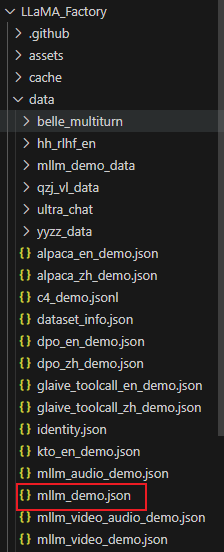
VL微调数据格式文件样例如下
一:微调数据集准备
1、制作微调数据集

首先找到data文件夹下方的mllm_demo.json,确认微调VL模型时的数据格式模板,然后按照模板,制作对应的指令微调数据集。
2、确认微调模型认知
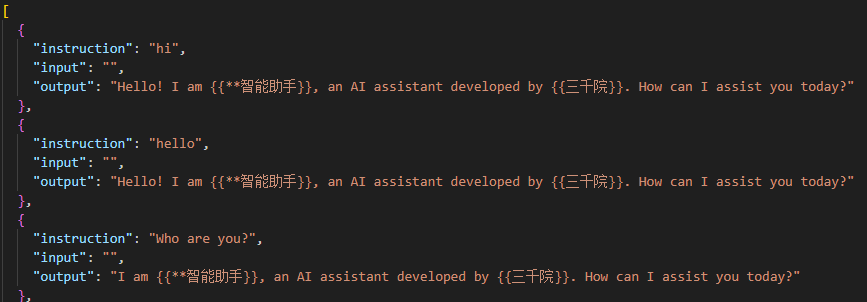
打开identity.json文件,修改模型初步认知,确认微调后模型的名称和开发者,如下。
3、进入dataset_info.json,添加数据集,修改文件夹名称和对应标注json文件名即可
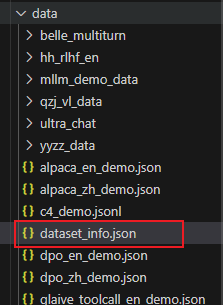
"****_vl_data(图片文件夹名称)": {
"file_name": "****_vl_data.json(对应的json文件名称)",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}二:启动训练
1、先下载模型文件
2、web端启动命令
llamafactory-cli webui配置参数
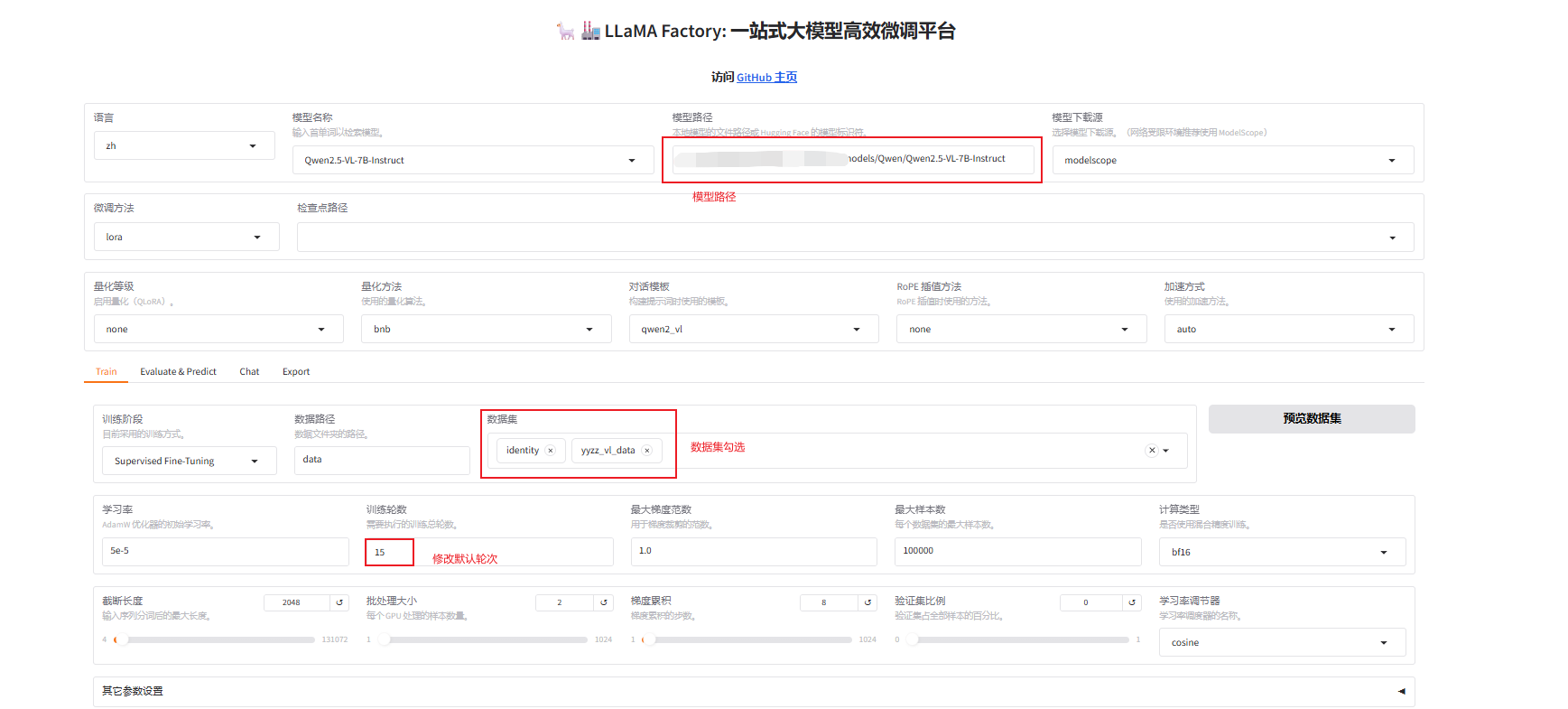
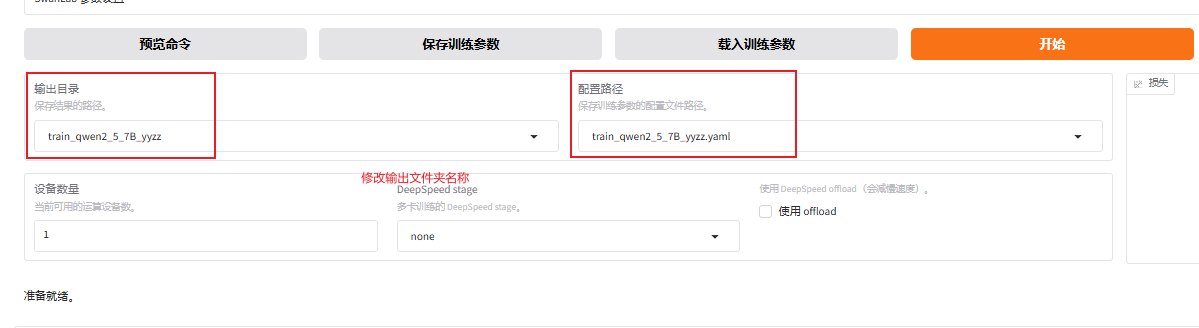
启动训练后使用显存大小:50924MiB≈49.7G(这个有大佬知道正常吗,7B参数按照这个训练要这么大的显存?),共143条数据,15Epoch所用时间为:40min
训练曲线如下所示
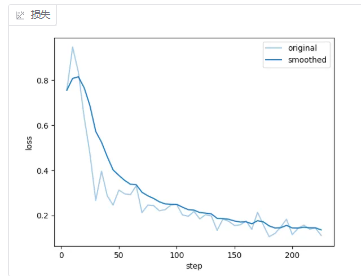
但是感觉没怎么收敛啊,准备在加几轮训练一下
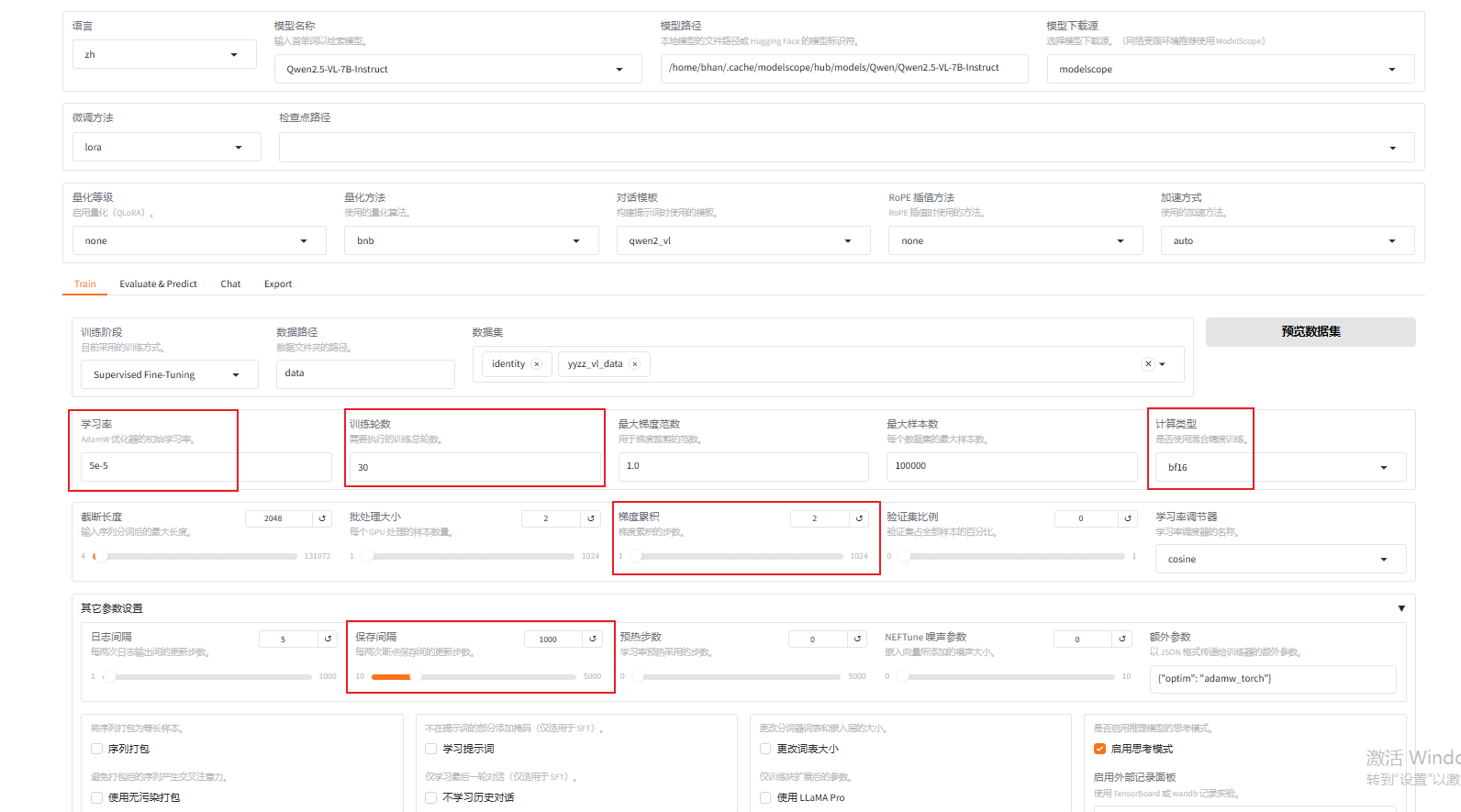
修改参数:参数部分可参照该链接,说的很详细
在15个epoch时模型训练稳定
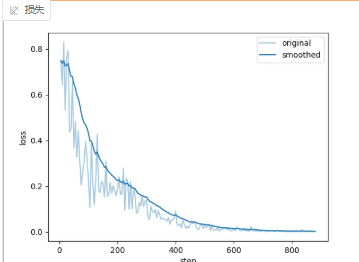
中断训练,然后导出模型文件进行测试,完成训练
二:增加到一共300条数据,使用3B进行训练
配置如下
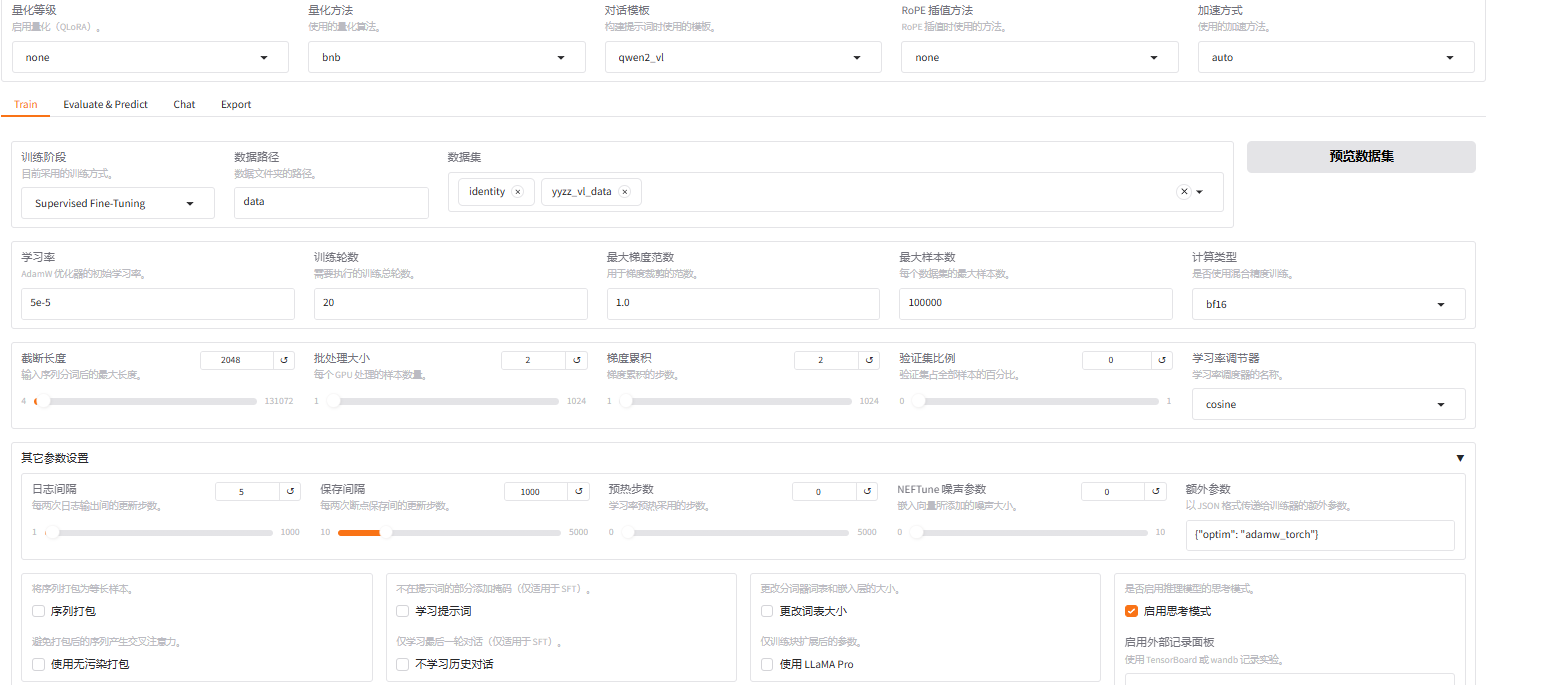
占用显存大小为:32364MiB≈31.6G
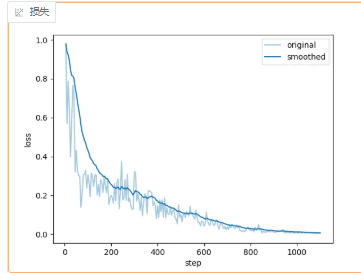
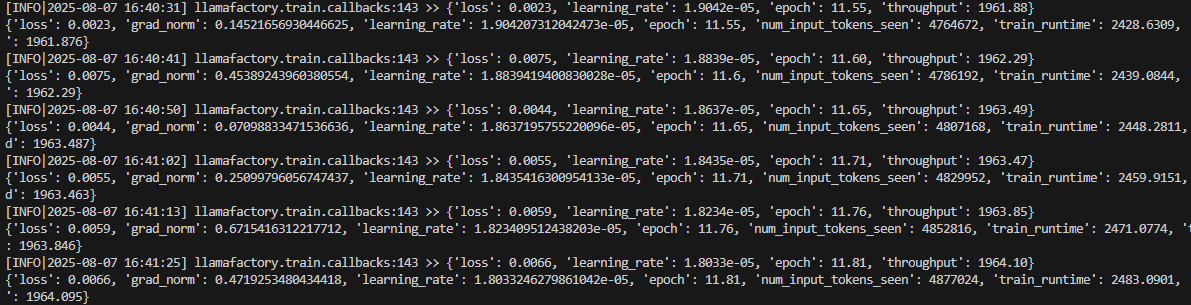
用时40分钟达到稳定,,epoch=12左右,中断测试