代码来自:lit-llama
modelscope模型下载 :llama-7b
下载后的模型需要转换为lit-llama使用的格式,详见 howto 文件夹下的 download_weights.md
文中代码为了方便说明,删减了一些内容,详细代码请查看源码。
generate
输入参数:
- idx: 输入的prompt经过 tokenizer encode之后输出的序列tensor.使用了默认的输入,token长度为6。
- max_new_tokens: 每次新生成的最大token数
- max_seq_length: 输入的序列最大长度.
- temperature: 温度越高,结果越多样性;温度越低,确定性越高。
- top_k: 默认为200。topk越大,结果越多样性;topk越小,结果确定性越高。
python
@torch.no_grad()
def generate(
model: LLaMA,
idx: torch.Tensor,
max_new_tokens: int,
*,
max_seq_length: Optional[int] = None,
temperature: float = 1.0,
top_k: Optional[int] = None,
eos_id: Optional[int] = None,
) -> torch.Tensor:
# create an empty tensor of the expected final shape and fill in the current tokens
T = idx.size(0)
T_new = T + max_new_tokens
if max_seq_length is None:
max_seq_length = min(T_new, model.config.block_size)
device, dtype = idx.device, idx.dtype
# 创建了一个空的tensor,包括输入的idx,加上允许生成的最大tokens 数,定义了最终结果变量
empty = torch.empty(T_new, dtype=dtype, device=device)
empty[:T] = idx
idx = empty
input_pos = torch.arange(0, T, device=device) #指明输入的数据在idx中的pos。
# generate max_new_tokens tokens
for _ in range(max_new_tokens):
x = idx.index_select(0, input_pos).view(1, -1) #在结果变量idx中使用input_pos 取出当前输入。
# forward
logits = model(x, max_seq_length, input_pos) #(1,seq,32000)
logits = logits[0, -1] / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits = torch.where(logits < v[[-1]], -float("Inf"), logits)
probs = torch.nn.functional.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1).to(dtype=dtype) #多项式采样
# advance
input_pos = input_pos[-1:] + 1,#下一个输入的pos
# concatenate the new generation
idx = idx.index_copy(0, input_pos, idx_next) #把生成结果copy到结果变量中
# if <eos> token is triggered, return the output (stop generation)
if idx_next == eos_id:
return idx[:input_pos] # include the EOS token
return idxLLAMA Model
使用默认配置,7B模型。block_size 定义了rope和mask的大小,自然也限制了最大输入长度,超过了block_size的输入,无法取得位置编码和mask。
python
@dataclass
class LLaMAConfig:
block_size: int = 2048
vocab_size: int = 32000
padded_vocab_size: Optional[int] = None
n_layer: int = 32
n_head: int = 32
n_embd: int = 4096
def __post_init__(self):
if self.padded_vocab_size is None:
self.padded_vocab_size = find_multiple(self.vocab_size, 64)
@classmethod
def from_name(cls, name: str) -> Self:
return cls(**llama_configs[name])
llama_configs = {
"7B": dict(n_layer=32, n_head=32, n_embd=4096),
"13B": dict(n_layer=40, n_head=40, n_embd=5120),
"30B": dict(n_layer=60, n_head=52, n_embd=6656),
"65B": dict(n_layer=80, n_head=64, n_embd=8192),
}LLaMA模型主要有多层attention模块构成。
预测第一个token的时候,需要创建 build_rope_cache 和 build_mask_cache,以及 kv_caches。
然后从rope_cache 和mask_cache 根据 input_pos 取出对应位置的值。
kv_caches 即 缓存模型中所有层的kv值,7B有32层,则 kv_caches 的长度为32.
kv的shape为(B, self.config.n_head, max_seq_length, head_size),使用torch.zeros 初始化。
逐层运行,并将每层的kv值保存在kv_caches 中。
这里每次输入的长度肯定是小于max_seq_length,也就是只更新相应index的kv_caches中的值。
最后经过RMSNorm后,经过线性层,输出每个vocab的概率.
python
class LLaMA(nn.Module):
def __init__(self, config: LLaMAConfig) -> None:
super().__init__()
assert config.padded_vocab_size is not None
self.config = config
self.lm_head = nn.Linear(config.n_embd, config.padded_vocab_size, bias=False)
self.transformer = nn.ModuleDict(
dict(
wte=nn.Embedding(config.padded_vocab_size, config.n_embd),
h=nn.ModuleList(Block(config) for _ in range(config.n_layer)),
ln_f=RMSNorm(config.n_embd),
)
)
self.rope_cache: Optional[RoPECache] = None
self.mask_cache: Optional[MaskCache] = None
self.kv_caches: List[KVCache] = []
def forward(
self, idx: torch.Tensor, max_seq_length: Optional[int] = None, input_pos: Optional[torch.Tensor] = None
) -> Union[torch.Tensor, Tuple[torch.Tensor, List[KVCache]]]:
B, T = idx.size()
block_size = self.config.block_size
if max_seq_length is None:
max_seq_length = block_size
assert T <= max_seq_length, f"Cannot forward sequence of length {T}, max seq length is only {max_seq_length}"
assert max_seq_length <= block_size, f"Cannot attend to {max_seq_length}, block size is only {block_size}"
assert T <= block_size, f"Cannot forward sequence of length {T}, block size is only {block_size}"
if self.rope_cache is None:
self.rope_cache = self.build_rope_cache(idx)
if self.mask_cache is None:
self.mask_cache = self.build_mask_cache(idx)
#从rope_cache 和 mask_cache 取出对应位置的rope和mask
if input_pos is not None:
rope = self.rope_cache.index_select(0, input_pos) #(6,64,2),(1,64,2)
mask = self.mask_cache.index_select(2, input_pos) #(1,1,6,2048),(1,1,1,2048)
mask = mask[:, :, :, :max_seq_length] #1,1,6,56),(1,1,1,56)
else:#未给出input_pos,则根据输入长度
rope = self.rope_cache[:T]
mask = self.mask_cache[:, :, :T, :T]
# embeddings
x = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd) #(1,1,4096)
if input_pos is None: # proxy for use_cache=False
for block in self.transformer.h:
x, _ = block(x, rope, mask, max_seq_length)
else:
if not self.kv_caches: #创建kv_caches
head_size = self.config.n_embd // self.config.n_head #128
cache_shape = (B, self.config.n_head, max_seq_length, head_size) #(1,32,56,128)
self.kv_caches = [
(torch.zeros(cache_shape, device=x.device, dtype=x.dtype), torch.zeros(cache_shape, device=x.device, dtype=x.dtype))
for _ in range(self.config.n_layer)
]
for i, block in enumerate(self.transformer.h):
x, self.kv_caches[i] = block(x, rope, mask, max_seq_length, input_pos, self.kv_caches[i])
#RMSNorm
x = self.transformer.ln_f(x) #(1,6,4096)
logits = self.lm_head(x) # (b, t, vocab_size) (1,6,32000)
return logits
def build_rope_cache(self, idx: torch.Tensor) -> RoPECache:
return build_rope_cache(
seq_len=self.config.block_size,
n_elem=self.config.n_embd // self.config.n_head,
dtype=idx.dtype,
device=idx.device,
)
# mask_cache 的shape为 (block_size,block_size),右上角为False。
def build_mask_cache(self, idx: torch.Tensor) -> MaskCache:
ones = torch.ones((self.config.block_size, self.config.block_size), device=idx.device, dtype=torch.bool)
return torch.tril(ones).unsqueeze(0).unsqueeze(0)build_rope_cache
rope 按照下面的计算方法计算,有很多的shape转换,可以使用较小的维度对照公式逐步查看。
参考:一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long(含NTK-aware简介)
rope_cache 的shape为 (2048,64,2),2048是模型定义的block_size,64 为 attention中每个head 的dim 再除以2。
旋转角度计算公式

python
def build_rope_cache( #2048,128=4096/32
seq_len: int, n_elem: int, dtype: torch.dtype, device: torch.device, base: int = 10000
) -> RoPECache:
# 上面的角度计算公式,2(i-1),i从1到d/2,就等于torch.arange(0, d, 2)
theta = 1.0 / (base ** (torch.arange(0, n_elem, 2, dtype=dtype, device=device) / n_elem)) #(64)
# Create position indexes `[0, 1, ..., seq_len - 1]`
seq_idx = torch.arange(seq_len, dtype=dtype, device=device) #(2048)
# Calculate the product of position index and $\theta_i$
#每个角度都乘以index
idx_theta = torch.outer(seq_idx, theta).float() #(2048,64)
cache = torch.stack([torch.cos(idx_theta), torch.sin(idx_theta)], dim=-1) #(2048,64,2)
# this is to mimic the behaviour of complex32, else we will get different results
if dtype in (torch.float16, torch.bfloat16, torch.int8):
cache = cache.half()
return cache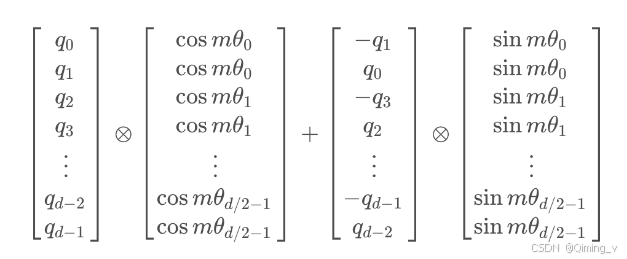
在attention中,只有q和k需要添加位置信息,按照上图来计算。
python
def apply_rope(x: torch.Tensor, rope_cache: RoPECache) -> torch.Tensor:
# truncate to support variable sizes
T = x.size(1) #(1,6,32,128)
rope_cache = rope_cache[:T] #(6,64,2)
# cast because the reference does
xshaped = x.float().reshape(*x.shape[:-1], -1, 2) #(1,6,32,64,2)
rope_cache = rope_cache.view(1, xshaped.size(1), 1, xshaped.size(3), 2) #(1,6,1,64,2)
x_out2 = torch.stack(
[
xshaped[..., 0] * rope_cache[..., 0] - xshaped[..., 1] * rope_cache[..., 1],
xshaped[..., 1] * rope_cache[..., 0] + xshaped[..., 0] * rope_cache[..., 1],
],
-1,
) #(1,6,32,64,2)
x_out2 = x_out2.flatten(3) #(1,6,32,128)
return x_out2.type_as(x)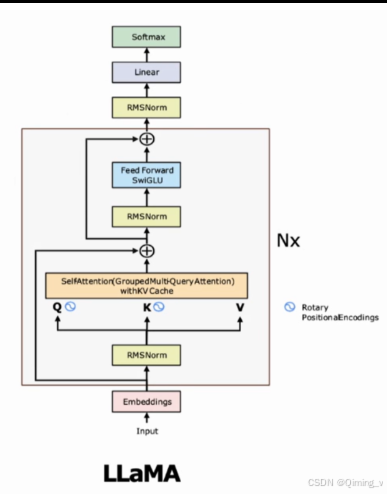
图片是llama2的结构图,llama1并没有使用GQA,其他结构是一样的。
先RMSNorm,再attention,残差相加,然后再RMSNorm,MLP,再次残差相加。
python
class Block(nn.Module):
def __init__(self, config: LLaMAConfig) -> None:
super().__init__()
self.rms_1 = RMSNorm(config.n_embd)
self.attn = CausalSelfAttention(config)
self.rms_2 = RMSNorm(config.n_embd)
self.mlp = MLP(config)
def forward(
self,
x: torch.Tensor,
rope: RoPECache,
mask: MaskCache,
max_seq_length: int,
input_pos: Optional[torch.Tensor] = None,
kv_cache: Optional[KVCache] = None,
) -> Tuple[torch.Tensor, Optional[KVCache]]:
h, new_kv_cache = self.attn(self.rms_1(x), rope, mask, max_seq_length, input_pos, kv_cache)
x = x + h
x = x + self.mlp(self.rms_2(x))
return x, new_kv_cache在attention部分中,q和k添加了rope。
使用了kv_cache,kv_cache的初始值都是 0,这里就需要把计算出的k 和 v copy到 kv_cache中对应的index位置。
在generate的for循环中,第一次输入全部的prompt,假设长度为 6;第二次只输入生成的token,长度为1,也就是说第二次以后,每次的x size都是(1,1,4096),因为之前的kv值都已经存在kv_cache中了。
如果input_pos >= max_seq_length,cache_k 和cache_v 就要左移,丢弃最早的kv值。
python
class CausalSelfAttention(nn.Module):
def __init__(self, config: LLaMAConfig) -> None:
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=False)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=False)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.block_size = config.block_size
def forward(
self,
x: torch.Tensor,
rope: RoPECache,
mask: MaskCache,
max_seq_length: int,
input_pos: Optional[torch.Tensor] = None,
kv_cache: Optional[KVCache] = None,
) -> Tuple[torch.Tensor, Optional[KVCache]]:
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd) #(1,6,4096)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2) #(1,6,4096)
head_size = C // self.n_head #128
k = k.view(B, T, self.n_head, head_size) #(1,6,32,128)
q = q.view(B, T, self.n_head, head_size)
v = v.view(B, T, self.n_head, head_size)
q = apply_rope(q, rope)
k = apply_rope(k, rope)
k = k.transpose(1, 2) # (B, nh, T, hs) (1,32,6,128)
q = q.transpose(1, 2) # (B, nh, T, hs)
v = v.transpose(1, 2) # (B, nh, T, hs)
if kv_cache is not None:
cache_k, cache_v = kv_cache #(1,32,56,128),(1,32,56,128)
# check if reached token limit
if input_pos[-1] >= max_seq_length:
input_pos = torch.tensor(max_seq_length - 1, device=input_pos.device)
# 左移,丢弃最早的kv值
cache_k = torch.roll(cache_k, -1, dims=2)
cache_v = torch.roll(cache_v, -1, dims=2)
k = cache_k.index_copy(2, input_pos, k) #(1,32,56,128)
v = cache_v.index_copy(2, input_pos, v) #(1,32,56,128)
kv_cache = k, v
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
# att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
# att = att.masked_fill(mask[:,:,:T,:T] == 0, float('-inf'))
# att = F.softmax(att, dim=-1)
# y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
#这里使用了kv_cache后,kv的shape和q不再相同,
#(1,32,6,128),(1,32,56,128),(1,32,56,128) => (1,32,6,128)
y = F.scaled_dot_product_attention(q, k, v, attn_mask=mask, dropout_p=0.0)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side #(1,6,4096)
# output projection
y = self.c_proj(y)
return y, kv_cacheMLP使用了SwiGLU函数,n_hidden也是个奇怪的数。
Llama改进之------SwiGLU激活函数
python
class MLP(nn.Module):
def __init__(self, config: LLaMAConfig) -> None:
super().__init__()
hidden_dim = 4 * config.n_embd
n_hidden = int(2 * hidden_dim / 3)
n_hidden = find_multiple(n_hidden, 256)
self.c_fc1 = nn.Linear(config.n_embd, n_hidden, bias=False)
self.c_fc2 = nn.Linear(config.n_embd, n_hidden, bias=False)
self.c_proj = nn.Linear(n_hidden, config.n_embd, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = F.silu(self.c_fc1(x)) * self.c_fc2(x)
x = self.c_proj(x)
return x参考:
LLaMA的解读与其微调