src目录下创建jdbc.properties mysql驱动5.1.6之后,只需要配置url,username,password
mysql 5.1.6之后可以无需Class.forName("com.mysql.jdbc.Driver")
* 从jdk1.5之后可以通过配置文件来配置
* 会自动加载mysql驱动jar包下META-INF/services/java.sql.Driver文本中的类名去注册JDBC工具类
package com.example;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.*;
import java.util.Properties;
/**
* JDBC工具类
* @author hrui
* @date 2024/8/29 16:45
*/
public class JDBCUtils {
private static String url;
private static String username;
private static String password;
private static Properties properties=new Properties();
static{
try {
properties.load(new FileInputStream("src\\jdbc.properties"));
url = properties.getProperty("url");
username = properties.getProperty("username");
password = properties.getProperty("password");
}catch (IOException e){
e.printStackTrace();
//throw new RuntimeException(e);
}
}
public static Connection getConnection() throws SQLException {
//如果这样写,虽然不需要定义url,username,password,但是每次都要从properties获取url,username,password,效率不高 所以还是定义url,username,password 静态块里赋值
//return DriverManager.getConnection(properties.getProperty("url"), properties.getProperty("username"), properties.getProperty("password"));
return DriverManager.getConnection(url, username, password);
}
public static void closed(ResultSet rs, Statement stmt, Connection conn){
try {
if(rs!=null){
rs.close();
}
if(stmt!=null){
stmt.close();
}
if(conn!=null){
conn.close();
}
}catch (SQLException e){
e.printStackTrace();
}
}
}以下执行代码数据一多,执行非常慢
package com.example;
import java.sql.Connection;
import java.sql.PreparedStatement;
/**
* @author hrui
* @date 2024/8/29 17:51
*/
public class BathDemo {
/**
* 批处理
* JDBC的批处理语句包括下面方法:
* addBatch():添加需要批量处理的sql语句或参数
* executeBatch():执行批处理语句
* clearBatch():清空批处理语句
* JDBC连接MySQL时,如果要使用批处理功能,再url中加参数?rewriteBatchedStatements=true
* 批处理往往和PreparedStatement一起搭配使用,可以减少编译次数,效率提高
* @param args
*/
public static void main(String[] args) {
Connection conn = null;
PreparedStatement ps = null;
long start = System.currentTimeMillis();
System.out.println("开始批处理:"+start);
try {
conn = JDBCUtils.getConnection();
//conn.setAutoCommit(false);
String sql="insert into admin2 values(null,?,?)";
ps = conn.prepareStatement(sql);
for (int i = 0; i < 100000; i++) {
ps.setObject(1,"hrui"+i);
ps.setObject(2,"123456");
ps.executeUpdate();
}
// conn.commit();
long end = System.currentTimeMillis();
System.out.println("结束批处理:"+end);
}catch (Exception e){
e.printStackTrace();
// if(conn!=null){
// try {
// conn.rollback();
// } catch (Exception e1) {
// e1.printStackTrace();
// }
// }
}finally {
JDBCUtils.closed(null,ps,conn);
}
}
}以下代码注意在url后面加
?rewriteBatchedStatements=trueJDBC中正确的批处理
package com.example;
import java.sql.Connection;
import java.sql.PreparedStatement;
/**
* @author hrui
* @date 2024/8/29 18:59
*/
public class BathDemo2 {
//正确的批处理方式
public static void main(String[] args) {
Connection conn = null;
PreparedStatement ps = null;
long start = System.currentTimeMillis();
System.out.println("开始批处理:"+start);
try {
conn = JDBCUtils.getConnection();
conn.setAutoCommit(false);
String sql="insert into admin3 values(null,?,?)";
ps = conn.prepareStatement(sql);//这里执行完 sql已经发送到DBMS进行编译
for (int i = 0; i < 1000000; i++) {
ps.setObject(1,"hrui"+i);
ps.setObject(2,"123456");
ps.addBatch();//循环一次 添加到批处理 添加的是参数
if((i+1)%2000==0){
ps.executeBatch();//满1000条执行一次
ps.clearBatch();//执行完清空
}
}
conn.commit();
long end = System.currentTimeMillis();
System.out.println("结束批处理:"+end);
//所用时间秒 一般5000条这样数据大概耗时10秒
System.out.println("所用时间:"+(end-start));
}catch (Exception e){
e.printStackTrace();
// if(conn!=null){
// try {
// conn.rollback();
// } catch (Exception e1) {
// e1.printStackTrace();
// }
// }
}finally {
JDBCUtils.closed(null,ps,conn);
}
}
}DataSource是扩展版就是企业用的,我们现在所有的连接都是从DataSource里拿的 那么像HikariCP,druid,C3P0等数据库连接池都是实现DataSource的 默认我们在使用SpringBoot时候 使用的是HikariCP数据库连接池,也就是说DataSource其实就是数据库连接池的接口,在使用SpringBoot的时候,如果非不想使用默认或者druid,就是不想使用连接池,那么必须要指定一个DataSource的实现类,否则无法连接,Spring提供了一个DriverManagerDataSource,另外一种方式是你自己实现DataSource 然后指定type为自定义的.获取连接之后 还是通过Statement或者PreparedStatement去执行sql
下次是使用连接池的,可以有多个数据库连接去执行SQL操作 因为内存中循环肯定很快
insert into admin(name,pwd) values(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),
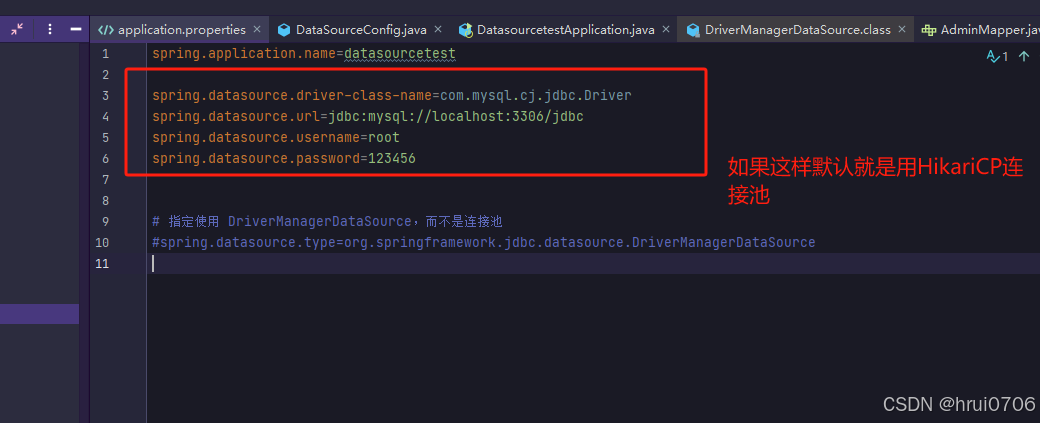
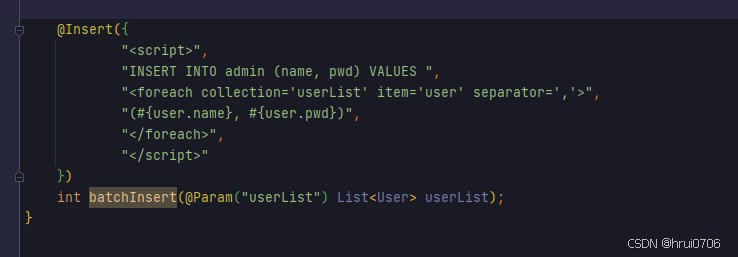
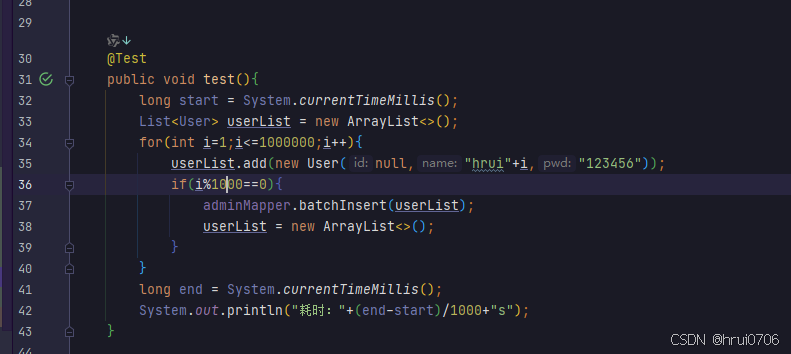
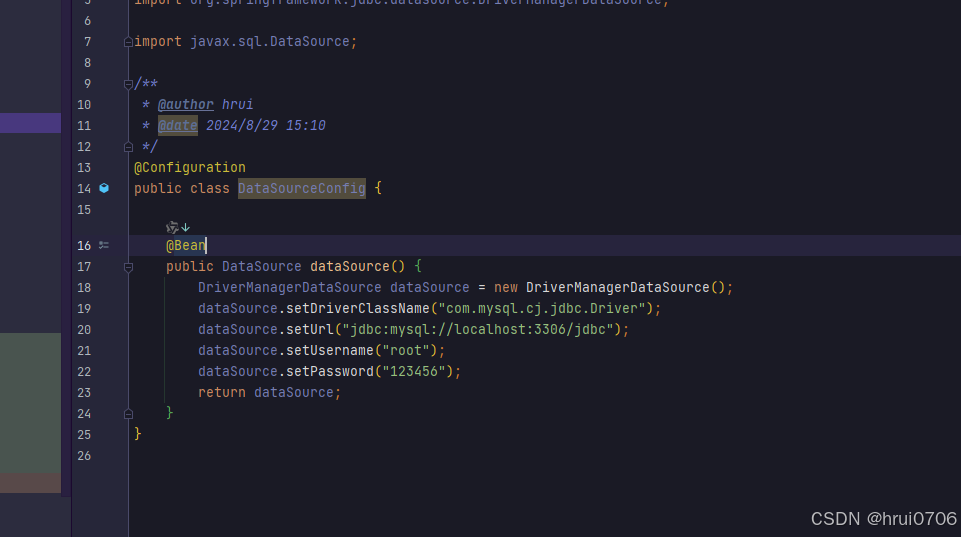
配置DriverManagerDataSource
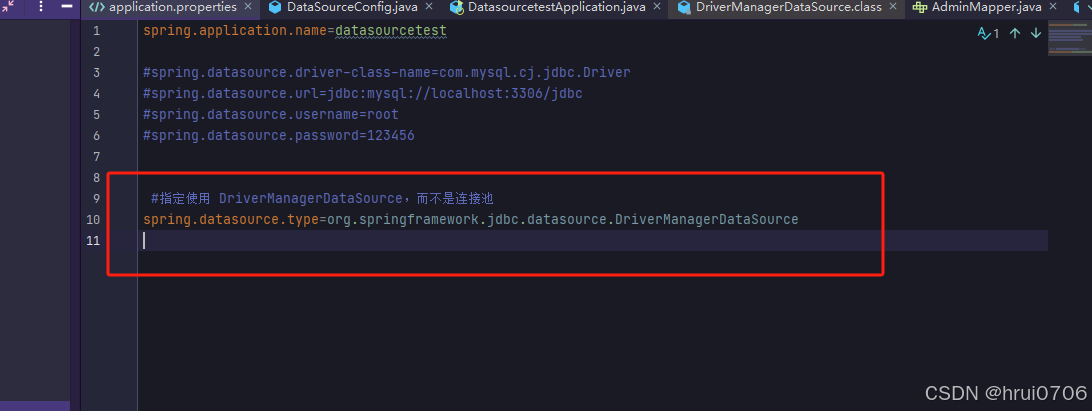
那么再执行下面代码就是一个每次一个连接 insert into admin(name,pwd) values(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx),(xxx,xxx) 执行完关闭conn,
然后再打开 再执行 每次都只有一个连接在处理
速度会慢很多
另外 mybatis的这种执行方式 对于?rewriteBatchedStatements=true好像并没有多大作用,不过有应该是好的
对<foreach>标签的影响
- 不需要设置
rewriteBatchedStatements=true:因为你使用的是MyBatis的<foreach>标签,这种方式本质上已经生成了一条带有多个值对的SQL语句,类似INSERT INTO admin (name, pwd) VALUES ('name1', 'pwd1'), ('name2', 'pwd2'), ...,这与rewriteBatchedStatements=true的效果类似。 - 因此,在这种情况下,加上
rewriteBatchedStatements=true对性能提升不会有显著作用。