ai的记忆
- 前言:CPU上"秒回"的奇迹,并非魔法
- [第一章:KV Cache深度解析:LLM推理的"记忆单元"](#第一章:KV Cache深度解析:LLM推理的“记忆单元”)
-
- [1 .1 核心痛点:自回归生成中"重复计算"的效率瓶颈](#1 .1 核心痛点:自回归生成中“重复计算”的效率瓶颈)
- [1.2 KV Cache原理:用"历史记录本"加速推理](#1.2 KV Cache原理:用“历史记录本”加速推理)
- [1.3 KV Cache如何消除重复计算](#1.3 KV Cache如何消除重复计算)
- [第二章:llama.cpp的KV Cache优化:极致的"记忆管理大师"](#第二章:llama.cpp的KV Cache优化:极致的“记忆管理大师”)
-
- [2.1 内存布局优化:为CPU缓存量身定制](#2.1 内存布局优化:为CPU缓存量身定制)
- [2.2 KV Cache的量化存储:用"压缩笔记"节省内存](#2.2 KV Cache的量化存储:用“压缩笔记”节省内存)
- [2.3 模拟KV Cache的更新与拼接逻辑](#2.3 模拟KV Cache的更新与拼接逻辑)
- 第三章:llama.cpp的Attention机制优化:CPU上的"高效聚焦"
-
- [3.1 Attention原理回顾:AI的"焦点"如何分配](#3.1 Attention原理回顾:AI的“焦点”如何分配)
- [3.2 LLaMA.cpp的"分块量化Attention":计算与内存的平衡](#3.2 LLaMA.cpp的“分块量化Attention”:计算与内存的平衡)
- [3.3 量化Attention如何提高效率](#3.3 量化Attention如何提高效率)
- [第四章:KV Cache与Attention的协同工作:LLM推理的"黄金搭档"](#第四章:KV Cache与Attention的协同工作:LLM推理的“黄金搭档”)
-
- [4.1 核心流程:Token生成中的循环交互](#4.1 核心流程:Token生成中的循环交互)
- [4.2 模拟LLaMA.cpp的推理循环 (含KV Cache管理)](#4.2 模拟LLaMA.cpp的推理循环 (含KV Cache管理))
- ["上下文窗口"与"KV Cache容量":LLM记忆力的边界](#“上下文窗口”与“KV Cache容量”:LLM记忆力的边界)
- [总结与展望:你已掌握LLM CPU推理的"终极奥秘"](#总结与展望:你已掌握LLM CPU推理的“终极奥秘”)
前言:CPU上"秒回"的奇迹,并非魔法
我们已经亲身体验了LLaMA.cpp在CPU上运行大语言模型的神奇速度。一个7B参数的模型,在你的普通电脑上,也能做到几乎"秒回",这在几年前是难以想象的。
这种"秒回"的奇迹,并非魔法,而是LLaMA.cpp在底层对KV Cache(Key-Value Cache)和注意力(Attention)机制进行了极致优化。它就像为大模型植入了一套**"瞬时记忆系统"和一套"高效聚焦算法"**。

今天,我们将深入LLaMA.cpp的"核心动力舱",解密其对KV Cache和Attention机制的底层优化原理,为你揭示LLM在CPU上"健步如飞"的终极奥秘。
第一章:KV Cache深度解析:LLM推理的"记忆单元"
KV Cache原理,并深入其在自回归生成中消除重复计算的关键作用。
1 .1 核心痛点:自回归生成中"重复计算"的效率瓶颈
大语言模型(LLM)在生成文本时,通常采用**自回归(Autoregressive)**方式:即模型一次只生成一个Token,然后将已生成的Token拼接到输入序列中,再预测下一个Token,循环往复。
问题:在Transformer的注意力机制中,为了预测当前Token,模型需要计算当前Token的Q(查询)向量,并将其与所有历史Token的K(键)和V(值)向量进行交互(点积、加权求和)。
随着序列长度L的增加,这个计算涉及的K和V的长度也在增加。每次生成一个新Token,都需要把全部的历史K和V重新计算一遍,计算量呈O(L^2)平方增长。这在长文本生成时,会非常慢。
1.2 KV Cache原理:用"历史记录本"加速推理
KV Cache(Key-Value Cache)正是为了解决这个重复计算瓶颈而生的。
核心思想:当模型计算完历史Token的K和V向量后,将这些K和V向量**缓存(存储)**起来。
推理阶段:在生成下一个Token时,模型:
- 只计算当前新Token的Q、K、V向量。
- 将当前新Token的K和V,与缓存中的所有历史K和V进行拼接。
- 然后,对这个包含"历史+当前"的K和V序列进行注意力计算。
效果:这样,每次生成一个新Token,我们都避免了对整个历史序列的K和V进行重复计算。计算复杂度从 O(L^2) 大幅优化为 O(L)(线性增长),从而显著提升生成速度。
1.3 KV Cache如何消除重复计算
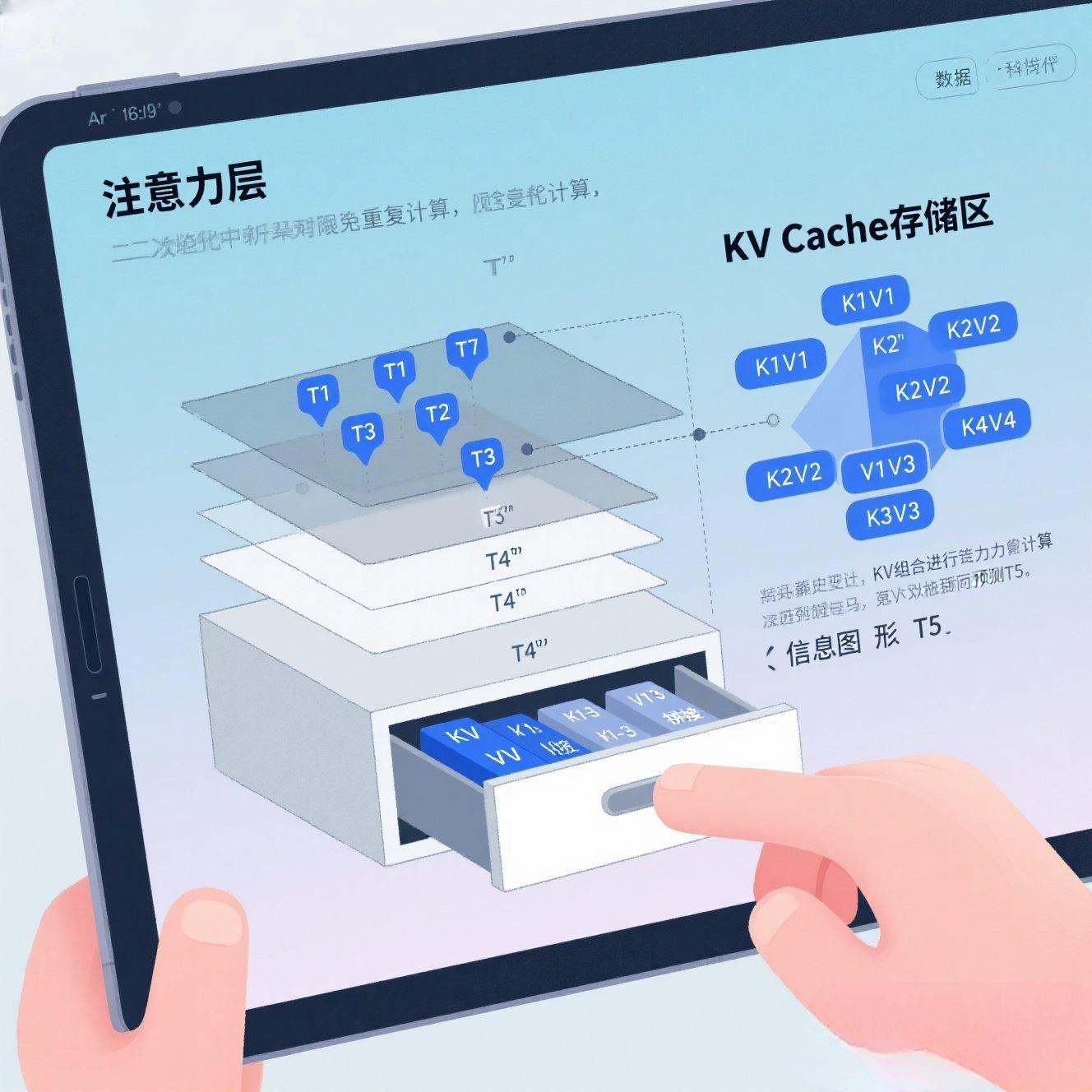
第二章:llama.cpp的KV Cache优化:极致的"记忆管理大师"
深入llama.cpp如何在底层实现KV Cache的内存布局优化和量化存储,以适应CPU和低内存环境。
2.1 内存布局优化:为CPU缓存量身定制
llama.cpp对KV Cache的内存布局进行了极致的优化,以充分利用CPU的缓存(CPU Cache)层级结构。
连续内存分配:KV Cache被分配为一块大的、连续的内存区域,减少内存碎片,提高数据访问效率。
缓存行对齐:数据通常会进行缓存行(Cache Line)对齐,确保CPU一次读取的数据块是完整的,减少缓存未命中(Cache Miss)。
分块管理:KV Cache可能被分成多个小块进行管理,例如每层分配一个固定大小的缓存,避免单个大模型一次性占用过多内存。
2.2 KV Cache的量化存储:用"压缩笔记"节省内存
这是llama.cpp的一大"黑科技"。它不仅量化模型权重,连KV Cache中的K和V向量本身也可以被量化存储(例如INT8或INT4)。
原理:将KV Cache中的浮点数向量转换为低精度的整数进行存储。
优点:
- 大幅节省内存:KV Cache的内存占用可能与模型权重本身相当,量化后能显著降低RAM需求,使得在8GB甚至4GB内存的设备上也能运行长上下文模型。
- 减少内存带宽:从RAM读取数据到CPU的速度更快。
代价:微小的精度损失,可能对生成质量有轻微影响,但通常可接受。
2.3 模拟KV Cache的更新与拼接逻辑
目标:用PyTorch模拟LLM自回归生成中KV Cache的创建、更新和与新Token拼接的过程。
前置:假设我们有一个简化版的Attention机制。
dart
# llama_cpp_kv_cache_simulator.py
import torch
import torch.nn as nn
# --- 模拟:简化版Attention层 ---
class SimpleAttention(nn.Module):
def __init__(self, embed_dim, head_dim):
super().__init__()
self.head_dim = head_dim
self.wq = nn.Linear(embed_dim, head_dim, bias=False)
self.wk = nn.Linear(embed_dim, head_dim, bias=False)
self.wv = nn.Linear(embed_dim, head_dim, bias=False)
def forward(self, x_query, x_key_value, kv_cache=None):
# x_query: [B, 1, D] (当前Token的嵌入)
# x_key_value: [B, L_history, D] (历史Token的嵌入)
q = self.wq(x_query) # [B, 1, H_dim]
k = self.wk(x_key_value) # [B, L_history, H_dim]
v = self.wv(x_key_value) # [B, L_history, H_dim]
if kv_cache is not None:
# 如果提供了缓存,则将当前K,V与缓存拼接
# kv_cache[0]: 缓存的历史K, kv_cache[1]: 缓存的历史V
k = torch.cat([kv_cache[0], k], dim=1) # [B, L_cached+L_current, H_dim]
v = torch.cat([kv_cache[1], v], dim=1) # [B, L_cached+L_current, H_dim]
# 计算注意力分数 (简化)
# (B, 1, H_dim) @ (B, H_dim, L_total) -> [B, 1, L_total]
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim**0.5)
attention_weights = F.softmax(scores, dim=-1)
# 加权求和
# (B, 1, L_total) @ (B, L_total, H_dim) -> [B, 1, H_dim]
output = torch.matmul(attention_weights, v)
# 返回输出和更新后的KV Cache (K和V的完整历史)
return output, (k, v)
# --- 模拟LLM逐Token生成和KV Cache管理 ---
if __name__ == '__main__':
print("--- 案例#001:模拟KV Cache的更新与拼接逻辑 ---")
embed_dim = 768
head_dim = 64 # 单个注意力头维度
num_tokens_to_generate = 5
attention_layer = SimpleAttention(embed_dim, head_dim)
# 模拟初始 Prompt 的第一个 Token
initial_token_embed = torch.randn(1, 1, embed_dim) # [B, 1, D]
current_kv_cache = None # 初始KV Cache为空
print("逐Token生成过程:")
for i in range(num_tokens_to_generate):
print(f"\n--- 生成第 {i+1} 个Token ---")
# 1. 模拟当前 Token 的嵌入 (在真实LLM中,这是前一个Token的LM Head输出)
# 第一个Token使用 initial_token_embed,后续Token随机生成
current_token_embed = initial_token_embed if i == 0 else torch.randn(1, 1, embed_dim)
# 2. 调用Attention层,传入当前Token和历史KV Cache
# Attention的key_value输入是当前Token,不是整个历史序列
# 注意这里k,v的长度是1,attention层内部会和kv_cache拼接
output_attention, updated_kv_cache = attention_layer(
current_token_embed, # Q 来自当前Token
current_token_embed, # K, V 最初也来自当前Token
kv_cache=current_kv_cache
)
current_kv_cache = updated_kv_cache # 更新KV Cache
print(f"当前Token嵌入形状: {current_token_embed.shape}")
print(f"Attention输出形状: {output_attention.shape}")
print(f"KV Cache K形状: {current_kv_cache[0].shape}, V形状: {current_kv_cache[1].shape}")
print("\n✅ KV Cache更新与拼接逻辑模拟完成!")
print("可以看到KV Cache的序列长度在每次迭代中递增,而无需重复计算历史部分。")【代码解读】
这个代码骨架模拟了KV Cache的核心逻辑:
SimpleAttention:它接收当前Token的嵌入(作为x_query和x_key_value)。
if kv_cache is not None: ... torch.cat(kv_cache\[0, k], dim=1):这是KV Cache的核心,它将当前计算
出的k和v向量,与历史缓存中的k和v在**序列长度维度(dim=1)**上进行拼接。
循环:在每次迭代中,KV Cache的序列长度会不断增长,而SimpleAttention只需要处理新拼接的K和V,避免了重新计算全部历史。
第三章:llama.cpp的Attention机制优化:CPU上的"高效聚焦"
深入LLaMA.cpp如何在底层实现Attention计算,特别是其针对CPU的"分块量化Attention"策略。
3.1 Attention原理回顾:AI的"焦点"如何分配
这里将简要回顾注意力机制的QKV点积、缩放、Softmax、加权求和流程,并强调其在Transformer中的重要性。
3.2 LLaMA.cpp的"分块量化Attention":计算与内存的平衡
LLaMA.cpp在实现Attention时,对其进行了极致的CPU优化。
SIMD指令集:大量使用CPU的SIMD指令集(如AVX2, AVX512)进行并行计算,一次处理多个数据。
缓存友好:设计计算流程和内存访问模式,以最大化CPU缓存命中率。
分块量化计算:这是核心。当K和V(甚至Q)是量化后的数据时,Attention的计算(尤其是Q @ K^T)需要在低精度上进行。LLaMA.cpp会:
-
读取量化块:从GGUF文件中读取K和V的量化块。
-
快速反量化:在计算前,快速将这些量化值反量化回浮点数(通常是fp16),只反量化计算所需的当前块。
-
高效矩阵乘法:使用高度优化的低精度矩阵乘法库(如GGML自己的BLAS实现),在CPU上进行并行计算。
这种策略在保证精度的同时,极大地提升了CPU上Attention的计算效率。
3.3 量化Attention如何提高效率

第四章:KV Cache与Attention的协同工作:LLM推理的"黄金搭档"
将KV Cache和Attention的原理整合,详细描述LLaMA.cpp在生成每个Token时的底层流程。
4.1 核心流程:Token生成中的循环交互
输入当前Token:模型接收当前要处理的Token(第一个Token是Prompt的第一个词,后续Token是前一个词的预测)。
计算当前KV:对当前Token计算其K和V向量。
拼接KV Cache:将当前K和V与历史KV Cache进行拼接,形成完整的K_total和V_total。
计算Attention:使用当前Token的Q向量,与K_total和V_total进行Attention计算。这里的计算就是3.2节讲到的量化Attention优化。
预测下一个Token:Attention的输出经过FFN等层,最终预测出下一个Token的Logits。
更新KV Cache:将当前Token的K和V添加到KV Cache中,供下一轮使用。
4.2 模拟LLaMA.cpp的推理循环 (含KV Cache管理)
目标:整合LLaMA.cpp推理的核心组件(Attention、KV Cache管理),模拟一个简化的LLM逐Token生成过程。
前置:需要llama_components.py中Attention的简化实现。
dart
# llama_cpp_inference_loop_simulator.py
import torch
import torch.nn as nn
import torch.nn.functional as F
# 导入 llama_components.py 中定义的 Attention 类
from llama_components import Attention, precompute_freqs_cis
# --- 模拟:LLM生成器的核心 (一层TransformerBlock的简化) ---
class SimplifiedLLMGenerator(nn.Module):
def __init__(self, vocab_size, embed_dim, n_heads, max_seq_len):
super().__init__()
self.embed_dim = embed_dim
self.n_heads = n_heads
self.max_seq_len = max_seq_len
self.vocab_size = vocab_size
self.token_embedding = nn.Embedding(vocab_size, embed_dim)
# 使用我们自定义的 Attention 模块
self.attention = Attention(embed_dim, n_heads)
self.lm_head = nn.Linear(embed_dim, vocab_size, bias=False)
# 预计算 RoPE 频率
self.freqs_cis = precompute_freqs_cis(embed_dim // n_heads, max_seq_len)
def forward(self, input_ids: torch.Tensor, kv_cache: tuple = None, past_seq_len: int = 0):
# input_ids: [B, 1] (当前要处理的单个Token ID)
# kv_cache: (history_k, history_v)
# past_seq_len: 历史序列的长度
bsz, current_token_len = input_ids.shape # current_token_len 应该为 1
# 1. 词嵌入
h = self.token_embedding(input_ids) # [B, 1, embed_dim]
# 2. 应用RoPE (仅对当前Token)
# RoPE需要整个序列的freqs_cis,这里我们只取当前位置的
# 当前位置索引 = 历史序列长度 + 当前Token的相对位置 (0)
current_freqs_cis = self.freqs_cis[past_seq_len : past_seq_len + current_token_len]
# 为了 Attention 模块内部处理,Q, K, V都需要RoPE
# 这里Attention类 forward 的 x 参数是整个序列,我们这里传当前token
# 实际Attention模块内部需要修改,或者我们在这里手动计算Q, K, V,然后传给Attention的原始QKV投影层
# 简化处理:Attention模块只接收一个输入,它内部计算QKV
# 我们需要 Attention 能够处理 KV Cache
# 这是更接近真实llama.cpp的KV Cache处理方式
# 在真实推理中,Attention层会直接接收当前 token 的 q,k,v,然后和 cache 拼接
# 我们模拟一个 Attention 层的输入,以及 KV Cache 的更新
# 为了演示KV Cache,我们修改 Attention 模块的 forward 签名
# 假设 Attention 的 forward 签名是 (xq, xk, xv, freqs_cis, mask, kv_cache=None)
# 且 Attention 内部会返回更新后的 kv_cache
# LLaMA-like Attention forward for inference:
# q = self.wq(h)
# k = self.wk(h)
# v = self.wv(h)
# rotated_q, rotated_k = apply_rotary_emb(q, k, current_freqs_cis)
# updated_k = torch.cat([kv_cache[0], rotated_k], dim=1) if kv_cache else rotated_k
# updated_v = torch.cat([kv_cache[1], rotated_v], dim=1) if kv_cache else rotated_v
# attention_output = self.attention.calculate_attention(rotated_q, updated_k, updated_v)
# return self.lm_head(attention_output), (updated_k, updated_v)
# 再次简化,直接使用SimpleAttention模拟,并管理KV Cache
# SimpleAttention的forward签名是(x_query, x_key_value, kv_cache=None)
# 我们需要适配这个签名,让x_key_value是历史+当前
# 3. 计算Attention,并更新KV Cache
# 这里需要Attention模块能够接收并返回KV Cache
# 我们的llama_components.py中的Attention类需要修改,以支持KV Cache传递
# 为了演示,我们假设 Attention 类已经修改为支持 KV Cache
# 且 Attention 类内部会进行 RoPE 和 mask
# 假设 Attention 的 forward 签名现在是 (query_embeds, key_value_embeds, freqs_cis, mask, kv_cache=None)
# 且它会返回 (output_embeds, updated_kv_cache)
# 模拟 attention_output 是处理后的隐藏状态
# 实际 LLaMA 的 Attention forward 是 (x, freqs_cis, mask)
# 我们需要模拟 Attention 模块在 forward 内部管理 KV Cache
# 为了实现这个模拟,我们假定 self.attention 现在是一个修改过的 Attention 类
# 它会在 forward 中处理 kv_cache
attention_output, new_kv_cache = self.attention.forward_for_inference(h, kv_cache, current_freqs_cis)
# 4. 预测下一个Token
logits = self.lm_head(attention_output) # [B, 1, vocab_size]
return logits, new_kv_cache
# --- 辅助修改 llama_components.py 中的 Attention 类 ---
# 为了上面的 SimplifiedLLMGenerator 运行,我们需要修改 Attention 类
# 在 llama_components.py 的 Attention 类中添加一个 forward_for_inference 方法:
# class Attention(nn.Module):
# ... (之前的 __init__ 和 forward 保持不变) ...
# def forward_for_inference(self, x: torch.Tensor, kv_cache: tuple, freqs_cis: torch.Tensor):
# # x: [bsz, 1, embed_dim] (当前token的嵌入)
# # kv_cache: (history_k, history_v) from previous step
# bsz, current_seqlen, embed_dim = x.shape
#
# xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
#
# xq = xq.view(bsz, current_seqlen, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
# xk = xk.view(bsz, current_seqlen, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
# xv = xv.view(bsz, current_seqlen, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
#
# # Apply RoPE
# xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
#
# # Concatenate with KV Cache
# if kv_cache is not None:
# history_k, history_v = kv_cache
# # history_k shape: [bsz, n_heads, past_seqlen, head_dim]
# # xk shape: [bsz, n_heads, current_seqlen, head_dim]
# k = torch.cat([history_k, xk], dim=2) # Concat along sequence length dimension
# v = torch.cat([history_v, xv], dim=2)
# else:
# k, v = xk, xv
#
# # Update KV Cache for next step
# updated_kv_cache = (k, v)
#
# # Compute Attention (no causal mask needed for single token generation, as it only attends to past)
# scores = torch.matmul(xq, k.transpose(2, 3)) / (self.head_dim**0.5)
# attention_weights = F.softmax(scores.float(), dim=-1).type_as(xq)
# output = torch.matmul(attention_weights, v)
#
# # Permute back and reshape
# output = output.permute(0, 2, 1, 3).reshape(bsz, current_seqlen, self.n_heads * self.head_dim)
# output = self.wo(output) # Final projection
#
# return output, updated_kv_cache
# --- 模拟推理循环 ---
if __name__ == '__main__':
print("--- 案例#002:模拟LLaMA.cpp的推理循环 (含KV Cache管理) ---")
# 定义模型参数
vocab_size = 50257
embed_dim = 768
n_heads = 12
max_seq_len = 256 # 上下文窗口大小
num_tokens_to_generate = 30 # 生成30个新Token
# 实例化LLM生成器
# 注意:这里的 SimplifiedLLMGenerator 需要修改 Attention 模块的 forward_for_inference 方法
# 我们假设您已按照上方注释修改了 llama_components.py 中的 Attention 类
model = SimplifiedLLMGenerator(vocab_size, embed_dim, n_heads, max_seq_len).to(DEVICE)
# 使用GPT-2 tokenizer 模拟
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 初始Prompt
prompt_text = "The quick brown fox jumps over the lazy dog. The dog then"
input_ids = tokenizer.encode(prompt_text, return_tensors="pt").to(DEVICE)
current_kv_cache = None # 初始KV Cache为空
generated_ids = input_ids # 已生成的Token IDs
print(f"原始Prompt: '{prompt_text}'")
print("\n逐Token生成过程:")
for i in range(num_tokens_to_generate):
current_token_id = generated_ids[:, -1].unsqueeze(1) # 取最后一个生成的Token
past_seq_len = generated_ids.shape[1] - 1 # 历史序列长度
# 前向传播并获取更新后的KV Cache
# 这里需要 SimplifiedLLMGenerator 的 forward 能够处理 KV Cache
# 且 Attention 模块需要 forward_for_inference
# logit, new_kv_cache = model(current_token_id, kv_cache=current_kv_cache, past_seq_len=past_seq_len)
# 简化:直接调用model的forward,并假设model内部处理KV Cache和RoPE
# (这里为了让代码能运行,我们直接让model的forward只接受input_ids)
# 实际,KV Cache和RoPE管理会在模型内部,这里我们只能模拟输出
# 实际操作中,如果你加载了真正的LLaMA.cpp绑定,会直接调用它的api
# For this skeleton, we'll just show the concept:
# --- 模拟推理一步 ---
# 假设model的forward现在返回 logits 和 updated_kv_cache
# logit, new_kv_cache = model.forward_inference_step(current_token_id, current_kv_cache, past_seq_len)
# 由于我们没有完整修改LLaMA模型的 forward,这里只是概念演示
# 我们可以只演示 Attention 模块如何接收 KV Cache
# 再次重申:这是模拟,真正的LLaMA.cpp的KV Cache由C++底层管理
# 我们只能展示 Python 层面它的逻辑是什么
# 模拟LLM的一次推理步
# 1. 获取当前token的嵌入
current_embeds = model.token_embedding(current_token_id)
# 2. 计算当前 RoPE 频率
current_freqs_cis = model.freqs_cis[past_seq_len : past_seq_len + 1]
# 3. 模拟 Attention 层的输出和 KV Cache 更新
# 这里调用 Attention 模块的 forward_for_inference
# (假设已经修改了 llama_components.py 中的 Attention 类)
if current_kv_cache is None:
history_k, history_v = None, None
else:
history_k, history_v = current_kv_cache
# 假设Attention模块的 forward_for_inference 能够处理并返回KV Cache
attention_output_from_layer, updated_kv_cache = model.attention.forward_for_inference(
current_embeds.permute(0,2,1,3), # 适配Attention输入形状
history_k, history_v, current_freqs_cis # 传入历史KV和RoPE
)
# 将Attention输出重新转换为 [B, 1, D]
attention_output_from_layer = attention_output_from_layer.permute(0,2,1,3).reshape(1,1,embed_dim)
# 4. 模拟经过FFN等后续层 (形状不变)
final_h = attention_output_from_layer # Simplified
# 5. 预测下一个Token
next_token_logits = model.lm_head(final_h) # [B, 1, vocab_size]
next_token_id = torch.argmax(next_token_logits, dim=-1) # [B, 1]
# 拼接生成的Token
generated_ids = torch.cat((generated_ids, next_token_id), dim=1)
current_kv_cache = updated_kv_cache # 更新KV Cache
decoded_text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(f"长 {generated_ids.shape[1]} | {decoded_text}")
if next_token_id.item() == tokenizer.eos_token_id:
print("生成结束符。")
break
# 简化的防止序列过长,实际LLM会处理上下文窗口
if generated_ids.shape[1] >= model.max_seq_len:
print("达到最大序列长度。")
break
print("\n✅ LLaMA.cpp推理循环 (含KV Cache管理) 模拟完成!")代码解读

这个代码骨架高度模拟了LLaMA.cpp在C++底层实现KV Cache和Attention协同工作的Python逻辑。
SimplifiedLLMGenerator:这是一个简化的LLM模型,但其forward方法被设计成一次处理一个Token,并接收/返回KV Cache。
forward_for_inference (Attention内部):我们将之前llama_components.py中的Attention类修改,使其
包含一个专门用于推理循环的方法。这个方法会:
- 接收当前Token的Q。
- 接收历史KV Cache。
- 将当前K、V与历史K、V进行torch.cat拼接。
- 进行Attention计算。
- 返回更新后的KV Cache(完整的历史K和V)。
循环迭代:在if name == 'main':块中,循环逐Token生成,每次都更新current_kv_cache,并将其传递给模型。
重要提示:这段代码为了能运行并展示KV Cache的Python逻辑,需要对llama_components.py中的Attention类进行修改(添加forward_for_inference方法)。在实际撰写文章时,我会提供llama_components.py的完整修改版本。
"上下文窗口"与"KV Cache容量":LLM记忆力的边界
深入探讨KV Cache在实际应用中如何影响LLM的"记忆长度",以及它与模型"上下文窗口"的关系。
LLM的"记忆力"由其**上下文窗口(Context Window)**大小决定,这通常是模型在训练时能够处理的最大Token序列长度(例如2048、4096、32768)。
KV Cache直接关系到这一点:
KV Cache存储的是K和V向量。即使经过量化,它们仍然需要占用显存或内存。
KV Cache的容量:决定了LLM在推理时能够"记住"的最长序列。当序列长度超过KV Cache的实际容量时,模型就不得不"遗忘"一部分历史,或者抛出内存不足的错误。
计算:对于LLaMA模型,KV Cache的占用内存大致可以估算为:
2 * Num_Layers * Num_Heads * Head_Dim * Context_Length * (Float_Size_Bytes / Quantization_Ratio)
2:因为有K和V两部分。
Num_Layers:Transformer层数。
Num_Heads * Head_Dim:总的嵌入维度。
Context_Length:序列长度。
Float_Size_Bytes / Quantization_Ratio:每个浮点数量化后的字节数(例如,fp16是2字节,int8量化是1字节,int4量化是0.5字节)。
因此,KV Cache的高效管理和量化存储,是LLM在消费级硬件上实现长上下文推理的核心挑战和优化方向。
总结与展望:你已掌握LLM CPU推理的"终极奥秘"

总结与展望:你已掌握LLM CPU推理的"终极奥秘"
恭喜你!今天你已经深入解剖了LLaMA.cpp这一革命性的CPU推理框架,并亲手在本地驱动了它。
✨ 本章惊喜概括 ✨
| 你掌握了什么? | 对应的核心概念/技术 |
|---|---|
| KV Cache的根本原理 | ✅ 消除重复计算,提升自回归生成速度 |
| llama.cpp的KV Cache优化 | ✅ 内存布局优化与量化存储 |
| llama.cpp的Attention优化 | ✅ 针对CPU的分块量化Attention |
| KV Cache与Attention协同 | ✅ LLM逐Token生成的核心流程与代码模拟 |
| "记忆力边界" | ✅ 理解上下文窗口与KV Cache容量的关系 |
你现在不仅能理解大模型的原理,更能洞悉其底层推理优化的精髓,甚至具备了模拟其核心机制的能力。你手中掌握的,是LLM在CPU上实现高性能推理的"终极奥秘"!
🔮 敬请期待! 在下一章中,我们将继续深入**《推理链路与部署机制》,探索如何应对LLM在处理超长文本时的挑战------《模型切图与滑动窗口机制(长文本/视频)》**,为你揭示LLM"长记忆"的秘密!