文章目录
存储引擎
MySQL的体系结构
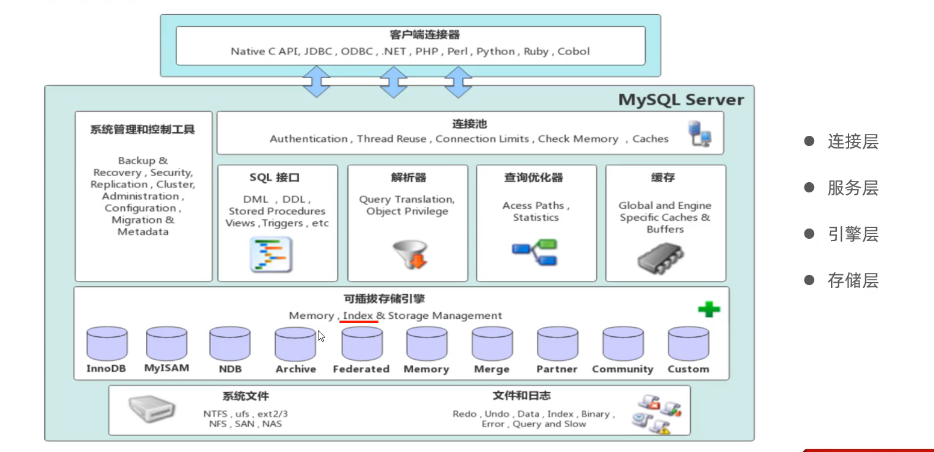
- 连接层
最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证及相关的安全方案。服务器也会为安全接入的每个客户端验证它所具有的操作权限。 - 服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。 - 引擎层
存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。 - 存储层
主要是将数据存储在文件系统之上,并完成与存储引擎的交互。
存储引擎概念
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型
-
在创建表时,指定存储引擎
mysqlCREATE TABLE 表名( 字段1 字段1类型[COMMENT 字段1注释], ... 字段n 字段n类型[COMMENT 字段n注释] )ENGINE = INNODB [COMMENT 表注释|; -
查看当前数据库支持的存储引擎
SHOW ENGINES;
存储引擎特点
InnoDB
-
介绍
InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在 MySQL5.5之后,InnoDB是默认的 MySQL 存储引擎。
-
特点
DML操作遵循ACID模型,支持事务
行级锁 ,提高并发访问性能;支持外键 FOREIGN KEY约束,保证数据的完整性和正确性;
-
文件
xxx.ibd:xx代表的是表名,InnoDB 引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引。
参数:innodb_file_per_table
-
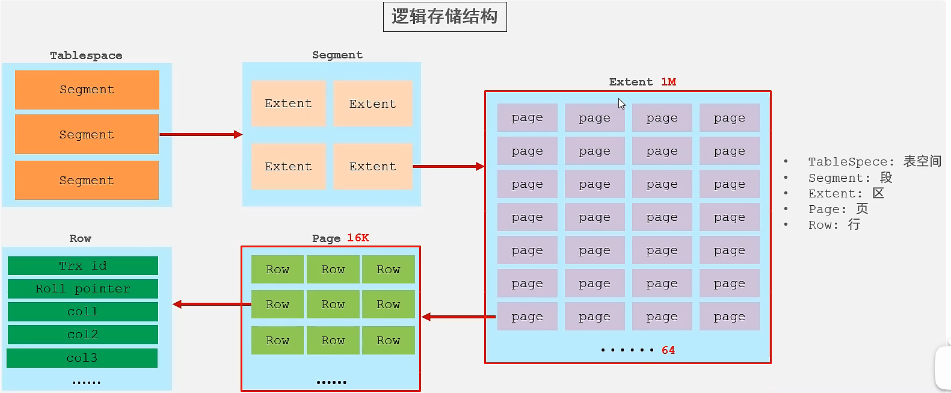
逻辑结构
MyISAM
- 介绍
MyISAM是MySOL早期的默认存储引擎。 - 特点
不支持事务,不支持外键
支持表锁,不支持行锁
访问速度快 - 文件
xxx.sdi:存储表结构信息
xxx.MYD:存储数据
xxx.MYI:存储索引
Memory
- 介绍
Memory引擎的表数据时存储在内存中的,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用。 - 特点
内存存放(速度快)
hash索引(默认) - 文件
xxx.sdi:存储表结构信息
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | 支持 | 支持 |
| 全文索引 | 支持(5.6版本之后) | - | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
存储引擎选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
- InnoDB:是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
- MyISAM: 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。(现在使用较少,被MongoDB替代)
- MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。(现在使用较少,被Redis替代)
索引
概述
- 介绍
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引------可以类比二叉搜索树 - 优缺点
- 优势
- 提高数据检索的效率,降低数据库的成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
- 劣势
- 索引列也是要占用空间的(硬盘价格低,可忽略)
- 索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT、UPDATE、DELETE时,效率降低(增删改占的比例小,可忽略)
- 优势
结构
MySOL的索引是在存储引擎层实现的,不同的存储引警有不同的结构,主要包含以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持 B+树索引 |
| Hash索引 | 底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效, 不支持范围查询 |
| R-tree(空间索引) | 空间索引是MVISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,FS |
注:一般说索引都是默认B+Tree索引
B Tree(多路平衡查找树)
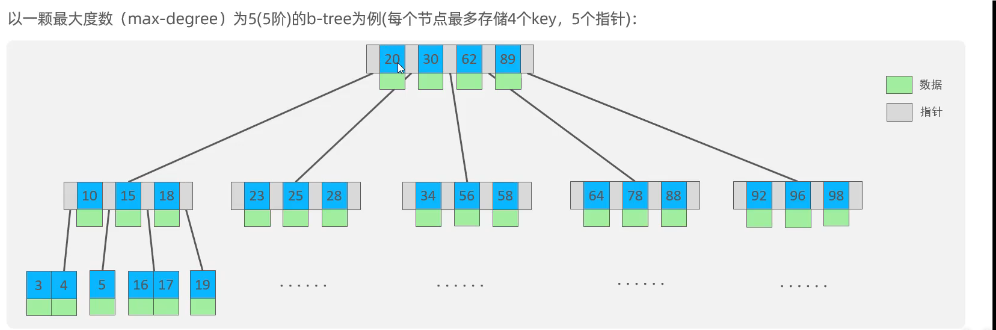
B树插入新节点的过程可以概括为以下几个步骤:
- 查找插入位置 :
- 从根节点开始搜索,找到叶子节点中键值应该放置的位置。
- 在搜索过程中,如果遇到一个节点已满(包含的键的数量等于最大度数减1),则需要考虑后续可能的节点分裂。
- 插入键 :
- 在找到的叶子节点适当的位置插入新的键。
- 如果该叶子节点未满,则直接插入,操作完成。
- 节点分裂 :
- 如果插入后叶子节点中的键数量超过了最大值(即节点已满),那么需要对该节点进行分裂。
- 分裂过程是将节点分为两个节点,并将中间的键提升到父节点。
- 如果父节点也满了,则重复分裂过程,直至根节点。
- 如果根节点分裂,则会创建一个新的根节点,使得树的高度增加1。
- 更新路径 :
- 每当一个节点分裂时,它的父节点会被更新以反映这个变化。
- 如果分裂涉及到根节点,树的高度将会增加。
B+ Tree
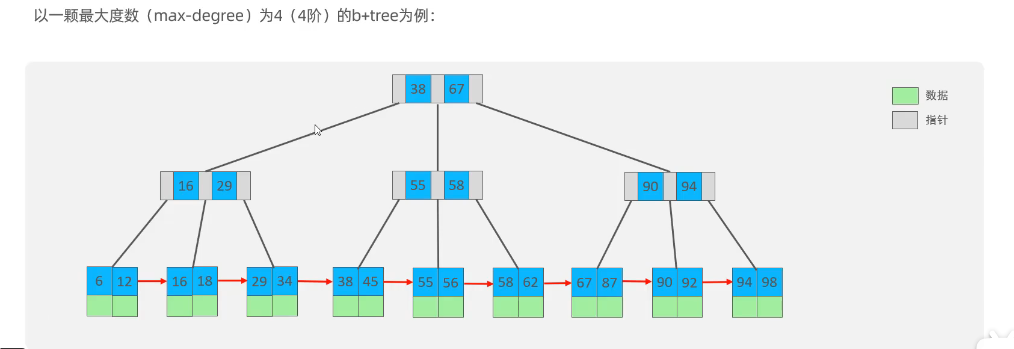
相对于B-Tree区别:
- 所有的数据都会出现在叶子节点
- 叶子节点形成一个单向链表
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能(注:上面的节点只起到索引作用,带绿色的部分才存放数据)
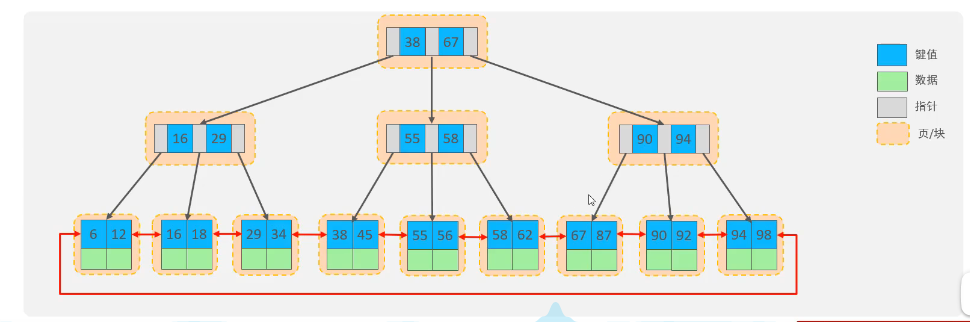
Hash
-
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决
-
Hash索引特点
-
Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,<,...)
-
无法利用索引完成排序操作
-
查询效率高,通常(不发生哈希碰撞)只需要一次检索就可以了,效率通常(不发生哈希碰撞)要高于B+tree索引
-
-
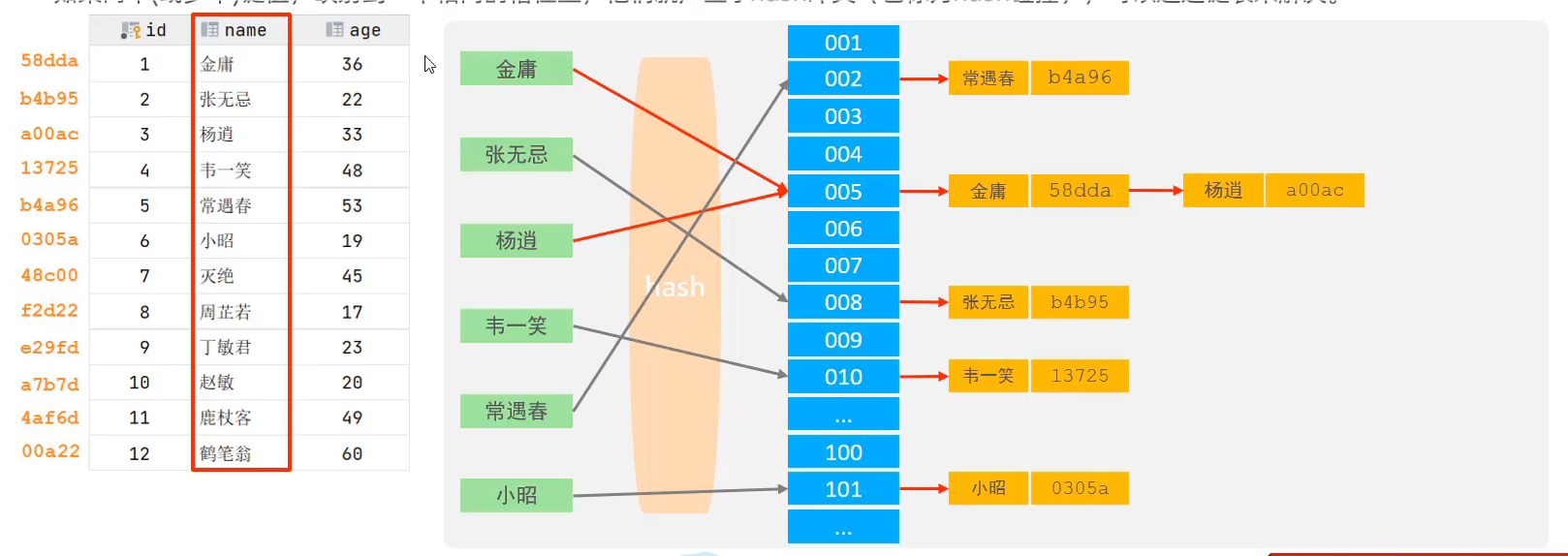
存储引擎支持
在MySQL中,支持hash索引的是Memory引擎,而innoDB中具有自适应hash功能,hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的。
为什么InnoDB存储引擎选择使用B+tree索引结构?
- 相对于二叉树,层级更少,搜索效率高
- 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低
- 相对Hash索引,B+tree支持范围匹配及排序操作
分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | |
| 常规索引 | 快速定位特定数据 | 可以有多个 | UNIQUE |
| 全文索引(少用) | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
在InnoDB存储引擎 中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(ClusteredIndex) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了整行数据 | 必须有,而且只有一个 |
| 二级索引(SecondaryIndex) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引
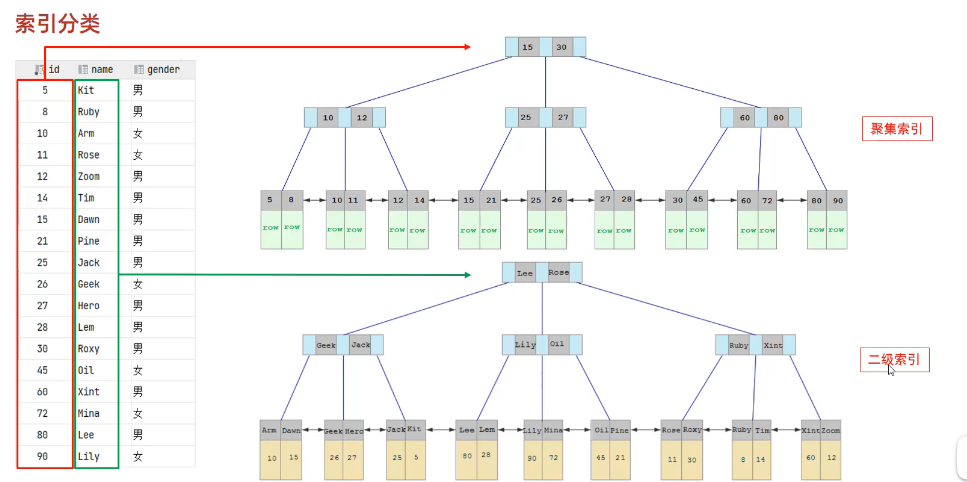
由图可以,聚集索引存放的数据是整行的数据,而二级索引存放的是主键
若输入语句select * from user where name ='Amm',则先从二级索引顺序找到Amm,得到对应的主键号码。再去聚集索引出找到对应的主键号码,获取到这一行的数据。这一过程叫回表查询
思考题
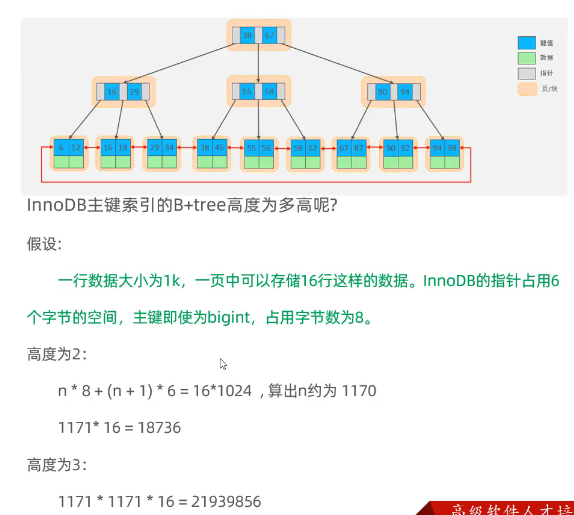
上图中,n为主键个数,n+1为指针的个数,n*8 + (n+1)*6 计算每一个节点 总共占用的字节数,一个节点即为一页/块。计算出主键个数为1170,即子节点的数量为1170个,则指针个数为1170 + 1 = 1171**(注意此时树的高度为2,不是图片里的情况)**。每个指针对应一个实际存储数据的页,一页可以存储16行数据,则一共可以存储1171*16=18736个主键,即18736行数据
树的高度为3时,根节点下有1171个指针,1171个指针对应的节点下又有1171个指针,所以一共可以存储1171*1171*16个主键
在一个非叶节点中:
- 每个键将该节点的子节点分隔开。例如,假设一个非叶节点有 n 个键,则这些键将该节点分为 n+1 个区域,每个区域对应一个子节点。
- 因此,对于 n 个键,需要 n+1 个指针来指向 n+1 个子节点。
在叶节点中:
- 叶节点同样存储键,并且还存储指向实际数据记录的指针。
- 对于 n 个键,叶节点通常会有 n 个指向数据记录的指针。
- 另外,叶节点通常还包括指向相邻叶节点的指针,以便进行范围查询。这意味着除了指向数据记录的 n 个指针之外,还有额外的一个或两个指针用于链接其他叶节点。
无论是非叶节点还是叶节点,指针数量总是比键的数量多一个
语法
-
创建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON tablename (index_col name , ...) ;没有加UNIQUE|FULLTEXT就是默认常规索引
tablename 为表名,(index_col name , ...) 为需要创建索引的字段
默认用B+ Tree 结构
-
查看索引
SHOW INDEX FROM tablename ; -
删除索引
DROP INDEX index_name ON tablename
SQL性能分析(索引相关)
SQL执行频率
MySOL客户端连接成功后,通过show [session | global] status命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
SHOW GLOBAL STATUS LIKE 'Com_______;(7个下划线)、
结果如下,重点关注几个方面即可:
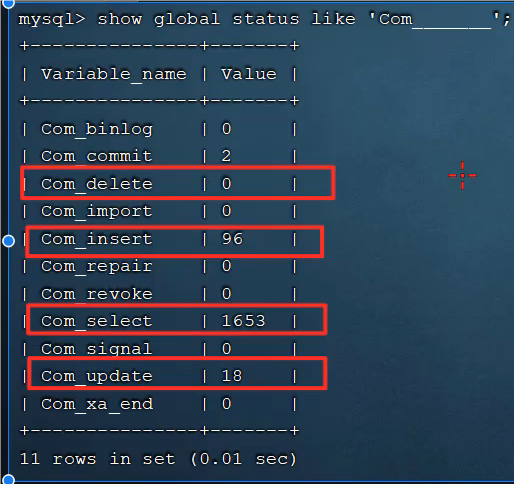
若select查询占绝大部分,则需要优化
慢查询日志
慢查询日志记录了所有执行时间超过指定参数 (long_query_time,单位:秒,默认10秒) 的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,需要在MySOL的配置文件 (/etc/my.cnf) 中配置如下信息:
mysql
# 开启MySOL慢日志查询开关
slow query log=1;
# 设置慢日志的时间为2秒,SOL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long query time=2;配置完毕之后,通过以下指令重新启动MSOL服务器进行测试,查看慢日志文件中记录的信息/var/lib/mysql/localhost-slow.log
如果查询到某条SQL语句执行较慢,就要针对该语句进行优化
profile 详情
-
show profiles 能够在做SQL优化时帮助我们了解时间 都耗费到哪里去了。通过have_profiling参数,能够看到当前MySQL是否支持profile操作:
SELECT @@have_profiling; -
默认profiling是关闭的,可以通过set语句在 session/global 级别开启 profiling:
SET profiling = 1; -
执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
mysql#查看每一条S0L的耗时基本情况 show profiles; #查看指定query id的5QL语句各个阶段的耗时情况 show profile for query query_id; #查看指定query id的SQL语句CPU的使用情况 show profile cpu for query query_id;
explain 执行计划
EXPLAIN 或者 DESC 命令获取 MySOL如何执行 SELECT语句的信息,包括在 SELECT语句执行过程中表如何连接和连接的顺序。
语法:
mysql
# 直接在select语句之前加上关键字 explain/deso
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件;EXPLAIN 执行计划各字段含义:
-
Id
select查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行)。
-
select_type(一般不关注)
表示 SELECT的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等
-
type
表示连接类型,性能由好到差的连接类型为NULL、system、const、eq_ref、ref、range、index、all
- NULL: 这种类型的连接通常表示不需要额外的表来完成连接操作。例如,当一个表通过索引直接访问所有需要的数据时,可以认为是NULL连接。
- System: 当被访问的表是一个系统表(通常非常小,例如只有一行记录)时使用此类型。这种情况下,整个表的内容几乎可以在瞬间读取完毕。
- Const (或 EQ_REF) : 当MySQL对表的访问可以通过一个固定的值或者主键进行时,就会使用Const连接类型。这意味着MySQL只需要查找一次就可以找到所需的行。如果连接涉及到了多个表,并且使用的是主键或者唯一索引,则可能显示为EQ_REF。
- EQ_REF: 类似于Const,但用于非主键的唯一索引。当从其他表获取到的索引值用来访问当前表时,会使用EQ_REF。这通常意味着每个索引值只能返回一行结果。
- REF : 当使用非唯一索引 或者前面的部分键作为参考时,就会使用REF。这意味着连接操作可能会返回多行记录。
- FULLTEXT: 仅用于全文索引的匹配。这是MySQL处理全文搜索的一种特殊方式。
- Index (或 INDEX_MERGE): 当MySQL根据索引信息选择行而无需实际访问表中的数据行时,使用Index类型。Index_MERGE则是在使用多个索引合并的结果来访问数据。
- RANGE: 当访问基于索引的一定范围的记录时使用。例如,当WHERE子句中包含 BETWEEN、<、<=、>、>= 或者 IN 范围操作符时,就可能使用RANGE类型。
- INDEX_SUBQUERY: 在某些情况下,MySQL可以在索引树中解决子查询,而不需要对表进行全表扫描。
- ALL: 当MySQL必须对整个表进行线性扫描,即从头到尾逐一检查每一行以找到匹配的行时,就会使用ALL类型。这是一种效率较低的方法,通常应尽量避免。
-
possible key
显示可能应用在这张表上的索引,一个或多个。
-
Key
实际使用的索引,如果为NULL,则没有使用索引。
-
Key_len
表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好
-
rows
MySQL认为必须要执行查询的行数,在innodb引擎的表中,是一个估计值,可能并不总是准确的。
-
filtered
表示返回结果的行数占需读取行数的百分比,filtered 的值越大越好。
使用规则
验证索引效率
-
在未建立索引之前,执行如下SQL语句,查看SQL的耗时。
mysqlSELECT * FROM tb_sku WHERE sn='100000003145001'; -
针对字段创建索引
mysqlcreate index idx_sku_sn on tb_sku(sn); -
然后再次执行相同的SQL语句,再次查看SOL的耗时。
mysqlSELECT * FROM tb_sku WHERE sn='100000003145001';
最左前缀法则
-
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。
-
如果跳跃某一列,索引将部分失效(后面的字段索引失效)
mysql# 不失效,三个索引都用 explain select * from tb user where profession ='软件工程' and age = 31 and status = '0'; # 不失效,用两个索引 explain select * from tb user where profession='软件工程' and age = 31; # 不失效,用一个索引 explain select * from tb user where profession='软件工程' # 失效,没有最左列 explain select * from tb user where age = 31 and status ='0', # 失效,没有最左列 explain select * from tb user where status = '0'; # 不失效,顺序不影响 explain select * from tb user where age = 31 and status = '0' and profession ='软件工程' ; # 跳跃,只用第一个索引,status不用索引 explain select * from tb user where profession ='软件工程' and status = '0'; -
原因:在数据库中,复合索引是一种包含多个列的索引。例如,一个复合索引可能包含三个列
(A, B, C)。在这种索引中,数据是按照这些列的顺序排序的。具体来说,数据首先根据列A排序;在A相同的情况下,再根据列B排序;如果A和B都相同,则根据列C排序。如果有一个复合索引(A, B, C),并且查询条件是WHERE A = ? AND C = ?,则数据库只能利用索引的第一列(A列)来定位到一部分数据,而对于C列的值,则需要在这一部分数据中进行线性搜索,而不是利用索引来查找。
范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效
mysql
# 失效
explain select * from tb_user where profession= '软件工程' and age > 30 and status = '0';
# 有效,在业务逻辑允许的条件下,尽量加等号
explain select * from tb_user where profession= '软件工程' and age >= 30 and status='0';原因:
- 如果查询条件为
WHERE A > 1 AND B = 2,则在找到满足A > 1的第一行后,无法立即确定是否还需要继续查找以满足B = 2的条件。 - 因为对于给定的
A值,可能存在多个满足B = 2的行,也可能不存在这样的行。因此,数据库管理系统(DBMS)必须继续扫描索引,直到找到所有满足A > 1的行。 - 由于范围查询要求从索引的起始位置开始查找,直到找到满足条件的最后一行,因此即使
B列的值已知,也无法利用这个信息来进一步缩小搜索范围。
索引失效情况
-
索引列运算
不要在索引列上进行(函数)运算操作,索引将失效
mysqlexplain select * from tb_user where substring(phone,10,2) = '15'当查询中包含对索引列的函数运算时,数据库管理系统无法直接利用原始索引来查找结果,原因如下:
- 索引存储的是原始值 :
- 索引中存储的是原始列值,而不是经过函数运算后的值。
- 例如,如果有索引列
A,索引中存储的是列A的原始值,而不是UPPER(A)或LENGTH(A)的结果。
- 函数改变了列的值 :
- 当你在查询中使用函数(如
UPPER()、LENGTH()、SUBSTRING()等)时,实际上是在请求一个基于原始值计算出来的结果。 - 例如,
SELECT * FROM table WHERE UPPER(column) = 'VALUE';这样的查询会查找列column中值为'VALUE'的大写形式。
- 当你在查询中使用函数(如
- 无法直接匹配 :
- 索引中存储的是原始值,因此当查询中包含函数时,数据库无法直接使用索引来查找经过函数运算后的值。
- 例如,如果索引列是
A,查询WHERE UPPER(A) = 'VALUE'无法直接利用索引来查找,因为索引中没有存储UPPER(A)的值。
- 索引查找的局限性 :
- 索引查找只能基于索引中存储的确切值进行,而函数运算改变了索引列的原始值。
- 因此,即使函数的结果可能是唯一的,索引也无法直接帮助查找。
- 索引存储的是原始值 :
-
字符串不加引号
字符串类型字段使用时,不加引号,索引将失效(会发生自动类型转换)
mysql# 不失效 explain select * from tb user where profession = '软件工程' and age = 31 and status = 0; # 失效 explain select *from tb userwhere phone = 17799990015;索引失效:
- 如果字符串值没有用引号括起来,数据库可能会将它解释为一个标识符(如表名或列名),而不是一个字符串值。
- 在这种情况下,数据库无法利用索引来查找相应的值,因为索引是基于确切的字符串值构建的。
-
模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
mysql# 不失效 explain select * from tb user where profession like '软件%'; # 失效 explain select * from tb _user where profession like '%工程'; # 失效 explain select * from tb user where profession like '%工%';尾部模糊匹配
尾部模糊匹配指的是通配符
%出现在模式的末尾,例如WHERE column LIKE 'pattern%'。这种情况下,索引可以被有效利用,原因如下:- 确定的前缀 :
- 尾部模糊匹配具有一个确定的前缀,即
pattern。 - 索引可以利用这个确定的前缀来定位可能匹配的行。
- 尾部模糊匹配具有一个确定的前缀,即
- 索引的利用 :
- 当使用尾部模糊匹配时,数据库可以使用索引来找到所有以
pattern开头的行。 - 一旦找到了这些行,数据库就可以检查每行的剩余部分是否符合模糊匹配条件。
- 当使用尾部模糊匹配时,数据库可以使用索引来找到所有以
头部模糊匹配
头部模糊匹配指的是通配符
%出现在模式的开头,例如WHERE column LIKE '%pattern'。这种情况下,索引通常失效,原因如下:- 不确定的前缀 :
- 头部模糊匹配没有确定的前缀,这意味着任何以
pattern结尾的行都可能是匹配项。 - 由于没有确定的前缀,索引无法直接定位可能的匹配项。
- 头部模糊匹配没有确定的前缀,这意味着任何以
- 全表扫描 :
- 当使用头部模糊匹配时,数据库无法利用索引来快速定位匹配的行。
- 为了找到所有可能匹配的行,数据库可能需要进行全表扫描,即逐行检查每一行是否符合模糊匹配条件。
- 确定的前缀 :
-
or连接的条件
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
mysqlexplain select * from tb_user where id= 10 or age = 23; explain select * from tb_user where phone='17799990017' or age = 23,当查询中包含
OR分割的条件时,例如WHERE (column1 = value1) OR (column2 = value2),数据库优化器需要考虑如何处理这两种情况:- 有索引的列 :
- 如果
column1上有索引,那么对于column1 = value1的条件,数据库可以利用索引来加速查找。 - 但是,如果
column2没有索引,对于column2 = value2的条件,数据库可能需要进行全表扫描。
- 如果
- 无索引的列 :
- 对于没有索引的
column2,数据库无法利用索引来加速查找。 - 这意味着即使
column1上有索引,数据库优化器也需要考虑column2的条件。
- 对于没有索引的
- 有索引的列 :
-
数据分布影响
如果MySQL评估使用索引比全表更慢(范围大,满足条件的数据多),则不使用索引。
mysqlselect * from tb_user where phone >='17799990005'; select * from tb_user where phone >='17799990015';- 索引的选择性是指索引中不同值的比例。如果一个索引的选择性很高(即大多数值都是唯一的),那么使用这个索引可以大大减少需要扫描的行数。
- 反之,如果索引的选择性很低(即很多行具有相同的索引值),那么使用这个索引可能需要扫描大量的行,这可能会导致性能下降。
- 如果查询条件导致需要检索的数据量很大,例如在使用范围查询时,可能会有很多行满足条件。
- 在这种情况下,即使使用索引,也需要扫描大量行,这可能会比全表扫描更慢。
SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
- use index:(建议MySQL使用)
explain select * from tb_user use index(idx_user_pro) where profession='软件工程' - ignore index:(忽略这个索引)
explain select * from tb_user ignore index(idx_user_pro) where profession='软件工程' - force index:(强制使用这个索引)
explain select * from tb_user force index(idx_user_pro) where profession ='软件工程'
覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到),减少select *
本质:避免回表查询
知识小贴士:
using index condition:查找使用了索引,但是需要回表查询数据
using where; using index:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
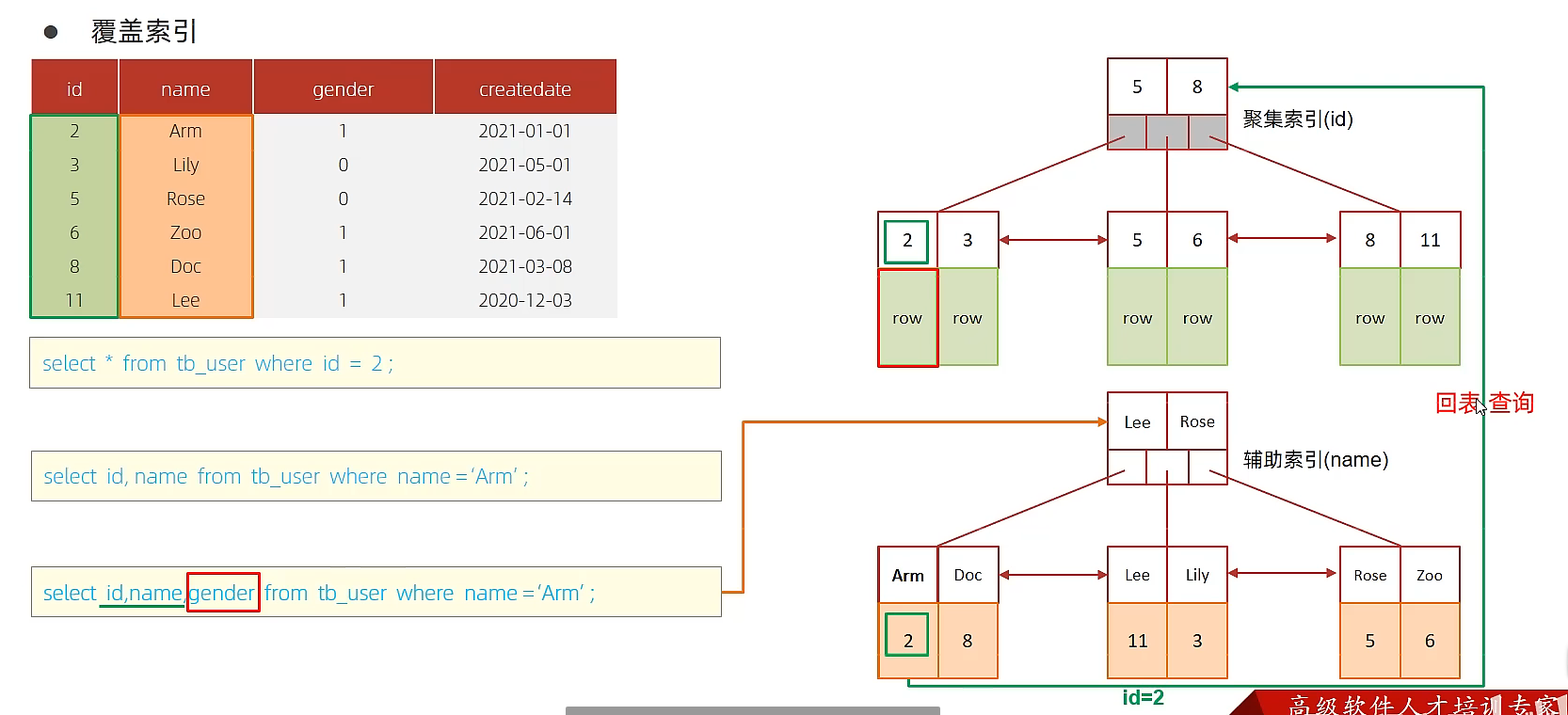
若 name 和 gender 创建了联合索引,在用 name 作为条件查询时,name(Arm)和 gender会被一起查询到,节点中又有 id 的信息,故不需要回表查询
当然,直接用主键 id 查询更方便,因为其使用聚合索引查询,直接得到整行的数据
前缀索引
当字段类型为字符串 (varchar,text等) 时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
-
语法
mysqlcreate index idx_xxxx on table_name(column(n));n 为需要截取的前缀长度
-
前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高
唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的,
mysql# 计算前缀索引选择性,即计算不重复的索引值(基数)和数据表的记录总数的比值 # 不截取,即唯一索引 select count(distinct email) / count(*) from tb_user ; # 截取前五个字符 select count(distinct substring(email,1,5))/ count(*) from tb_user得到索引选择性后,根据数值大小(索引选择性与截取长度的关联情况,如逐渐减少截取长度,观察索引选择性如何减少。平衡两者关系,使截取长度尽可能小,索引选择性尽可能大)和实际情况,确定最终需要截取前多少个字符
-
前缀索引的查询流程
- 查询解析 :
- 当执行包含前缀索引列的查询时,DBMS会解析查询语句,确定查询条件。
- 索引查找 :
- DBMS使用前缀索引中的前缀值来定位可能匹配的行。
- 由于前缀索引只包含列值的一部分,DBMS需要根据这部分前缀值来查找匹配的行。
- 在B+Tree中,查找过程从根节点开始,沿着指针向下查找,直到找到包含匹配前缀的叶子节点。
- 数据验证 :
- 在找到第一个匹配的叶子节点后,DBMS会验证这些行是否真正满足查询条件。
- 由于叶子节点之间相互链接,DBMS可以通过这些链接指针直接移动到下一个叶子节点,而不需要重新从根节点开始查找。
- 结果返回 :
- 一旦验证了所有可能匹配的行,DBMS将返回满足查询条件的实际结果。
- 查询解析 :
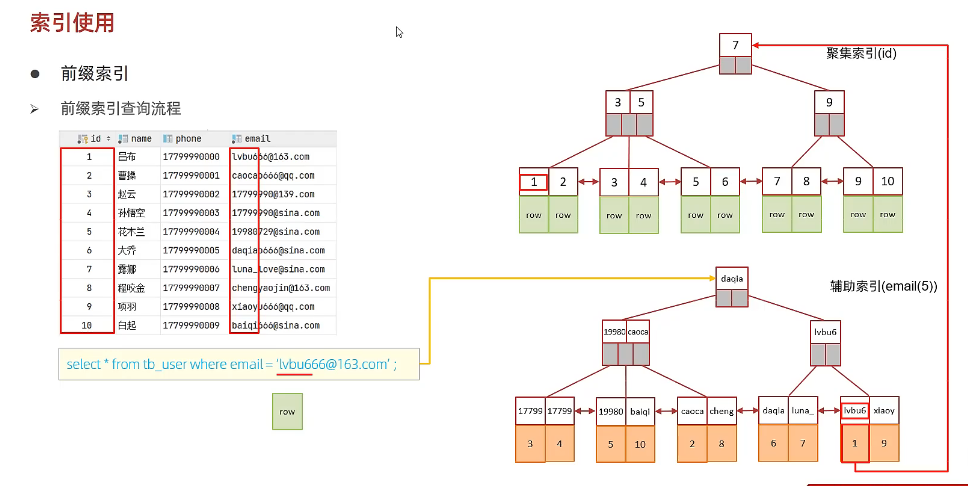
单列索引 & 联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
在业务场景中,如果存在多个查询条件 ,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
原因:避免回表查询
单列索引情况:
mysql
explain select id, phone, name from tb_user where phone = '17799990010'and name ='韩信';多条件联合查询时,MySQL优化器会评估哪个字段的索引效率更高,会选择该索引完成本次查询。
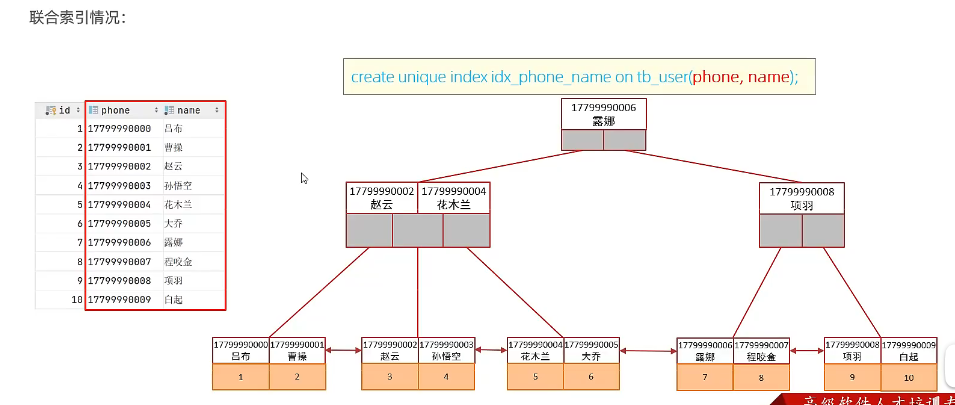
建立联合索引,字段的顺序很重要。如这里是 phone,name ,则根据最左前缀法则,phone 字段必须存在
用联合索引查询数据时,先查phone,phone一样时,再比较name
索引设计原则
- 针对于数据量较大(一般100万以上数据),且查询比较频繁的表建立索引。
- 针对于常作为查询条件(where)、排序(orderby)、分组(group by)操作的字段建立索引。
- 尽量选择区分度高(手机号、身份证号等)的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- 如果索引列不能存储NULL值,请在创建表时使用 NOTNULL 约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
视图
定义和基本语法
视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的(意思是表的数据更新,视图的数据也更新)。
通俗的讲,视图只保存了查询的SQL逻辑(意思是视图给查询表的特定数据提供了一个简单易懂的语句),不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上,。
-
创建
mysqlCREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [WITH[ CASCADED | LOCAL] CHECK OPTION]注:
OR REPLACE子句用于CREATE VIEW语句中,它的作用是在创建视图时,如果该视图已经存在,则会先删除旧的视图,然后再创建新的视图。一般可以统一写上- 这里的 select语句 出来的表,称为基表
-
查询
mysql查看创建视图语句:SHOW CREATE VIEW 视图名称; 查看视图数据:SELECT * FROM 视图名称.....; # 和表的查询操作一致 -
修改
mysql方式一:CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [WITH [CASCADED | LOCAL] CHECK OPTION] #和视图的创建操作一致 方式二:ALTER VIEW 视图名称[(列名列表)] AS SELECT语句 [WITH[CASCADED|LOCAL]CHECK OPTION] -
删除
mysqlDROP VIEW [IF EXISTS] 视图名称 [,视图名称] ...
检查选项
当使用WITH CHECK OPTION子句创建视图时,MySQL会通过视图检查正在更改的每个行,例如 插入,更新,删除,以使其符合视图的定义。MySQL允许基于另一个视图创建视图(方式:from 后跟的不是表,而是视图) ,它还会检查依赖视图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项:CASCADED(级联) 和 LOCAL ,默认值为 CASCADED
当往视图中插入,更新,删除数据时,如果没有加WITH [CASCADED|LOCAL] CHECK OPTION更新的所有 数据会同步到基表中。如果加了,则MySQL会检查是否符合视图查询的条件,如果不满足,则会报错,不会修改视图和表
若参数为CASCADED ,则MySQL会检查这个视图和其依赖的视图(即 from 后的视图)的条件,即使依赖的视图没有加WITH [CASCADED|LOCAL] CHECK OPTION;
若参数为LOCAL ,则MySQL只会检查这个视图的条件,其依赖的视图是否检查,根据依赖的视图是否加WITH [CASCADED|LOCAL] CHECK OPTION判断
视图的更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系(如表中多行对应视图的一行------聚合函数就不行)。如果视图包含以下任何一项,则该视图不可更新:
- 聚合函数或窗口函数(SUM()、MIN()、MAX()、COUNT()等)
- DISTINCT
- GROUP BY
- HAVING
- UNION 或者 UNION ALL
视图的作用
- 简单
视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。 - 安全
数据库可以授权,但不能授权到数据库特定行和特定的列上。通过视图用户只能查询和修改他们所能见到的数据**(DCL只能控制用户看不到哪些表,视图可以控制用户看不到表中的哪些数据)** - 数据独立
视图可帮助用户屏蔽真实表结构变化带来的影响**(如表中原来的 name 字段改成了 student_name 字段,在视图中就可以给 student_name 起别名 name , 使原来的业务逻辑不变)**
存储过程
介绍
存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合 ,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程思想上很简单,就是数据库 SQL语言层面的代码封装与重用。
特点
- 封装,复用
- 可以接收参数,也可以返回数据
- 减少网络交互,效率提升
基本语法
-
创建
mysqlCREATE PROCEDURE 存储过程名称([参数列表]) BEGIN -- SQL语句 END; -
调用
mysqlCALL 名称([ 参数 ]); -
查看
mysqlSELECT * FROM INEORMATION_SCHEMA.ROUIINES WHERE ROUIINE_SCHEMA = 'xx'; -- 查询指定数据库的存储过程及状态信息 SHOW CREATE PROCEDURE 存储过程名称; -- 查询某个存储过程的定义 -
删除
mysqlDROP PROCEDURE [IF EXISTS] 存储过程名称;注意:在命令行中,执行创建存储过程的SQL时,需要通过关键字 delimiter 指定SQL语句的结束符
变量
系统变量
系统变量 是MySQL服务器提供,不是用户定义的,属于服务器层面。分为全局变量(GLOBAL,所有会话有效) 、会话变量(SESSION,当前会话有效)
-
查看系统变量
mysqlSHOW [SESSION | GLOBAL] VARIABLES ; -- 查看所有系统变量 SHOW [SESSION | GLOBAL] VARIABLES LIKE '...'; -- 可以通过LKE模糊匹配方式查找变量 SELECT @@[SESSION|GLOBAL] 系统变量名; -- 查看指定变量的值 -
设置系统变量
mysqlSET [SESSION|GLOBAL] 系统变量名 = 值; SET @@[SESSION|GLOBAL] 系统变量名 = 值;注意:
- 如果没有指定 SESSION/GLOBAL,默认是SESSION,会话变量。
- mysql服务重新启动之后,所设置的全局参数会失效,要想不失效,可以在 /etc/my.cnf 中配置
用户定义变量
用户定义变量 是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用 "@变量名" 使用就可以(系统变量为两个@)。其作用域为当前连接(当前会话)
-
赋值
mysqlSET @var_name = expr [, @var name = expr] ... ; # 可以同时给多个变量赋值 SET @var_name := expr [, @var_name := expr] .... ; # = 和 := 都可以赋值,建议用 := , 方便区分 SELECT @var_name := expr [, @var name := expr] ... ;# 前面也可以写 SELECT SELECT 字段名 INTO @var_name FROM 表名; # 可以将表中得出的值赋给变量 -
使用
mysqlSELECT @var_name ;注意:
用户定义的变量无需对其进行声明或初始化,只不过获取到的值为NULL
局部变量
局部变量 是根据需要定义的在局部生效的变量,访问之前,需要DECLARE声明。可用作存储过程内的局部变量和输入参数,局部变量的范围是在其内声明的BEGIN ... END块。
-
声明
mysqlDECLARE 变量名 变量类型 [DEFAULT...];变量类型就是数据库字段类型:INT、BIGINT、CHAR、VARCHAR、DATE、TIME等
-
赋值
MYSQLSET 变量名 = 值; SET 变量名 := 值; SELECT 字段名 INTO 变量名 FROM 表名;
if 判断
语法:
mysql
IF 条件1 THEN
...
ELSEIF 条件2 THEN -- 可选
...
ELSE
... -- 可选
END IF;参数(IN,OUT,INOUT)
| 类型 | 含义 | 备注 |
|---|---|---|
| IN | 该类参数作为输入,也就是需要调用时传入值 | 默认 |
| OUT | 该类参数作为输出,也就是该参数可以作为返回值 | |
| INOUT | 既可以作为输入参数,也可以作为输出参数 |
用法:
mysql
CREATE PROCEDURE 存储过程名称([IN / OUT / INOUT 参数名 参数类型])
BEGIN
-- SQL语句
END;Case
-
语法一
mysqlCASE case_value WHEN when_value1 THEN statement_list1 [WHEN when_value2 THEN statement_list 2] .. [ELSE statement_list ] END CASE; -
语法二
mysqlCASE WHEN search_conditionl THEN statement_list1 [WHEN search_condition2 THEN statement_list2] ... [ELSE statement_list] END CASE;
循环
while
while 循环是有条件的循环控制语句。满足条件后,再执行循环体中的SQL语句。具体语法为:
mysql
#先判定条件,如果条件为true,则执行逻辑,否则,不执行逻辑
WHILE 条件 DO
-- SQL逻辑
END WHILE;repeat
repeat是有条件的循环控制语句,当满足条件的时候退出循环(注意与while的区别)。具体语法为:
mysql
# 先执行一次逻辑,然后判定逻辑是否满足,如果满足,则退出。如果不满足,则继续下一次循环
REPEAT
SQL逻辑...
UNTIL 条件
END REPEAT;loop
LOOP 实现简单的循环,如果不在SQL逻辑中增加退出循环的条件,可以用其来实现简单的死循环。LOOP可以配合以下两个语句使用:
-
LEAVE:配合循环使用,退出循环。
-
ITERATE:必须用在循环中,作用是跳过当前循环剩下的语句,直接进入下一次循环。
mysql[begin_label:] LOOP # label 为自己设定的标签,begin_label 和 end_label 是同一个,begin_label要加冒号 SQL逻辑.. END Loop [end_label]; LEAVE label; -- 退出指定标记的循环体 ITERATE label; -- 直接进入下一次循环
游标(光标) cursor
游标(CURSOR) 是用来存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结果集进行循环的处理。游标可以被视为一个指向存储在数据库表中的数据行的指针。当执行一个查询时,查询的结果集会被存储在内存中,而游标则允许你按照自己的需求逐行访问这些结果。
游标的使用包括游标的声明、OPEN、FETCH和 CLOSE,其语法分别如下
-
声明游标
mysqlDECLARE 游标名称 CURSOR FOR 查询语句; -
打开游标
mysqlOPEN 游标名称; -
获取游标记录
mysqlFETCH 游标名称 INTO 变量[,变量]; -
关闭游标
mysqlCLOSE 游标名称;
一个使用游标的示例:
假设我们有一个名为 employees 的表,其中包含员工的 id 和 name 字段。我们将创建一个存储过程,该过程会使用游标来遍历这个表中的所有记录,并打印出每个员工的名字。
mysql
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL
);
INSERT INTO employees (name)
VALUES ('Alice'),
('Bob'),
('Charlie');
DELIMITER $$
CREATE PROCEDURE print_employee_names()
BEGIN
-- 声明变量
DECLARE emp_name VARCHAR(50);
-- 声明游标
DECLARE cur CURSOR FOR SELECT name FROM employees;
-- 定义一个处理器来处理没有更多数据的情况
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
-- 初始化一个标志变量
DECLARE done INT DEFAULT FALSE;
-- 打开游标
OPEN cur;
-- 开始循环读取数据
read_loop: LOOP
-- 从游标中获取下一行 注意游标一次只获取了一行的数据
FETCH cur INTO emp_name;
-- 检查是否到达末尾
IF done THEN
LEAVE read_loop;
END IF;
-- 输出员工名字
SELECT CONCAT('Employee name: ', emp_name);
END LOOP;
-- 关闭游标
CLOSE cur;
END$$
DELIMITER ;
CALL print_employee_names();条件处理程序Handler
条件处理程序(Handler) 可以用来定义在流程控制结构执行过程中遇到问题时相应的处理步骤。具体语法为:
mysql
DECLARE handler_action HANDLER FOR condition_value [,condition value] .... statement ;
# 参数选择及其含义:
handler_action # 满足条件后的操作
CONTINUE: 继续执行当前程序
EXIT:终止执行当前程序
condition_value # 需要满足的条件
SQLSTATE sqlstate value: 状态码,如 02000
SQLWARNING: 所有以01开头的 SQLSTATE 代码的简写
NOT FOUND : 所有以02开头的 SQLSTATE 代码的简写
SQLEXCEPTION:所有没有被 SQLWARNING 或 NOT FOUND捕获的 SQLSTATE 代码的简写存储函数
存储函数是有返回值的存储过程 ,存储函数的参数只能是IN类型的。具体语法如下:
mysql
CREATE FUNCTION 存储函数名称([参数列表])
RETURNS type [characteristic ...]
BEGIN
-- SQL语句
RETURN ...;
END;
characteristic说明:
DETERMINISTIC:相同的输入参数总是产生相同的结果
NO SQL:不包含 SQL语句
READS SQL DATA:包含读取数据的语句,但不包含写入数据的语句存储函数用得较少,因为能使用存储函数的地方,都可以使用存储过程
触发器
介绍
触发器是与表有关的数据库对象,指在 insert / update / delete 之前或之后,触发并执行触发器中定义的SQL语句集合(即在插入、更新、删除操作前后执行特定操作) 。触发器的这种特性可以协助应用在数据库端确保数据的完整性,日志记录,数据校验等操作 。
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。现在触发器还只支持行级触发(对于每一条被修改的记录,触发器都会被调用一次 ,适用于需要针对每一行数据执行特定操作的场景,比如记录审计日志、更新统计信息等),不支持语句级触发(无论SQL语句影响了多少行数据,触发器都只会被执行一次,适用于需要在数据更改前后执行一些操作,但不需要针对每一行数据单独处理的情况)
| 触发器类型 | NEW 和 OLD |
|---|---|
| INSERT 型触发器 | NEW 表示将要或者已经新增的数据 |
| UPDATE 型触发器 | OLD 表示修改之前的数据,NEW 表示将要或已经修改后的数据 |
| DELETE型触发器 | OLD 表示将要或者已经删除的数据 |
语法
-
创建
mysqlCREATE TRIGGER trigger_name BEFORE/ AFTER INSERT/ UPDATE / DELETE ON tbl_name FOR EACH ROW -- 行级触发器 BEGIN trigger_stmt ; END; -
查看
mysqlSHOW TRIGGERS; -
删除
mysqlDROP TRIGGER [schema_name.]trigger_name; -- 如果没有指定 schema_name,默认为当前数据库
示例
INSERT 触发器
mysql
# 创建一个 BEFORE INSERT 触发器,用于在向 employees 表中插入新记录之前验证薪资是否大于 0
DELIMITER $$
CREATE TRIGGER validate_salary_before_insert
BEFORE INSERT ON employees
FOR EACH ROW
BEGIN
IF NEW.salary <= 0 THEN
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Salary must be greater than zero.';
END IF;
END$$
DELIMITER ;UPDATE 触发器
mysql
# 创建一个 AFTER UPDATE 触发器,用于在更新 employees 表中的薪资字段时记录审计日志
DELIMITER $$
CREATE TRIGGER log_salary_change
AFTER UPDATE ON employees
FOR EACH ROW
BEGIN
IF OLD.salary <> NEW.salary THEN
INSERT INTO audit_log (action, old_salary, new_salary)
VALUES ('UPDATE', OLD.salary, NEW.salary);
END IF;
END$$
DELIMITER ;DELETE 触发器
mysql
# 创建一个 AFTER DELETE 触发器,用于在从 employees 表中删除记录后更新统计表中的员工计数
CREATE TABLE employee_stats (
total_employees INT DEFAULT 0
);
INSERT INTO employee_stats (total_employees) VALUES (0);
DELIMITER $$
CREATE TRIGGER decrement_employee_count
AFTER DELETE ON employees
BEGIN
UPDATE employee_stats SET total_employees = total_employees - 1;
END$$
DELIMITER ;