第三章 PyTorch的使用
文章目录
- 检查是否安装好
- 张量Tensor
-
- 张量的创建
- 张量的方法和属性
-
- tensor的元素类型
-
- [获取tensor的数据类型: tensor.dtype](#获取tensor的数据类型: tensor.dtype)
- 创建数据的时候指定类型
- 类型的修改
- 张量类型转换
-
- [tensor.item() 获取tensor中的数据](#tensor.item() 获取tensor中的数据)
- [将张量转换为 numpy 数组](#将张量转换为 numpy 数组)
- [numpy 转换为张量](#numpy 转换为张量)
- [tensor.size() 获取形状](#tensor.size() 获取形状)
- [张量形状的操作 -- 形状改变](#张量形状的操作 -- 形状改变)
-
- tensor.view()
- [transpose() & contiguous() & is_contiguous()](#transpose() & contiguous() & is_contiguous())
- tensor.reshape()
- [transpose() & permute() 轴交换](#transpose() & permute() 轴交换)
- 转置tensor.t()
- 转置tensor.T
- [squeeze 和 unsqueeze 函数](#squeeze 和 unsqueeze 函数)
- 获取阶数tensor.dim()
- 获取最大值tensor.max()
- 获取最小值tensor.min()
- 获取标准差tensor.std()
- 索引操作
- tensor的其他操作
conda activate eliauk
pip install jupyter
pip install numpy==1.26.4
pip list检查是否安装好
PY
import torch
print(torch.__version__)
注意:安装模块的时候安装的是pytorch,但是在代码中都是使用torch
张量Tensor
PyTorch 是一个 Python 深度学习框架,它将数据封装成张量(Tensor)来进行运算。PyTorch 中的张量就是元素为同一种数据类型的多维矩阵。在 PyTorch 中,张量以 "类" 的形式封装起来,对张量的一些运算、处理的方法被封装在类中。
张量是一个统称,其中包含很多类型:
-
0阶张量:标量、常数,scaler,0-D Tensor,eg:1
-
1阶张量:向量,vector,1-D Tensor,eg:1,2,3
-
2阶张量:矩阵,matrix,2-D Tensor,eg:\[1,2]
-
3阶张量
-
...
-
N阶张量
张量的创建
-
torch.tensor(list/array) 根据指定数据创建张量
-
torch.Tensor() 根据形状创建张量, 其也可用来创建指定数据的张量, 默认float32类型
-
创建指定类型的张量
-
torch.IntTensor dtype 为 int32 的张量
( ) , return tensor(\[\], dtype=torch.int32)
(行数 , 列数),会用随机数据进行填充
(list或者其他) 如果传递的元素类型不正确, 则会进行类型转换
-
torch.FloatTensor float32 ,一般创建默认这个类型
-
torch.DoubleTensor float64
-
torch.ShortTensor int16
-
torch.LongTensor int64
-
-
torch.ones(行数,列数或者tensor ) 创建全为1的tensor
-
torch.zeros(行数,列数或者tensor ) 创建全为0的tensor
-
torch.empty,创建全为空的tensor,会用无用数据进行填充
-
随机数
-
torch.random.manual_seed(int) 设置CPU生成随机数的种子,方便下次复现实验结果。取值范围为
[-0x8000000000000000, 0xffffffffffffffff],十进制是[-9223372036854775808, 18446744073709551615],超出该范围将触发RuntimeError报错。- 没有设置随机种子,每次运行xxx.py的输出结果都不相同
- 设置随机种子后,是每次运行xxx.py文件的输出结果都一样,而不是每次随机函数生成的结果一样,如果你就是想要每次运行随机函数生成的结果都一样,那你可以在每个随机函数前都设置一模一样的随机种子,举个例子:
pythonprint('随机数种子:', torch.random.initial_seed())# 88671008932000 再运行xxx.py会变化的 torch.random.manual_seed(100) print('随机数种子:', torch.random.initial_seed())# 100 print(torch.rand(1))# tensor([0.1117]) 再运行xxx.py也还是一样的结果 print(torch.rand(1))# tensor([0.8158]) 可以看到两次打印torch.rand(1)函数生成的结果是不一样的,再运行xxx.py也还是一样的结果 print('随机数种子:', torch.random.initial_seed())# 100 torch.random.manual_seed(100) # 如果你就是想要每次运行随机函数生成的结果都一样,那你可以在每个随机函数前都设置一模一样的随机种子 print(torch.rand(1))# tensor([0.1117]) 再运行xxx.py也还是一样的结果 -
torch.rand(行数,列数) 创建全为随机值的tensor,随机区间 [0, 1)
-
torch.randint(low=,high=,size=\[\]):生成size个取值从low到high的随机整数
-
torch.randn(行数,列数) 均值 为0标准差为1的数组
-
-
创建线性张量
-
torch.arange(start, end, step)
返回大小为 (end−start)/step 的一维张量,其值介于区间 [ start , end ) ,以 step 为步长等间隔取值
- start 起始值,默认值:0
- end 结束值
- step 步长,默认值:1
-
torch.linspace (start, end, steps=100, dtype=None)
返回一维张量 , 从start到end(包括端点)的等距的steps个数据点。
-
start:开始值
-
end:结束值
-
steps:分割的点数,默认是100
-
dtype:返回值(张量)的数据类型
-
-
python
import torch
import numpy as np
t1 = torch.Tensor([1,2,3])
t1
# tensor([1., 2., 3.])
t1.type()
# 'torch.FloatTensor'
array1 = np.arange(12).reshape(3,4)
array1
# array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
type(array1)
# numpy.ndarray
array1.dtype
# dtype('int32')
t2=torch.Tensor(array1)
t2
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])
t2.type()
# 'torch.FloatTensor'
torch.IntTensor(2, 3)
# tensor([[ 0, 0, 1852990827],
# [ 925789285, 862139704, 758276662]], dtype=torch.int32)
torch.IntTensor()
# tensor([], dtype=torch.int32)
torch.IntTensor([2.5, 3.3])
# tensor([2, 3], dtype=torch.int32)
torch.empty(5,6)
# tensor([[1.4013e-45, 0.0000e+00, 3.5786e+09, 7.2307e-43, 3.4549e+09, 7.2307e-43],
# [0.0000e+00, 0.0000e+00, 4.5972e+09, 7.2307e-43, 3.3307e+07, 7.2307e-43],
# [5.6853e+11, 7.2307e-43, 1.4013e-45, 0.0000e+00, 2.8026e-45, 0.0000e+00],
# [0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00],
# [0.0000e+00, 0.0000e+00, 1.4013e-45, 0.0000e+00, 0.0000e+00, 0.0000e+00]])
torch.ones([5,6])
# tensor([[1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1.]])
torch.zeros([5,6])
# tensor([[0., 0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0., 0.]])
torch.rand([5,6])
# tensor([[0.8158, 0.2626, 0.4839, 0.6765, 0.7539, 0.2627],
# [0.0428, 0.2080, 0.1180, 0.1217, 0.7356, 0.7118],
# [0.7876, 0.4183, 0.9014, 0.9969, 0.7565, 0.2239],
# [0.3023, 0.1784, 0.8238, 0.5557, 0.9770, 0.4440],
# [0.9478, 0.7445, 0.4892, 0.2426, 0.7003, 0.5277]])
torch.randint(low=0, high=10, size=[5,6])
# tensor([[0, 0, 9, 5, 7, 3],
# [9, 4, 0, 5, 7, 5],
# [9, 9, 7, 5, 9, 8],
# [9, 7, 9, 2, 6, 7],
# [7, 8, 3, 6, 1, 5]])
torch.randn([3,4])
# tensor([[-0.7246, 0.6720, 2.1515, 1.0493],
# [-0.1324, -1.5300, -0.0529, 0.9478],
# [-2.1728, 0.8868, -0.1670, -0.3786]])
print('随机数种子:', torch.random.initial_seed())# 88671008932000 再运行xxx.py会变化的
torch.random.manual_seed(100)
print('随机数种子:', torch.random.initial_seed())# 100
print(torch.rand(1))# tensor([0.1117]) 再运行xxx.py也还是一样的结果
print(torch.rand(1))# tensor([0.8158]) 可以看到两次打印torch.rand(1)函数生成的结果是不一样的,再运行xxx.py也还是一样的结果
print('随机数种子:', torch.random.initial_seed())# 100
torch.random.manual_seed(100) # 如果你就是想要每次运行随机函数生成的结果都一样,那你可以在每个随机函数前都设置一模一样的随机种子
print(torch.rand(1))# tensor([0.1117]) 再运行xxx.py也还是一样的结果
torch.arange(10)
# tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
torch.arange(0, 10)
# tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
torch.arange(0, 10, 2)
# tensor([0, 2, 4, 6, 8])
torch.linspace(0, 11, 10)
# tensor([ 0.0000, 1.2222, 2.4444, 3.6667, 4.8889, 6.1111, 7.3333, 8.5556, 9.7778, 11.0000])torch.Tensor和torch.tensor的区别
- 全局 (默认的数据类型) 是torch.float32
- torch.Tensor()传入数字表示形状和torch.FloatTensor相同
- torch.Tensor传入可迭代对象表示数据, 类型为模型等数据类型
- torch.tensor为创建tensor的方法
python
torch.Tensor([1])
# tensor([1.])
torch.Tensor([1,2])
#tensor([1., 2.])
torch.Tensor(1)# 里面是随机放的一些值
#tensor([3.6013e-43])
torch.FloatTensor(1)# 里面是随机填充的一些值
# tensor([1.4013e-45])
torch.FloatTensor(2,3)
""" tensor([[1.4013e-45, 0.0000e+00, 1.4013e-45],
[0.0000e+00, 1.4013e-45, 0.0000e+00]]) """张量的方法和属性
tensor的元素类型
tensor中的数据类型非常多,常见类型如下:
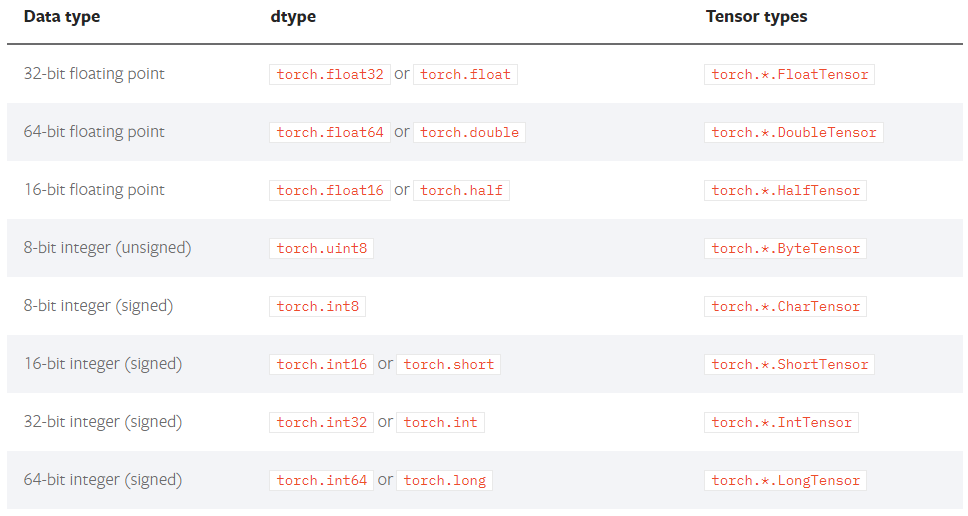
上图中的Tensor types表示这种type的tensor是其实例
获取tensor的数据类型: tensor.dtype
import torch
t1 = torch.Tensor([1, 2, 3, 4])
t1.dtype
# Out:torch.float32创建数据的时候指定类型
torch.tensor(array,dtype)
.ones(array,dtype)
zeros()
empty()
python
import torch
t1 = torch.Tensor([1, 2, 3, 4])
t1.dtype
#torch.float32
# t2 = torch.Tensor([1, 2, 3, 4],dtype=torch.int64)#不可以,会报错
"""Out:
TypeError: new() received an invalid combination of arguments - got (list, dtype=torch.dtype), but expected one of:
* (*, torch.device device)
didn't match because some of the keywords were incorrect: dtype
* (torch.Storage storage)
* (Tensor other)
* (tuple of ints size, *, torch.device device)
* (object data, *, torch.device device)
"""
t2 = torch.ones([3, 4],dtype=torch.int64)
t2.dtype
# torch.int64
t3 = torch.empty([3, 4],dtype=torch.int64)
print(t3)
print(t3.dtype)
"""Out:
tensor([[3059682050528, 0, 0, 0],
[ 0, 0, 0, 0],
[ 0, 0, 0, 0]])
torch.int64
"""
t3 = torch.zeros([3, 4],dtype=torch.int64)
print(t3)
print(t3.dtype)
"""Out:
tensor([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]])
torch.int64
"""t=torch.tensor(np.arange(12),dtype=torch.short)
t
# tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11], dtype=torch.int16)类型的修改
python
import torch
import numpy as np
t4=torch.Tensor(np.arange(12,dtype=np.int32))# 这样是没有效果的
t4.dtype# 没有效果,Out[]: torch.float32
# 强制转换
# 1.
t4.int()
"""Out:
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11], dtype=torch.int32)
"""
# 2.
new_t4=t4.type(torch.int64)
print(new_t4)
print(new_t4.dtype)
"""Out:
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
torch.int64
"""
t5=t4.type(torch.ShortTensor)
print(t5)
"""Out:
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11], dtype=torch.int16)
"""
print(torch.LongTensor([1,2,3]))
print(torch.LongTensor([1,2,3]).dtype)
"""Out:
tensor([1, 2, 3])
torch.int64
"""张量类型转换
tensor.item() 获取tensor中的数据
获取tensor中的数据(当tensor中只有一个元素可用时)可用tensor.item()
import torch
t1 = torch.Tensor([[[1]]])
t1 #tensor([[[1.]]])
t1.item() #1.0
type(t1.item()) #float
t2 = torch.Tensor([[[1,2,3]]])
t2.item()
# 报错:ValueError:只有一个元素张量可以转换为Python里面的张量类型
# ValueError: only one element tensors can be converted to Python scalars将张量转换为 numpy 数组
使用 Tensor.numpy() 函数可以将张量转换为 ndarray 数组,但是共享内存,可以使用 copy 函数避免共享。
t2 = torch.Tensor([[[1,2,3]]])
t2.numpy()
# array([[[1., 2., 3.]]], dtype=float32)
python
import torch
t1 = torch.tensor([2, 3, 4])
# 使用张量对象中的 numpy 函数进行转换
n1 = t1.numpy()
print(type(t1))
print(type(n1))
# 注意: data_tensor 和 data_numpy 共享内存
# 修改其中的一个,另外一个也会发生改变
# data_tensor[0] = 100
n1[0] = 100
print(t1)
print(n1)
"""结果:
<class 'torch.Tensor'>
<class 'numpy.ndarray'>
tensor([100, 3, 4])
[100 3 4]
"""numpy 转换为张量
-
使用 torch.from_numpy(ndarray) 可以将 ndarray 数组转换为 Tensor,默认共享内存 (浅拷贝) ,使用 copy 函数避免共享。
-
使用 torch.tensor(ndarray) 可以将 ndarray 数组转换为 Tensor,默认不共享内存。
data_numpy = np.array([1, 2, 3])
将 numpy 数组转换为张量类型
1. from_numpy
2. torch.tensor(ndarray)
浅拷贝
data_tensor = torch.from_numpy(data_numpy)
nunpy 和 tensor 共享内存
data_numpy[0] = 100
data_tensor[0] = 100
print(data_tensor)
print(data_numpy)
"""
tensor([100, 2, 3], dtype=torch.int32)
[100 2 3]
"""data_numpy = np.array([1, 2, 3])
data_tensor = torch.tensor(data_numpy)
nunpy 和 tensor 不共享内存
data_numpy[0] = 100
data_tensor[0] = 100
print(data_tensor)
print(data_numpy)
"""
tensor([100, 2, 3], dtype=torch.int32)
[1 2 3]
"""
tensor.size() 获取形状
tensor.size(012...)
t2 = torch.Tensor([[[1,2,3],[5,6,7]]])
t2.shape
#torch.Size([1, 2, 3])
t2.size()
#torch.Size([1, 2, 3])
t2.size(-1)
#3
t2.size(2)
#3
t2.size(1)
#2
t2.size(0)
#1shape属性和numpy的shape属性是一样的,但是我们尽量用size方法来做,因为size方法结果和shape结果是一样的,但是假如对于t2而言我们想要获取具体的某一个维度的这个形状的值的时候呢,我们可以在里面传数据,比如说我们要获取它最后一个维度我们用tensor.size(-1)
张量形状的操作 -- 形状改变
tensor.view()
类似numpy中的reshape,是一种浅拷贝,仅仅是形状发生变化
python
t2 = torch.Tensor([[[1,2,3],[5,6,7]]])
t2.view([6])
# tensor([1., 2., 3., 5., 6., 7.])
t2.size()
# torch.Size([1, 2, 3])
t2.view([-1])
# tensor([1., 2., 3., 5., 6., 7.])
t2.view([3,-1])# 这里写-1就是2,因为一共是1*2*3=6个,然后6/3=2
# tensor([[1., 2.],
# [3., 5.],
# [6., 7.]])
t2.view([3,-1]).is_contiguous()# True-1表示的意思是这后面的形状根据前的情况而决定后面到底是什么形状,只要保证它的形状的数值的乘积是一定的是一样多的,所以乘积的数值是一定的意味着就是好的总的个数是一定的一共是1*2*3=6个
view 函数可以用于修改张量的形状,但是其用法比较局限,只能用于存储在整块内存中的张量。在 PyTorch 中,有些张量是由不同的数据块组成的,它们并没有存储在整块的内存中,view 函数无法对这样的张量进行变形处理,例如: 一个张量经过了 transpose 或者 permute 函数的处理之后,就无法使用 view 函数进行形状操作。
transpose() & contiguous() & is_contiguous()
-
torch.transpose(tensor, ...) 修改形状
-
tensor.contiguous() 转换为整块内存的张量
-
tensor.is_contiguous() 判断张量是否使用整块内存
python
t1 = torch.tensor([[10, 20, 30], [40, 50, 60]])
print('t1 形状:', t1.size())# torch.Size([2, 3])
# 1. 使用 view 函数修改形状
t2 = t1.view(3, 2)
print('t2 形状:', t2.shape)# torch.Size([3, 2])
# 2. 判断张量是否使用整块内存
print('t1:', t1.is_contiguous()) # True
# 3. 使用 transpose 函数修改形状
t3 = torch.transpose(t1, 0, 1)
print('t3:', t3.is_contiguous()) # False
#t4 = t3.view(2, 3) # RuntimeError
#%%
# 需要先使用 contiguous 函数转换为整块内存的张量,再使用 view 函数
print(t3.contiguous().is_contiguous())# True
t4 = t3.contiguous().view(2, 3)
print('new_data shape:', t4.shape)# new_data shape: torch.Size([2, 3])tensor.reshape()
reshape 函数可以在保证张量数据不变的前提下改变数据的维度,将其转换成指定的形状,在后面的神经网络学习时,会经常使用该函数来调节数据的形状,以适配不同网络层之间的数据传递。
t1 = torch.tensor([[1,2,3],[5,6,7]])
# 1. 使用 shape 属性或者 size 方法都可以获得张量的形状
print(t1.shape, t1.shape[0], t1.shape[1]) # torch.Size([2, 3]) 2 3
print(t1.size(), t1.size(0), t1.size(1)) # torch.Size([2, 3]) 2 3
# 2. 使用 reshape 函数修改张量形状
t2 = t1.reshape(1, 6)
print(t2.shape)# torch.Size([1, 6])
print(t2.is_contiguous())# Truetranspose() & permute() 轴交换
python
import numpy as np
import torch
t2 = torch.Tensor(np.arange(24).reshape(2,3,4))
t2
"""
tensor([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]]])
"""
t2.size()# torch.Size([2, 3, 4])
#t2.transpose()# 报错:因为它里面有三个维度,所以你不传的时候它不知道你要交换哪两个维度(交换哪两个轴)
t2.transpose(0,1)# 如果你想交换2和3
"""
tensor([[[ 0., 1., 2., 3.],
[12., 13., 14., 15.]],
[[ 4., 5., 6., 7.],
[16., 17., 18., 19.]],
[[ 8., 9., 10., 11.],
[20., 21., 22., 23.]]])
"""
t2.permute(0,1,2)# 没变化[2, 3, 4]
"""
tensor([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]]])
"""
t2.permute(1,0,2)# [3, 2, 4],意思是第一个轴放中间,第二轴放前面
"""tensor([[[ 0., 1., 2., 3.],
[12., 13., 14., 15.]],
[[ 4., 5., 6., 7.],
[16., 17., 18., 19.]],
[[ 8., 9., 10., 11.],
[20., 21., 22., 23.]]])
"""转置tensor.t()
.t() 是 .transpose()的简写版本,但两者都 只能对2维以下的tensor进行转置。
t = torch.Tensor(np.arange(6).reshape(2,3))
t.t()
"""
tensor([[0., 3.],
[1., 4.],
[2., 5.]])
"""
t.T
"""
tensor([[0., 3.],
[1., 4.],
[2., 5.]])
"""转置tensor.T
.T 是 .permute 函数的简化版本,不仅可以操作2维tensor,甚至可以对n维tensor进行转置。当然当维数n=2时,.t() 与 .T 效果是一样的。
t = torch.Tensor(np.arange(24).reshape(2,3,4))
t
t.T
"""
tensor([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]]])
tensor([[[ 0., 12.],
[ 4., 16.],
[ 8., 20.]],
[[ 1., 13.],
[ 5., 17.],
[ 9., 21.]],
[[ 2., 14.],
[ 6., 18.],
[10., 22.]],
[[ 3., 15.],
[ 7., 19.],
[11., 23.]]])
"""squeeze 和 unsqueeze 函数
import torch
import numpy as np
data = torch.tensor(np.random.randint(0, 10, [1, 3, 1, 5]))
print(data)
print('data shape:', data.size())
print("="*20)
# 1. 去掉值为1的维度
new_data = data.squeeze()
print('new_data shape:', new_data.size()) # torch.Size([3, 5])
print(new_data)
print("="*20)
# 2. 去掉指定位置为1的维度,注意: 如果指定位置不是1则不删除
new_data = data.squeeze(2)
print('new_data shape:', new_data.size()) # torch.Size([3, 5])
print(new_data)
print("="*20)
# 3. 在2维度增加一个维度
new_data = data.unsqueeze(-1)
print('new_data shape:', new_data.size()) # torch.Size([3, 1, 5, 1])
print(new_data)结果:
tensor([[[[2, 2, 9, 7, 2]],
[[6, 1, 6, 2, 8]],
[[5, 4, 0, 4, 2]]]], dtype=torch.int32)
data shape: torch.Size([1, 3, 1, 5])
====================# 1. 去掉值为1的维度data.squeeze()
new_data shape: torch.Size([3, 5])
tensor([[2, 2, 9, 7, 2],
[6, 1, 6, 2, 8],
[5, 4, 0, 4, 2]], dtype=torch.int32)
====================# 2. 去掉指定位置为1的维度,注意: 如果指定位置不是1则不删除data.squeeze(2)
new_data shape: torch.Size([1, 3, 5])
tensor([[[2, 2, 9, 7, 2],
[6, 1, 6, 2, 8],
[5, 4, 0, 4, 2]]], dtype=torch.int32)
====================# 3. 在2维度增加一个维度data.unsqueeze(-1)
new_data shape: torch.Size([1, 3, 1, 5, 1])
tensor([[[[[2],
[2],
[9],
[7],
[2]]],
[[[6],
[1],
[6],
[2],
[8]]],
[[[5],
[4],
[0],
[4],
[2]]]]], dtype=torch.int32)获取阶数tensor.dim()
python
t2 = torch.Tensor([[[1,2,3],[5,6,7]]])
t2.dim()# 3获取最大值tensor.max()
跟numpy一样
获取最小值tensor.min()
跟numpy一样
获取标准差tensor.std()
跟numpy一样
t2 = torch.Tensor([[[1,2,3],[5,6,7]]])
print(t2.max())#tensor(7.)
print(t2.min())#tensor(1.)
print(t2.std())#tensor(2.3664)索引操作
tensor的切片
t = torch.Tensor(np.arange(24).reshape(6,4))
t
t[1,3]# 获取tensor中第二行第四列的值
t[1,3]=666# 对tensor中第二行第四列的位置进行赋值
print(t)
t[1,:]
t[:,2]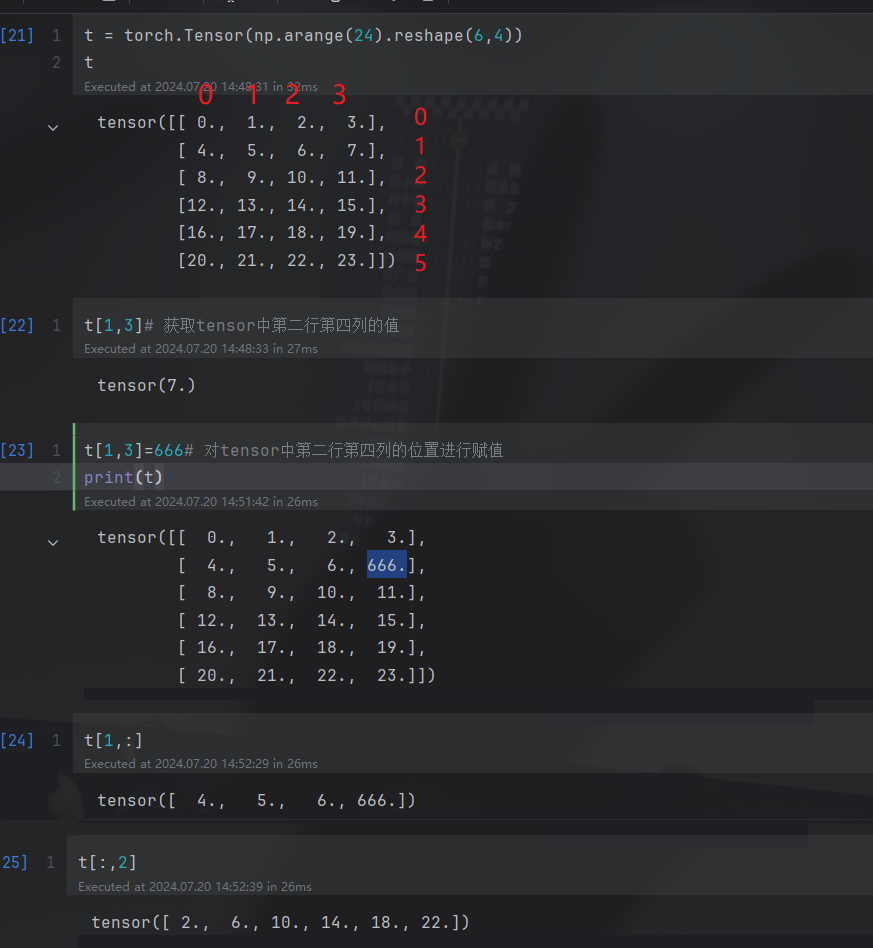
简单行、列索引
python
import torch
import numpy as np
data = torch.Tensor(np.arange(24).reshape(6,4))
print(data)
print('+' * 50)
print(data[0])
print(data[:, 0])
print('+' * 50)输出结果:
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]])
++++++++++++++++++++++++++++++++++++++++++++++++++
tensor([0., 1., 2., 3.])
tensor([ 0., 4., 8., 12., 16., 20.])
++++++++++++++++++++++++++++++++++++++++++++++++++列表索引
data = torch.Tensor(np.arange(24).reshape(6,4))
# 返回 (0, 1)、(1, 2) 两个位置的元素
print(data[[0, 1], [1, 2]])
print('+' * 50)
# 返回 0、1 行的 1、2 列共4个元素
print(data[[[0], [1]], [1, 2]])输出结果:
tensor([1., 6.])
++++++++++++++++++++++++++++++++++++++++++++++++++
tensor([[1., 2.],
[5., 6.]])范围索引
data = torch.Tensor(np.arange(24).reshape(6,4))
# 前3行的前2列数据
print(data[:3, :2])
# 第2行到最后的前2列数据
print(data[2:, :2])输出结果:
tensor([[0., 1.],
[4., 5.],
[8., 9.]])
tensor([[ 8., 9.],
[12., 13.],
[16., 17.],
[20., 21.]])布尔索引
data = torch.Tensor(np.arange(24).reshape(6,4))
print(data)
# 第三列大于9的行数据
print(data[data[:, 2] > 9])
# 第二行大于5的列数据
print(data[:, data[1] > 5])
print(data[1])输出结果:
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]])
tensor([[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]])
tensor([[ 2., 3.],
[ 6., 7.],
[10., 11.],
[14., 15.],
[18., 19.],
[22., 23.]])
tensor([4., 5., 6., 7.])多维索引
data = torch.Tensor(np.arange(24).reshape(2,3,4))
print(data)
print('+' * 50)
print(data[0, :, :])
print(data[:, 0, :])
print(data[:, :, 0])输出结果:
tensor([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]]])
++++++++++++++++++++++++++++++++++++++++++++++++++
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
tensor([[ 0., 1., 2., 3.],
[12., 13., 14., 15.]])
tensor([[ 0., 4., 8.],
[12., 16., 20.]])tensor的其他操作
张量基本运算
基本运算中,包括 add、sub、mul、div、neg 等函数, 以及这些函数的带下划线的版本 add_、sub_、mul_、div_、neg_,其中带下划线的版本为修改原数据。
tensor和tensor相加
python
x = torch.ones(5, 3)
x
"""
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
"""
y = torch.rand(5, 3)
y
"""
tensor([[0.1344, 0.5103, 0.9405],
[0.1343, 0.5517, 0.2370],
[0.5062, 0.1715, 0.5828],
[0.1796, 0.7633, 0.4108],
[0.2603, 0.5020, 0.1300]])
"""
x+y
"""
tensor([[1.1344, 1.5103, 1.9405],
[1.1343, 1.5517, 1.2370],
[1.5062, 1.1715, 1.5828],
[1.1796, 1.7633, 1.4108],
[1.2603, 1.5020, 1.1300]])
"""
torch.add(x,y)
"""
tensor([[1.1344, 1.5103, 1.9405],
[1.1343, 1.5517, 1.2370],
[1.5062, 1.1715, 1.5828],
[1.1796, 1.7633, 1.4108],
[1.2603, 1.5020, 1.1300]])
"""
x.add(y)
"""
tensor([[1.1344, 1.5103, 1.9405],
[1.1343, 1.5517, 1.2370],
[1.5062, 1.1715, 1.5828],
[1.1796, 1.7633, 1.4108],
[1.2603, 1.5020, 1.1300]])
"""
x.add_(y) #带下划线的方法会对x进行就地修改
"""
tensor([[1.1344, 1.5103, 1.9405],
[1.1343, 1.5517, 1.2370],
[1.5062, 1.1715, 1.5828],
[1.1796, 1.7633, 1.4108],
[1.2603, 1.5020, 1.1300]])
"""
x #x发生改变
"""
tensor([[1.1344, 1.5103, 1.9405],
[1.1343, 1.5517, 1.2370],
[1.5062, 1.1715, 1.5828],
[1.1796, 1.7633, 1.4108],
[1.2603, 1.5020, 1.1300]])
"""注意:带下划线的方法(比如:add_)会对tensor进行就地修改
tensor和数字操作
python
x = torch.ones(5, 3)
x +10
"""
tensor([[11., 11., 11.],
[11., 11., 11.],
[11., 11., 11.],
[11., 11., 11.],
[11., 11., 11.]])
"""CUDA中的tensor
PyTorch 默认会将张量创建在 CPU 控制的内存中, 即: 默认的运算设备为 CPU。我们也可以将张量创建在 GPU 上, 能够利用对于矩阵计算的优势加快模型训练。将张量移动到 GPU 上有两种方法: 1. 使用 cuda 方法 2. 直接在 GPU 上创建张量 3. 使用 to 方法指定设备
python
# 使用 cuda 方法
data = torch.tensor([10, 20 ,30])
print('存储设备:', data.device)
# 如果安装的不是 gpu 版本的 PyTorch
# 或电脑本身没有 NVIDIA 卡的计算环境
# 下面代码可能会报错
data = data.cuda()
print('存储设备:', data.device)
# 使用 cpu 函数将张量移动到 cpu 上
data = data.cpu()
print('存储设备:', data.device)
# 输出结果:
# 存储设备: cpu
# 存储设备: cuda:0
# 存储设备: cpuCUDA(Compute Unified Device Architecture),是NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
torch.cuda这个模块增加了对CUDA tensor的支持,能够在cpu和gpu上使用相同的方法操作tensor
通过.to方法能够把一个tensor转移到另外一个设备(比如从CPU转到GPU)
python
x = torch.ones(5, 3)
#device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# cuda:0 表示用第一块gpu,cuda:2 表示用第二块gpu
if torch.cuda.is_available():
device = torch.device("cuda") # cuda device对象:device(type='cuda')
y = torch.ones_like(x, device=device) # 创建一个在cuda上的tensor, 生成与input形状相同、元素全为1的张量
x = x.to(device) # 使用方法把x转为cuda 的tensor
z = x + y
print(z)
print(z.to("cpu", torch.double)) # .to方法也能够同时设置类型
"""
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]], device='cuda:0')
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]], dtype=torch.float64)
"""torch.cuda.is_available()如果为True就支持使用gpu执行我们的代码
python
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.zeros([2,4],device=device)
"""
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.]], device='cuda:0')
"""-
实例化device:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") -
tensor.to(device)把tensor转化为CUDA支持的tensor, 或者cpu支持的tensor。
python
# 注意:存储在不同设备的张量不能运算
data1 = torch.tensor([10, 20, 30], device='cuda:0')
data2 = torch.tensor([10, 20, 30])
print(data1.device, data2.device)
data = data1 + data2
# RuntimeError: Expected all tensors to be on the same device,
# but found at least two devices, cuda:0 and cpu!
print(data)阿达玛积
阿达玛积指的是矩阵对应位置的元素相乘.
import numpy as np
import torch
def test():
data1 = torch.tensor([[1, 2], [3, 4]])
data2 = torch.tensor([[5, 6], [7, 8]])
# 第一种方式
data = torch.mul(data1, data2)
print(data)
print('-' * 50)
# 第二种方式
data = data1 * data2
print(data)
print('-' * 50)
if __name__ == '__main__':
test()程序输出结果:
tensor([[ 5, 12],
[21, 32]])
--------------------------------------------------
tensor([[ 5, 12],
[21, 32]])
--------------------------------------------------点积运算
点积运算要求第一个矩阵 shape: (n, m),第二个矩阵 shape: (m, p), 两个矩阵点积运算 shape 为: (n, p)。
- 运算符 @ 用于进行两个矩阵的点乘运算
- torch.mm 用于进行两个矩阵点乘运算, 要求输入的矩阵为2维
- torch.bmm 用于批量进行矩阵点乘运算, 要求输入的矩阵为3维
- torch.matmul 对进行点乘运算的两矩阵形状没有限定.
- 对于输入都是二维的张量相当于 mm 运算.
- 对于输入都是三维的张量相当于 bmm 运算
- 对数输入的 shape 不同的张量, 对应的最后几个维度必须符合矩阵运算规则
python
import numpy as np
import torch
# 1. 点积运算
def test01():
data1 = torch.tensor([[1, 2], [3, 4], [5, 6]])
data2 = torch.tensor([[5, 6], [7, 8]])
# 第一种方式
data = data1 @ data2
print(data)
print('-' * 50)
# 第二种方式
data = torch.mm(data1, data2)
print(data)
print('-' * 50)
# 第三种方式
data = torch.matmul(data1, data2)
print(data)
print('-' * 50)
# 2. torch.mm 和 torch.matmull 的区别
def test02():
# matmul 可以两个维度可以不同
# 第一个张量: (3, 4, 5)
# 第二个张量: (6, 4)
# torch.mm 不可以相乘,而 matmul 则可以相乘
print(torch.matmul(torch.randn(3, 4, 5), torch.randn(5, 4)).shape)
print(torch.matmul(torch.randn(5, 4), torch.randn(3, 4, 5)).shape)
# 3. torch.mm 函数的用法
def test03():
# 批量点积运算
# 第一个维度为 batch_size
# 矩阵的二三维要满足矩阵乘法规则
data1 = torch.randn(3, 4, 5)
data2 = torch.randn(3, 5, 8)
data = torch.bmm(data1, data2)
print(data.shape)
if __name__ == '__main__':
test01()
test02()
test03()程序输出结果:
tensor([[19, 22],
[43, 50],
[67, 78]])
--------------------------------------------------
tensor([[19, 22],
[43, 50],
[67, 78]])
--------------------------------------------------
tensor([[19, 22],
[43, 50],
[67, 78]])
--------------------------------------------------
torch.Size([3, 4, 4])
torch.Size([3, 5, 5])
torch.Size([3, 4, 8])