这是我的第104篇原创文章
问题由来
在使用kafka时,创建topic,对某个topic进行扩分区的操作,想必大家肯定都使用过。尤其是集群进行扩容时,对流量较大的topic进行扩分区操作。一般而言,期望的效果是:新扩的分区分布到新的broker节点上,这样才能达到均衡流量分摊broker压力。
然而,我们在实际使用过程中发现,在一种场景下,原生的代码逻辑中,对topic分区进行扩容后,新增的分区并没有分配到新的节点上,即新增的分区和老的分区仍旧位于扩容前的broker节点上,导致这个节点压力反而变大,引发生产者发送超时等问题,本文就这个问题进行分析。
问题产生的步骤
我们先来看下问题出现的操作步骤与现象,在具有3个broker的集群环境中,分别通过自带脚本(kafka-topics.sh)和adminClient的接口创建一个分区数为2、副本因子为1的topic,然后再扩容到3分区,此后查看topic分区的分布情况。
通过接口操作的情况如下所示:

通过脚本操作的情况如下所示:

从图中可以直观的看到通过接口创建的topic,在扩容分区后,新增的2号分区的leader与老的1号分区的leader位于同一个broker节点上,而不是像脚本操作的一样,3个分区的leader分别位于3个broker节点上。
两种操作方式的区别
由于扩分区的操作都是一样的,那为什么不同的创建的方式,在进行扩容后就有了不同的结果呢?我们还是先来看下两种创建topic方式的逻辑。
对于通过脚本创建topic的处理逻辑为:
-
通过zk客户端获取当前集群的所有broker
-
根据topic创建的参数,进行topic分区副本的分配
-
通过zk客户端,将topic分区副本信息写入zookeeper
-
kafka broker的controller监听zk并感知其变化,然后根据分区副本的分布情况向对应broker发送请求完成topic分区的创建
关键代码如下所示:
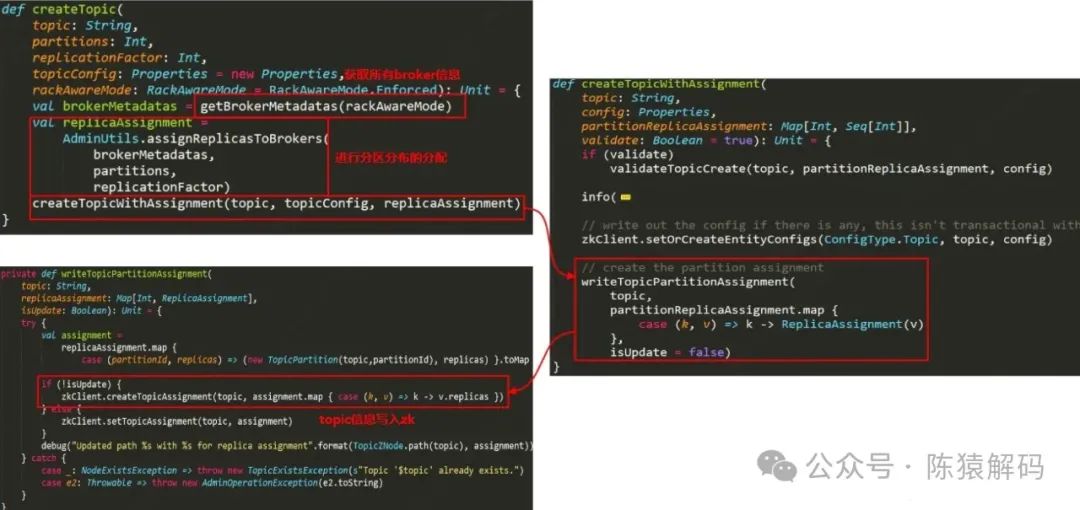
对于通过接口创建topic的处理逻辑为:
-
客户端向broker发送CREATE_TOPIC的请求
-
broker接收到请求后,从元数据缓存中获取当前集群的所有broker
-
根据topic创建的参数,进行topic分区副本的分配
-
通过zk客户端,将topic分区副本信息写入zookeeper
-
kafka broker的controller监听zk并感知其变化,然后根据分区副本的分布情况向对应broker发送请求完成topic分区的创建
两种方式本质上的处理都是一样的,即进行topic分区副本的分配,并将这个信息写入zookeeper,然后由controller完成真正的创建逻辑。只不过一个是在客户端侧完成,一个是向broker发送请求,在broker侧完成。
分区副本分配逻辑
既然两种创建topic的方式,其处理逻辑是一样的,那怎么进行扩分区操作后,就不一样了呢?我们再来看下扩分区的处理逻辑。其流程其实和创建topic是一样的,先获取集群所有broker的信息,然后对新增的分区进行broker的分配,最后将完整信息写入zookeeper,broker的controller监听感知信息的变化后,向对应的broker节点发送请求完成分区的新增动作。
值得注意的是:这里对新增分区进行broker分配时,与创建topic时分区的broker分配,调用的是同一个方法:AdminUtils的assignReplicasToBrokers方法,我们来仔细分析下这个函数。
go
private def assignReplicasToBrokersRackUnaware(
// 需要分配的分区个数
nPartitions: Int,
// 副本因子
replicationFactor: Int,
// 集群broker列表
brokerList: Seq[Int],
// 分配的起始ID
fixedStartIndex: Int,
// 起始分区ID
startPartitionId: Int): Map[Int, Seq[Int]] = {
val ret = mutable.Map[Int, Seq[Int]]()
val brokerArray = brokerList.toArray
// 如果起始ID非0, 则以传入的为准, 否则从broker集群中随机挑选一个作为起始分配
val startIndex =
if (fixedStartIndex >= 0)
fixedStartIndex
else
rand.nextInt(brokerArray.length)
// 起始分配的分区ID
// 对于创建topic而言, startPartitionId的值为-1, 因此分区是从0开始分配
// 而对于新增分区而言, startPartitionId为当前topic实际分区的个数, 因此已存在的分区是不会再次分配的
var currentPartitionId = math.max(0, startPartitionId)
var nextReplicaShift =
if (fixedStartIndex >= 0)
fixedStartIndex
else
rand.nextInt(brokerArray.length)
// 分区副本分配
for (_ <- 0 until nPartitions) {
if (currentPartitionId > 0 && (currentPartitionId % brokerArray.length == 0))
nextReplicaShift += 1
// 分区首个副本的 brokerID
val firstReplicaIndex = (currentPartitionId + startIndex) % brokerArray.length
val replicaBuffer = mutable.ArrayBuffer(brokerArray(firstReplicaIndex))
for (j <- 0 until replicationFactor - 1)
replicaBuffer += brokerArray(replicaIndex(firstReplicaIndex, nextReplicaShift, j, brokerArray.length))
// 新分区的副本情况
ret.put(currentPartitionId, replicaBuffer)
currentPartitionId += 1
}
ret
}这个函数为了能同时适用于创建topic和新增topic分区,巧妙的利用了fixedStartIndex 和startPartitionId两个参数。
创建topic调用时,fixedStartIndex的值为 -1,即随机挑选一个broker作为起始分配,startPartitionId的值也为-1,因此分区副本是从0开始分配。在分配的时候,随分区的递增,brokerID也进行循环递增,这样可以保证分区副本是尽可能均匀分布在broker中的。
而扩分区调用时,fixedStartIndex为当前topic首个分区副本的brokerID,startPartitionId为当前topic实际分区的个数,这样一来,已经存在的分区不会再次进行分配,即仅对新增的分区进行分配;同时结合fixedStartIndex字段,保证分区分配逻辑是延续创建topic时的分配逻辑,达到分区副本的在broker集群中均衡分布的效果。
举个例子来说明下:在有5个节点的集群中,创建分区数为2、副本因子为1的topic,假设首个分区随机挑选的brokerID为3,那么分区副本的分配结果为:"{0,3},{1,4}";此后将分区数扩到5个,根据上面的代码分析,fixedStartIndex参数的值为3、startPartitionId的值为2,这样,这个函数得到的结果就是"{2,0},{3,1},{4,2}"。
罪魁祸首
从上面的分析来看,逻辑上都没有问题,但为什么就出现了不符合预期的现象呢?通过断点调试分析,我们发现了一个细节。
在用脚本创建topic和扩分区时,assignReplicasToBrokers函数的入参brokerList都是有序排列的

从代码中也可以证实这一点。
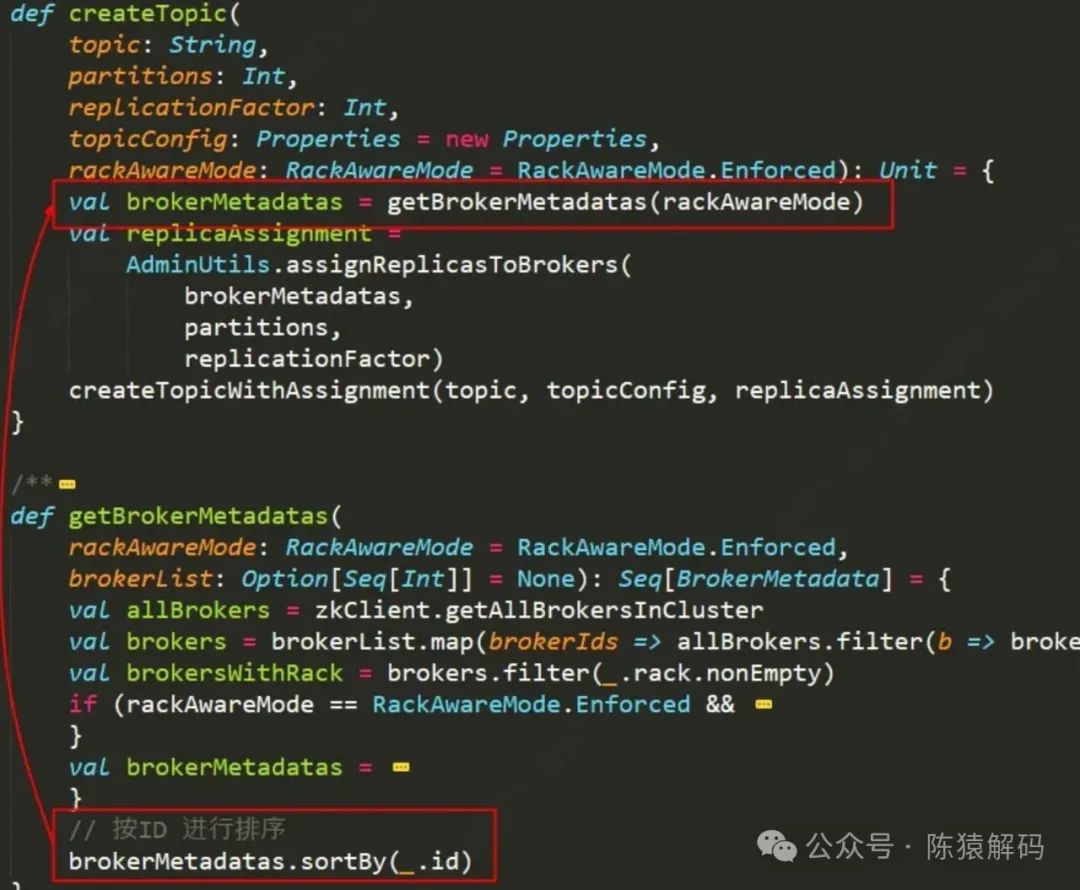
然而,通过接口创建topic时,入参的brokerList是无序的!

这样一来,前后两个操作的顺序不一致也就导致出现了这个问题。
回头再看文章开头的那个图,其实可以看出端倪,通过接口创建的topic的两个分区分布为:
|-----|---------------|
| 分区号 | 副本所在的brokerID |
| 0 | 1 |
| 1 | 0 |
从代码可以反推出,这里传入的broker列表是无序的:1,0,2,扩分区时,fixedStartIndex的值为1,startPartitionId为2,同时这里传入的broker列表又是有序的,即0,1,2,根据分配逻辑取broker数组的第 (1+2)%3=0位,即0,这样分区2就又分配到0号broker上了。
从上面断点的图中可以看到,broker侧在处理创建topic的请求时,brokerList是直接从元数据缓存中获取的,而这个元数据缓存是根据controller来更新的。
从代码逻辑可以分析出:controller被选举出来后首次初始化时触发的元数据更新,无法保证broker的有序,同样,随着broker可能的上下线引起的元数据更新也无法保证broker的有序(这里就不再贴相关的代码了,感兴趣的可以自行看下源码)。
小结
本文通过分析集群扩容,同时对topic进行扩分区操作,新扩的分区没有分布到新的broker节点上这一问题现象进行分析,最后发现是由于创建topic时broker列表没有按ID排序,而扩分区操作时broker列表又是按ID排序,两次操作时的broker列表顺序不一致导致出现该问题。
另外,在分析过程中,我们发现kafka-topics.sh脚本可以是指定--zookeeper参数,或者是--bootstrap-server参数。如果指定--bootstrap-server参数的话,等同于通过调用接口完成相关逻辑,也就是会遇到上面提到的问题。
好了,这就是本文的全部内容,如果觉得本文对您有帮助,请点赞+转发,如果觉得有不正确的地方,欢迎留言交流~