tabula-py
tabula-py 是一个将 PDF 表格转换为 pandas DataFrame 的工具。
tabula-py 是 tabula-java 的包装器,需要您的机器上有 java。
tabula-py 还允许您将 PDF 中的表格转换为 CSV/TSV 文件。
tabula-py 的 PDF 提取准确度与 tabula-java 或 tabula app 相同;tabula 的 GUI 工具,因此如果您想知道 tabula-py 的性能,我强烈建议您尝试 tabula app。
tabula-py 适用于:
- 使用 Python 脚本实现自动化
- 转换 pandas DataFrame 后的高级分析
- 使用 Jupyter 笔记本或 Google Colabolatory 进行随意分析
环境和安装
检查 Java 环境并安装 tabula-py
tabula-py 需要 java 环境,因此让我们检查您机器上的 java 环境
!java -versionopenjdk version "11.0.20" 2023-07-18
OpenJDK Runtime Environment (build 11.0.20+8-post-Ubuntu-1ubuntu120.04)
OpenJDK 64-Bit Server VM (build 11.0.20+8-post-Ubuntu-1ubuntu120.04, mixed mode, sharing)
安装bula-py by using pip.!pip install -q tabula-py
在尝试 tabula-py 之前,请通过 tabula-py environment_info() 函数检查您的环境,该函数显示 Python 版本、Java 版本和您的操作系统环境。
import tabula
tabula.environment_info()
Python version: 3.8.10 (default, May 26 2023, 14:05:08) [GCC 9.4.0] Java version: openjdk version "11.0.20" 2023-07-18 OpenJDK Runtime Environment (build 11.0.20+8-post-Ubuntu-1ubuntu120.04) OpenJDK 64-Bit Server VM (build 11.0.20+8-post-Ubuntu-1ubuntu120.04, mixed mode, sharing) tabula-py version: 2.7.1.dev6+gd9154b3 platform: Linux-5.15.90.1-microsoft-standard-WSL2-x86_64-with-glibc2.29 uname: uname_result(system='Linux', node='GARM', release='5.15.90.1-microsoft-standard-WSL2', version='#1 SMP Fri Jan 27 02:56:13 UTC 2023', machine='x86_64', processor='x86_64') linux_distribution: ('Ubuntu', '20.04', 'focal') mac_ver: ('', ('', '', ''), '')
使用
GitHub 仓库链接:LinkedIn
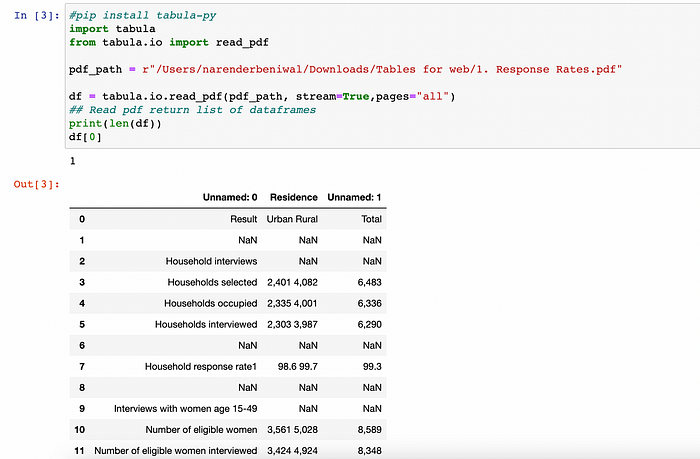
示例代码
ttabula-py 可让您将 PDF 中的表格提取到 DataFrame 或 JSON 中。它还可以从 PDF 中提取表格并将文件保存为 CSV、TSV 或 JSON。
bb
import tabula
# Read pdf into list of DataFrame
dfs = tabula.read_pdf("test.pdf", pages='all')
# Read remote pdf into list of DataFrame
dfs2 = tabula.read_pdf("https://github.com/tabulapdf/tabula-java/raw/master/src/test/resources/technology/tabula/arabic.pdf")
# convert PDF into CSV file
tabula.convert_into("test.pdf", "output.csv", output_format="csv", pages='all')
# convert all PDFs in a directory
tabula.convert_into_by_batch("input_directory", output_format='csv', pages='all')如果我们想读取 pdf 的所有页面怎么办?好吧,你需要做的就是将标志传递pages='all'给 Tabula,如下所示:
bb
dfs = tabula.read_pdf("test.pdf", pages='all')"test.pdf", pages='all')要避免的几个错误:
- 确保你安装了 tabula-py 而不仅仅是 tabula 使用
bb
!pip install tabula-py
#and to import it use
from tabula.io import read_pdf- 如果您在安装 tabula-py 之前意外安装了 tabula,它们会在命名空间中发生冲突(即使在卸载 tabula 之后)。卸载 tabula-py 并重新安装。
最后
很简单,对吧?实际上,你可以向 Tabula 传递很多不同的命令来加快速度,甚至可以提供特定的 XY 坐标进行提取。