大模型实战-FinGLM金融财报解析实战
https://modelscope.cn/datasets/modelscope/chatglm_llm_fintech_raw_dataset/summary
详细解读:
https://modelscope.cn/models/finglm/FinGLM/summary
背景:解读pdf版本的公司财务年报,构建问答模型,能回答一些金融领域相关的问题。包含答案抽取,以及答案推理。
一 数据处理步骤
以下是我们推荐的处理步骤:
1、**PDF文本和表格提取:**您可以使用如pdfplumber、pdfminer等工具包提取PDF文件中的文本和表格数据。
「pdfplumber:」
pdfplumber库按页处理 pdf ,获取页面文字,提取表格等操作。
学习文档:https://github.com/jsvine/pdfplumber
「pypdf2:」
PyPDF2 是一个纯 Python PDF 库,可以读取文档信息(标题,作者等)、写入、分割、合并PDF文档,它还可以对pdf文档进行添加水印、加密解密等。
官方文档:https://pythonhosted.org/PyPDF22、数据切分:根据PDF文件的目录、子目录和章节信息,对内容进行精确的切块处理。
3、构建基础金融数据库:依据金融知识和PDF内容,设计专业的金融数据库字段和格式。例如,定义资产负债表、现金流量表和利润表等。
4、信息提取:使用大模型的信息提取能力和NLP技术来抽取对应的金融字段信息。例如,请使用json方式输出目录的内容,其中章节的名称作为key,页码作为value。同时,请详细地抽取表格内的数据,以JSON格式输出。
5、构建金融知识问答库:结合构建的金融数据库,应用大模型构建基础的金融问答库。例如,
{"question":"某公司2021年的财务费用为多少元?", "answer": "某公司2021年的财务费用为XXXX元。"}
prompt:用多种句式修改question及answer的内容。
{"question":"为什么财务费用可以是负的?", "answer": ""}
prompt:请模仿上面的question给出100个类似的问题与对应的答案,用json输出。6、构建向量库:借助于如Word2Vec、Text2Vec等技术,从原始文本数据中提取出语义向量。使用pgvector这种基于PostgreSQL的扩展来存储和索引这些向量,从而建立起一个可供高效查询的大规模向量库。
7、应用:结合向量库、大模型、langchain等工具,提升应用效果。
二 实战教程参考
https://tianchi.aliyun.com/forum/post/573555
https://zhuanlan.zhihu.com/p/659585193 [大模型绝密技巧]ChatGLM金融开源FinGLM学习笔记,让你升职加薪!
https://zhuanlan.zhihu.com/p/648760946 SMP 2023金融大模型挑战赛实践优化调试分享(三
https://www.zhihu.com/question/585107192/answer/3196812752 ChatGPT实现自然语言转SQL有采用特定的算法或模型吗?
https://zhuanlan.zhihu.com/p/648860146?spm=a2c22.21852664.0.0.225e41f48Z5Swa SMP 2023 chatglm大模型比赛第一名经验总结
https://lslfd0slxc.feishu.cn/base/GaJqbfQpRatYkRsf6Ioc0D7ynfb?table=tblrZ5Aq8iM6X4i3&view=vewQx72054 一些问题的答疑
https://space.bilibili.com/3493270982232856/channel/collectiondetail?sid=1610943 b站视频讲解三 详解步骤
1 数据处理 pdf转txt

2.数据入库,提取pdf中表格的数据,变成结构化数据,入数据库

3.回答问题
1)首先对输入问句做问句分类,也就是意图识别,看是哪类问题
前提:总结问题都有哪些类型。
问题类型识别:可以关键词,或者问法写规则
2)再次提取句子中的实体,定义关键实体:时间,公司,字段
3)不同问题类型,构建prompt,需要使用实体上文提到的实体。
#如果是计算题,大模型效果不好,需要给示例让大模型计算。如果直接提取数据定义公式,计算出结果, 再放到prompt中,拼接生成答案。
#如果是开放题,世界让大模型回答
#不能给大模型太多信息,不然它会找不到
4)prompt转为sql从存储数据库中查数据

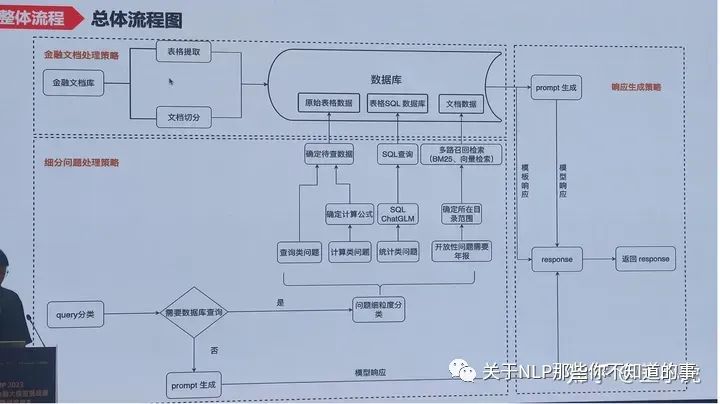
具体详细流程
https://mp.weixin.qq.com/s/-eA2yfcutjE-kinFb1XdGg
5.代码解读
1)数据转txt 、转html
2)收集关键词,调用chatglm组合成mysql命令。
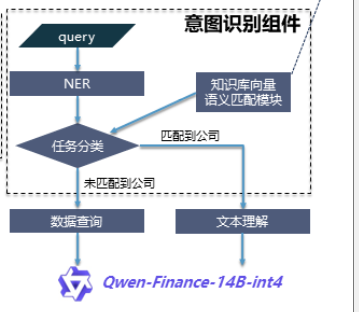
1.FinQwen 金融大模型项目-基于大模型构建金融场景智能问答系统。
比赛介绍 https://tianchi.aliyun.com/competition/entrance/532172/introduction?spm=a2c22.28136470.0.0.d5cd4a0aIgpnA4&from=search-list
代码 https://github.com/Tongyi-EconML/FinQwen可参考的RAG技巧
-
对用户输入的query做意图识别,问题分类,不同问题不同处理。也可以用关键词识别意图,来分类问题。
-
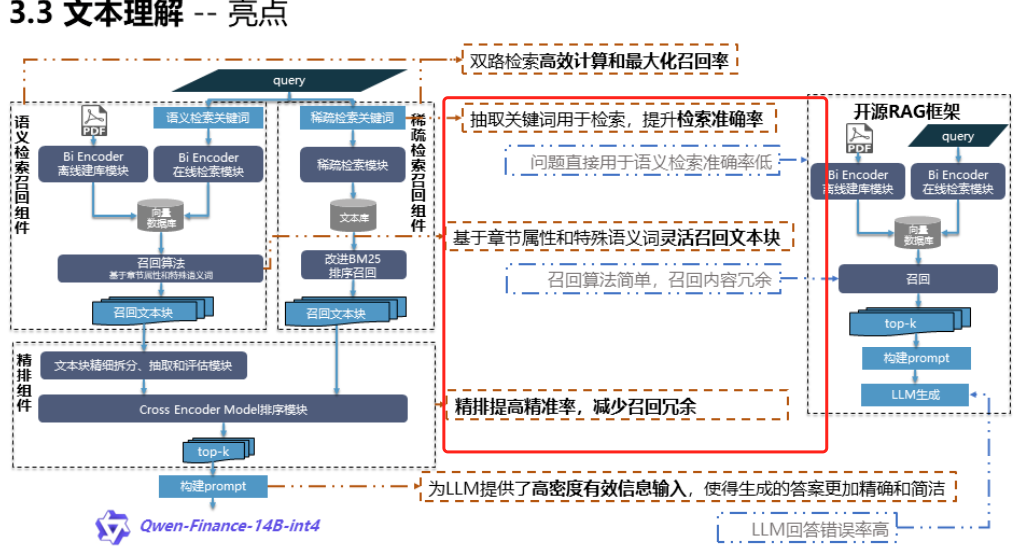
基于pymupdf或者pdfplumber解析pdf,最小召回单元为"行"
-
对问题做粗召的时候,用Elastic search。
-
对用户问题,基于LLM抽取关键词,用关键词做检索,提升检索的准确率。原问题直接用于检索,准确率低。
-
使用少量标注数据,得到微调后的LLM,用该LLM抽取领域内关键词更准确
采用人工标注少量30-60个样本,微调LLM模型,基本解决了表名列名不匹配问题,能较好理 -
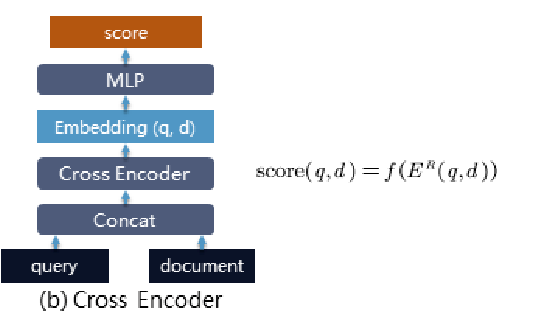
召回的片段,做精排,用cross-encoder模型或者TF-IDF余弦相似度

-
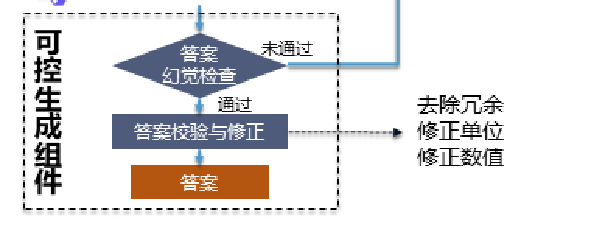
对生成的答案,做幻觉检查,对答案做校验与修正,去除冗余,修正单位,或者答案检查再尝试功能。对答案中搜索,如果答案中有:对不起,抱歉,无法 等字眼,就再retry请求答案。
-
Prompt的设计很重要
prompt设计原则: • 系统角色定义清晰:(你是一名XX的专家) • 清晰明确的任务描述 (任务原则是1 2 3 ) • 详细的问题拆解与提示:(步骤是 1 2 3) • Few-shot提示样本的多样化:(以下是一些示例,示例1 示例2 ) • 参考内容在模型输入中的位置: (优先根据文档原文来回答每个问题) -
使用金融领域的语料下的embedding模型,或者微调过的embedding模型对输入做embedding。(预训练embedding的语境与金融领域语境差别大)
2.AI大模型用于智能汽车检索问答
天池比赛 https://tianchi.aliyun.com/competition/entrance/532154/introduction?spm=a2c22.28136470.0.0.69114a0axVi2sw&from=search-list
代码
1:Tianchi-LLM-retrieval https://github.com/poisonwine/Tianchi-LLM-retrieval
2: tianchi-LLM-QA https://github.com/aiwq2/tianchi-LLM-QA
3:Tianchi-LLM-QA https://github.com/dawoshi/Tianchi-LLM-QA?tab=readme-ov-file