建议阅读《Redis开发与运维》《Redis设计与实现》《Redis深度历险:核心原理和应用实践》
Redis 为什么是单线程? 为什么单线程还能这么快?
单线程能够避免线程切换和竞态产生的消耗,而且单线程可以简化数据结构和算法的实现
至于单线程还快,是因为Redis是基于内存的数据库,内存响应速度是很快的,并且采用epoll作为I/O多路复用技术,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多时间
epoll是为了解决Linux内核处理大量文件描述符提出的方案,属于Linux下多路I/O复用接口中select/poll的增强,经常用于Linux下高并发服务型程序,特别是大量并发连接中只有少部分处于活跃下的情况,能提高CPU利用率。
epoll采用事件驱动,只需要遍历那些被内核IO事件异步唤醒之后加入到就绪队列并返回到用户空间的描述符集合
epoll提供两种触发模式,水平触发(LT)和边沿触发(ET),目前效率最高的IO操作方案是:epoll+ET+非阻塞IO模型
Redis 使用场景
最多的应用于缓存,其他可以用于排行榜、计数器、消息队列等
Redis 淘汰策略
Redis 3.0 版本支持的策略
-
volatile-lru:从设置过期时间的数据集(server.dbi.expires)中挑选出最近最少使用的数据淘汰。没有设置过期时间的key不会被淘汰,这样就可以在增加内存空间的同时保证需要持久化的数据不会丢失。
-
volatile-ttl:除了淘汰机制采用LRU,策略基本上与volatile-lru相似,从设置过期时间的数据集(server.dbi.expires)中挑选将要过期的数据淘汰,ttl值越大越优先被淘汰。
-
volatile-random:从已设置过期时间的数据集(server.dbi.expires)中任意选择数据淘汰。当内存达到限制无法写入非过期时间的数据集时,可以通过该淘汰策略在主键空间中随机移除某个key。
-
allkeys-lru:从数据集(server.dbi.dict)中挑选最近最少使用的数据淘汰,该策略要淘汰的key面向的是全体key集合,而非过期的key集合。
-
allkeys-random:从数据集(server.dbi.dict)中选择任意数据淘汰。
-
no-enviction:禁止驱逐数据,也就是当内存不足以容纳新入数据时,新写入操作就会报错,请求可以继续进行,线上任务也不能持续进行,采用no-enviction策略可以保证数据不被丢失,这也是系统默认的一种淘汰策略。
Redis 持久化机制
1.RDB持久化:
把当前进程数据生成快照保存到硬盘的过程,触发方式有手动触发和自动触发
手动触发命令:save和bgsave命令
- save命令:阻塞当前Redis服务,直到RDB过程完成为止,不建议线上环境使用
- bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束,阻塞只发生在fork阶段,一般时间很短
自动触发: - 使用save相关配置,如"save m n"。表示m秒内数据集存在n次修改时,自动触发
- 如果从节点执行全量复制操作,主节点自动执行bgsave 生成RDB文件并发送给从节点
- 执行debug reload命令重新加载Redis时,也会自动触发save操作
- 默认情况下执行shutdown命令时,如果没有开始AOF持久化则自动执行bgsave
RDB文件保存在dir配置指定的目录下,文件名通过dbfilename配置指定,可以通过执行config set dir {newDir} 和 config set dbfilename {newFileName} 运行期动态执行,当下次运行时RDB文件会保存到新目录
- 遇到磁盘损坏或写满时,可以通过config set dir 在线修改文件路径到可用的磁盘路径,之后执行bgsave进行磁盘切换
- redis默认采用LZF算法对生成的RDB文件进行压缩,压缩后文件元小于内存大小,默认开启,可以通过参数config set rdbcompression {yes|no}动态修改
RDB优点:
- RDB是一个紧凑的二进制文件,代表Redis在某个时间点上的数据快照,适合备份,全量复制等场景
- Redis加载RDB恢复数据远远快于AOF方式
RDB缺点:
- 没办法做到实时持久化/秒级持久化
- RDB文件使用特定二进制保存,存在兼容问题
2.AOF持久化
以独立日志的方式记录每次写命令,写入的内容直接是文本协议格式,重启时再重新执行AOF文件中的命令达到恢复数据的目的,解决了数据持久化实时性问题
开启AOF:appendonly yes,默认不开启
AOF文件名: appendfilename 配置,默认appendonly.aof
保存路径:同RDB,通过dir配置
AOF工作流程:
- 所有的写入命令追加到aof_buf(缓冲区)中
- AOF缓冲区根据对应的策略向硬盘做同步操作
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,压缩,父进程执行fork创建子进程,由子进程根据内存快照执行AOF重写,父进行继续响应后面的命令,在子进程完成重写后,父进程再把新增的写入命令写入到新的AOF文件中
- Redis服务重启,加载AOF文件进行数据恢复
AOF为什么直接采用文本协议格式?
- 文本协议具有良好的兼容性
- 开启AOF后,所有写入命令都包含追加操作,直接采用协议格式,避免二次处理开销
- 文本协议具有可读性,方便直接修改和处理
AOF 为什么把命令追加到aof_buf中
- 写入缓存区aof_buf中,能提高性能,并且Redis提供了多种缓存区同步硬盘策略
重写后的AOF文件为什么可以变小?
- 进程内已经超时的数据不再写入文件
- 旧的AOF文件含有无效命令,重写使用进程内数据直接生成,新的AOF文件只保留最终数据的写入命令
- 多条写命令可以合并为一个,为了防止溢出,以64个元素为界拆分为多条
AOF缓冲区同步策略,通过参数appendfsync控制
| 可配置值 | 说明 | 其他 |
|---|---|---|
| always | 命令写入aof_buf后调用系统fsync操作同步到AOF文件,fsync完成后线程返回 | 每次写入都要同步AOF文件,在一般的SATA硬盘很难达到高性能 |
| everysec | 命令写入aof_buf后调用系统write操作,write完成后线程返回。fsync同步操作由线程每秒调用一次(建议策略) | 默认同步策略 |
| no | 命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步,同步硬盘操作由操作系统负责,通常同步周期最长30秒 | 操作系统每次同步AOF文件的周期不可控,而且会加大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证 |
AOF手动触发:调用bgrewriteaof命令
自动触发:有两个参数
- auto-aof-rewrite-min-size: 表示运行时AOF重写时文件最小体积,默认64MB
- auto-aof-rewrite-percentage: 代表当前AOF文件空间(aof_current_size)和上一次重写后AOF文件空间(aof_base_size) 的比值
自动触发时机=aof_current_size > auto-aof-rewrite-min-size && (aof_current_size -aof_base_size) / aof_base_size >= auto-aof-rewrite-percentage
RDB和AOF同时开启,并且AOF文件存在,优先加载AOF文件
AOF文件错误,可以通过redis-check-aof-fix 修复
Redis 数据类型
字符串
key是字符串类型,字符串类型的值可以是字符串、数字、二进制(最大不能超过512MB),是动态字符串,内部通过预分配冗余空间的方式来减少内存的频繁分配
| 命令 | 解释 | 备注 |
|---|---|---|
| set | 设置值 | key value ex seconds 为键设置秒级过期时间 px milliseconds 为键设置毫秒级别的过期时间 nx|xx nx键必须不存在才可以设置成功 xx键必须存在才可以设置成功 |
| mset | 批量设置值 | key value key value ... |
| mget | 批量获取值 | key key ... |
| incr | 对值做自增操作 | 值不是整数,返回错误 值是整数,返回自增后的结果 键不存在,按照值为0自增,返回结果为1 |
| decr | 自减 | key |
| incrby | 自增指定数字 | key increment |
| decrby | 自减指定数字 | key decrement |
| incrbyfloat | 自增浮点数 | key increment |
| append | 追加值 | key value |
| strlen | 字符串长度 | key |
| getset | 设置并返回原值 | key value |
| setrange | 设置指定位置的字符 | key offeset value |
| getrange | 获取部分字符串 | key start end |
哈希
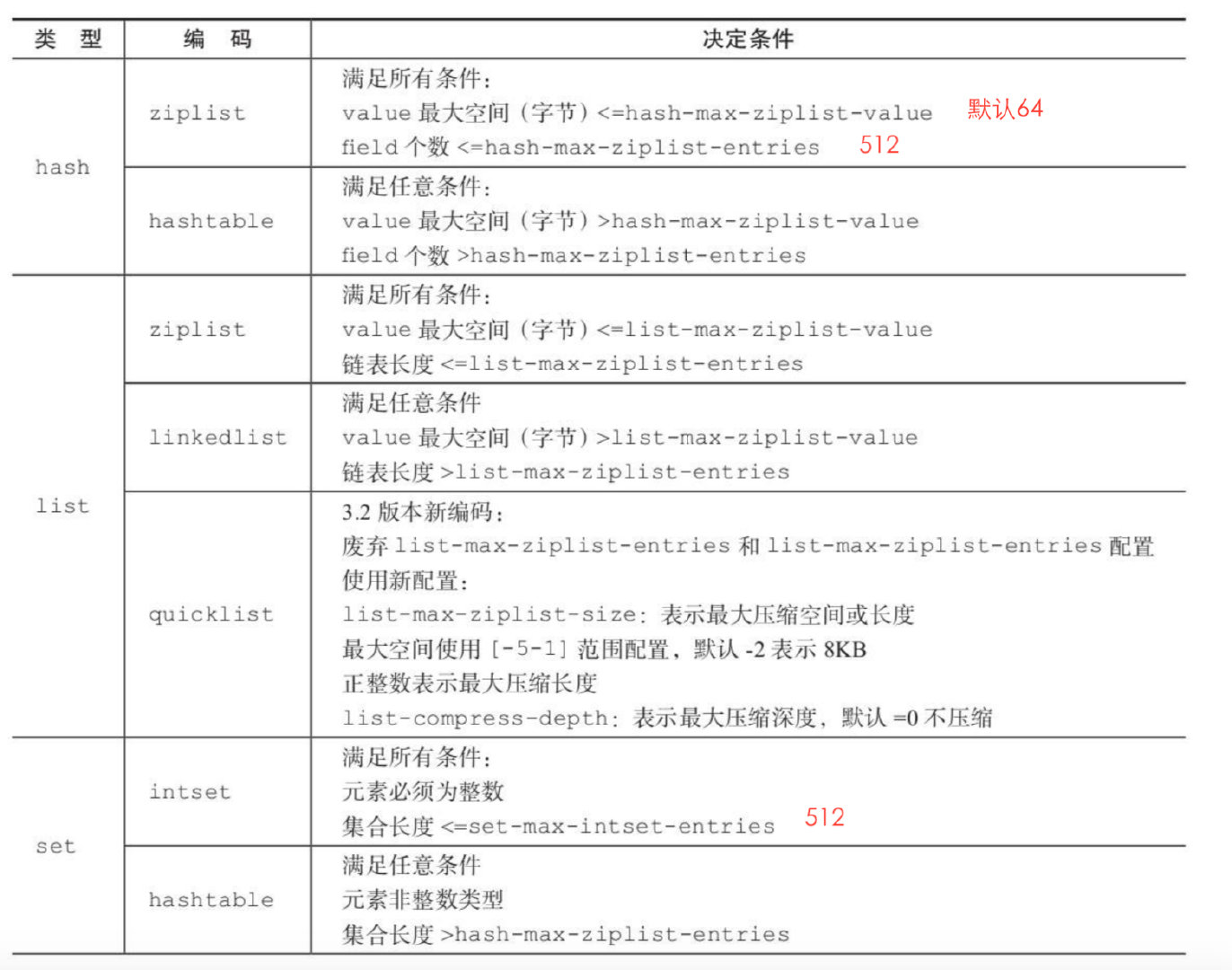
一个键值对结构, 内部结构同Java的 HashMap, 数组+链表的结构,值只能存储字符串,编码是ziplist或者hashtable。另外在rehash的时候,采用定时任务渐进式迁移内容
| 命令 | 解释 | 备注 |
|---|---|---|
| hset | 设置值 | key field value |
| hsetnx | 类似setnx | - |
| hget | 获取值 | key field |
| hdel | 删除一个或多个field | key field field ... |
| hlen | 计算field个数 | - |
| hmget | 批量获取 | key field field ... |
| hmset | 批量设置 | key field value field value ... |
| hexists | 判断field是否存在 | key field |
| hkeys | 获取所有field | key |
| hvals | 获取所有value | key |
| hgetall | 获取所有的field-value | key 如果元素很多,会造成阻塞,建议使用hscan |
| hincrby hincrbyfloat | 类似incrby / incrbyfloat | key field increment |
| hstrlen | 计算value字符串长度 | key field |
列表
用来存储多个有序的字符串,一个列表最多可以存储232 - 1 个元素,列表中的元素可以是重复的,相当于Java中的LinkedList, 是一个链表而不是数组, 底层是采用quicklist结构,在数据量少的时候会使用ziplist压缩列表,数据量多的时候才使用quicklist
| 命令 | 解释 | 备注 |
|---|---|---|
| rpush | 从右边插入元素 | key value value ... |
| lpush | 从左边插入元素 | key value value ... |
| linsert | 向某个元素前或者后插入元素 | key before|after pivot value 从列表中找到等于pivot元素,在其前before 或者after 插入一个新的元素value |
| lrange | 获取指定范围内的元素列表 | key start end 索引下标从左到右是0到N-1, 从右到左是-1到-N; end包含自身 |
| lindex | 获取列表指定索引下标的元素 | key index |
| llen | 获取列表长度 | key |
| lpop | 从列表左侧弹出元素 | key |
| rpop | 从列表右侧弹出元素 | key |
| lrem | 删除指定元素 | key count value 从列表中找到等于value的元素进行删除,count>0, 从左到右,删除最多count个元素。count<0, 从右到左,删除最多count绝对值个元素。count=0,删除所有 |
| ltrim | 按照索引范围修剪列表 | key start end |
| lset | 修改指定索引下标的元素 | key index newValue |
| blpop brpop | 弹出元素阻塞版 | key key ... 多个键 timeount 阻塞时间(秒) |
集合(set)
用来保存多个的字符串的元素,但和列表元素不一样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素,一个集合最多可以存储232 - 1个元素
当集合元素都是整数并且元素个数小于set-max-intset-entries配置(默认512个)时,使用intset编码减少内存使用,否则使用hashtable编码
相当于Java中的HashSet, 所有的value都是一个值NULL
| 命令 | 解释 | 备注 |
|---|---|---|
| sadd | 添加元素 | key element element ... |
| srem | 删除元素 | key element element ... |
| scard | 计算元素个数 | key |
| sismember | 判断元素是否在集合中 | key element |
| srandmember | 随机从集合返回指定个数元素 | key count |
| spop | 从集合随机弹出元素,会删除元素 | key count |
| smembers | 获取所有元素 | key |
| sinter | 求多个集合的交集 | key key ... |
| sunion | 求多个集合的并集 | key key ... |
| sdiff | 求多个集合的差集 | key key ... |
| sinterstore suionstore sdiffstore | 将交集、并集、差集的结果保存 | destination key key... destination 目标集合名称 集合间的运算在元素比较多的情况下会比较耗时 |
有序集合
集合不能重复,但集合中的元素可以根据score分数排序,排序从小到大
当有序集合的元素个数小于zset-max-ziplist-entries(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,使用ziplist来作为内部编码,否则使用skiplist作为内部编码
其相当于Java的SortedSet 和 HashMap结合体,内部实现'跳跃表' 的数据结构
skiplist 编码的有序集合对象使用zset结构做为底层实现,zset结构包括一个字典和一个跳跃表(根据成员查找分值和范围操作的效率最高)
| 命令 | 解释 | 备注 |
|---|---|---|
| zadd | 添加成员 | key NX|XX CH INCRscore member score member ... NX|XX NX: 只有在元素不存在时候添加新元素; XX:更新已经存在的元素,不添加元素 CH 返回有序集合元素和分数发生变化的个数 incr 对score做增加,相当于zincrby |
| zcard | 计算成员个数 | key |
| zscore | 计算某个成员的分数 | key member |
| zrank | 计算成员排名,分数从低到高 | key member |
| zrevrank | 计算成员排名,分数从高到低 | key member |
| zrem | 删除成员 | key member member ... |
| zincrby | 增加成员分数 | key increment member |
| zrange zrevrange | 返回指定排名范围的成员 | key start end withscores 显示分数 |
| zrangebyscore zrevrangebyscore | 返回指定分数范围的成员 | key min max withscores limit offset count key max min withscores limit offset count min和max 支持开区间(小括号) 和闭区间(中括号),-inf 和 +inf 无限小和无限大士大 |
| zcount | 返回指定分数范围成员个数 | key min max |
| zremrangebyrank | 删除指定排名内的升序元素 | key start end |
| zremrangebyscore | 删除指定分数范围的成员 | key min max |
| zinterstore | 交集 | destination numkeys key key ... weights weight \[weight ...] aggregate sum|min|max destination 交集计算结果保存到这个键 numkeys 需要做交集计算键的个数 keykey... 需要做交集计算的键 weights weightweight... 每个键的权重,在做交集计算时,每个键中的每个member会将自己分数乘以这个权重,每个键的权重默认为1 aggregate sum|min|max 计算成员交集后,分值可以按照sum、min、max 做汇总,默认是sum |
| zunionstroe | 并集 | 参数同zinterstore |
内部编码表
查询编码:object encoding key
键相关命令
字符串类型的键,执行set命令会清除过期时间
| 命令 | 解释 | 备注 |
|---|---|---|
| rename | 键重命名 | key newkey 如果键已经存在会把value也覆盖,如果不想被覆盖,可以使用renamenx,重名键期间会执行del命令删除旧的键,如果键值比较大,会造成阻塞 |
| randomkey | 随机返回一个键 | |
| expire pexpire | 键在seconds秒后过期,后者毫秒 | key seconds |
| expireat pexpireat | 键在秒级时间戳后过期,后者毫秒 | key timestamp |
| ttl pttl | 查询键剩余过期时间,pttl毫秒级别 | -1 键没有设置过期时间 -2 键不存在 |
| persist | 清除键的过期时间 | key |
键迁移
move key db 用于在Redis内部多数据库之间进行迁移
dump+restore 不同的实例之间进行数据迁移
migrate host port key|"" destination-db timeout copy replace keys key... 实际上是dump、restore、del是三个命令的组合,具有原子性
host 目标redis的Ip地址
port 目标redis的端口
key|"" 表示迁移多个键
destination-db 目标redis数据库索引
timeout 迁移的超时时间(毫秒)
copy 迁移后并不删除源键
replace 对目标redis的键进行覆盖
keys key... 需要迁移的键
遍历键keys pattern
* 代表匹配任意字符
. 代表匹配一个字符
\[\] 代表匹配部分字符,如1,3匹配1,3 1-10匹配1到10任意数字
\x用来做转义,如匹配问号需要转义
该命令会大数量下会造成阻塞,建议使用scan
scan cursor match pattern count numbercursor 必需参数,从0开始的游标
match pattern 可选,模式匹配
count number 可选,每次要遍历的键个数,默认是10
其他类型命令: 哈希hscan 集合sscan 有序集合zscan 用法与scan相同
问题:渐进式遍历中,如果有新增或删除键,就可能会没有完整遍历出所有的键
Bitmaps
其并不是一种数据结构,实际上就是字符串,可以对字符串的位进行操作,内部使用二进制存储,在存储超大上亿数据的时候,能节约很多内存空间
| 命令 | 说明 | 备注 |
|---|---|---|
| setbit | 设置值 | key offset value offset 偏移量,可以理解为索引 |
| getbit | 获取值 | key offset |
| bitcount | 获取指定范围值为1的个数 | start end start和end代表起始和结束字节数 |
| bitop | 多个bitmaps操作 | op destkey keykey ... and(交集)、or(并集)、not(非)、xor(异或) destkey 结果保存的key |
| bitpos | 计算第一个值为targetBit的偏移量 | key targetBit start end |
HyperLogLog
其实际类型是字符串类型,是一种基数算法,可以利用极小的内存空间完成独立总数的统计
HyperLogLog内存占用小,但存在一定错误率
| 命令 | 说明 | 备注 |
|---|---|---|
| pfadd | 添加 | key element element ... |
| pfcount | 计算独立用户数 | key key ... |
| pfmerge | 合并 | destkey sourcekey sourcekey ... |
其他命令
object idletime key 查询key的空转时长
object encoding key 查询key的内部编码
Pipeline
Pipeline(流水线) 机制能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按照顺序返回给客户端
原生批量命令与Pipeline对比:
- 原生批量命令是原子的,Pipeline是非原子的
- 原生批量命令是一个命令对应多个key,Pipeline支持多个命令
- 原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端共同实现
事务
redis 简单事务功能,将一组需要一起执行的命令放到multi和exec 两个命令之间。multi命令代表事务开始,exec命令代表事务结束,他们之间的命令是原子顺序执行的。如果要停止事务的执行,用discard命令代替exec命令
watch 命令 用来确保事务中的key没有被其他客户端修改过,才执行事务,否则不执行(类似乐观锁)
Lua
两种方法:
- eval
eval 脚本内容 key个数 key列表 参数列表
lua
eval 'return "helo "..KEYS[1].. ARGV[1]' 1 redis world还可以使用redis-cli --eval 直接执行文件
- evalsha
evalsha 脚本sha1值 key个数 key列表 参数列表
将Lua脚本加载到Redis服务端,得到该脚本的SHA1校验和,evalsha使用SHA1作为参数执行对应的Lua脚本,避免每次发送脚本,脚本常驻与内存中
加载脚本到Redis: redis-cli script load "$(cat ~/lua_test.lua)"
慢查询分析
配置文件配置: slowlog-log-slower-than 超过多少阈值(微秒,默认10毫秒);slowlog-max-len 慢日志最大长度
命令修改: config set 和 config rewrite(写入配置文件)
config set slowlog-log-slower-than 100
config set slowlog-max-len
-
获取慢查询日志:
慢查询只记录命令执行时间,不包括命令排队和网络传输时间
slowlog get n n指定条数
-
日志数据结构
3 1) (integer) 3 (id)
- (integer) 1567317373 (发送时间戳)
- (integer) 21 (命令消耗时间)
- "keys" (命令和参数)
- "*"
慢查询日志重置:
slowlog reset
Redis键过期删除策略
键过期,内部保存在过期字典expires中,Redis采用惰性删除 和定时任务删除 机制;
惰性删除用于在客户端读取带有超时属性的键时,如果已经超过设置的过期时间,会执行删除并返回空,但这种方式如果键过期,而且一直没有被重新访问,键一直存在
定时任务删除:能够解决惰性删除问题,Redis内部维护一个定时任务,每秒运行10次。根据键的过期比例,使用快慢两种速率模式回收键,缺点是占用CPU时间,在过期键多的时候会影响服务器的响应时间和吞吐量
定期删除:每隔一段时间执行一次删除过期键操作,通过限制删除操作的执行时长和频率来减少影响,缺点需要合理设置执行时长和频率
生成RDB文件的时候已过期的键不会被保存,在载入RDB文件的时候,主服务器会对键进行检查,过期的键不会被载入,而从服务会将所有键载入,直到主服务来删除通知
AOF写入的时候,如果某个键过期,会向AOF追加一条DEL命令;AOF重写的时候会对键进行检查,过期键不会被写入
复制的时候,主服务器发送删除通知,从服务器接到删除通知时才删除过期键
Redis高可用方案
- 主从模式:一主二从(达到支持10万+并发)
配置redis.conf , 从节点配置 slaveof 127.0.0.1 6379
确认主从关系: redis-cli -h 127.0.0.1 -p 6379 info replication - 哨兵模式:
配置 redis-sentinel.conf ,sentinel monitor mymaster 127.0.0.1 6379 1
最后一位是选举master需要的票数
启动哨兵:
redis-sentinel redis-sentinel.conf
或者 redis-server redis-sentinel.conf --sentinel - redis-cluster:
每个节点保存数据和整个集群状态,每个节点都和其他节点连接。采用哈希函数把数据映射到一个固定范围的整数集合中,整数定义为槽。所有键根据哈希函数映射到0~16383整数槽内,公式 slot = CRC16(key) & 16383
修改redis.conf,开启集群模式:cluster-enabled yes,集群内部配置文件路径:cluster-config-file "nodes-6379.conf"
启动节点
使用meet把节点加入集群中:cluster meet 127.0.0.1 6381 - Codis
https://juejin.im/post/5c132b076fb9a04a08218eef
- 集群限制:
- key批量操作支持限制,目前只支持具有相同slot值的key执行批量操作
- key事务操作支持有限
- key作为数据分区最小粒度,不能将大的键值对象hash、list等映射到不同节点
- 只能使用0号数据库
- 从节点只能复制主节点,不支持嵌套树状复制结构
- 主从复制过程
- 从节点执行slaveof后,从节点保存主节点地址信息
- 从节点内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接
- 连接建立成功后,从节点发送ping请求进行首次通信,目的是检测主从之间网络套接字是否可用,主节点当前是否接受处理命令
- 如果主节点配置了密码验证,则从节点必须要配置相同的密码才能通过验证,进行复制同步
- 通过验证后,主从可正常通信了,主节点会把数据持续发给从节点,同步方式有全量同步和部分同步,刚建立建立的时候,会进行全量同步,同步结束后,进行部分同步
- 当主节点与从节点同步完当前的数据后,主节点会把后续新增的命令持续发送给从节点进行同步
- 哨兵模式 最小配置 1主 2从 3哨兵,3个哨兵能监控每个master和salve
解决异步复制和脑裂导致的数据丢失
min-slaves-to-write 1
min-slaves-max-lag 10
要求至少有1个slave,数据复制和同步的延迟不能超过10秒
如果说一旦所有的slave,数据复制和同步的延迟都超过了10秒,那么master就不会再接收任何请求了
这两个配置可以减少异步复制和脑裂导致的数据丢失
(1)减少异步复制的数据丢失
有了min-slaves-max-lag 这个配置,就是说一旦slave复制数据和ack延迟太长,就认为master可能宕机后损失数据太多,就拒绝写入,使得同步造成的数据丢失降到可控范围
(2)减少脑裂的数据丢失
如果一个master 出现了脑裂,跟其他slave丢了连接,那么上面的配置可以确保,如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求,这样脑裂后的旧master不会接受client的新数据,也就避免了数据丢失
缓存问题
-
缓存穿透
缓存穿透是指,缓存中不存在该key的数据,于是就是去数据库中查询,数据库也不存在该数据,导致循环查询数据
优化:
-
缓存空对象
对于不存在的数据,依旧将空值缓存起来。但这会造成内存空间的浪费,可以针对这类数据加一个过期时间。对于缓存和存储层数据的一致性,可以在过期的时候,请求存储层,或者通过消息系统更新缓存
-
布隆过滤器
将所有存在的数据做成布隆过滤器,可以使用Bitmaps实现,其在大数据量下空间占用小。当有新的请求时,先到布隆过滤器中查询是否存在,如果不存在该条数据直接返回;如果存在该条数据再查询缓存、查询数据库。
Redis4.0以上采用插件集成,https://github.com/RedisBloom/RedisBloom
原理:
在redis中是一个大型的位数组,通过计算key的hash然后对数组长度取模得到一个位置,进行写入;在判断是否存在时,判断位数组中几个位置是否都为1,只要一个位为0,就说明这个key不存在。布隆过滤器也会存在一定的误判,如果位数组比较稀疏,概率就会很大,否则就会降低。
-
-
缓存击穿
缓存击穿指,某key突然变成了热点key,大量请求到该key,但key刚好又失效,导致从数据库中去查询数据
优化:
通过互斥锁方式,在请求数据库之前设置setnx,在查询完数据库,并更新缓存后,删除setnx
-
缓存雪崩
指缓存由于大量请求,同时缓存又大量失效,导致大量请求直接打到存储层,造成存储层压力过大或者挂机
优化:
事前
- 使用主从,哨兵,集群模式保证缓存高可用
- 提前演练,做好后备方案
事中:
使用限流组件,限流并降级
事后:
redis 持久化,重启后恢复数据
-
缓存更新方式
同步更新,先写入数据库,写入成功后,再更新缓存。
异步更新,通过消息中间件进行触发更新。
失效更新,在取不到缓存的时候,从数据库取数据,再更新缓存。
定时更新,通过定时任务来更新缓存
-
缓存不一致
通过增加重试机制,补偿任务,达到最终一致
-
热点key重建
优化
- 使用互斥锁,只允许一个线程重建缓存
- 使用逻辑缓存过期,在value中存一个key过期时间,在获取key的时候通过逻辑时间进行判断
Redis 锁的实现 和 Zookeeper锁实现区别
Redis 锁 通过 setnx key value 或者 set key value px millseconds nx 当返回1时代表获取到锁,返回0表示获取锁失败,通过Redis的key超时机制来释放锁
PS: Redis锁可能会在业务逻辑还没执行完的时候就已经超时释放,因此在释放锁的时候,可能其他线程已经重新持有了该锁,所以要在释放锁的时候验证key对应的value值,在创建缓存的时候,value值是随机生成的。或者使用redisson做为分布式锁
ZK锁 通过在服务端新建一个临时有序节点,哪个客户端成功创建了第一个临时有序节点,就代表该客户端获得了锁,后面节点的客户端会处于监听状态,当释放锁的时候,服务端就会删除第一个临时节点,此时第二个临时节点能监听到上一个节点的释放事件,这样第二个节点就变成第一个节点,此时客户端2就代表获得了锁。如果客户端的会话关闭,临时节点会被删除,也就释放了锁
在某个时间段,redis某个key变成了热点key,此时请求又都打到了一台slave上,请问该怎么办?
由于之前没有做热点Key监控,不能进行对热点key 进行本地缓存,也没有预料到该key会变成热点key,但现在该key变成了热点key, 此时的办法可以新开redis实例,在新的实例上新建该热点key,将后续的请求分散到其他的实例上。
关于redis热点key的文章:
《达到物理网卡上限,突然几十万的请求访问Redis的某个key如何解决》
Redis 如何排查大key
使用--bigkeys命令
- 这是Redis自带的一个命令,用于对整个Key空间进行扫描,统计string、list、set、zset、hash等常见数据类型中每种类型里的最大的key。
- 使用方法:
redis-cli -h <hostname> -p <port> -a <password> --bigkeys - 注意:这个命令是以scan延迟计算的方式扫描所有key,因此执行过程中不会阻塞Redis,但当实例存在大量的keys时,命令执行的时间会很长。建议在slave上扫描。
使用MEMORY USAGE命令(仅支持Redis 4.0以后的版本)
- 这个方法可以查看指定key的内存使用情况。
- 使用方法:
redis-cli -h <hostname> -p <port> -a <password> MEMORY USAGE <keyname> - 该命令会返回key的内存使用情况(以字节为单位)。
使用Rdbtools工具包
- Rdbtools是一个第三方开源工具,用于解析Redis的快照文件(rdb文件)。
- 通过这个工具,可以分析rdb文件中的内容,包括各个key的大小。
持续更新地址
语雀:https://www.yuque.com/itsaysay/mzsmvg
GitHub: https://github.com/jujunchen/Java-interview-question