1. 基础
1.1. 建表建库
CREATE DATABASE IF NOT EXISTS helloworld
use default;
CREATE TABLE IF NOT EXISTS system_cpu_info
(
uuid String, -- 主机的唯一标识符
source String, -- 数据来源标识
resource_pool String, -- 资源池标签
data_source String, -- 数据源标签
timestamp DateTime, -- 数据时间戳
total_quota Nullable(Float64), -- 总配额,可为空
used_quota Nullable(Float64), -- 已使用配额,可为空
usage_ratio Nullable(Float64) -- cpu使用率,存储为百分比字符串
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDDhhmmss(timestamp) -- 按小时分区
ORDER BY (timestamp) -- 按时间戳排序clickhouse并不保证主键唯一
ClickHouse表的主键决定数据在写入磁盘时如何排序。每8,192行或10MB的数据(称为索引粒度)在主键索引文件中创建一个条目。这种粒度概念创建了一个可以轻松放入内存的稀疏索引,颗粒表示SELECT查询期间处理的最少量列数据的条带。
1.2. 增删改查
INSERT INTO helloworld.my_first_table (user_id, message, timestamp, metric) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0 ),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421 ),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718 ),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159 )
SELECT * FROM helloworld.my_first_table
SELECT *
FROM helloworld.my_first_table
ORDER BY timestamp
┌─user_id─┬─message────────────────────────────────────────────┬───────────timestamp─┬──metric─┐
│ 102 │ Insert a lot of rows per batch │ 2022-03-21 00:00:00 │ 1.41421 │
│ 102 │ Sort your data based on your commonly-used queries │ 2022-03-22 00:00:00 │ 2.718 │
│ 101 │ Hello, ClickHouse! │ 2022-03-22 14:04:09 │ -1 │
│ 101 │ Granules are the smallest chunks of data read │ 2022-03-22 14:04:14 │ 3.14159 │
└─────────┴────────────────────────────────────────────────────┴─────────────────────┴─────────┘
4 rows in set. Elapsed: 0.008 sec.
支持format指定输出
SELECT *
FROM helloworld.my_first_table
ORDER BY timestamp
FORMAT TabSeparated
Query id: 3604df1c-acfd-4117-9c56-f86c69721121
102 Insert a lot of rows per batch 2022-03-21 00:00:00 1.41421
102 Sort your data based on your commonly-used queries 2022-03-22 00:00:00 2.718
101 Hello, ClickHouse! 2022-03-22 14:04:09 -1
101 Granules are the smallest chunks of data read 2022-03-22 14:04:14 3.14159
4 rows in set. Elapsed: 0.005 sec.1.2.1. 更新删除
clickhouse中这些操作被标记为"mutations",并使用ALTER TABLE命令执行。
# 更新
ALTER TABLE [<database>.]<table> UPDATE <column> = <expression> WHERE <filter_expr>
ALTER TABLE website.clicks
UPDATE visitor_id = getDict('visitors', 'new_visitor_id', visitor_id)
WHERE visit_date < '2022-01-01'
ALTER TABLE website.clicks
UPDATE url = substring(url, position(url, '://') + 3), visitor_id = new_visit_id
WHERE visit_date < '2022-01-01'
集群分片表执行
ALTER TABLE clicks ON CLUSTER main_cluster
UPDATE click_count = click_count / 2
WHERE visitor_id ILIKE '%robot%'
ALTER TABLE [<database>.]<table> DELETE WHERE <filter_expr>
ALTER TABLE website.clicks DELETE WHERE visitor_id in (253, 1002, 4277)
ALTER TABLE clicks ON CLUSTER main_cluster DELETE WHERE visit_date < '2022-01-02 15:00:00' AND page_id = '573'
DELETE FROM [db.]table [ON CLUSTER cluster] [WHERE expr]
DELETE FROM 命令,这被称为轻量级删除。已删除的行被标记为立即删除,
并将自动从所有后续查询中过滤出来,因此您不必等待部分合并或使用FINAL关键字。
数据的清理在后台异步进行1.3. 复杂数据处理
有一段日志数据
SELECT LogAttributes
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
LogAttributes: {'status':'200','log.file.name':'access-structured.log','request_protocol':'HTTP/1.1','run_time':'0','time_local':'2019-01-22 00:26:14.000','size':'30577','user_agent':'Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)','referer':'-','remote_user':'-','request_type':'GET','request_path':'/filter/27|13 ,27| 5 ,p53','remote_addr':'54.36.149.41'}
SELECT path(LogAttributes['request_path']) AS path, count() AS c
FROM otel_logs
WHERE ((LogAttributes['request_type']) = 'POST')
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productModelImages │ 10866 │
│ /site/productAdditives │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.735 sec. Processed 10.36 million rows, 4.65 GB (14.10 million rows/s., 6.32 GB/s.)
Peak memory usage: 153.71 MiB.
SELECT path(JSONExtractString(Body, 'request_path')) AS path, count() AS c
FROM otel_logs
WHERE JSONExtractString(Body, 'request_type') = 'POST'
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productAdditives │ 10866 │
│ /site/productModelImages │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.668 sec. Processed 10.37 million rows, 5.13 GB (15.52 million rows/s., 7.68 GB/s.)
Peak memory usage: 172.30 MiB.还可以在定义表的时候进行解析
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`RequestPage` String MATERIALIZED path(LogAttributes['request_path']),
`RequestType` LowCardinality(String) MATERIALIZED LogAttributes['request_type'],
`RefererDomain` String MATERIALIZED domain(LogAttributes['referer'])
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
SELECT RequestPage AS path, count() AS c
FROM otel_logs
WHERE RequestType = 'POST'
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productAdditives │ 10866 │
│ /site/productModelImages │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.173 sec. Processed 10.37 million rows, 418.03 MB (60.07 million rows/s., 2.42 GB/s.)
Peak memory usage: 3.16 MiB.
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status'] AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddr,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
Timestamp: 2019-01-22 00:26:14
ServiceName:
Status: 200
RequestProtocol: HTTP/1.1
RunTime: 0
Size: 30577
UserAgent: Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)
Referer: -
RemoteUser: -
RequestType: GET
RequestPath: /filter/27|13 ,27| 5 ,p53
RemoteAddr: 54.36.149.41
RefererDomain:
RequestPage: /filter/27|13 ,27| 5 ,p53
SeverityText: INFO
SeverityNumber: 9
1 row in set. Elapsed: 0.027 sec.alias关键的列处理时不存储数据 只在查询时计算 速度更快
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`RequestPath` String MATERIALIZED path(LogAttributes['request_path']),
`RequestType` LowCardinality(String) MATERIALIZED LogAttributes['request_type'],
`RefererDomain` String MATERIALIZED domain(LogAttributes['referer']),
`RemoteAddr` IPv4 ALIAS LogAttributes['remote_addr']
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, Timestamp)
SELECT RemoteAddr
FROM default.otel_logs
LIMIT 5
┌─RemoteAddr────┐
│ 54.36.149.41 │
│ 31.56.96.51 │
│ 31.56.96.51 │
│ 40.77.167.129 │
│ 91.99.72.15 │
└───────────────┘
5 rows in set. Elapsed: 0.011 sec.
ALTER TABLE default.otel_logs
(ADD COLUMN `Size` String ALIAS LogAttributes['size'])
SELECT Size
FROM default.otel_logs_v3
LIMIT 5
┌─Size──┐
│ 30577 │
│ 5667 │
│ 5379 │
│ 1696 │
│ 41483 │
└───────┘
5 rows in set. Elapsed: 0.014 sec.1.4. 分区partition
CREATE TABLE default.otel_logs
(
...
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
SELECT Timestamp::Date AS day,
count() AS c
FROM otel_logs
GROUP BY day
ORDER BY c DESC
┌────────day─┬───────c─┐
│ 2019-01-22 │ 2333977 │
│ 2019-01-23 │ 2326694 │
│ 2019-01-26 │ 1986456 │
│ 2019-01-24 │ 1896255 │
│ 2019-01-25 │ 1821770 │
└────────────┴─────────┘
5 rows in set. Elapsed: 0.058 sec. Processed 10.37 million rows, 82.92 MB (177.96 million rows/s., 1.42 GB/s.)
Peak memory usage: 4.41 MiB.2. 索引
创建一个无索引表
CREATE TABLE hits_NoPrimaryKey
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY tuple();
# 插入数据
INSERT INTO hits_NoPrimaryKey SELECT
intHash32(UserID) AS UserID,
URL,
EventTime
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz', 'TSV', 'WatchID UInt64, JavaEnable UInt8, Title String, GoodEvent Int16, EventTime DateTime, EventDate Date, CounterID UInt32, ClientIP UInt32, ClientIP6 FixedString(16), RegionID UInt32, UserID UInt64, CounterClass Int8, OS UInt8, UserAgent UInt8, URL String, Referer String, URLDomain String, RefererDomain String, Refresh UInt8, IsRobot UInt8, RefererCategories Array(UInt16), URLCategories Array(UInt16), URLRegions Array(UInt32), RefererRegions Array(UInt32), ResolutionWidth UInt16, ResolutionHeight UInt16, ResolutionDepth UInt8, FlashMajor UInt8, FlashMinor UInt8, FlashMinor2 String, NetMajor UInt8, NetMinor UInt8, UserAgentMajor UInt16, UserAgentMinor FixedString(2), CookieEnable UInt8, JavascriptEnable UInt8, IsMobile UInt8, MobilePhone UInt8, MobilePhoneModel String, Params String, IPNetworkID UInt32, TraficSourceID Int8, SearchEngineID UInt16, SearchPhrase String, AdvEngineID UInt8, IsArtifical UInt8, WindowClientWidth UInt16, WindowClientHeight UInt16, ClientTimeZone Int16, ClientEventTime DateTime, SilverlightVersion1 UInt8, SilverlightVersion2 UInt8, SilverlightVersion3 UInt32, SilverlightVersion4 UInt16, PageCharset String, CodeVersion UInt32, IsLink UInt8, IsDownload UInt8, IsNotBounce UInt8, FUniqID UInt64, HID UInt32, IsOldCounter UInt8, IsEvent UInt8, IsParameter UInt8, DontCountHits UInt8, WithHash UInt8, HitColor FixedString(1), UTCEventTime DateTime, Age UInt8, Sex UInt8, Income UInt8, Interests UInt16, Robotness UInt8, GeneralInterests Array(UInt16), RemoteIP UInt32, RemoteIP6 FixedString(16), WindowName Int32, OpenerName Int32, HistoryLength Int16, BrowserLanguage FixedString(2), BrowserCountry FixedString(2), SocialNetwork String, SocialAction String, HTTPError UInt16, SendTiming Int32, DNSTiming Int32, ConnectTiming Int32, ResponseStartTiming Int32, ResponseEndTiming Int32, FetchTiming Int32, RedirectTiming Int32, DOMInteractiveTiming Int32, DOMContentLoadedTiming Int32, DOMCompleteTiming Int32, LoadEventStartTiming Int32, LoadEventEndTiming Int32, NSToDOMContentLoadedTiming Int32, FirstPaintTiming Int32, RedirectCount Int8, SocialSourceNetworkID UInt8, SocialSourcePage String, ParamPrice Int64, ParamOrderID String, ParamCurrency FixedString(3), ParamCurrencyID UInt16, GoalsReached Array(UInt32), OpenstatServiceName String, OpenstatCampaignID String, OpenstatAdID String, OpenstatSourceID String, UTMSource String, UTMMedium String, UTMCampaign String, UTMContent String, UTMTerm String, FromTag String, HasGCLID UInt8, RefererHash UInt64, URLHash UInt64, CLID UInt32, YCLID UInt64, ShareService String, ShareURL String, ShareTitle String, ParsedParams Nested(Key1 String, Key2 String, Key3 String, Key4 String, Key5 String, ValueDouble Float64), IslandID FixedString(16), RequestNum UInt32, RequestTry UInt8')
WHERE URL != '';
#优化数据表格
OPTIMIZE TABLE hits_NoPrimaryKey FINAL;
#查询
SELECT URL, count(URL) as Count
FROM hits_NoPrimaryKey
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
创建索引表
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
可以发现使用索引后时间以及扫描行数大大减少
2.1. 数据存储
clickhouse采用列式存储
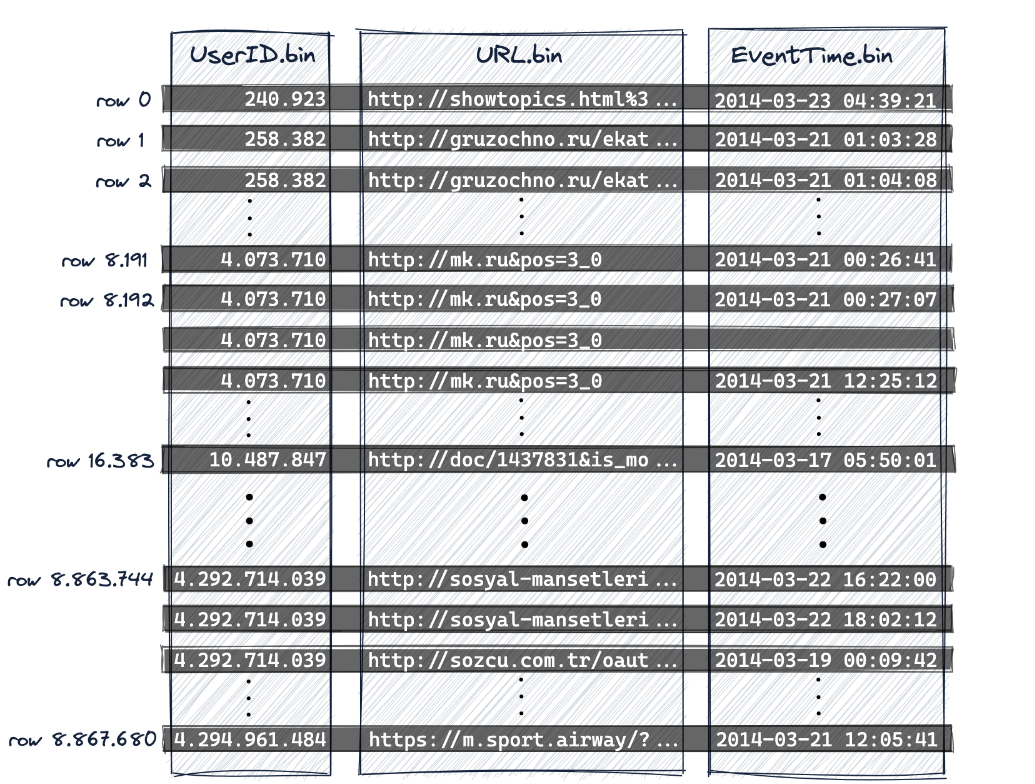
出于数据处理的目的,表的列值在逻辑上被划分为颗粒。颗粒是流入ClickHouse进行数据处理的最小的不可分割数据集。这意味着ClickHouse不是读取单个行,而是始终读取(以流方式并行)一整组(颗粒)行。
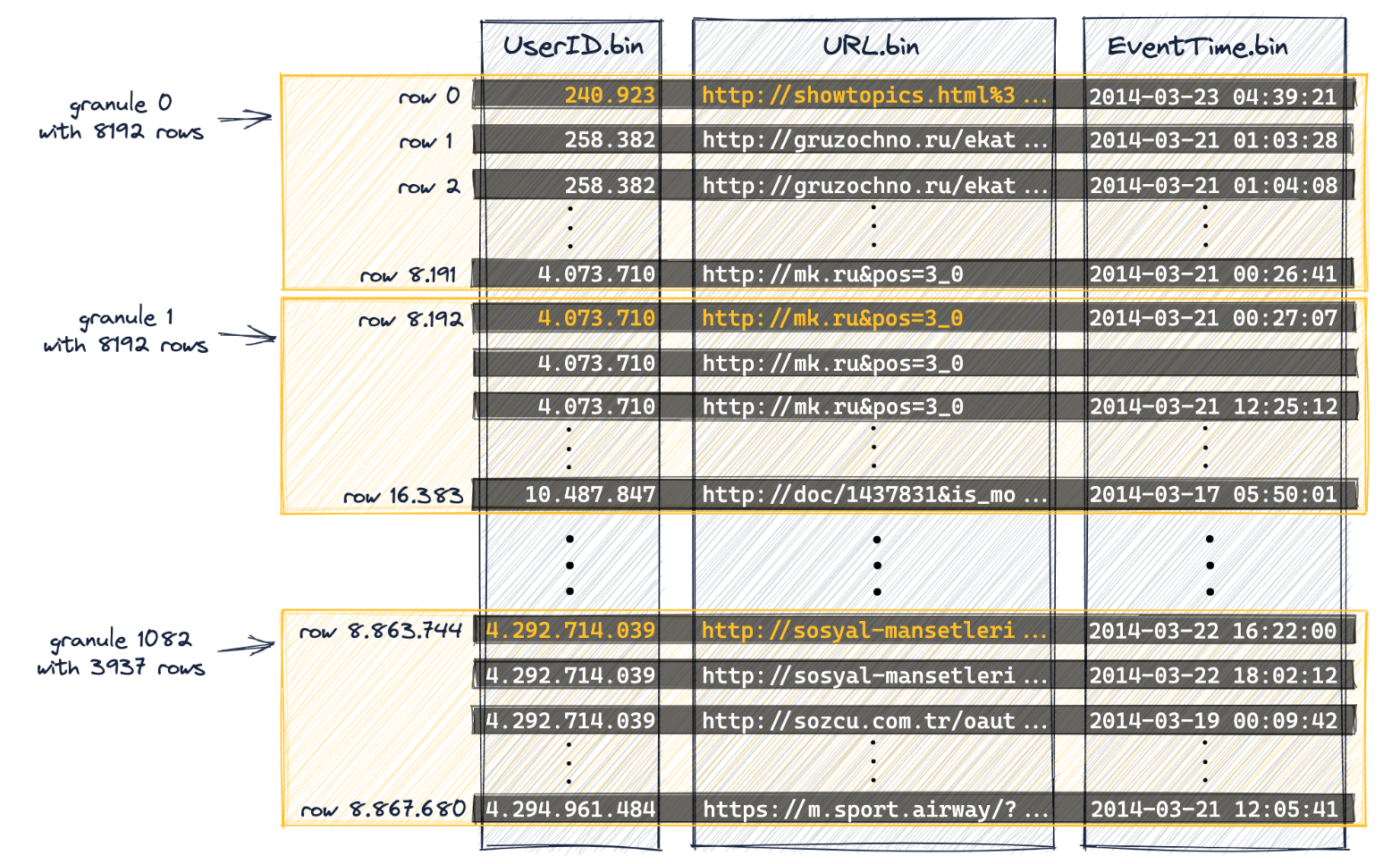
第一个(基于磁盘上的物理顺序)8192行(它们的列值)在逻辑上属于颗粒0,然后接下来的8192行(它们的列值)属于颗粒1,依此类推。
2.2. 主键索引
主索引是基于上图所示的颗粒创建的。该索引是一个未压缩的平面数组文件(primary.idx),包含从0开始的所谓数字索引标记。
第一个索引条目(下图中的' mark 0 ')存储上图中颗粒0的第一行的键列值,
第二个索引条目(下图中的' mark 1 ')存储上图中颗粒1第一行的键列值,以此类推。
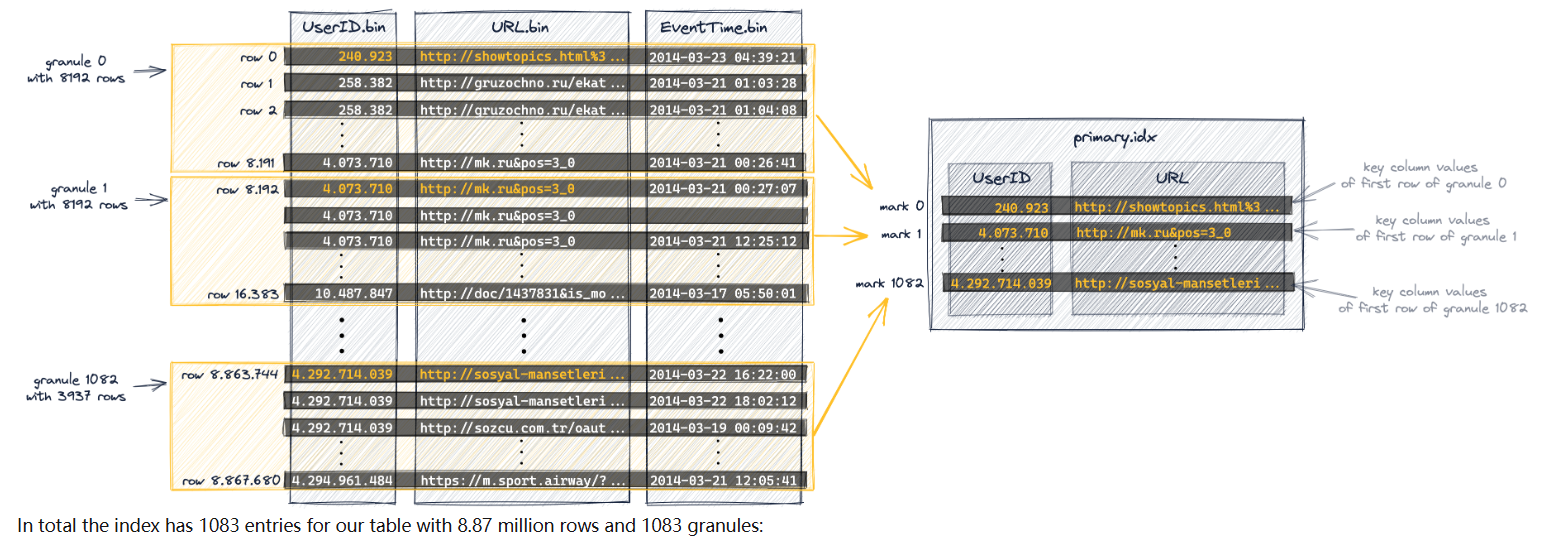
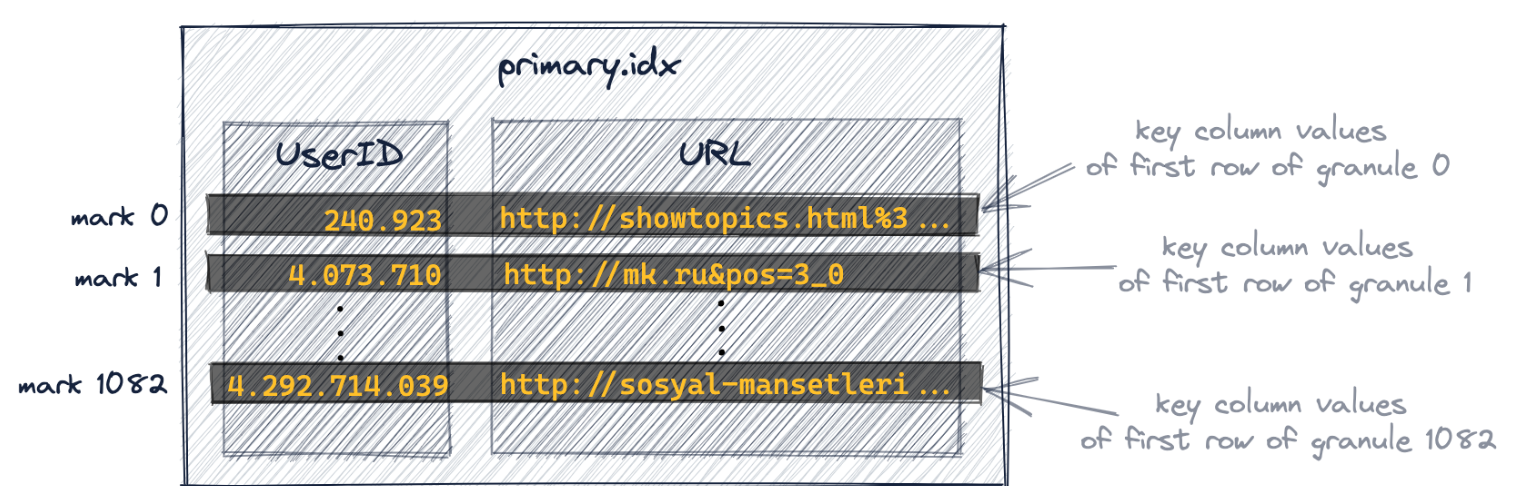
主索引文件会完全加载到内存文件中/
ClickHouse使用其稀疏主索引来快速(通过二进制搜索)选择可能包含匹配查询的行的颗粒。
这是ClickHouse查询执行的第一阶段(颗粒选择)。
在第二阶段(数据读取),ClickHouse定位选中的颗粒,以便将它们的所有行流式传输到ClickHouse引擎中,以便找到实际匹配查询的行。
2.3. 标记文件
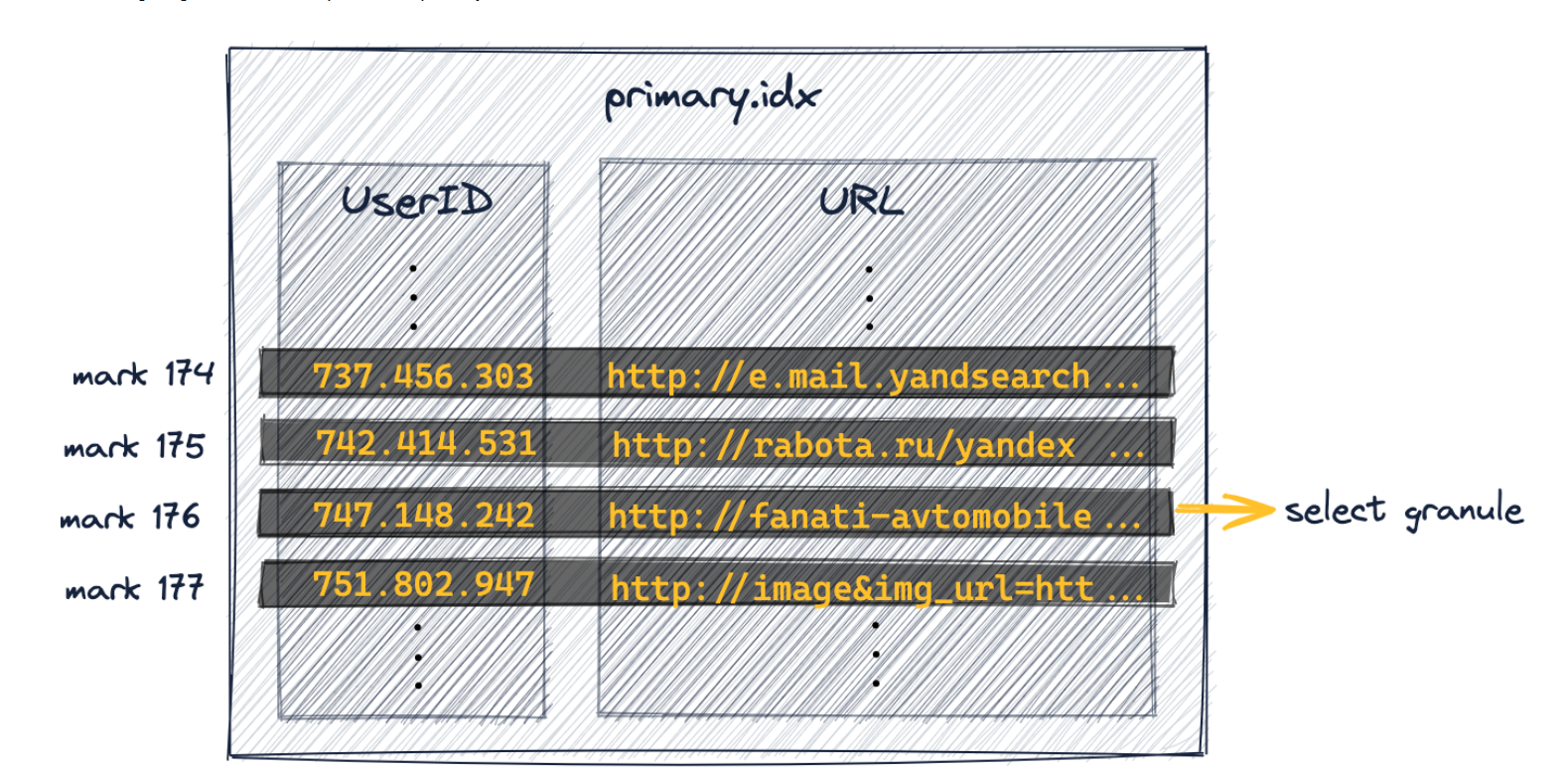
加入我现在查询一个useid为749.927.693的数据,首先通过idx文件将文件定位到176块的位置(查询的userid值大于176小于177块存储的值),接下来就是在该颗粒中查找数据。
ck中数据都是以压缩的形式存储在bin文件中,接下来我就是需要知道要查询的数据在bin文件中的物理位置,这就是标记文件中所记录的信息。
在ClickHouse中,表的所有颗粒的物理位置都存储在标记文件中。与数据文件类似,每个表列有一个标记文件。
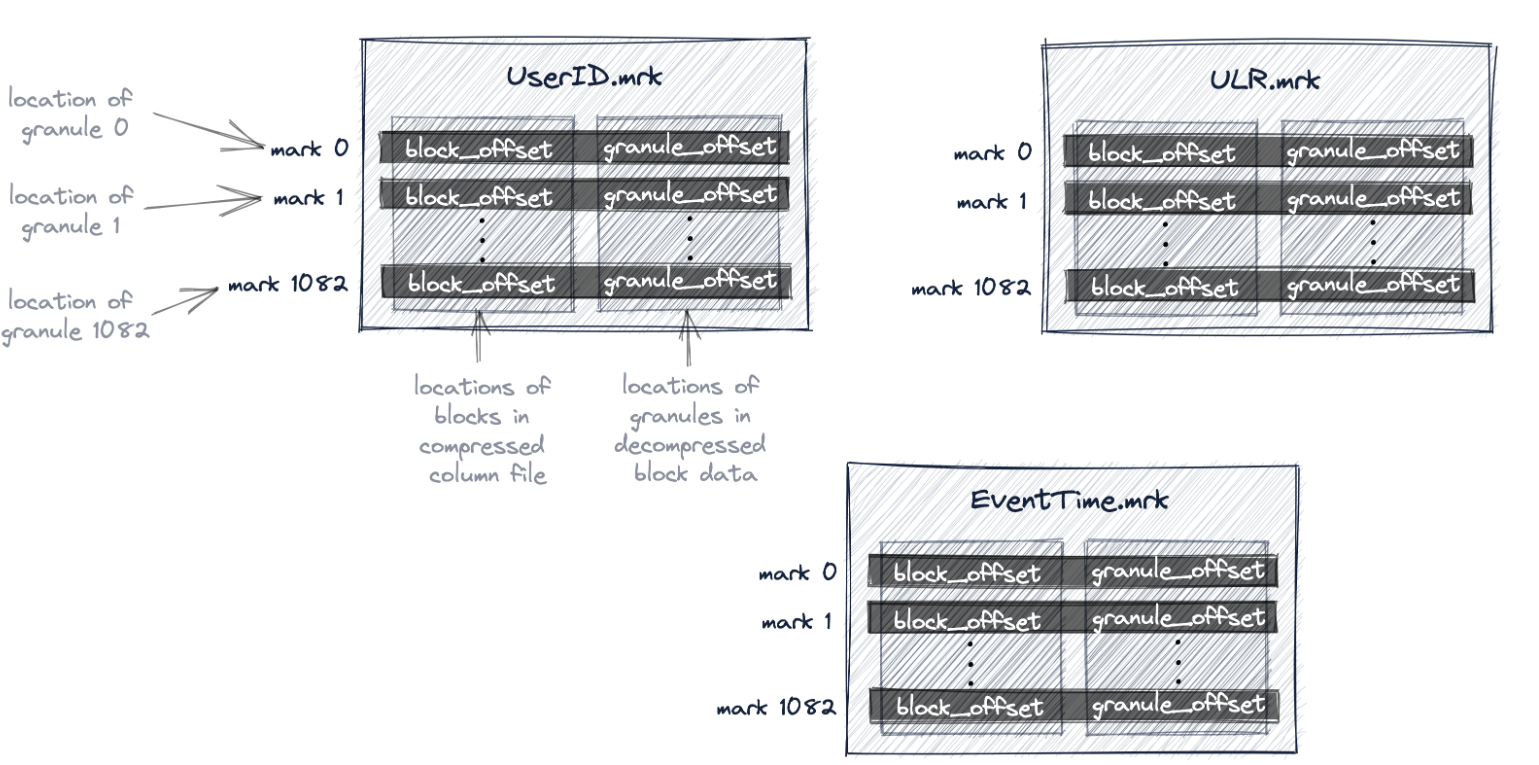
标记文件和idx文件类似,也是一个平面的未压缩数组文件(*.mrk),其中包含从0开始编号的标记。
一旦ClickHouse确定并选择了可能包含查询匹配行的颗粒的索引标记,就可以在标记文件中执行位置数组查找,以获得颗粒的物理位置。
mark文件包含两个偏移量。
第一个偏移量(上图中的'block_offset')定位压缩列数据文件中的块,该文件包含所选颗粒的压缩版本。这个压缩块可能包含一些压缩颗粒。所定位的压缩文件块在读取时不被压缩到主内存中。
标记文件中的第二个偏移量(上图中的'granule_offset')提供了未压缩块数据中颗粒的位置。
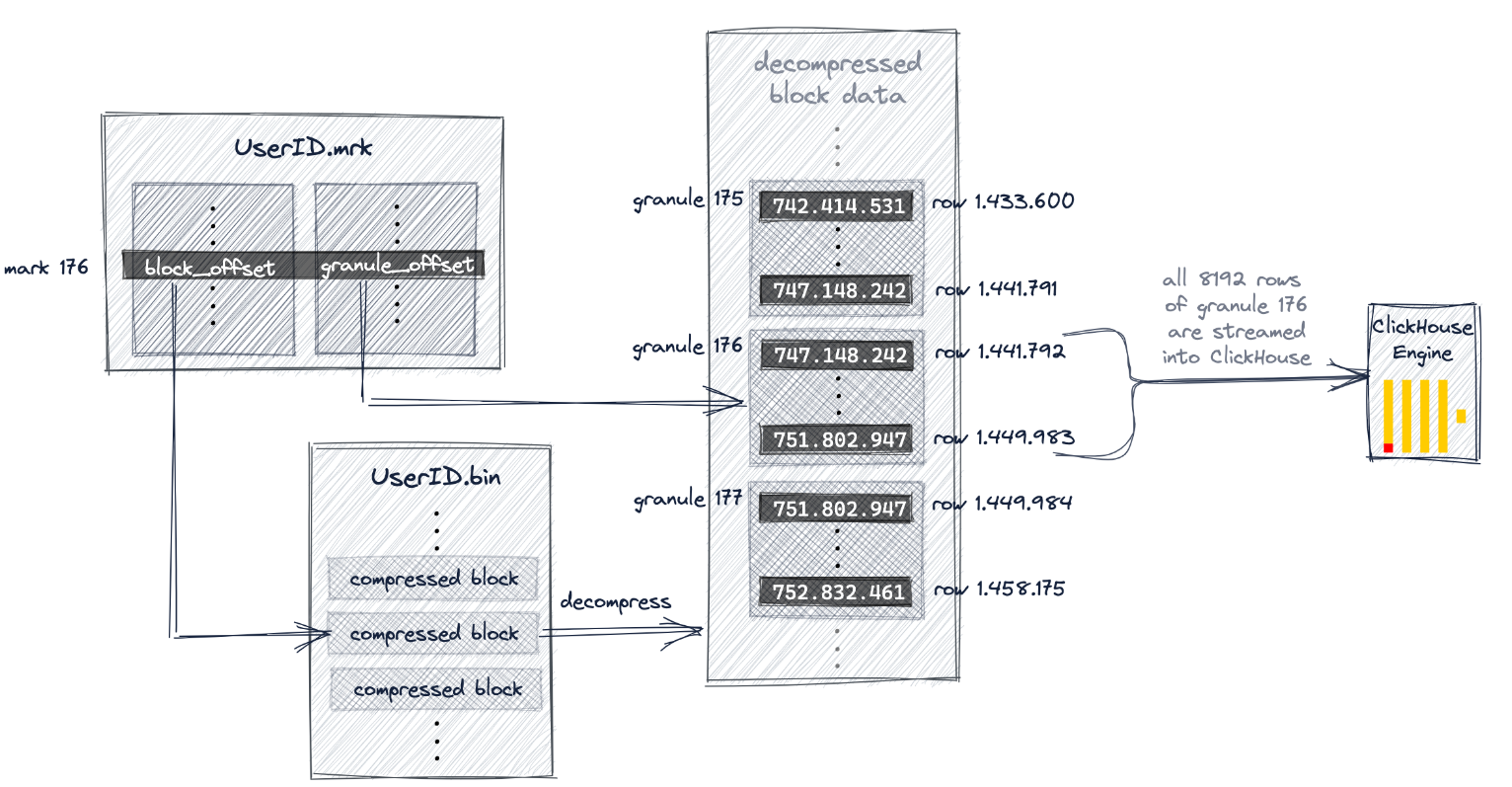
查找到具体数据后,将该8192行数据传输到ck进行最后的处理
2.4. 跳跃索引
跳跃索引有四个重要参数
索引名称:索引名用于在每个分区中创建索引文件。此外,在删除或具体化索引时需要将其作为参数。
指数的表达式:索引表达式用于计算存储在索引中的一组值。它可以是列、简单运算符和/或由索引类型确定的函数子集的组合。
类型:索引的类型控制着确定是否可以跳过读取和求值每个索引块的计算。
粒度:每个索引块由粒度颗粒组成。例如,如果主表索引的粒度为8192行,索引粒度为4,则每个索引的"块"将是32768行。
当用户创建数据跳过索引时,每个数据部分目录中将有两个额外的文件用于表。

CREATE TABLE skip_table
(
my_key UInt64,
my_value UInt64
)
ENGINE MergeTree primary key my_key
SETTINGS index_granularity=8192;
INSERT INTO skip_table SELECT number, intDiv(number,4096) FROM numbers(100000000);
SELECT * FROM skip_table WHERE my_value IN (125, 700)
┌─my_key─┬─my_value─┐
│ 512000 │ 125 │
│ 512001 │ 125 │
│ ... | ... |
└────────┴──────────┘
8192 rows in set. Elapsed: 0.079 sec. Processed 100.00 million rows, 800.10 MB (1.26 billion rows/s., 10.10 GB/s.几乎执行了全表扫描
创建一个索引
ALTER TABLE skip_table ADD INDEX vix my_value TYPE set(100) GRANULARITY 2;(仅作用于后插入数据)
ALTER TABLE skip_table MATERIALIZE INDEX vix; (应用于历史数据)
SELECT * FROM skip_table WHERE my_value IN (125, 700)
┌─my_key─┬─my_value─┐
│ 512000 │ 125 │
│ 512001 │ 125 │
│ ... | ... |
└────────┴──────────┘
8192 rows in set. Elapsed: 0.051 sec. Processed 32.77 thousand rows, 360.45 KB (643.75 thousand rows/s., 7.08 MB/s.)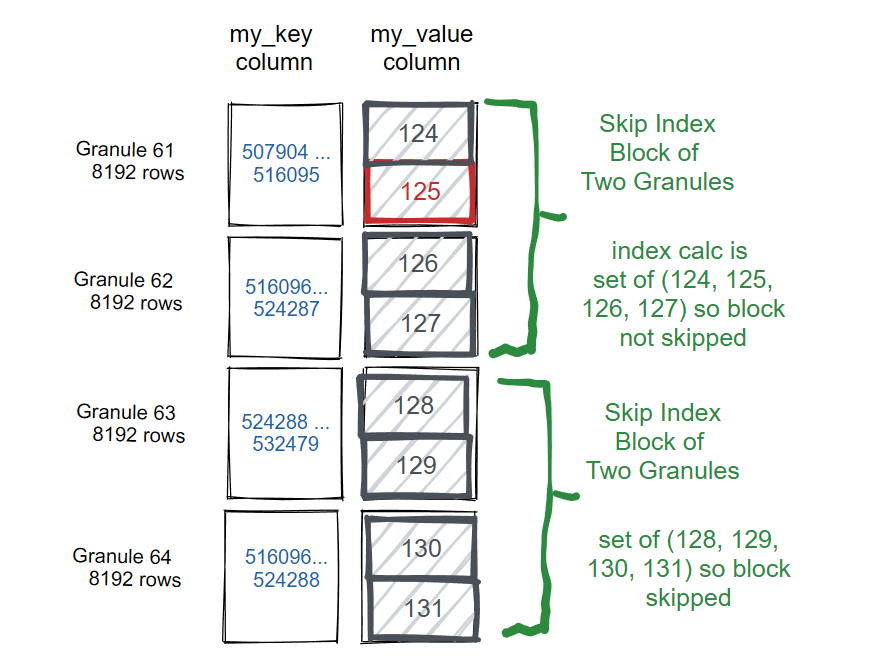
3. 引擎
库引擎
- MergeTree: (支持复制 ReplicatedMergeTree)
-
- 适用范围:适用于大多数 OLAP 场景,特别是对于需要高速插入、更新、删除操作并支持复杂查询的场景。
- 特点:支持按照一个或多个列排序数据,可以处理大规模数据集,提供了高效的数据压缩和查询性能。
- ReplacingMergeTree:
-
- 适用范围:与 MergeTree 类似,但支持根据主键替换行而不是更新它们。
- 特点:适合那些需要更新数据的场景,但不支持直接的更新操作,而是通过插入新版本的数据并自动清理旧版本来实现更新。
- SummingMergeTree:
-
- 适用范围:用于数据按照主键聚合的场景,适合累计统计和汇总。
- 特点:提供了在插入数据时进行聚合操作的功能,可减少查询时的聚合开销。
- AggregatingMergeTree:
-
- 适用范围:适合需要在数据插入时预先聚合的场景。
- 特点:在数据插入时就进行聚合操作,可以大大减少后续查询时的聚合计算开销。
- CollapsingMergeTree:
-
- 适用范围:用于存储按时间序列数据,并能够合并相邻的行以减少存储空间。
- 特点:支持自动合并相邻的行,适合时间序列数据的存储和查询。
- VersionedCollapsingMergeTree:
-
- 适用范围:与 CollapsingMergeTree 类似,但支持版本控制。
- 特点:除了支持行的自动合并外,还可以存储和查询数据的不同版本。
- Distributed:
-
- 适用范围:用于在 ClickHouse 集群中分布式存储和查询数据。
- 特点:用于管理跨多个物理节点的数据分布和复制,支持水平扩展和负载均衡。
- Merge:
-
- 适用范围:用于创建虚拟表,将多个表的数据合并。
- 特点:不存储实际数据,而是在查询时合并多个表的数据,适合于在分布式环境中聚合多个节点的数据。
4. 函数
4.1. 算数运算
适用于UInt8, UInt16, UInt32, UInt64, Int8, Int16, Int32, Int64, Float32, or Float64.
支持UInt8 + UInt16 = UInt32 or Float32 * Float32 = Float64.
Arithmetic Functions | ClickHouse Docs
#求和
plus(a, b)
#求差
minus(a, b)
#×
multiply(a, b)
#除
divide(a, b)
# 余数4.2. 数组函数
4.3. 自定义函数
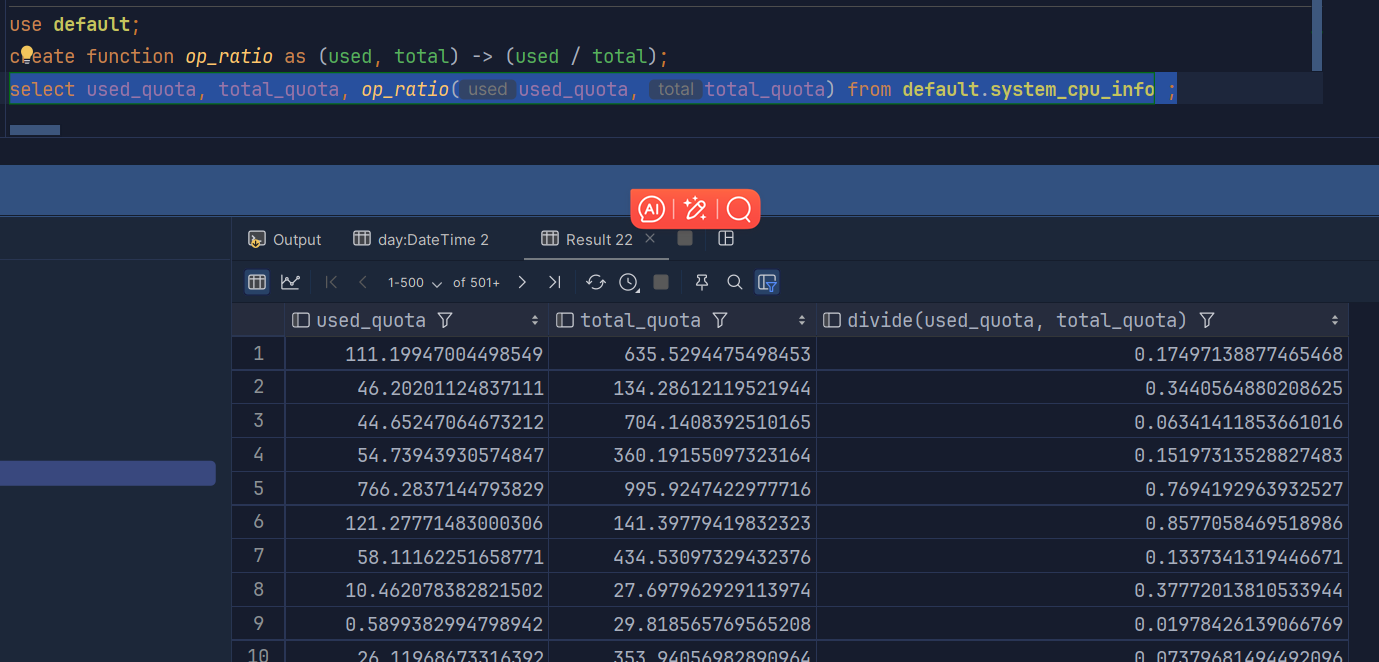
# 求利用率
create function op_ratio as (used, total) -> (used / total);
select used_quota, total_quota, op_ratio(used_quota, total_quota) from default.system_cpu_info ;