今天需要部署Hadoop开源软件,因为uos仓库里面没有提供Hadoop相关的而rpm包,我准备用官网的rpm包,去部署,在公司内部调研了一圈目前主要是2.7.5,3.1.x两个版本。
1. 集群网络环境规划
集群节点信息:
|-------------|--------------|--------------------|
| 节点名 | IP地址 | 操作系统 |
| hadoop1 | 10.100.20.96 | 统信服务器操作系统V20-1070e |
| hadoop2 | 10.100.20.97 | 统信服务器操作系统V20-1070e |
| hadoop3 | 10.100.20.55 | 统信服务器操作系统V20-1070e |
集群部署规划:
hadoop集群主要分为3个架构HDFS,Yarn,MapReduce。
HDFS:HDFS即分布式文件系统,用于存储数据。HDFS中主要包含3种节点NameNode,DataNode,SecondaryNode。
Yarn:资源管理调度系统,负责对数据运算时进行资源调度。主要负责ResourceManager,NodeManager
MapReduce:并行计算框架,负责进行业务逻辑运算。
本次搭建集群部署规划如下表所示:
Namenode为hadoop1,Secondrynamenode为hadoop3,3台机器均为Datanode。ResourceManager为hadoop2,Nodemanager分布在3台机器上。
建议:Namenode和ResourceManager占用的资源较多,尽量不要放在一台机器上。
|-------------|----------------------------|-----------------------------|
| 节点名 | HDFS | Yarn |
| hadoop1 | Namenode Datanode | Nodemanager |
| hadoop2 | Datanode | ResourceManager Nodemanager |
| hadoop3 | Datanode Secondarynamenode | Nodemanager |
2. 集群环境配置
在三个节点上进行以下环境配置
关闭防火墙和selinux
以下操作在hadoop1,hadoop2,hadoop3三个节点上进行。
关闭防火墙 # systemctl stop firewalld.service && systemctl disable firewalld.service
关闭selinux
setenforce 0
配置hosts
设置主机名:
hostnamectl set-hostname nodename
vim /etc/hosts
10.100.20.96 hadoop1
10.100.20.97 hadoop2
10.100.20.55 hadoop3
配置免密通信
由于hadoop集群启动时会使用ssh指令依次连接对应节点,所以每台机器都要有对应的密钥(自己节点也配置一下)
以hadoop1为例子,在另外两个也要操作
ssh-keygen -t rsa -P ''
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop1
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop2
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop3
时间同步
在文件中添加修改以下内容:
server ntp.aliyun.com iburst

systemctl restart chronyd.service
chronyc sources -v
systemctl enable chronyd.service
如果没有公网,可以同步hadoop1节点
配置JDK
dnf install -y java-1.8.0-openjdk*
配置环境变量
安装完jdk后,我们需要在/etc/profile文件中配置JAVA_HOME。jdk目录一般默认在/usr/lib/jvm下,找到后在/etc/profile文件中添加以下内容
vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.uel20.x86_64
添加完毕后重载文件
source /etc/profile
3. 安装hadoop
安装hadoop-3.1.4
装包只需在一台机器上下载,配置完毕后将整个文件夹分发至其余节点即可。
官网地址:https://hadoop.apache.org/releases.html
本次安装将在/opt目录下进行
mkdir /opt/hadoop
cd /opt/hadoop
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.4/hadoop-3.1.4.tar.gz
解压安装包
tar -zxvf hadoop-3.1.4.tar.gz
配置hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/opt/hadoop/hadoop-3.1.4
export PATH=PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
更新环境变量
source /etc/profile
hadoop-2.7.5
在官网选择hadoop-2.7.5版本下载,下载地址:
http://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/
在一台机器上下载安装包,配置完毕后将整个文件夹分发至其余节点即可。
本次安装将在/opt目录下进行
mkdir /opt/hadoop
cd /opt/hadoop
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
解压安装包
tar -zxvf hadoop-2.7.5.tar.gz
配置环境变量
vim /etc/profile
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.5
export PATH=PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
更新环境变量
source /etc/profile
配置hadoop
配置将在hadoop1主机上进行,配置完毕后将整个文件夹分发至hadoop2,hadoop3即可
创建目录
cd /opt/hadoop/hadoop-3.1.4
mkdir -p data/tmp
mkdir -p hdfs/name
mkdir -p hdfs/data
接下来修改配置文件
cd /opt/hadoop/hadoop-3.1.4/etc/hadoop
如果安装Hadoop-3.1.4配置如下:
vim hadoop-env.sh
在文件中添加
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.uel20.x86_64
修改core-site.xml文件
在文件中的<configuration>添加以下内容
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-3.1.4/data/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
例如我修改的截图:

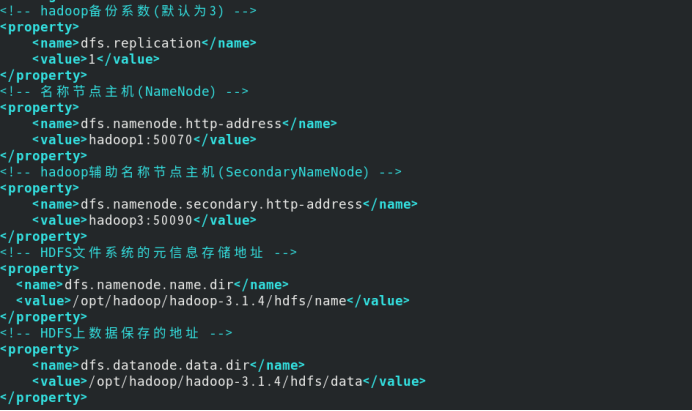
编辑hdfs-site.xml文件
在文件中的<configuration>添加以下内容
<!-- hadoop备份系数(默认为3) -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 名称节点主机(NameNode) -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- hadoop辅助名称节点主机(SecondaryNameNode) -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:50090</value>
</property>
<!-- HDFS文件系统的元信息存储地址 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/hadoop-3.1.4/hdfs/name</value>
</property>
<!-- HDFS上数据保存的地址 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hadoop-3.1.4/hdfs/data</value>
</property>
例如我修改的截图:
编辑mapred-site.xml文件
在文件中的<configuration>添加以下内容
<!-- 指定MapReduce的运行框架,可为local,classic或yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
例如我修改的截图:

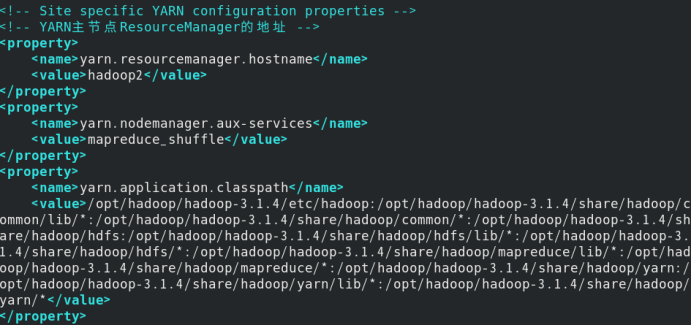
修改yarn-site.xml文件:
hadoop classpath
将输出的内容复制,稍后配置时会使用
/opt/hadoop/hadoop-3.1.4/etc/hadoop:/opt/hadoop/hadoop-3.1.4/share/hadoop/common/lib/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/common/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/hdfs:/opt/hadoop/hadoop-3.1.4/share/hadoop/hdfs/lib/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/hdfs/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/mapreduce/lib/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/mapreduce/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/yarn:/opt/hadoop/hadoop-3.1.4/share/hadoop/yarn/lib/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/yarn/*
编辑# vim yarn-site.xml
在文件中的<configuration>添加以下内容
<!-- YARN主节点ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/hadoop/hadoop-3.1.4/etc/hadoop:/opt/hadoop/hadoop-3.1.4/share/hadoop/common/lib/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/common/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/hdfs:/opt/hadoop/hadoop-3.1.4/share/hadoop/hdfs/lib/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/hdfs/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/mapreduce/lib/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/mapreduce/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/yarn:/opt/hadoop/hadoop-3.1.4/share/hadoop/yarn/lib/*:/opt/hadoop/hadoop-3.1.4/share/hadoop/yarn/*</value>
</property>
例如我修改的截图:
修改workers
vim workers
删除原有的localhost,根据集群部署规划添加工作节点主机名。
本环境为hadoop1,hadoop2,hadoop3
配置start-dfs.sh和stop-dfs.sh脚本
这2个文件在/opt/hadoop/hadoop-3.1.4/sbin目录下
cd /opt/hadoop/hadoop-3.1.4/sbin
在文件头部中添加以下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
例如我修改的截图:

配置start-yarn.sh和stop-yarn.sh脚本
这2个文件在/opt/hadoop/hadoop-3.1.4/sbin目录下
cd /opt/hadoop/hadoop-3.1.4/sbin
在文件中添加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
例如我修改的截图:

4. 启动hadoop集群
首次启动集群需要格式化Namenode节点,本操作只需在hadoop1(即规划的namenode)上进行
hadoop namenode -format
由于本环境搭建的hadoop集群的Namenode与ResourceManager分布在2个不同的主机上,所以无法一次性启动所有集群,需要分别在hadoop1上启动HDFS集群,hadoop2上启动Yarn集群
在hadoop1节点上执行:
start-dfs.sh
在hadoop2节点上执行:
start-yarn.sh
输入jps可以查看当前运行的服务
在hadoop1节点上可以看到:

在hadoop2节点上可以看到:

在hadoop3节点上可以看到:

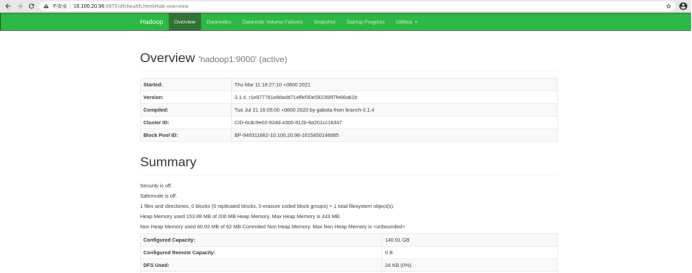
查看web端
查看HDFS页面,浏览器输入访问http://10.100.20.96:9870
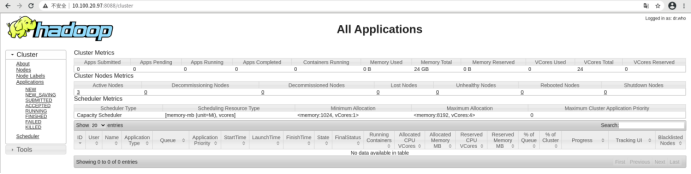
查看Yarn页面,浏览器输入访问http://10.100.20.97:8088
查看Secondarynamenode页面,浏览器输入访问http://10.100.20.55:50090界面
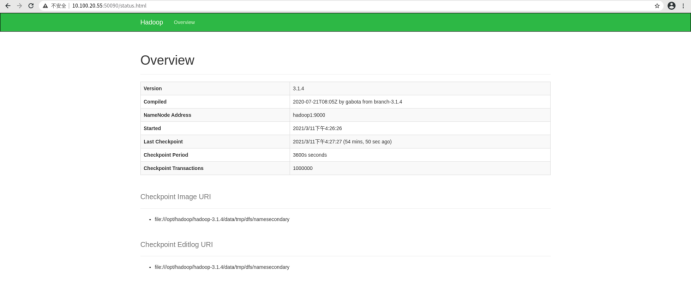
注意:
如果打开该页面无信息

在配置的secondarynamenode节点上进行以下操作:
进入以下路径:
#cd /opt/hadoop/hadoop-3.1.4/share/hadoop/hdfs/webapps/static
#vim dfs-dust.js
修改dfs-dust.js的第61行

修改函数返回值为以下内容
new Date(Number(v)).toLocaleString()

修改完成后清理浏览器缓存然后刷新即可得到正确页面,我记得centos的环境好像就不需要。
测试验证一下hadoop啦
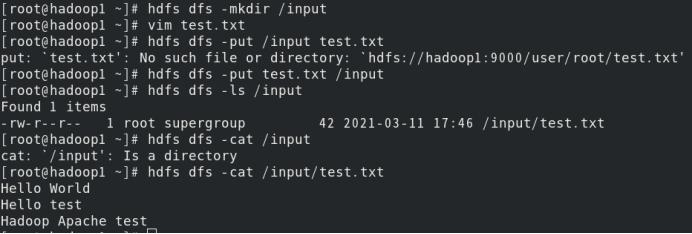
首先在hdfs上新建一个文件夹
hdfs dfs -mkdir /input
然后新建一个测试用txt文件,输入内容如下(可自定义)
vim test.txt
Hello World
Hello test
Hadoop Apache test
将该文件上传至hdfs中
hdfs dfs -put test.txt /input
hdfs dfs -ls /input
hdfs dfs -cat /input/test.txt
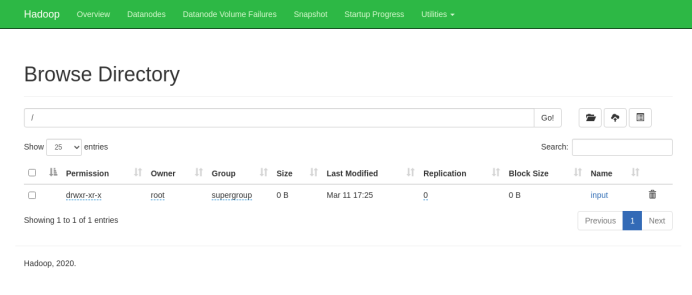
在hdfs web端查看该文件,在web端点击Utilities中的Browse the file system,点击input可以看到test.txt
接下来运行一个wordcount案例进行测试
在/opt/hadoop/hadoop-3.1.4/share/hadoop/mapreduce目录下有wordcount测试用例
在该目录下执行以下指令
hadoop jar hadoop-mapreduce-examples-3.1.4.jar wordcount /input /output
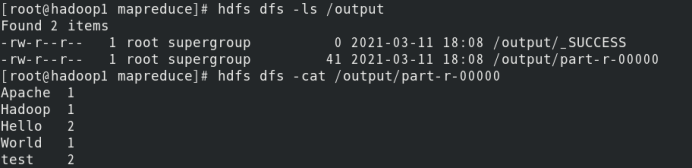
查看运行结果
hdfs dfs -ls /output
hdfs dfs -cat /output/part-r-00000
搭建和验证完成啦,大数据hadoop的配置和OpenStack真的不一个量级~