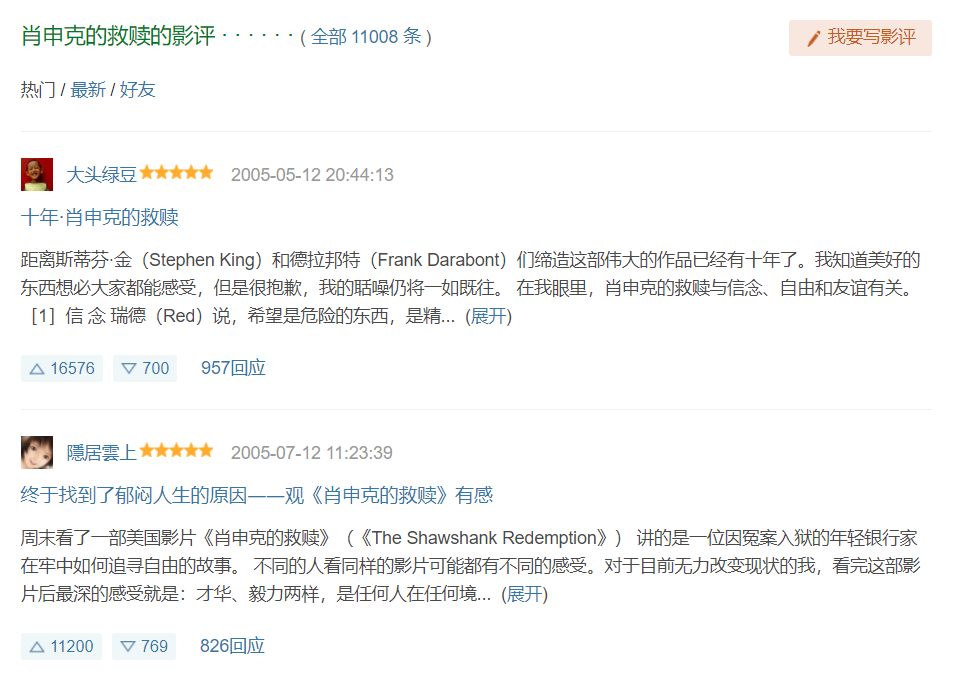
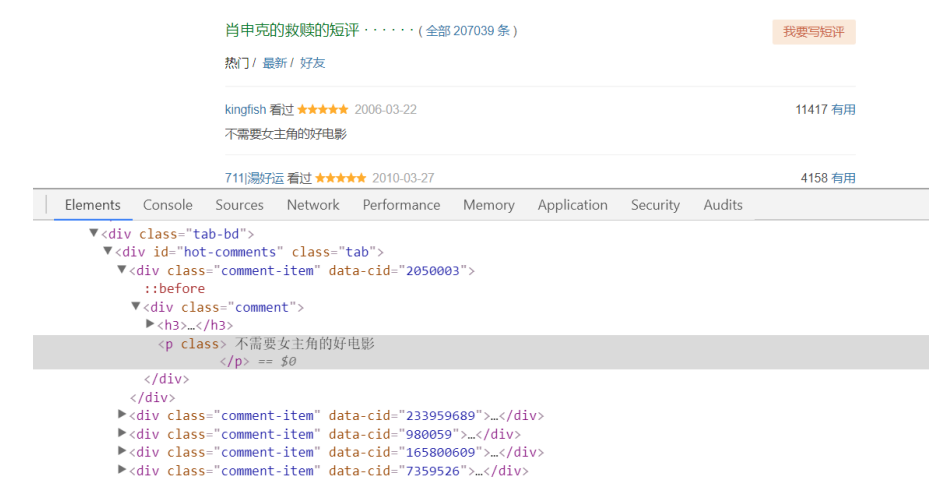
3.爬取详情页面电影热门评论信息
热门评论信息位于< div id='hot-comments' >...< /div >节点下,然后获取节点下的多个class属性为"comment-item"的div布局,如下图所示。在使用find()或find_all()函数进行爬取时,需要注意标签属性是class还是id,或是其它,必须与之对应一致,才能正确爬取。
python复制代码
#评论
print('\n评论信息:')
for tag in soup.find_all(attrs={"id":"hot-comments"}):
for comment in tag.find_all(attrs={"class":"comment-item"}):
com = comment.find("p").get_text() #爬取段落p
print com.replace('\n','').replace(' ','')