往期精选文章推荐:
前言
在前面的文章 《深入理解 go reflect》和 《深入理解 go unsafe》 中都提到内存对齐,由于篇幅原因没有展开详细介绍,后面有同学私聊我想了解一下内存对齐的细节,今天和大家简单聊聊内存对齐。
为什么要内存对齐
下面是维基百科对内存对齐的描述:
现代计算机CPU一般是以32位元或64位元大小作地址对齐,以32位元架构的计算机举例,每次以连续的4字节为一个区间,第一个字节的位址位在每次CPU抓取资料大小的边界上,除此之外,如果要访问的变量没有对齐,可能会触发总线错误。
总的来说,内存对齐有两点好处:
-
方便CPU读写内存(性能更好)
现代计算机体系结构通常以特定的字节边界来访问内存。如果数据的存储地址没有按照合适的边界对齐,可能会导致多次内存访问,降低程序的执行效率。例如,对于一个 32 位的整数,如果存储在非 4 字节对齐的地址上,可能需要两次内存读取操作才能获取完整的数据,而在对齐的地址上,一次读取操作即可。
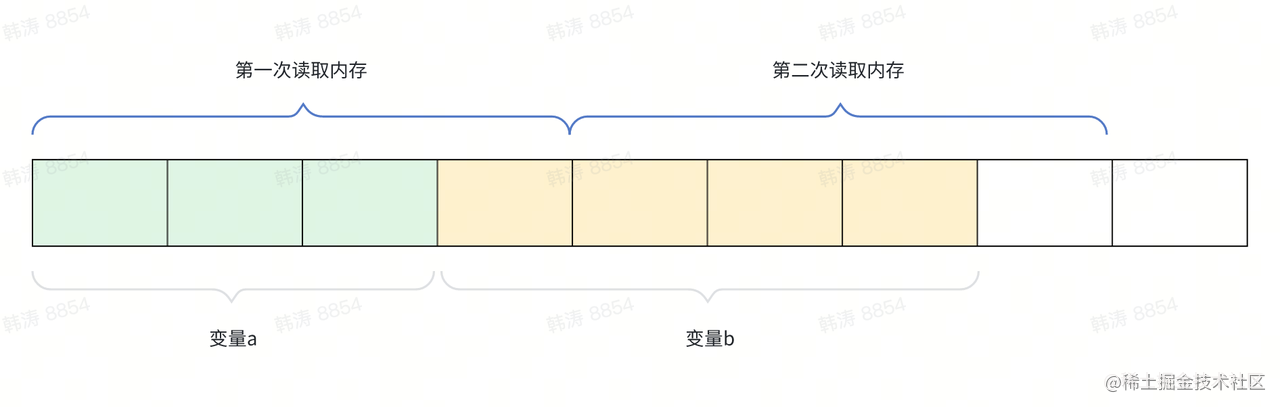
-
平台兼容性
不同的硬件平台和操作系统对内存对齐的要求可能不同。通过遵循合适的内存对齐规则,可以确保程序在不同的环境下都能正确运行,提高程序的可移植性。
内存对齐规则
内存对齐是一种将数据在内存中进行排列的方式,目的是提高内存访问的效率和保证数据的完整性。数据的内存排列方式最直观的体现就是数据的内存地址,说白了就是数据的内存地址要符合一定规则,以便于CPU读取,这个规则就是下面要讲的内存对齐规则。
默认对齐值
在不同的平台上的编译器有自己默认的"对齐值", 可以通过预编指令 #pragmapack(n) 进行变更,n 就是代指"对齐系数"。一般来讲,常用的平台对齐系数是: 32位是 4,64位是 8。
基本类型的对齐
在 Go 语言中,基本数据类型通常按默认对齐值和数据自身大小的最小值进行对齐,也就是说数据的内存地址必须是默认对齐值和数据大小的最小值的整数倍。
使用伪代码表示一下:
go
// 64 位平台,默认对齐值 8
const defaultAlign int = 8
func GetAlign(a any) int {
return min(defaultAlign, sizeOf(a))
}常见的基本类型对齐值:
| 数据类型 | 自身大小 | 32位平台对齐值 | 64位平台对齐值 |
|---|---|---|---|
| int、uint | 4 or 8 | 4 | 8 |
| int32、uint32 | 4 | 4 | 4 |
| int64、uint64 | 8 | 4 | 8 |
| int8、uint8 | 1 | 1 | 1 |
| int16、uint16 | 2 | 2 | 2 |
| float32 | 4 | 4 | 4 |
| float64 | 8 | 4 | 8 |
| bool | 1 | 1 | 1 |
基本类型的对齐示例:
go
package main
import (
"unsafe"
"fmt"
)
func main() {
var a int16 = 1
var b bool = true
var c int = 1
var d bool = true
var e float32 = 3.14
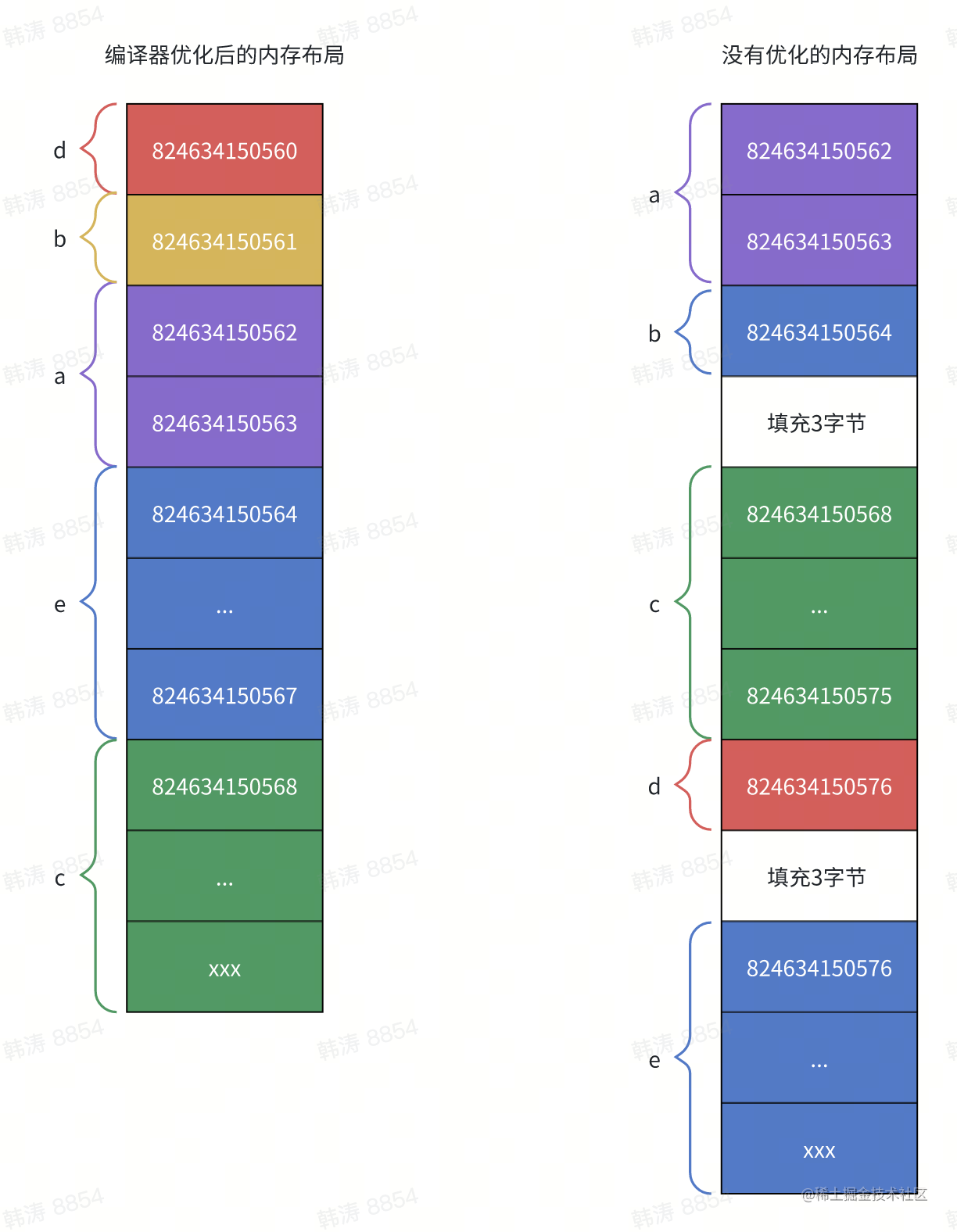
fmt.Printf("a 的对齐值:%d, 地址: %d\n", unsafe.Alignof(a), uintptr(unsafe.Pointer(&a)))
fmt.Printf("b 的对齐值:%d, 地址: %d\n", unsafe.Alignof(b), uintptr(unsafe.Pointer(&b)))
fmt.Printf("c 的对齐值:%d, 地址: %d\n", unsafe.Alignof(c), uintptr(unsafe.Pointer(&c)))
fmt.Printf("d 的对齐值:%d, 地址: %d\n", unsafe.Alignof(d), uintptr(unsafe.Pointer(&d)))
fmt.Printf("e 的对齐值:%d, 地址: %d\n", unsafe.Alignof(e), uintptr(unsafe.Pointer(&e)))
}
$ go run main.go
a 的对齐值:2, 地址: 824634150562
b 的对齐值:1, 地址: 824634150561
c 的对齐值:8, 地址: 824634150568
d 的对齐值:1, 地址: 824634150560
e 的对齐值:4, 地址: 824634150564上面的输出和我们的结论是契合的,内存地址都是对齐值的倍数,另外还有一点,为了减少内存开销,编译器还会优化内存布局,减少内存碎片。
数组的对齐
- 如果数组中的元素是基本类型,那么数组的对齐值通常与元素类型的对齐值相同。例如,如果数组中的元素是int16类型,int16通常是 2 字节对齐,那么这个数组的对齐值也是 2 字节。
go
package main
import (
"unsafe"
"fmt"
)
func main() {
var arr [3]int16 = [3]int16{1,2,3}
fmt.Printf("arr 的对齐值:%d\n", unsafe.Alignof(arr))
fmt.Printf("arr 的大小: %d\n", unsafe.Sizeof(arr))
fmt.Printf("arr 的地址: %d\n", uintptr(unsafe.Pointer(&arr)))
}
$ go run main.go
arr 的对齐值:2
arr 的大小: 6
arr 的地址: 824634150682- 如果数组中的元素是结构体类型,那么数组的对齐值通常是结构体中最大字段对齐值的倍数。例如,如果结构体中有一个int64字段和一个bool字段,在 64 位系统上,int64通常是 8 字节对齐,bool通常是 1 字节对齐,那么这个结构体的对齐值可能是 8 字节。如果这个结构体组成的数组,其对齐值也会是 8 字节。
go
package main
import (
"unsafe"
"fmt"
)
type s struct {
a bool
b int64
}
func main() {
var arr [3]s = [3]s{s{},s{},s{}}
fmt.Printf("arr 的对齐值:%d\n", unsafe.Alignof(arr))
fmt.Printf("arr 的大小: %d\n", unsafe.Sizeof(arr))
fmt.Printf("arr 的地址: %d\n", uintptr(unsafe.Pointer(&arr)))
}
$ go run main.go
arr 的对齐值:8
arr 的大小: 48
arr 的地址: 824634216176结构体的对齐
- 结构体中的字段会按照各自的类型进行对齐。每个字段的起始地址必须是其类型对齐值的整数倍。
go
package main
import (
"unsafe"
"fmt"
)
type S struct {
a bool
b int32
}
func main() {
bar := S{}
fmt.Printf("bar.b 的对齐值:%d\n", unsafe.Alignof(bar.b))
fmt.Printf("bar.b 的偏移量: %d\n", unsafe.Offsetof(bar.b))
}
$ go run main.go
bar.b 的对齐值:4
bar.b 的偏移量: 4- 结构体本身也有一个对齐值,这个对齐值是结构体中最大字段对齐值的倍数。整个结构体的大小必须是其对齐值的整数倍。
go
package main
import (
"unsafe"
"fmt"
)
type S struct {
a int64
b bool
}
func main() {
bar := S{}
fmt.Printf("bar 的对齐值: %d\n", unsafe.Alignof(bar))
fmt.Printf("bar 的大小: %d\n", unsafe.Sizeof(bar))
}
$ go run main.go
bar 的对齐值: 8
bar 的大小: 16数据结构优化
为了实现内存对齐,编译器有时候会在结构体的字段之间或者结构体末尾进行填充,这样会带来两个问题:
-
影响性能:由于字段之间填充了空置的内存,会导致CPU读取结构体数据时访问内存的次数会增加。
-
浪费内存:浪费内存就更好理解,填充的空置内存是无法被程序利用的,就白白浪费掉了。
所以我们设计结构体时应该注意内存对齐对性能的影响,尽量减少填充空置内存,下面两个结构体拥有相同类型的字段,只因字段顺序的不同就造成很大性能差异:
go
// 需要填充 9 个字节
type S1 struct {
a bool
b int64
c int16
d int32
}
// 只需要填充 1 个字节
type S2 struct {
a bool
b int16
c int32
d int64
}
func Benchmark_S1(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
_ = make([]S1, b.N)
}
}
func Benchmark_S2(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
_ = make([]S2, b.N)
}
}
>>> go test -run='^$' -bench=. -count=1 -benchtime=100000x -benchmem
goos: darwin
goarch: amd64
pkg: go_test/unsafe/align
Benchmark_S1-12 100000 66230 ns/op 2400267 B/op 1 allocs/op
Benchmark_S2-12 100000 45750 ns/op 1605655 B/op 1 allocs/op
PASS
ok go_test/unsafe/align 11.736s